







想象一下,你班上有个超级聪明的学霸,但他做题时总像得了「思维多动症」——一会儿用代数算,突然又切到几何法,再蹦出个微积分,最后…答案错了!这篇论文抓到的正是大语言模型(比如OpenAI的o1)的这个小毛病:underthinking(思考不足)。
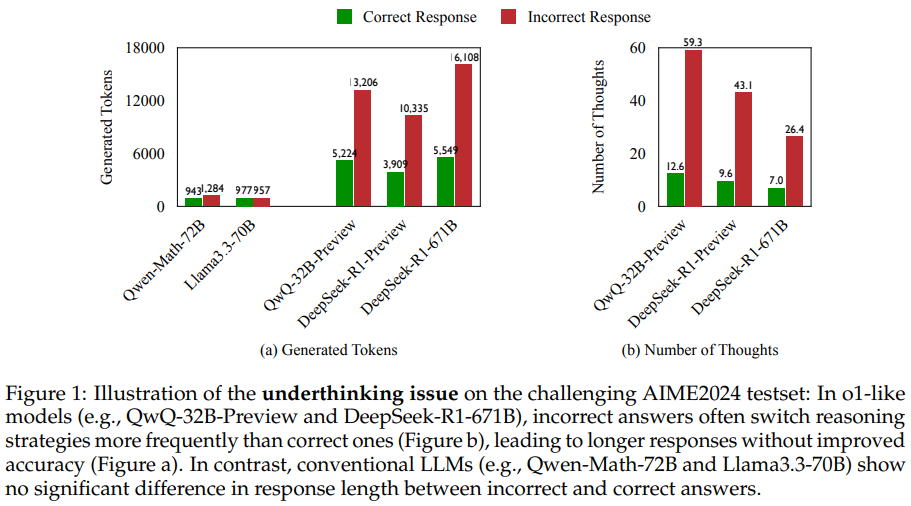
作者们发现,这些模型面对数学难题时,像极了刷题时三心二意的人类——明明找到正确思路的开头(比如画椭圆找交点),却非要切到其他方法,最后用7681个token写了一篇《论我如何跑题》的小作文,答案还是错的😂。更扎心的是,错误答案的token量比正确答案多225%,妥妥的「无效内卷」!
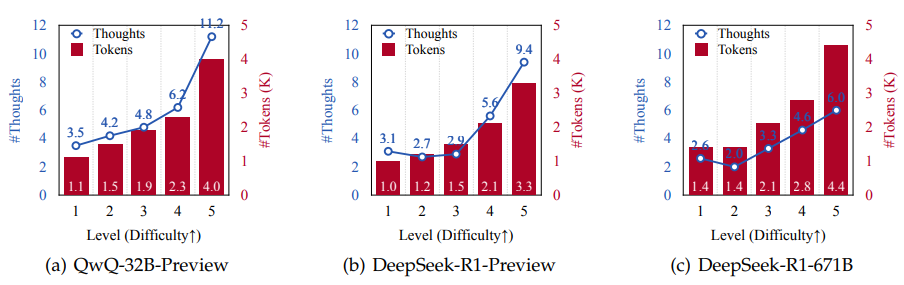
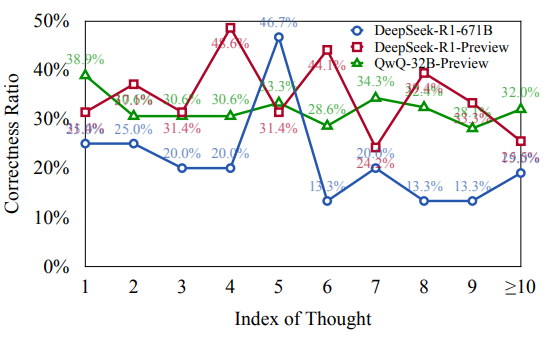
方法
如何治这个「思维多动症」?论文祭出了TIP(Thought Switching Penalty),简单说就是给模型戴上一副「专注眼镜」:
惩罚分心词汇:当模型想用"Alternatively"这种「切台词」时,直接扣分!
惩罚公式:把分心词的logits值减掉α(惩罚力度),并在β个token内持续生效。举个栗子🌰:如果α=3,β=600,模型一说"Alternatively",系统就弹出一个表情包:「禁止切台!请先写完当前思路!」

这波操作像极了老师敲黑板:「同学,先把第一种方法算到底,再想别的!」
实验
为了验证TIP的效果,作者们给模型开了个「数学特训班」,用三大地狱级题库测试:
MATH500-Hard:高中数学竞赛题(难度5颗星🌟)
GPQA Diamond:研究生级别数理化生题(瑟瑟发抖.jpg)
AIME2024:美国数学邀请赛真题(专治各种不服)
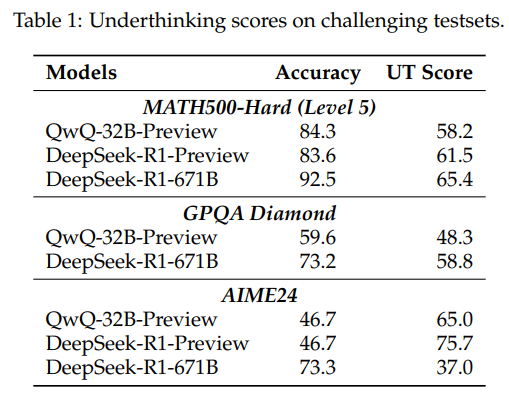
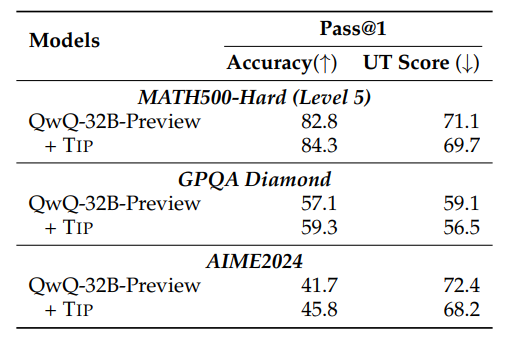
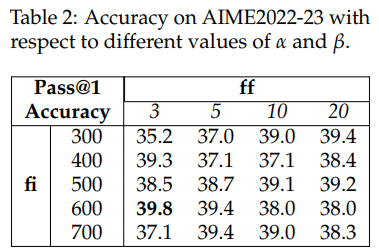
实验发现,用了TIP的QwQ-32B模型成绩全面提升!比如在AIME2024上,准确率从41.7%涨到45.8%,而「分心指数」UT Score从72.4降到68.2。更搞笑的是,当惩罚参数调成α=3、β=600时,模型像吃了定心丸,准确率最高冲到39.8%(对比基线35.2%)!
结论
这篇论文给大语言模型开了副「专注药」,核心就一句话:少切频道,多挖矿!通过TIP策略,模型在错误答案上少浪费70%的口水(token),还能在数学题上多拿4分(准确率+4.1%)!
未来,作者们还想让AI学会「自适应专注」——该切换时切换,该深挖时深挖。说不定哪天,AI做题时会自己喊出:「教练,我想先把这个思路写完!」
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









