






来自:东南COIN
作者:Dehai Min1, Zhiyang Xu3, Guilin Qi1, Lifu Huang4, Chenyu You2
作者单位:1、东南大学, 2、纽约州立大学石溪分校, 3、弗吉尼亚理工大学, 4、加州大学戴维斯分校
论文录用:NAACL 2025 Main Conference
论文地址:https://arxiv.org/abs/2410.20163
数据集&代码地址:https://github.com/ZhishanQ/UniHGKR

1、引言
检索增强型生成(Retrieval-Augmented Generation, RAG)已成为提高生成式大语言模型(LLMs)真实性的一项关键技术。通过利用检索器从大规模知识库中提取相关知识,RAG 有效减少了 LLMs 经常产生的幻觉现象。如图1所示,尽管现有的信息检索(IR)方法在从同质知识库(知识以单一结构存储,如表格或文本)中检索信息方面表现出有效性,但这些系统大多无法识别多样化的用户检索意图,也无法从多个来源有效地检索异构知识。在异构信息检索中,知识来自多种结构,这使得检索复杂得多。仅依赖同质知识通常会导致检索结果不完整或不全面,限制了这些系统在更广泛下游任务中的适用性。为了克服这些问题,本文提出了UniHGKR,一个统一的指令感知异质知识检索器,它(1)为异质知识构建统一的检索空间,并(2)遵循多样的用户指令以检索指定类型的知识。此外,现有的异构信息检索基准测试在知识覆盖范围上存在局限性。例如一些研究仅关注两种知识类型:表格和文本。为了填补这一空白,我们还引入了CompMix-IR,这是首个异构知识检索基准测试。我们发布了相关的代码、模型权重和CompMix-IR语料库以供社区的进一步研究。
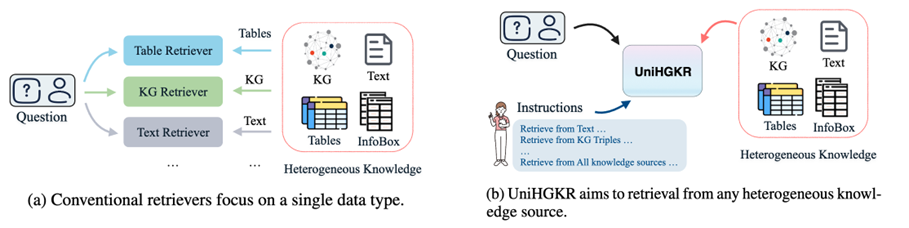
图1: 与传统方法相比,UniHGKR 能够根据用户指令处理查询,并从异构知识候选池中检索信息。
2、CompMix-IR 基准建立
CompMix-IR 是第一个用于异构知识检索的基准数据集,旨在满足现实世界中多样化的检索需求。它基于 CompMix QA 数据集构建,涵盖了四种知识类型:文本(Text)、知识图谱(KG)、表格(Table) 和 信息框(Infobox)。我们从Wikidata和Wikipedia中共收集了超过 1000 万条证据,涵盖 137,808 个不同实体,具体分布和统计信息如表1所示:
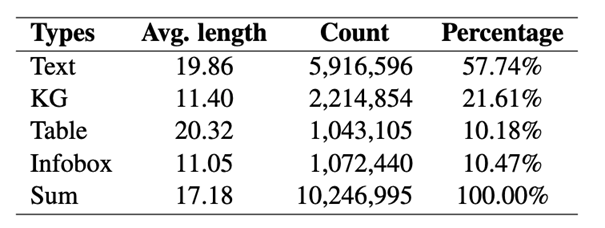
表1: CompMix-IR统计信息
为了模拟现实世界的检索需求,CompMix-IR 定义了两种检索场景和相应的指令模板:
- 场景 1:从所有知识类型中检索相关证据。
- 场景 2:根据用户指令检索特定类型的证据。
这两种场景都使用相同的证据池,要求检索器根据指令调整查询-证据相似性。这种设置反映了现实世界检索任务的复杂性,为多样化应用提供了更强的实用性和相关性。它们对应的指令模板如表2所示:

表2: 异构检索指令的Schema和示例
3、UniHGKR方法
UniHGKR 的目标是从异构知识候选池中检索与问题相关的证据。检索任务是根据用户指令和问题的组合找到最相关的证据。检索器通过计算问题和证据的嵌入向量之间的相似性来返回最相关的证据。
UniHGKR 框架包含三个主要训练阶段,旨在逐步构建一个能够处理异构知识并遵循用户指令的检索器。我们的整体训练框架的示意图如图2所示:
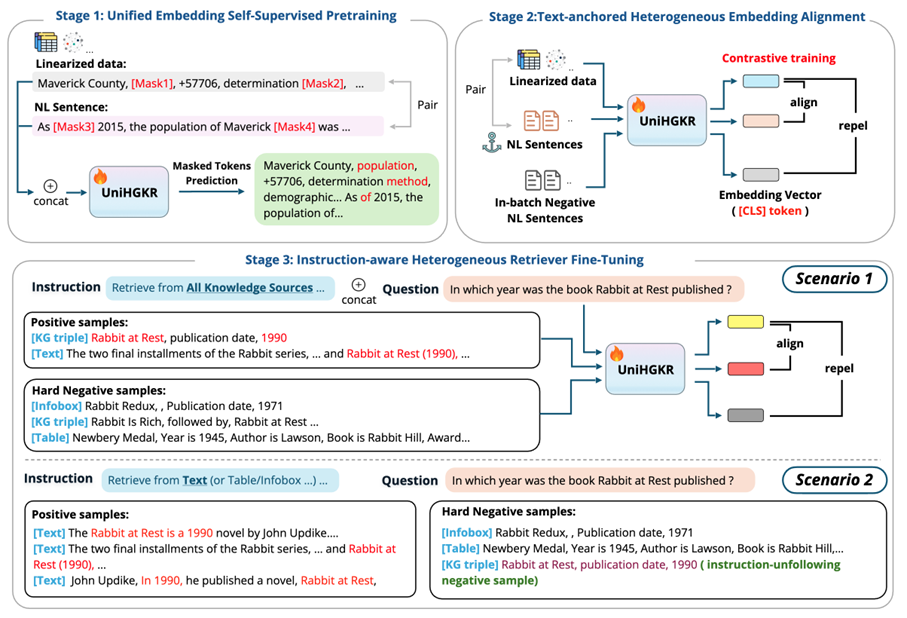
图2: UniHGKR训练框架的示意图
阶段 1:异构数据的统一嵌入自监督预训练
此阶段的目标是解决预训练语言模型(PLMs)在处理异构数据时的不足。具体方法是:
构建数据-文本对,其中数据是线性化的结构化知识(如知识图谱、表格或信息框),文本是以自然语言表达的描述结构化知识语义信息的句子。
使用掩码标记重建任务对模型进行训练,使模型能够接受异构格式的输入序列作为自监督信号。
其中,我们利用LLM来构建异构数据-文本对的示意图如图3所示:

图3: 数据-文本对集合的示例。粗体红色部分是在将结构化数据线性化时用的模板。其中用于 GPT-4o-mini 的提示可以在原文的附录中找到。
阶段 2:以文本为锚点的异构数据嵌入表示对齐
此阶段通过对比学习进一步优化嵌入空间,使结构化数据和自然语言文本的嵌入对齐。具体方法是:
使用数据-文本对,通过对比学习将结构化数据和自然语言文本的嵌入对齐。
使用批次内负样本(in-batch negatives)来推斥语义不同的嵌入,从而创建一个专注于语义信息的统一嵌入空间。
阶段 3:指令感知异构检索器的微调
此阶段的目标是微调检索器,使其能够根据用户指令检索特定类型的证据。具体方法是:
对于每个问题及其相关证据,生成两种训练样本:一种是检索所有类型证据的样本,另一种是检索特定类型证据的样本。
引入两种对比损失函数, 优化检索器的性能:
- 类型平衡损失:用于检索所有类型证据的场景(检索场景1),使每种类型的负样本数量大致相等。
- 类型优先损失:用于检索特定类型证据的场景(检索场景2),通过减少指定类型的负样本数量,使模型优先检索该类型的证据。
4、实验
实验的主要目标是评估 UniHGKR 模型和基线模型在 CompMix-IR 数据集的两种检索场景上的性能。实验中使用了 CompMix 数据集的训练集、验证集和测试集划分。
4.1 基线模型
我们选择了多种现有的检索模型作为基线,包括:
- Zero-shot SOTA 检索器:这些模型未在 CompMix-IR 数据集上进行微调,但已经在其他检索任务中表现出色。包括:Mpnet, Contriever, DPR, GTR-T5, SimLM, BGE, Instructor, BM25。
- Fine-tuned 基线:这些模型在 CompMix-IR 数据集上进行了微调,以提高其在特定任务上的性能。包括:BERT-finetuned, UDT-retriever, UniK-retriever。
4.2 评估指标
为了全面评估模型性能,我们使用了以下指标:
- Hit@K:衡量前 K 条检索结果中是否包含正确答案的比例(K=5, 10, 100)。
- MRR@K(Mean Reciprocal Rank):计算第一个相关证据的平均倒数排名(K=100)。
- Type-Hit@100:仅在场景 2 中使用,衡量前 100 条检索结果中是否包含指定类型(Type)的正确证据。
4.3 实现细节
- 对比学习:所有对比训练均使用批次内负样本(in-batch negatives),以增加负样本的多样性。
- 硬件配置:实验在 8 块 A800-80GB GPU 上进行,使用最大可能的批量大小以充分利用 GPU 内存。
- 训练样本设置:在第三阶段(微调阶段),每个训练样本包含 1 个正样本和 15 个负样本。
5、实验结果与分析
5.1 主实验结果
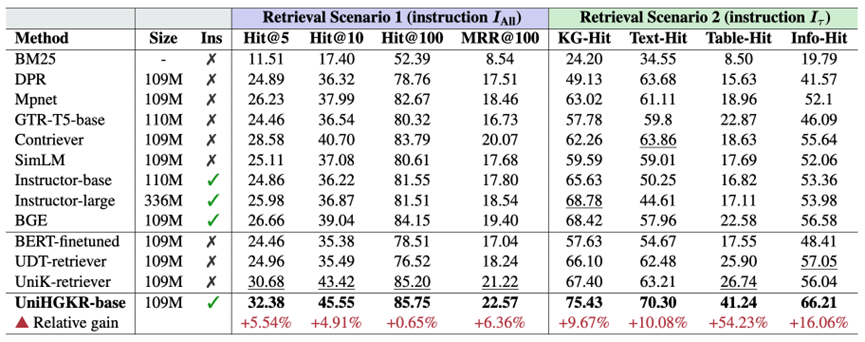
表3: 检索模型在CompMix-IR两种检索场景的实验结果
我们的主实验结果如表3所示,我们可以看到UniHGKR 在两种检索场景下均显著优于所有基线模型,证明了其在异构知识检索中的有效性。
- 场景 1(检索所有知识类型):
UniHGKR-base 在 Hit@5、Hit@10、Hit@100 和 MRR@100 上分别达到了 32.38%、45.55%、85.75% 和 22.57%。
相比之下,性能最好的基线模型(如 BGE 和 Instructor-large)在 MRR@100 上仅达到 19.40%,显示出 UniHGKR 在综合检索能力上的显著提升。
UniHGKR 在检索结构化数据(如表格和信息框)方面表现出色,Table-Hit 和 Info-Hit 分别达到了 41.24% 和 66.21%。
相比之下,其他基线模型在这些指标上表现较差,例如 BGE 的 Table-Hit 仅为 22.58%,表明 UniHGKR 在遵循用户指令检索特定类型知识方面具有明显优势。
5.2 扩展到基于 LLM 的检索器
我们还将 UniHGKR 框架扩展到基于LLMs的检索器,并训练了 UniHGKR-7B 模型。表4展示了它们在CompMix-IR上的检索表现。
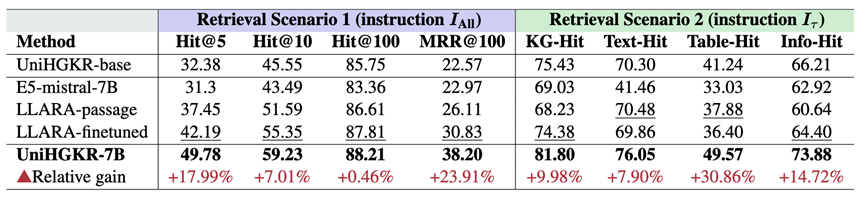
表4: UniHGKR-7B 和其他基于 LLM 的检索器基线的检索性能
实验结果表明,UniHGKR-7B 在所有指标上均优于现有的 LLM 基线模型,进一步证明了 UniHGKR 框架的可扩展性和有效性。
UniHGKR-7B 在场景 1 的 MRR@100 上达到了 38.20%,相比最佳基线模型(LLARA-finetuned)提升了 23.91%。
在场景 2 的 Table-Hit 上达到了 49.57%,相比最佳基线模型(E5-mistral-7B)提升了 30.86%。
5.3 在Open Domain的异构问答系统中的应用
为了验证 UniHGKR 在实际应用中的有效性,我们将其应用于开放域问答(QA)系统,特别是在 ConvMix 数据集上进行评估。
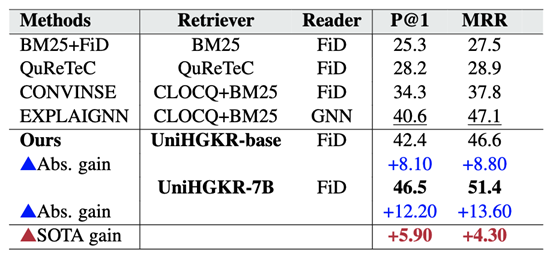
表5: 使用 UniHGKR 检索器和基准模型在 ConvMix 数据集上的问答性能
实验结果在表5中展示,我们可以观察到利用UniHGKR 模型作为检索器显著提升了 QA 系统的性能,在该数据集上达到了新的SOTA表现。
使用 UniHGKR-base 作为检索器时,P@1 和 MRR 分别达到了 42.4% 和 46.6%,相比之前的CONVINSE分别提升了 8.10 和 8.80。
使用 UniHGKR-7B 作为检索器时,P@1 和 MRR 分别达到了 46.5% 和 51.4%,相比之前的最佳系统(EXPLAIGNN)分别提升了 5.90 和 4.30。
额外的消融实验,鲁棒性实验,不同规模模型的时间效率分析 和 CompMix-IR 的语料库和QA Examples可以在原文中查看。
6、总结
在本文中,我们提出了 UniHGKR,一个能够根据用户指令从异构知识源中检索信息的框架。首先,我们构建了 CompMix-IR,这是首个包含四种异构数据类型(文本、知识图谱、表格和信息框)的检索任务数据集,语料库规模超过 1000 万条目。接着,我们定义了两种不同的异构信息检索场景,以满足现实世界中多样化的检索需求。我们设计了 UniHGKR 框架,包含三个训练阶段:统一嵌入自监督预训练、以文本为锚点的异构嵌入对齐和指令感知异构检索器微调。我们的实验结果表明,UniHGKR 在 CompMix-IR 基准测试中达到了最先进水平(SOTA),无论是基于 110M 参数的 BERT 模型,还是基于 7B 参数的 LLM 模型。此外,将 UniHGKR 检索器应用于开放域问答系统时,也能显著提升系统的性能,在 ConvMix 数据集上达到了新的 SOTA 结果。
参考文献(部分):
- Achiam, J.; et al. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774.
- Asai, A.; et al. 2023. Task-aware retrieval with instructions. In Findings of the Association for Computational Linguistics: ACL 2023, pages 3650–3675.
- Ayala, O.; Bechard, P. 2024. Reducing hallucination in structured outputs via retrieval-augmented generation. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 6: Industry Track), pages 228–238.
- BehnamGhader, P.; et al. 2024. Llm2vec: Large language models are secretly powerful text encoders. arXiv preprint arXiv:2404.05961.
- Chen, N.; et al. 2021a. Self-supervised dialogue learning for spoken conversational question answering. arXiv preprint arXiv:2106.02182.
- Chen, W.; et al. 2021b. Open question answering over tables and text. In International Conference on Learning Representations.
- Chen, W.; et al. 2020b. Hybridqa: A dataset of multi-hop question answering over tabular and textual data. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 1026–1036.
- Christmann, P.; et al. 2022a. Beyond ned: Fast and effective search space reduction for complex question answering over knowledge bases. In Proceedings of the fifteenth ACM international conference on web search and data mining, pages 172–180.
- Christmann, P.; et al. 2022b. Conversational question answering on heterogeneous sources. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 144–154.
- Christmann, P.; et al. 2023. Explainable conversational question answering over heterogeneous sources via iterative graph neural networks. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 643–653.
- Christmann, P.; et al. 2024. Compmix: A benchmark for heterogeneous question answering. In Companion Proceedings of the ACM on Web Conference 2024, pages 1091–1094.
- Chuang, Y.-S.; et al. 2022. Diffcse: Difference-based contrastive learning for sentence embeddings. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4207–4218.
- Devlin, J.; et al. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.
- Gao, T.; et al. 2021. SimCSE: Simple contrastive learning of sentence embeddings. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 6894–6910, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Gao, Y.; et al. 2023. Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997.
- Hasibi, F.; et al. 2017. Dbpedia-entity v2: A test collection for entity search. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 1265–1268.
- Herzig, J.; et al. 2021. Open domain question answering over tables via dense retrieval. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 512–519.
- Hu, N.; et al. 2023. An empirical study of pre-trained language models in simple knowledge graph question answering. World Wide Web, 26(5):2855–2886.
- Izacard, G.; et al. 2022. Unsupervised dense information retrieval with contrastive learning. Transactions on Machine Learning Research.
- Izacard, G.; Grave, E. 2021. Leveraging passage retrieval with generative models for open domain question answering. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 874–880.
- Jia, Z.; et al. 2024. Faithful temporal question answering over heterogeneous sources. In Proceedings of the ACM on Web Conference 2024, pages 2052–2063.
- Jiang, Z.; et al. 2024. Longrag: Enhancing retrieval-augmented generation with long-context llms. arXiv preprint arXiv:2406.15319.
- Johnson, J.; et al. 2019. Billion-scale similarity search with gpus. IEEE Transactions on Big Data, 7(3):535–547.
- Karpukhin, V.; et al. 2020. Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6769–6781.
- Kong, K.; et al. 2024. Opentab: Advancing large language models as open-domain table reasoners. In The Twelfth International Conference on Learning Representations.
- Kostic, B.; et al. 2021. Multi-modal retrieval of tables and texts using triencoder models. In Proceedings of the 3rd Workshop on Machine Reading for Question Answering, pages 82–91.
- Kweon, S.; et al. 2023. Open-wikitable: Dataset for open domain question answering with complex reasoning over table. In Findings of the Association for Computational Linguistics: ACL 2023, pages 8285–8297.
- Kwiatkowski, T.; et al. 2019. Natural questions: A benchmark for question answering research. Transactions of the Association for Computational Linguistics, 7:453–466.
- Lewis, P.; et al. 2020. Retrieval-augmented generation for knowledge-intensive NLP tasks. CoRR, abs/2005.11401.
- Li, A.; et al. 2021. Dual reader-parser on hybrid textual and tabular evidence for open domain question answering. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 4078–4088.
- Li, C.; et al. 2023a. Making large language models a better foundation for dense retrieval. arXiv preprint arXiv:2312.15503.
- Li, X.; et al. 2022. Coderetriever: A large scale contrastive pre-training method for code search. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 2898–2910.
- Li, Z.; et al. 2023b. Structure-aware language model pretraining improves dense retrieval on structured data. In Findings of the Association for Computational Linguistics: ACL 2023, pages 11560–11574.
- Liu, Z.; et al. 2023. Retromae-2: Duplex masked auto-encoder for pre-training retrieval-oriented language models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics.
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦

















 504
504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









