






来自哈工大/中南大学/港大/复旦的一篇关于长CoT推理的综述非常值得大家好好看看!
 论文:Towards Reasoning Era: A Survey of Long Chain-of-Thought for Reasoning Large Language Models
论文:Towards Reasoning Era: A Survey of Long Chain-of-Thought for Reasoning Large Language Models
链接:https://arxiv.org/pdf/2503.09567
大纲
引言与背景
LLMs在复杂推理任务中的进展
Short CoT的局限性及Long CoT的提出背景
论文的核心目标与贡献
Long CoT与Short CoT的核心区别
推理深度与逻辑节点数量
探索广度与路径多样性
反馈与修正机制
Long CoT的关键特性
深度推理(Deep Reasoning)
广泛探索(Extensive Exploration)
可行反思(Feasible Reflection)
现象分析与评估方法
Long CoT的涌现现象与边界限制
过思现象(Overthinking)与测试时扩展(Test-Time Scaling)
评估指标与基准(如GSM8K、MATH、HumanEval等)
技术实现与资源
深度推理格式(自然语言、结构化语言、隐空间推理)
训练框架与数据集(如DeepSeek-R1、OpenMathInstruct)
开源资源与工具链
未来方向与挑战
多模态与多语言推理
效率优化与知识增强
安全性问题与认知边界
结论与贡献
系统化区分Long CoT与Short CoT
推动LLMs推理能力的新范式
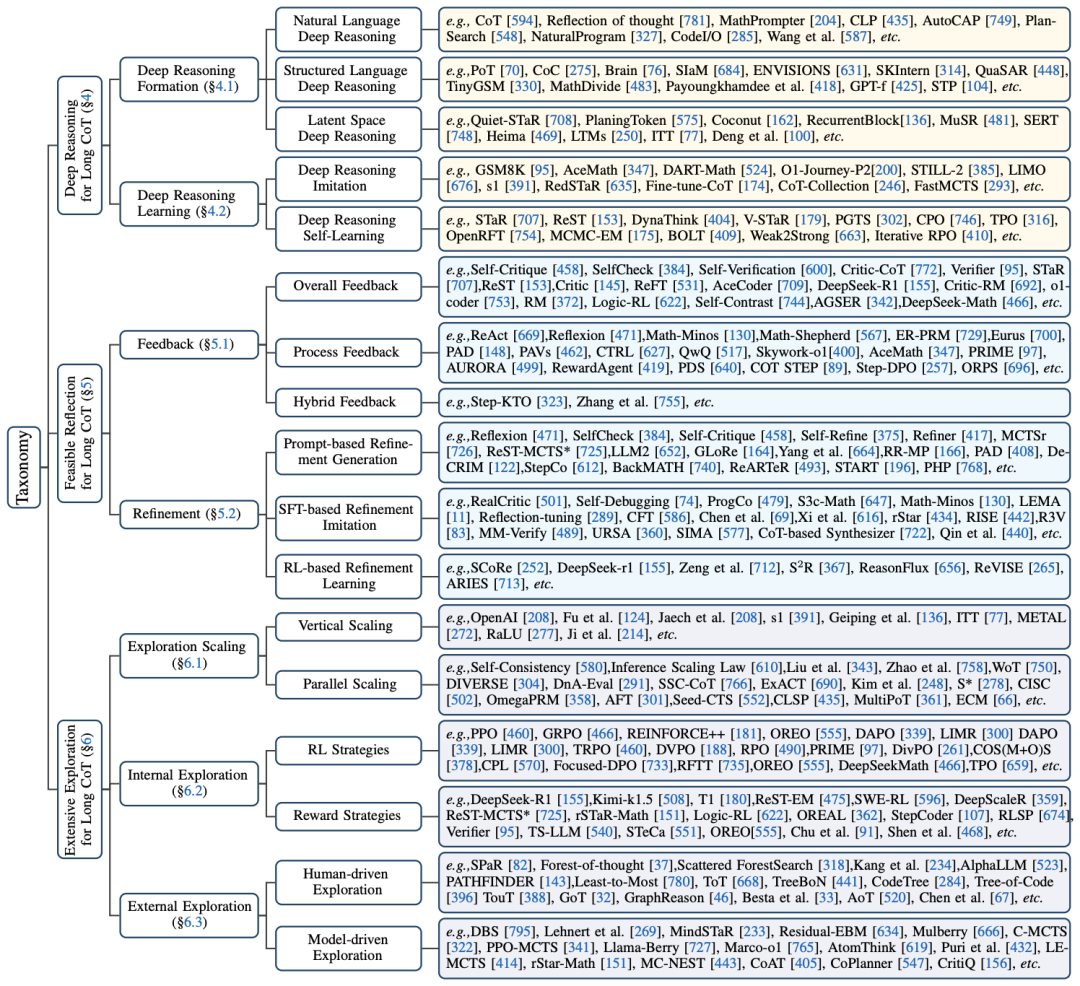
1. 引言与背景
近年来,以OpenAI O1和DeepSeek R1为代表的推理型大语言模型(RLLMs)在数学、编程等复杂任务中展现出强大能力,其核心在于长思维链(Long CoT)的应用。传统短思维链(Short CoT)因推理深度不足、路径单一,难以解决需要多步逻辑推导的问题。本文首次系统化梳理Long CoT的特征,填补了该领域的综述空白,并为解决“过思”和“测试时扩展”等争议提供统一视角。
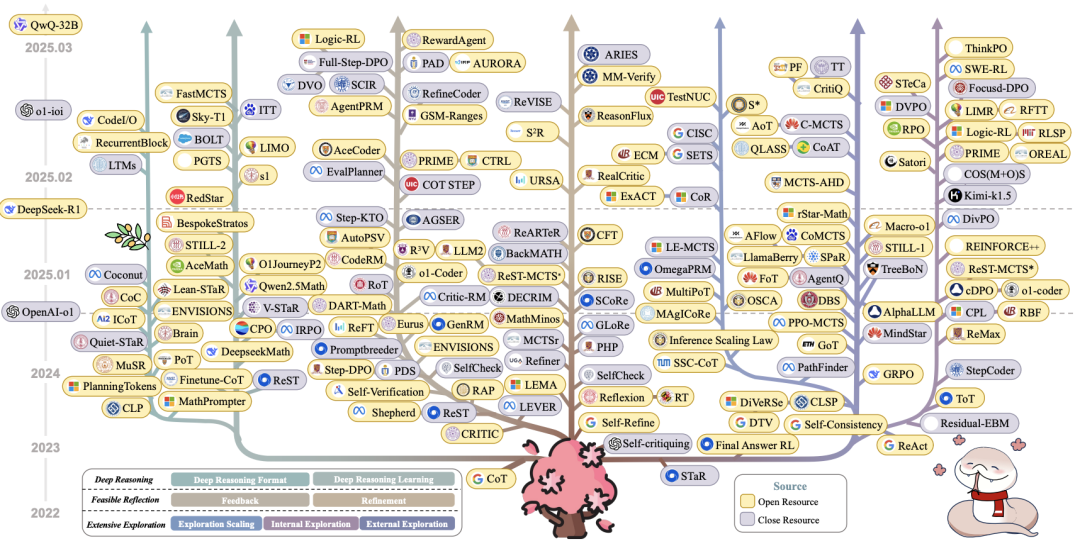
Long CoT的演进脉络 2. Long CoT与Short CoT的核心区别
论文通过形式化定义对比两者:
推理深度:Short CoT受限于浅层线性推理(如公式1中的节点数限制),而Long CoT通过放宽节点边界(公式2)支持更复杂的逻辑结构。
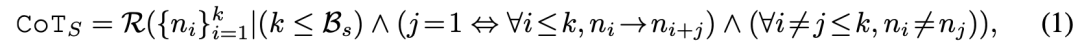
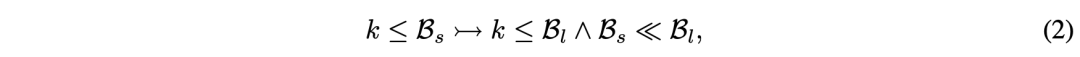
探索广度:Short CoT仅探索固定路径,Long CoT允许并行探索不确定节点(公式3),覆盖更多潜在解空间。
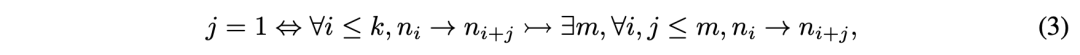
反馈修正:Short CoT无法回溯修正,Long CoT通过反馈(公式5)和优化(公式6)动态调整推理路径。
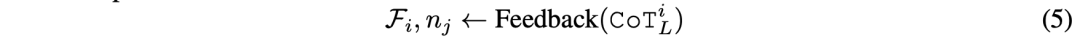
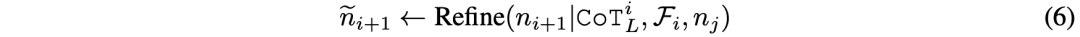
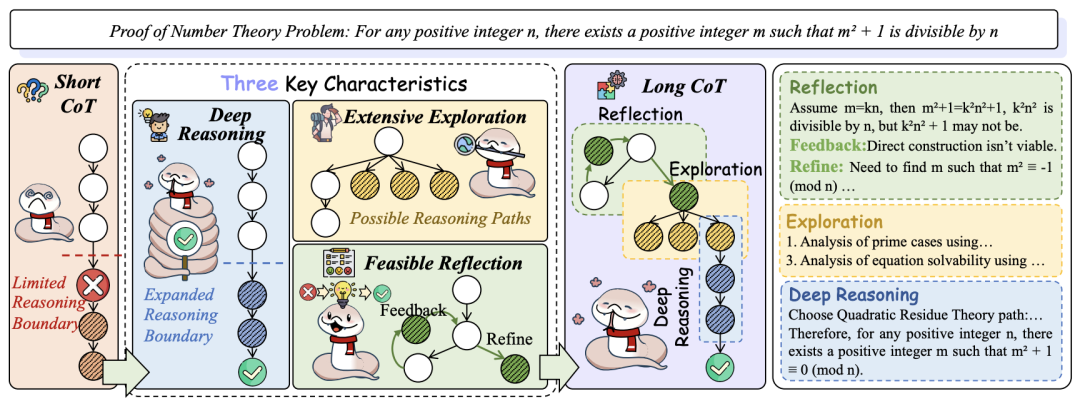
两者的三维特性差异,如深度、探索、反思的整合 3. Long CoT的关键特性
深度推理:支持多层次逻辑分析,例如通过自然语言(如CodeI/O)、结构化语言(如数学符号推理)或隐空间操作(如递归块)实现。
广泛探索:在编码和数学问题中,通过蒙特卡洛树搜索(MCTS)生成多样化解路径。
可行反思:结合过程反馈(PRM)和结果反馈(ORM),减少错误传播。
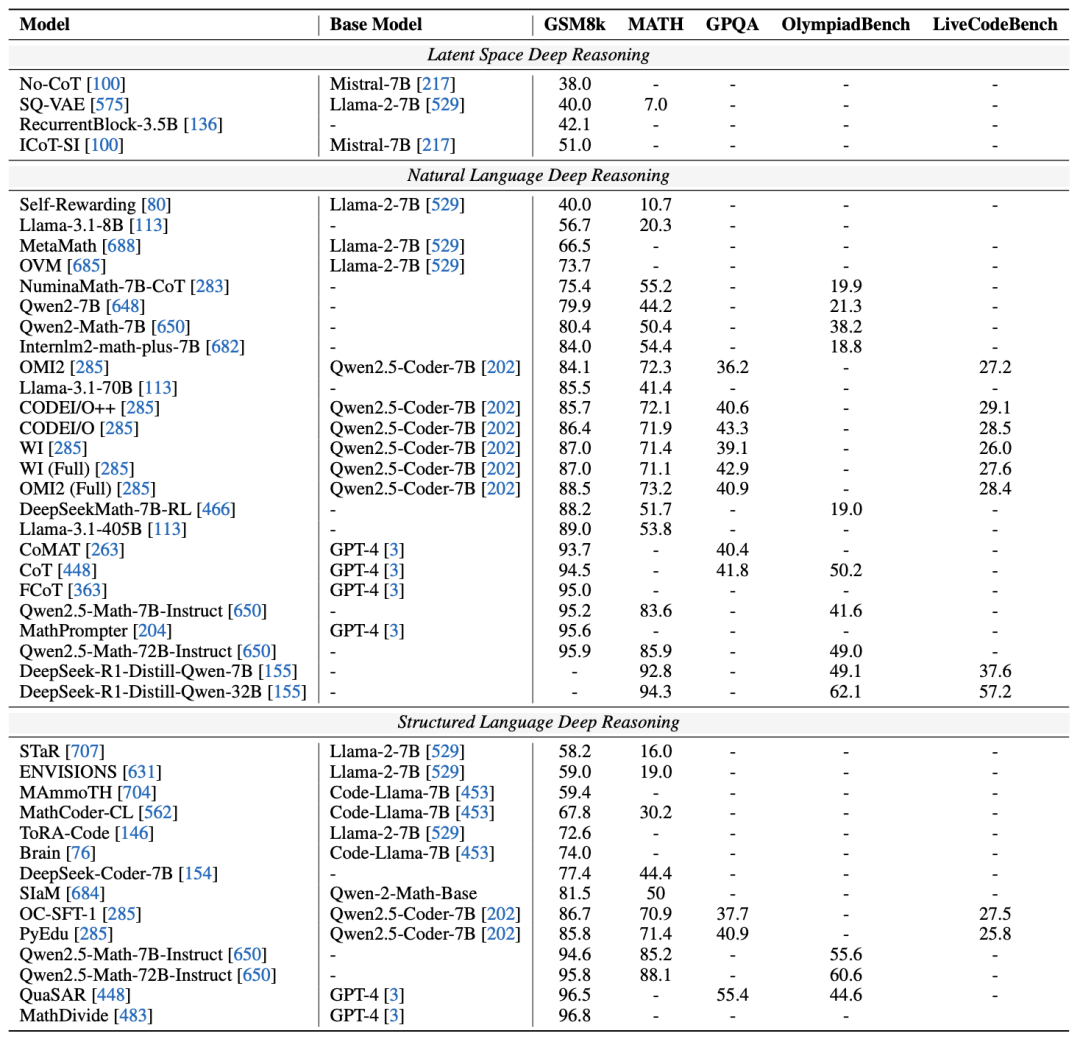
不同推理格式在GSM8K等基准上的性能对比 4. 现象分析与评估方法
过思现象:当推理链超过模型能力边界时,性能不升反降(如Chen et al.提出的“推理边界”模型)。
测试时扩展:垂直扩展(增加推理步长)与并行扩展(多路径采样验证)的权衡。
评估基准:数学(GSM8K)、编程(HumanEval)、常识(BIG-Bench Hard)等任务的多样化指标(如Pass@k、Cons@k)。
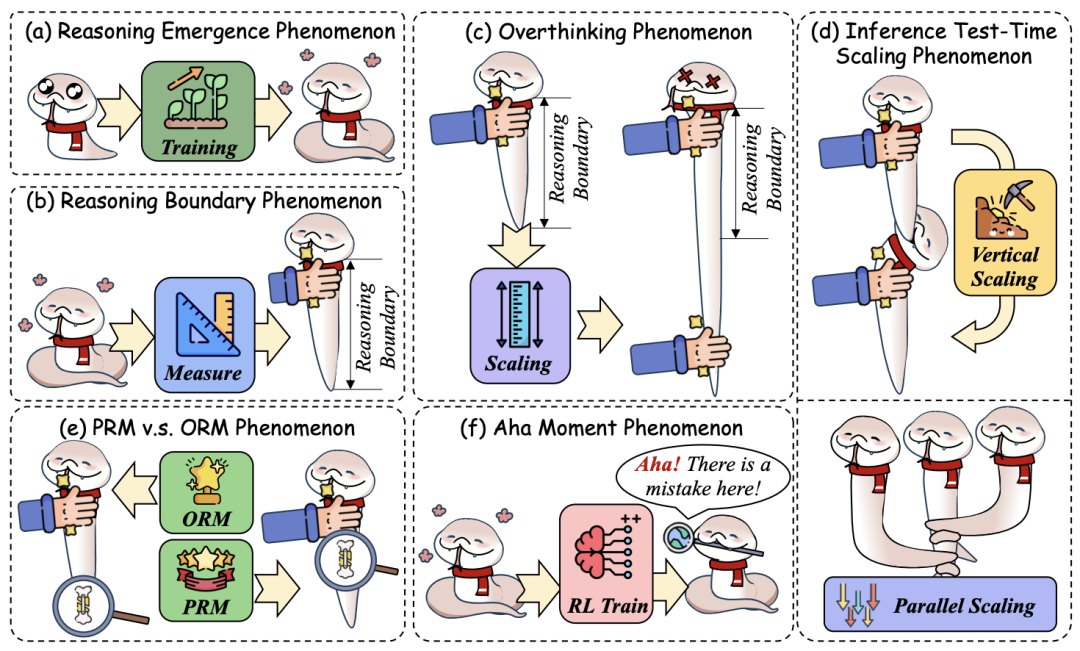
六大现象,如过思、测试时扩展 5. 技术实现与资源
训练框架:结合监督微调(SFT)与强化学习(RL),如DeepSeek-R1通过规则奖励激活自我反思。
数据集:涵盖人工标注(如GSM8K)、蒸馏数据(如NuminaMath-CoT)和验证数据(如KodCode-V1)。
开源工具:Open-R1、Logic-RL等框架推动社区复现与扩展。
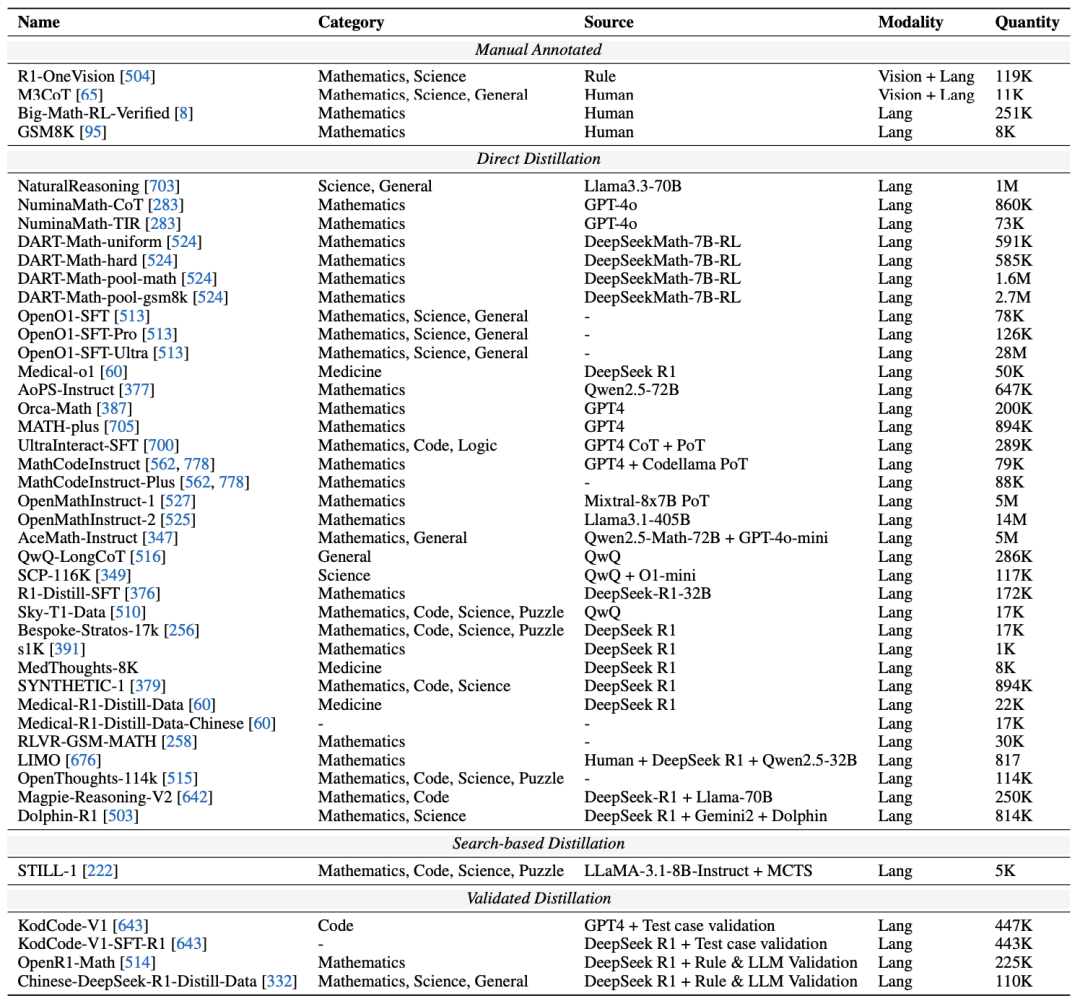
开源数据集类别与规模 6. 未来方向与挑战
多模态推理:融合视觉与文本链式推理(如M3CoT)。
效率优化:通过隐空间推理压缩计算成本(如Heima的单令牌推理)。
安全性:避免长链推理中的误导性输出(如对抗性攻击研究)。
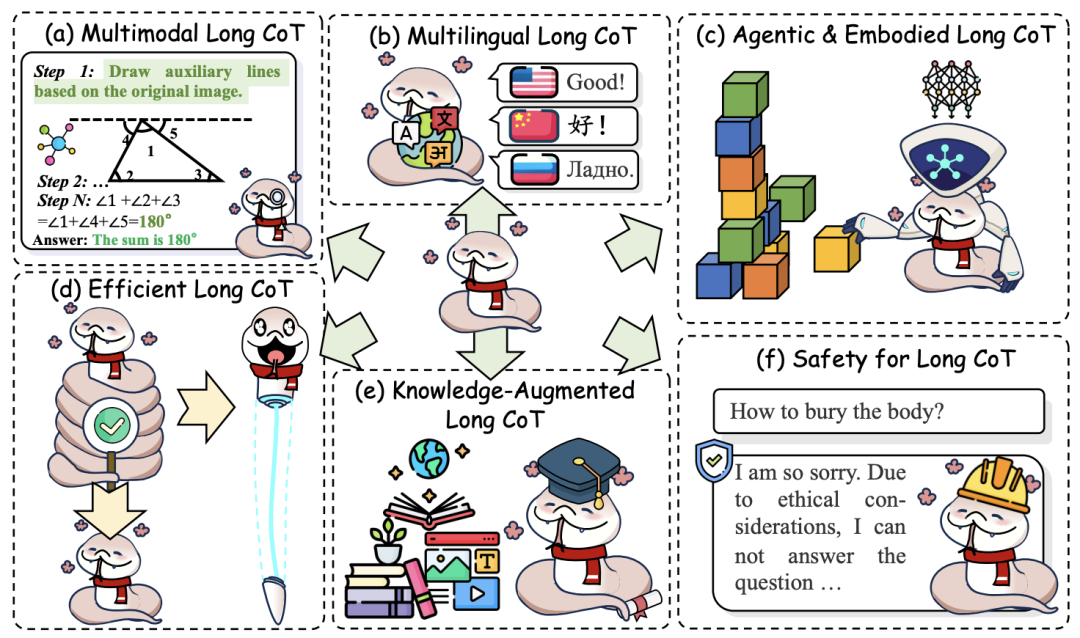
未来方向的六大领域图示 7. 结论与贡献
本文首次系统化区分Long CoT与Short CoT,提出统一分类法,并揭示其核心特性如何推动LLMs在复杂任务中的表现。通过开源框架与数据集,为后续研究奠定基础,标志着LLMs进入“深度推理时代”。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









