






算是咱们领域最近的一个新闻:强化学习的“评分标准”升级了!过去,LLM学数学、写代码时,系统只能根据“答案对不对”给个简单对错分。
论文:Crossing the Reward Bridge: Expanding RL with Verifiable Rewards Across Diverse Domains
链接:https://arxiv.org/pdf/2503.23829
但现在,来自腾讯AI Lab和苏大的研究者搞了个Expanding RLVR(可验证奖励强化学习) Across Diverse Domians,让模型能像人类老师一样,给医学、经济学甚至心理学问题的答案打“软分数”——比如“这个回答80%正确,但漏了一个关键点”。
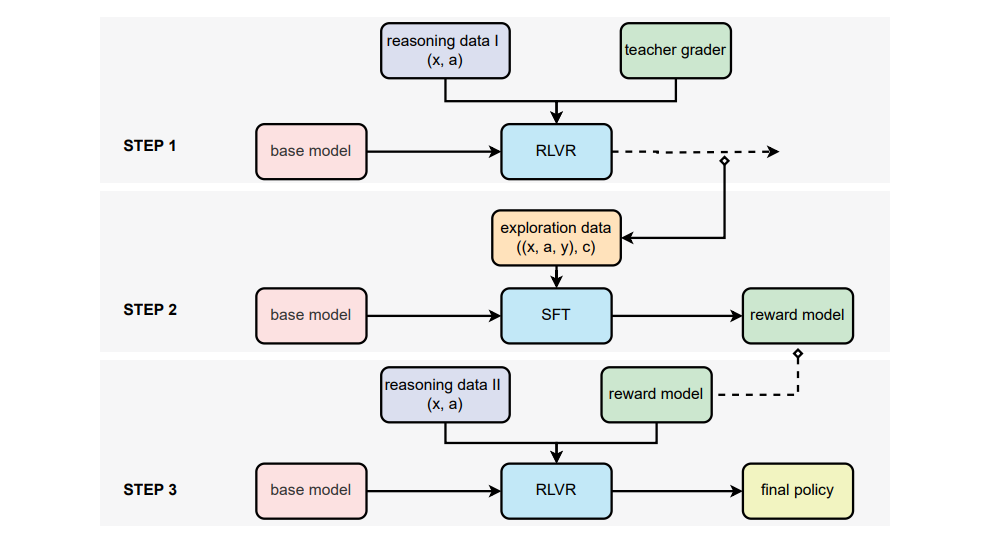
核心突破:让强化学习跨越学科边界
论文最牛的地方,是让RLVR走出了数学和编程的“舒适圈”。
以往,LLM只能在有标准答案的领域(比如1+1=2)自我训练,但现实中的问题往往是开放式的:比如“如何设计一个心理疏导方案?”或“分析某经济政策的长期影响”。这类问题没有唯一答案,传统RL直接懵圈。
而这篇论文通过两个关键操作破局:
专家参考答案:即使答案很长很复杂,只要有专家写的参考答案,模型就能学习对比;
生成式评分模型:用一个小型LLM(7B参数)当“评分老师”,直接生成0-1之间的“软分数”,而不是死板的对错。
亮点:用“软奖励”替代“对错二分法”
传统方法就像“判断题”,答案要么对(1分)要么错(0分)。但现实中,很多答案可能部分正确。
比如医学诊断:“患者可能是肺炎,建议做CT” vs “患者是肺炎,需立即手术”——前者不够完整,但不算全错。
论文提出的“软奖励”模型,能根据参考答案生成连续分数(比如0.7分),让AI更细腻地学习。更绝的是,这个评分模型只需7B参数(对比GPT-4的万亿参数),训练数据也只用16万条,成本低到离谱!
(具体RL细节还是看论文吧~)
实验:小模型逆袭,性能吊打巨头
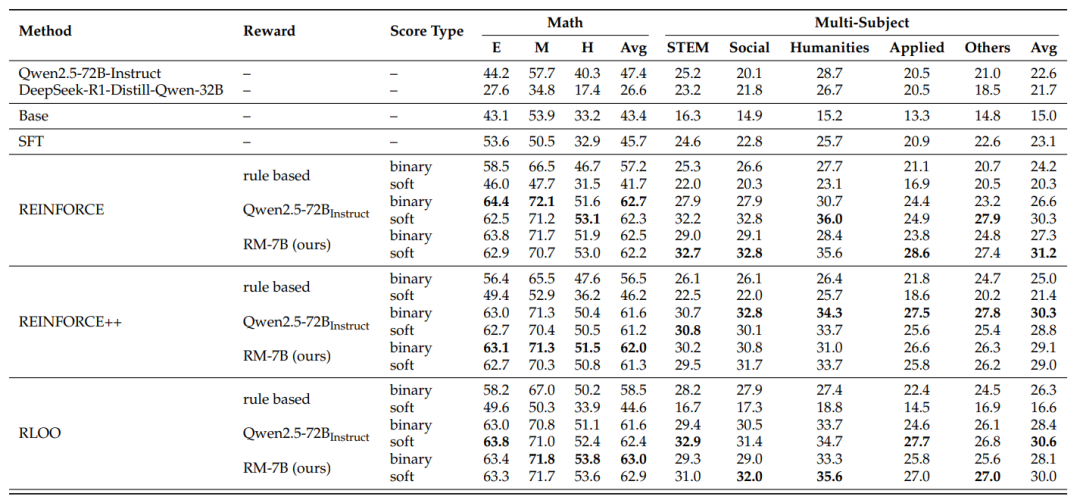
论文实验可总结如下:
数学题:7B小模型用RLVR训练后,正确率比720亿参数的Qwen2.5还高8%;
跨学科题(医学、法律等):在“自由发挥”的答案场景下,小模型直接碾压传统方法。
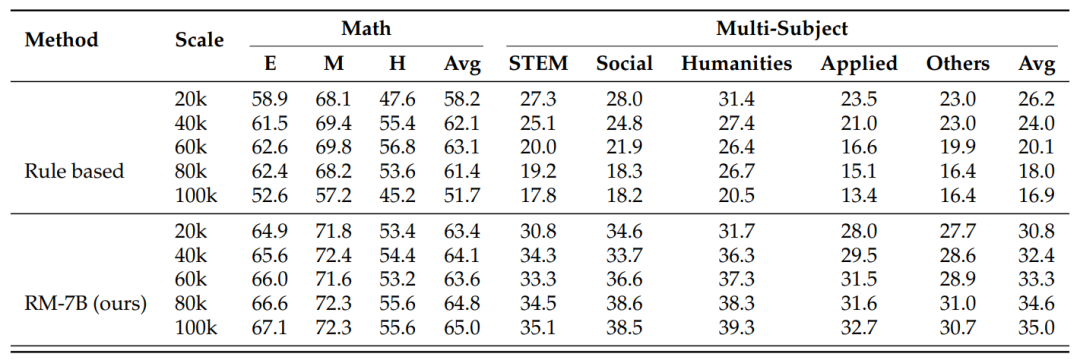
更狠的是,数据量越大,小模型表现越好,而传统方法反而会“学崩”。

不小的行业影响
这项研究的意义远超技术本身:
低成本落地:小模型+少数据就能训练,企业不用烧钱买算力;
跨领域通用:未来AI可能在医疗诊断、法律咨询、教育辅导等领域“自学成才”;
抗干扰性强:即使参考答案有噪声(比如专家写错了),模型也能稳健学习。
论文甚至开源了57万条多领域数据集,堪称业界良心!
数据集:https://huggingface.co/collections/virtuoussy/rlvr-67ea349b086e3511f86d1c1f
总结一下下
用大模型当“陪练”:训练时先用720亿参数的Qwen生成评分数据,再让小模型“偷师”;
反向操作:传统RL怕数据噪声,他们反而用带噪声的数据训练,结果模型更抗造;
隐藏福利:所有代码和模型已开源,普通人也能上手玩!
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









