






老话常谈,推理模型的“过度思考”是什么?比如解一道数学题,它明明已经算对了,却还在反复验算,甚至尝试其他方法。这就是论文提到的“过度思考(Overthinking)”现象。
论文:Reasoning Models Know When They’re Right: Probing Hidden States for Self-Verification
链接:https://arxiv.org/pdf/2504.05419v1
现有的大模型(如DeepSeek-R1、GPT-4等)虽然擅长数学和逻辑推理,但总爱“多此一举”,导致计算资源浪费。例如,解决一个方程可能需要生成几十步推理链,但正确答案可能在第5步就出现了。
关键问题:模型能知道自己算对了吗?能否及时停止“无效劳动”?
核心发现:模型隐藏状态中藏着答案正确性的“直觉”!
论文发现,模型的隐藏状态(Hidden States)就像一个“内心独白”,偷偷记录了答案是否正确。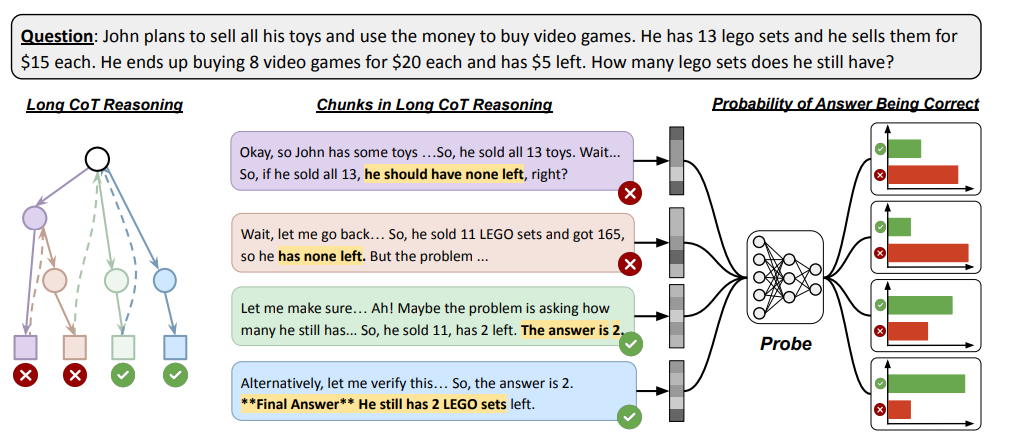 通过训练一个简单的“探针”(类似体检仪器),研究者发现:
通过训练一个简单的“探针”(类似体检仪器),研究者发现:
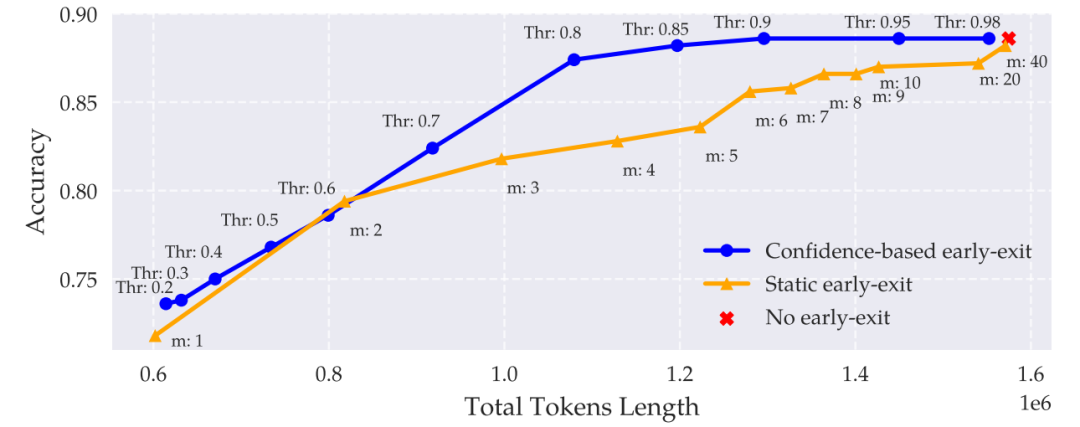
高准确率:探针预测中间答案正确性的准确率超过80%(ROC-AUC >0.9)。
提前预判:模型甚至在答案完全生成前,隐藏状态就已暴露正确性信号!
类比:就像学生考试时,刚写完答案就隐约感觉“这题对了”,但还要再检查几遍。
方法:如何用“探针”检测模型的“自我验证”能力?
研究团队设计了一套流程:
切分推理链:将长推理过程按关键词(如“再检查”“另一种方法”)分割成多个片段。
标注正确性:用另一个LLM(Gemini 2.0)自动判断每个片段的答案是否正确。
训练探针:用两层神经网络分析模型隐藏状态,预测答案正确性。
关键公式(2层MLP+激活函数):
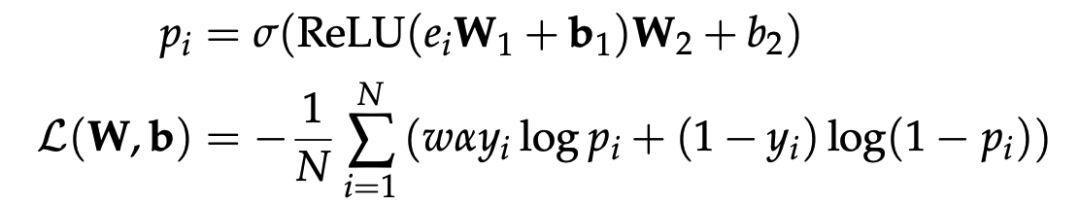
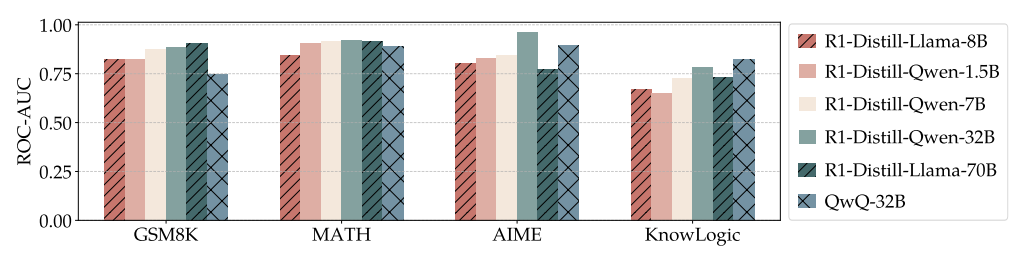
实验:模型能提前预判,还能少干活不降准!
预测能力:
数学题(如MATH数据集)的预测准确率最高(ROC-AUC >0.9)。
逻辑题稍弱,但依然可靠(ROC-AUC >0.7)。
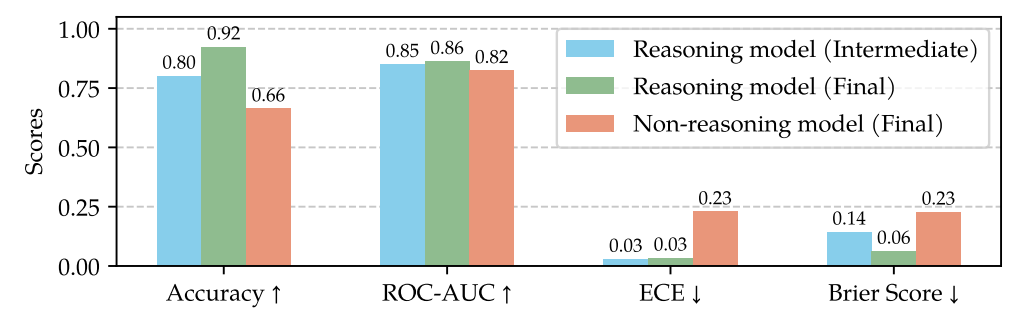
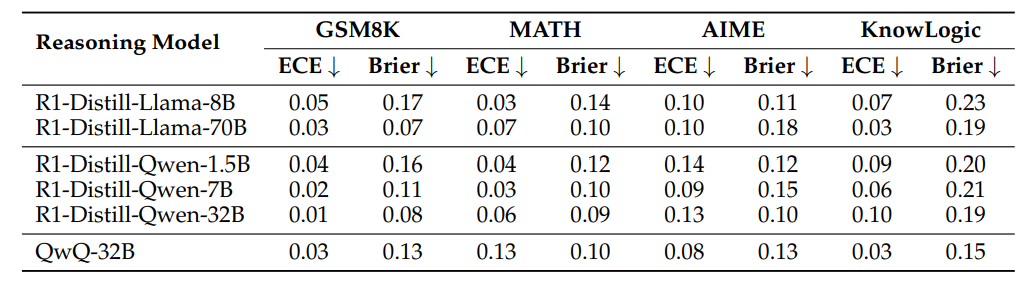
提前退出策略:当探针判断某一步答案正确性超过阈值(如85%),直接终止推理。
结果:节省24%计算量,准确率几乎不变!
应用价值还是有的
省钱:更少的计算量意味着更低的API调用成本。
省时:实时应用(如客服、教育)响应更快。
潜力:未来可结合强化学习,让模型自主决定何时停止推理。
未来展望
自我反思:模型能否像人类一样,主动修正错误?
跨领域:能否将这种能力迁移到编程、医疗诊断等场景?
欠思考:如果模型“太自信”提前退出,会不会漏掉关键步骤?
一天一个进展,真的进展迅猛啊~ (看不过来了~
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









