






为什么语言模型推理能力的评估「水分」这么大?
近几年,ChatGPT、Claude等大模型的「数学解题」「逻辑推理」能力突飞猛进,各大实验室争相发布「突破性成果」。但论文一针见血地指出:很多所谓的进步,可能只是评测标准不统一导致的假象!

论文:A Sober Look at Progress in Language Model Reasoning: Pitfalls and Paths to Reproducibility
链接:https://arxiv.org/pdf/2504.07086
比如,同一道数学题,模型答案的正确率可能因为以下「玄学因素」剧烈波动:
随机种子:就像抽奖的运气,换一个随机数,正确率能差10%以上
温度参数:模型答题是「保守」还是「放飞自我」,结果天差地别
硬件配置:用不同的GPU跑同一模型,正确率能差8%
提示词格式:加不加「请仔细思考」这句话,可能让结果直接崩盘
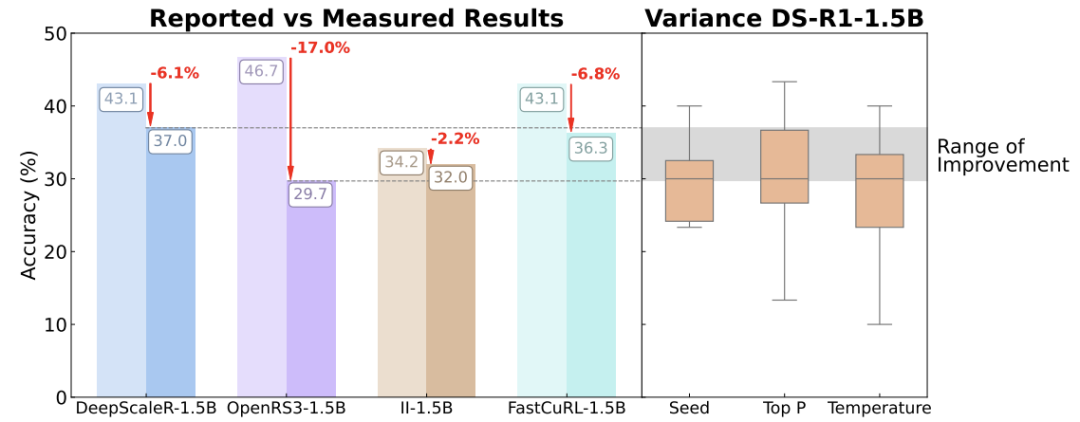
更夸张的是,许多论文评测时只用30道题的小数据集(如AIME’24)。这种情况下,多答对1题就能让正确率提升3%,导致结果毫无说服力。
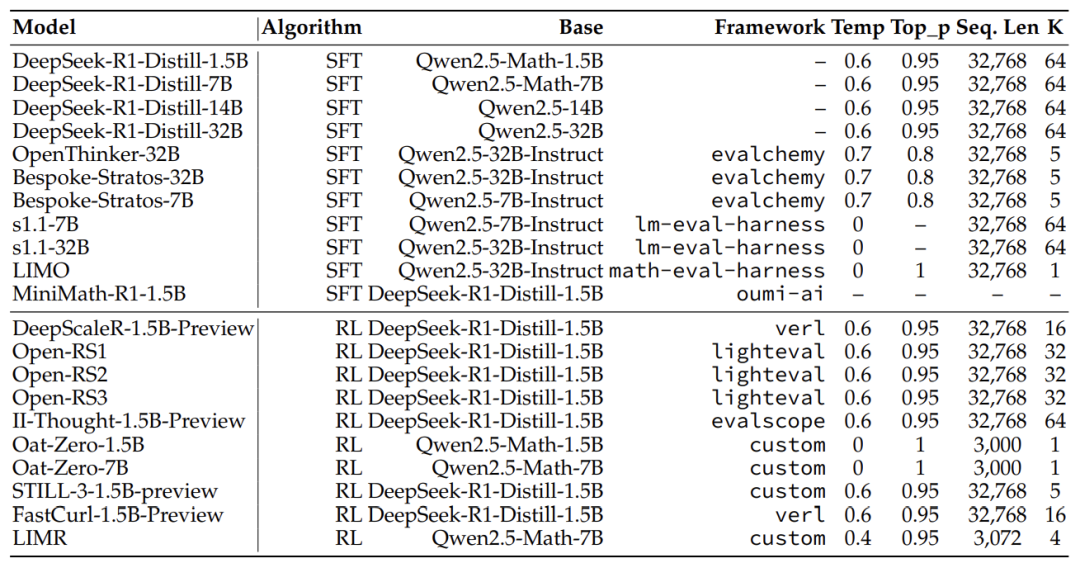
实验:连硬件和标点符号都能影响结果?
为了验证这些「玄学因素」,作者做了大量实验:
随机种子实验:用20个不同的随机种子测试模型,发现正确率波动最高达15%
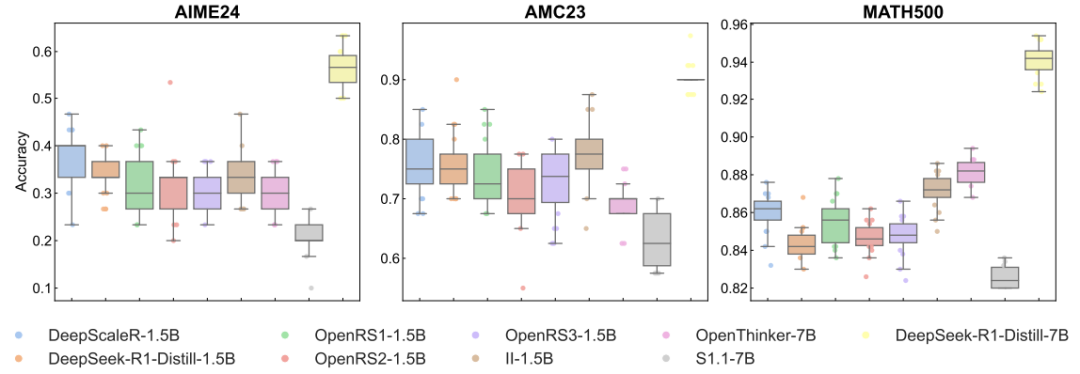
温度参数对比:温度调高(模型更「放飞」),正确率可能提升,但波动也更大
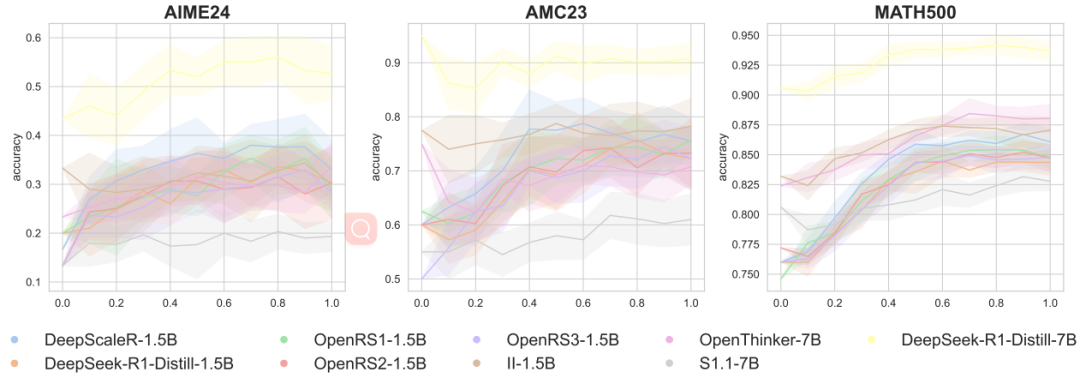
硬件差异:同一模型在不同GPU集群上跑,正确率差异堪比模型升级
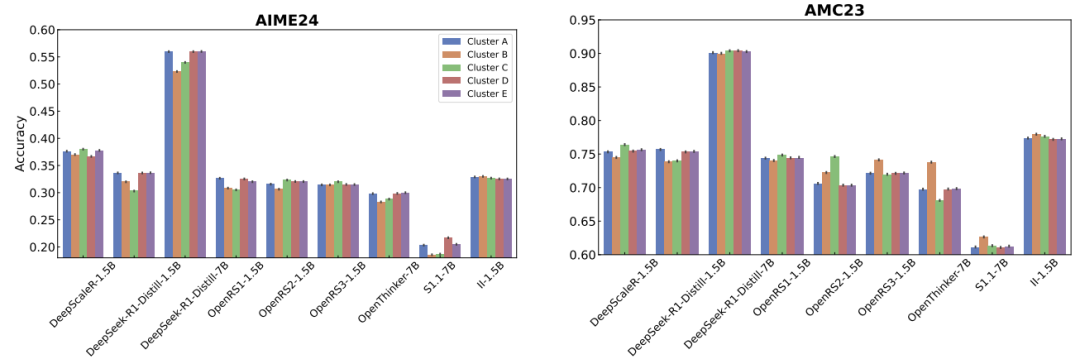
提示词格式:用错聊天模板,指令微调模型的性能直接「腰斩」
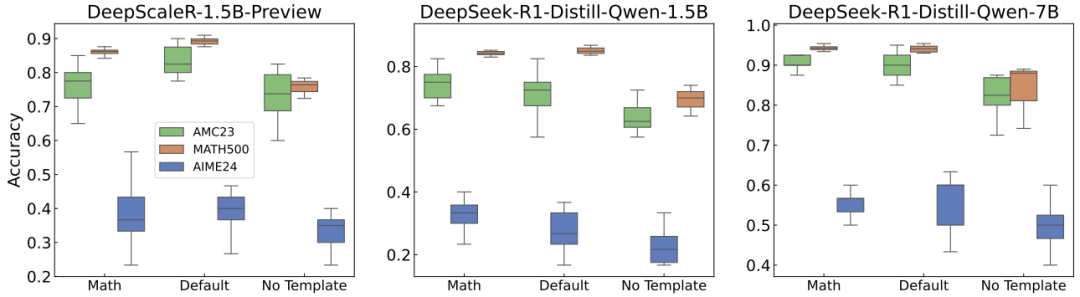
最讽刺的是,某些论文宣称的「RL方法提升10%」,在统一评测标准后,实际改进连统计显著性都没有。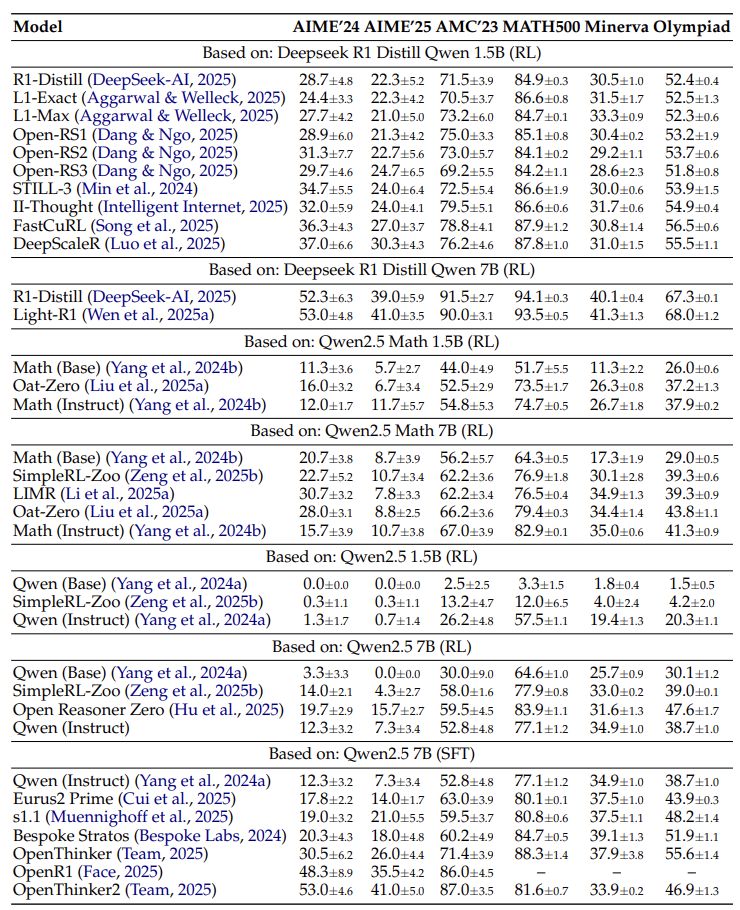
强化学习(RL)进步是假,监督微调(SFT)才是真神?
论文最颠覆的结论是:当前强化学习(RL)对推理能力的提升被严重高估,而监督微调(SFT)才是「低调的实力派」。
RL的尴尬:
在蒸馏模型(如DeepSeek-R1)上,RL训练几乎无提升,甚至可能过拟合小数据集(如AIME’24)。
换到新数据集(如AIME’25),RL模型的性能直接「跳水」。
SFT的稳定:
用高质量解题步骤数据做监督微调,模型在多个基准上表现稳定,且能泛化到新任务(如OlympiadBench)。
例如,OpenThinker模型在标准化评测中全面碾压RL方法。
论文甚至调侃:「RL训练像买彩票,SFT才是存定期」。
如何让评测不再「玄学」?
作者提出一套「防坑指南」,呼吁行业统一标准:
硬件软件标准化:所有实验用同一Docker镜像和云服务器(如Runpod的A100)。
多随机种子测试:小数据集至少跑10次取平均,避免「运气好」导致的虚高结果。
超参数调优:每个模型单独调温度、top_p等参数,不能「一刀切」。
答案匹配优化:用LaTeX解析答案,避免字符串匹配的「格式投机」(如
\boxed{2}和2算同一答案)。
此外,作者开源了所有代码、提示词和模型输出,号召「阳光评测,拒绝黑箱」。
这篇论文给行业泼了什么冷水?
给研究者的提醒:别再「刷榜」了!追求SOTA(最高性能)前,先确保结果可复现。
给企业的启示:RL训练成本高、收益低,不如扎扎实实做SFT数据。
给用户的真相:模型宣传的「推理能力提升」,可能只是评测游戏的胜利,而非真实进步。
论文最后呼吁:「AI推理的进步,需要方法论先行,而非论文数量竞赛」。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









