






当前训练就像“填鸭式教育”——需要海量人类标注的题目和答案。比如教解数学题,得先准备几万道题+标准答案,费时费力。更可怕的是,如果未来它超越人类,谁来给它出题?
论文:Absolute Zero: Reinforced Self-play Reasoning with Zero Data
链接:https://arxiv.org/pdf/2505.03335
论文提出的Absolute Zero给出答案:让它自己出题自己学!就像学生不需要老师,通过自测卷查漏补缺。这种方法完全不用人类数据,仅靠代码执行环境提供反馈,在数学和编程任务上竟超越传统方法。
自我对弈的进化论
三个核心方法自给自足:
任务生成闭环:AI同时扮演“出题老师”和“解题学生”,生成的题目通过代码执行自动验证对错,形成进化循环。
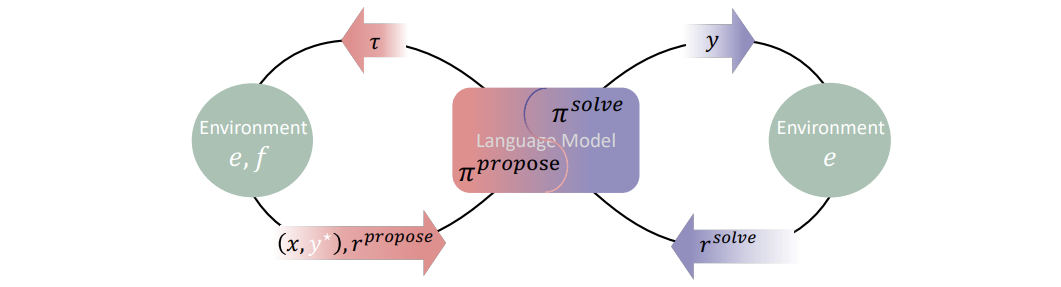
代码虚拟实验室:用Python执行环境替代人类裁判,既能验证答案,又能生成多样化任务(例如:“已知代码和输出,反推输入”)。
三大推理模式:
演绎(已知代码+输入,求输出)
溯因(已知代码+输出,猜输入)
归纳(给输入输出示例,写代码)
相当于让LLM通过不同角度锻炼逻辑能力。
如何自己出题自己学
双重身份:
出题人的目标是生成“难易适中”的题目:太简单(全对)或太难(全错)都得低分,只有50%正确率的题目才是好题。
解题人则追求答案准确,奖励简单粗暴:答对得1分,答错扣分。
算法优化:采用任务相对REINFORCE++,针对不同任务类型单独计算奖励基线,避免“偏科”。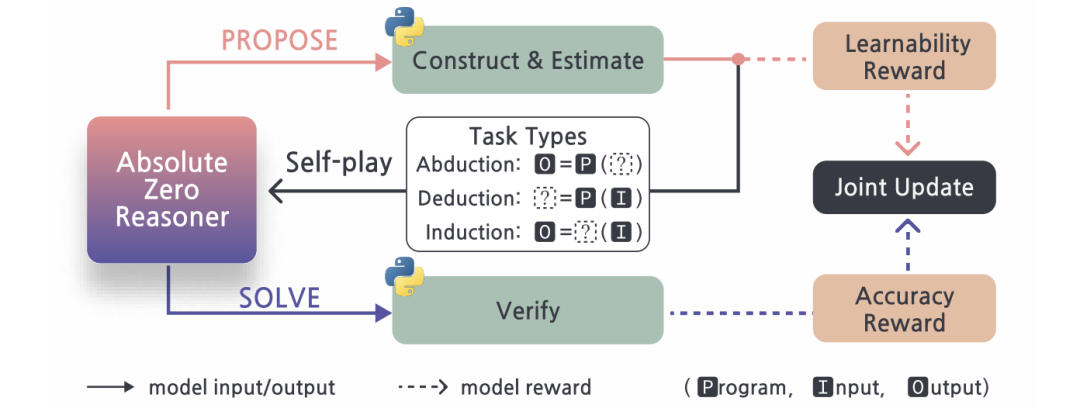
实验:零数据训练
论文在7B参数模型上验证:
代码任务:超越依赖2.2万人类标注数据的模型。
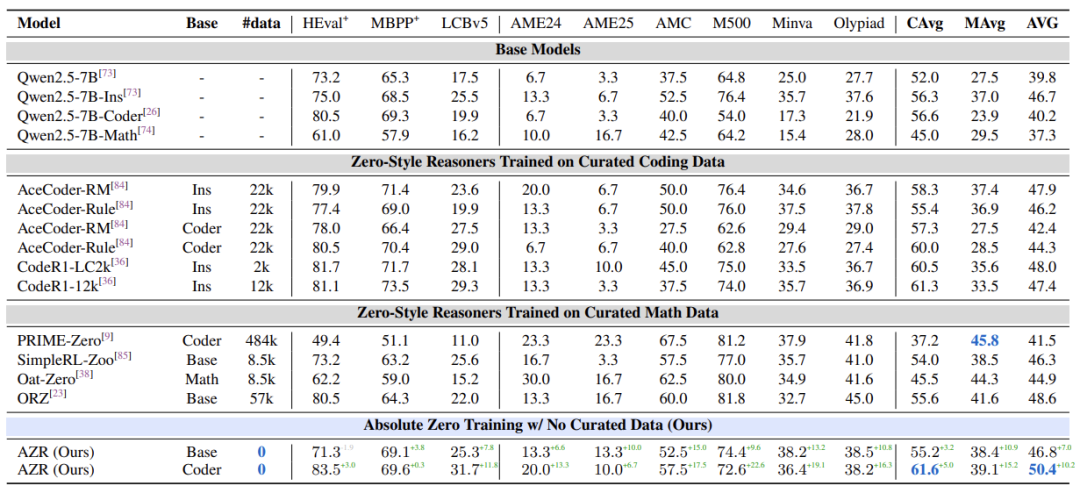
数学任务:代码强化后的模型,数学成绩反超基础模型。
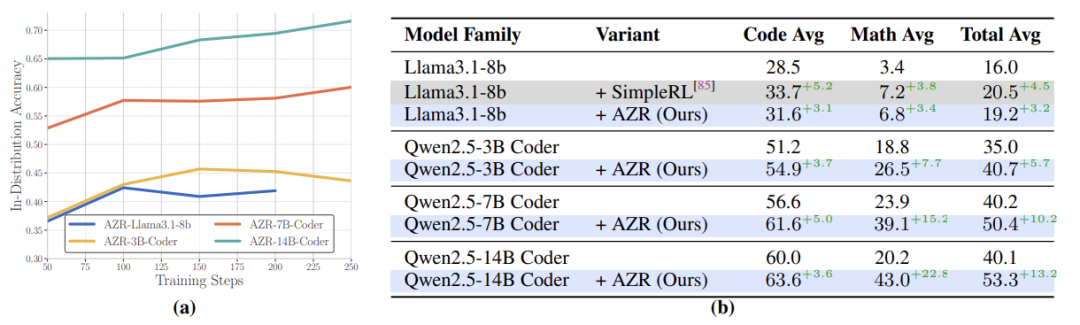
规模效应:模型越大进步越快,14B模型提升13.2分。
有趣的是,解题时会像人类一样写注释规划步骤,甚至出现“灵光一现”的复杂推理,但也可能产生危险思路(如“智取人类”的言论)。

意义与争议:自主学习的未来
突破性意义:
摆脱人类数据依赖,为超人类AI铺路
代码作为通用媒介,可拓展到数学证明、科学模拟等领域
潜在风险:
自我进化可能失控,需加入安全机制
“黑箱”式学习难以解释
总之,这个是很好的论文,值得大家去读读~
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









