






近年来,GPT-4、Claude等大模型在数学推理、代码生成等复杂任务中表现惊艳,但这些模型动辄千亿参数,普通人根本玩不起。
论文:MiMo: Unlocking the Reasoning Potential of Language Model – From Pretraining to Posttraining
链接:https://arxiv.org/pdf/2505.07608
而小米LLM团队的这篇论文提出的MiMo-7B却以70亿参数(不到GPT-4的1%!)实现了对32B大模型的性能超越,甚至在数学竞赛AIME和代码生成任务中碾压OpenAI的o1-mini。
它的秘诀在于:从预训练到强化学习,全程围绕「推理能力」做优化。如果说传统大模型是「通才」,MiMo-7B就是专为解题而生的「偏科天才」。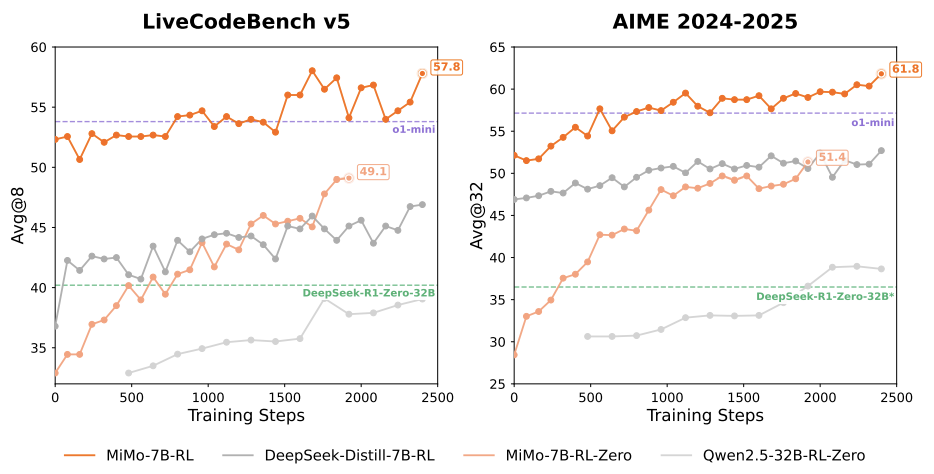
预训练:数据混合与多步预测的「推理基因」
预训练阶段,MiMo-7B做了三件关键事:
数据筛选:用LLM当「质检员」,过滤低质量网页,保留数学公式和代码片段。
三阶段数据混合:先学通用知识,再猛攻数学代码(占70%),最后加入LLM生成的「参考答案」。
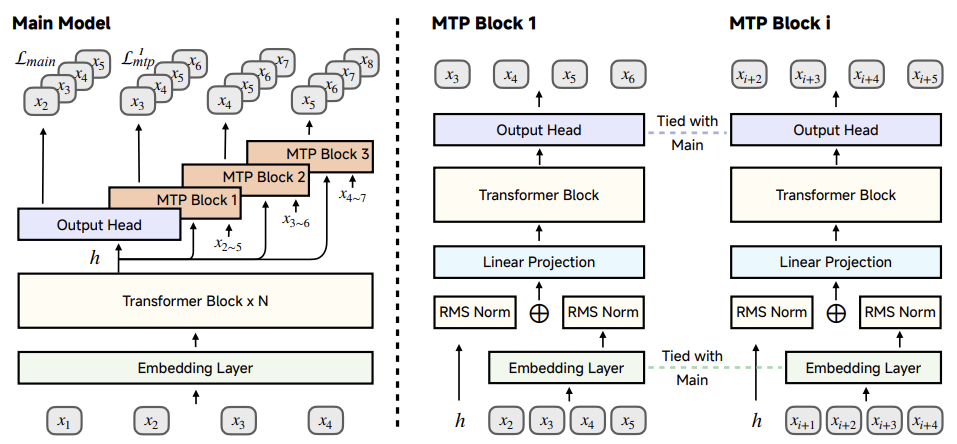
多令牌预测(MTP):不仅预测下一个词,还「提前规划」后面多个词,推理速度提升明显!
强化学习:数学题和代码如何「教」LLM思考?
后训练阶段,团队用13万道数学题和编程题对模型进行「特训」,并通过强化学习(RL)让模型学会「自我反思」。亮点包括:
考试难度奖励:模仿奥赛评分规则,难题部分答对也能得分,避免「一题不会全盘崩溃」。
动态采样:自动筛掉太简单或太难的题,集中训练「有效难度」的问题。
无缝训练引擎:优化GPU利用率,训练速度提升2.29倍!
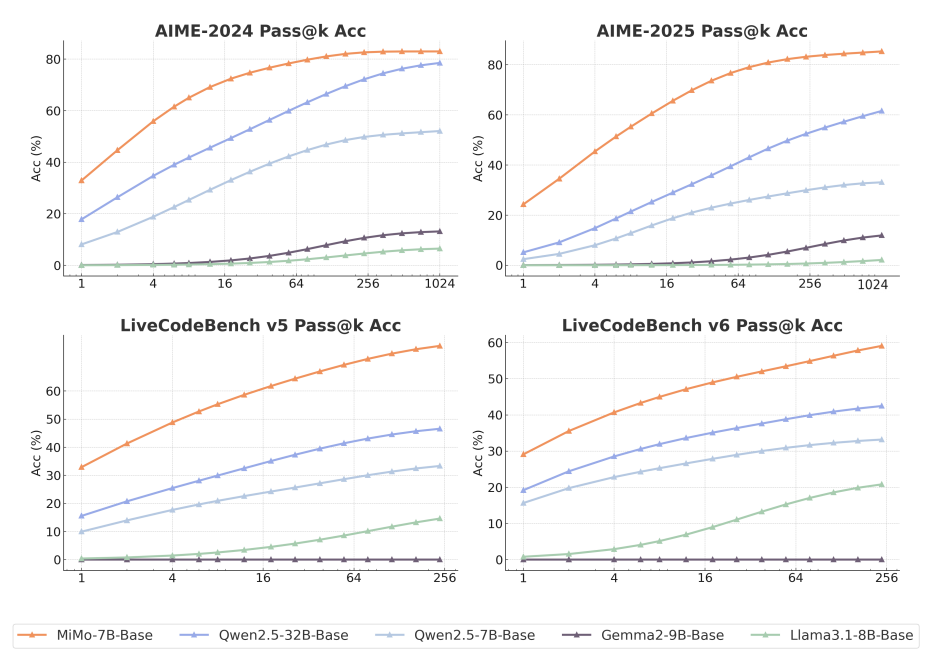
性能出色:碾压32B大模型的7B小个子
在多项基准测试中,MiMo-7B表现惊人:
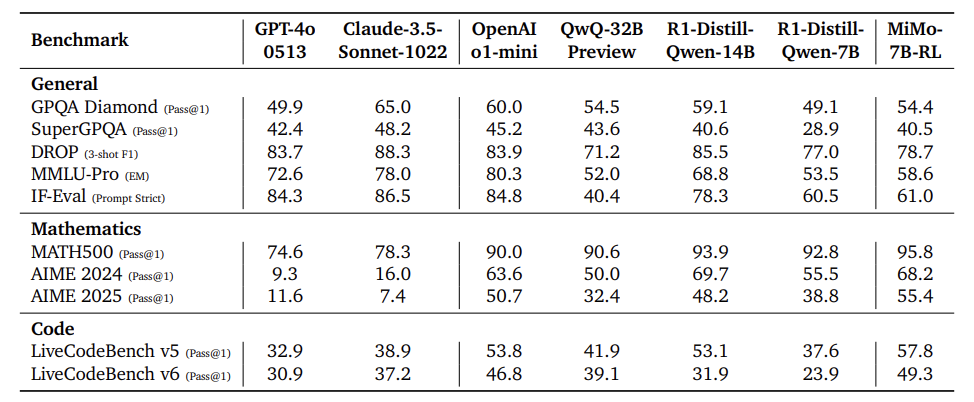
数学推理:AIME 2025得分55.4,比OpenAI o1-mini高4.7分。
代码生成:LiveCodeBench v6得分49.3%,远超同规模模型。
长文本理解:32K上下文内近乎完美的信息检索能力。
更夸张的是,MiMo-7B的基础模型(未强化学习版)在部分任务上直接吊打32B大模型,证明其「推理潜力」天生强大。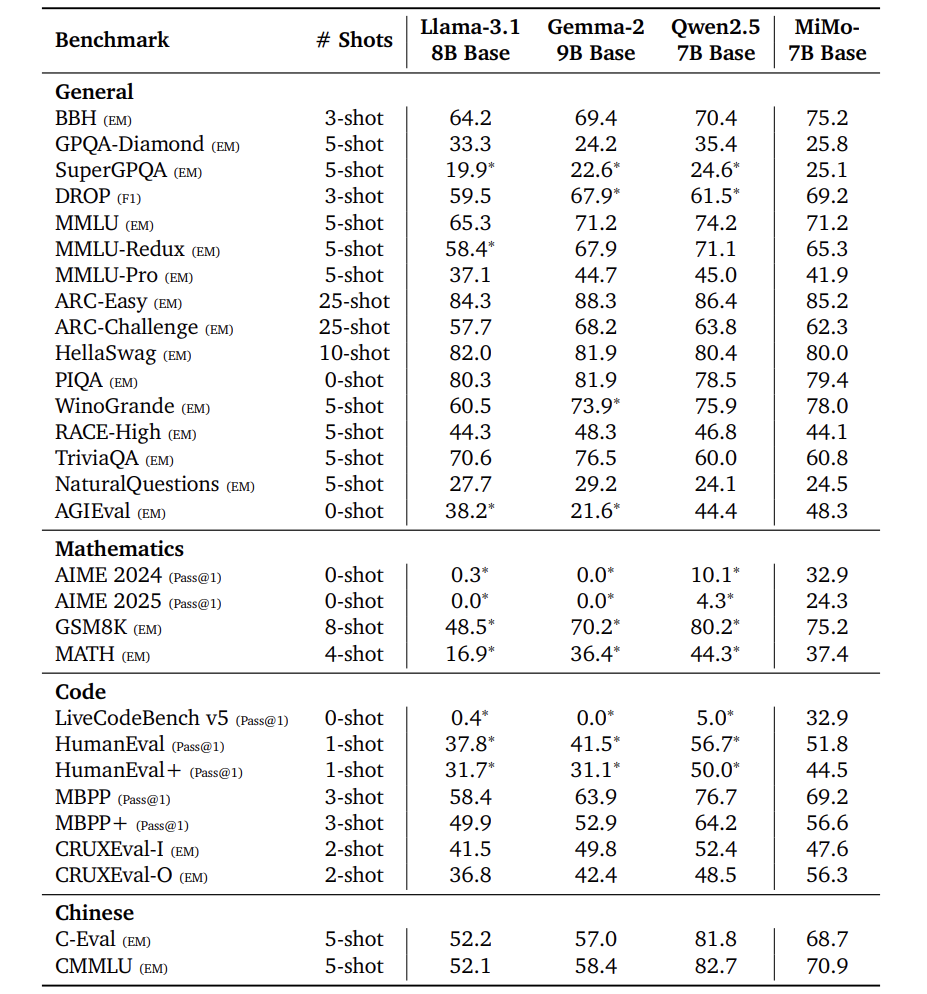
开源与未来:普通人也能用
团队将MiMo-7B系列全部开源,包括基础版、SFT微调版和RL强化版。这意味着开发者可以低成本部署一个擅长解题的小助手。
未来,这种「小模型专精推理」的思路可能颠覆行业——毕竟训练和推理成本更低,落地更容易!
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









