






在大型语言模型(LLMs)横扫NLP任务的时代,模型的推理路径却依然是一团迷雾。面对复杂问题,LLMs是凭“记忆”说话,还是靠“推理”得出结论?我们能不能把这两者解耦,从而获得更可控、更可靠的模型行为?

论文:Disentangling Memory and Reasoning Ability in Large Language Models
链接:https://arxiv.org/abs/2411.13504
代码:https://github.com/MingyuJ666/Disentangling-Memory-and-Reasoning
录用:ACL 2025 main
欢迎引用、扩展、基于此构建更可控、更可信的大模型推理系统!
在本项研究中,我们提出了一个创新性的训练范式 —— “记忆-推理解耦框架”(Disentangling Memory and Reasoning)。我们引入两个显式的控制符号 <memory> 和 <reason>,将推理流程拆解为两个明确阶段:
记忆阶段:检索和组织已有知识
推理阶段:基于记忆结果进行逻辑推导
通过这种方式,我们让语言模型在每一步“思考”中都清楚地知道:你现在是在回忆,还是在推理!
为什么要做这件事?
现有的LLM在执行任务时,常常把“知识回忆”与“逻辑推理”混杂在一起,这带来两个严重问题:
知识遗忘与错用:模型可能在多个推理步骤之间丢失或篡改关键知识;
幻觉不可控:我们不知道模型的错误来源是“记错了”,还是“推错了”。
我们的目标就是 —— 让每一步错误都能被追踪、被解释、被修复!
我们是怎么做的?
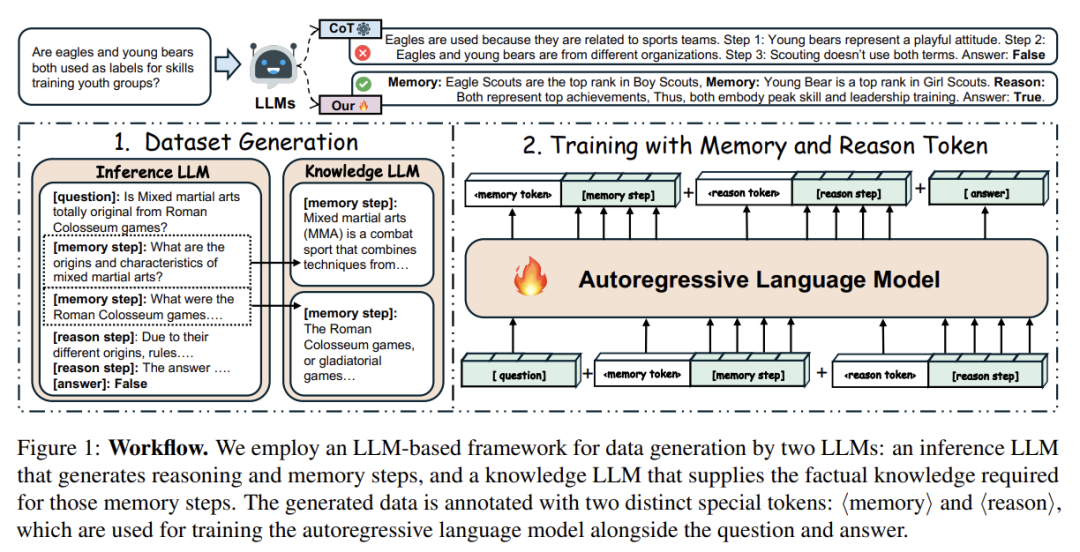
我们设计了一个完整的数据生成-训练框架(见图一):
用两个更强大的LLM生成训练数据:
推理LLM生成带 memory/reason 标签的解题过程
知识LLM补全 factual memory 用 <memory> 和 <reason> 特殊token进行训练,约束模型在不同阶段处理不同类型的信息,数据集如图。 最终,我们使用标准自回归语言模型进行训练,实现推理路径的结构性控制。
例子:

实验结果如何?
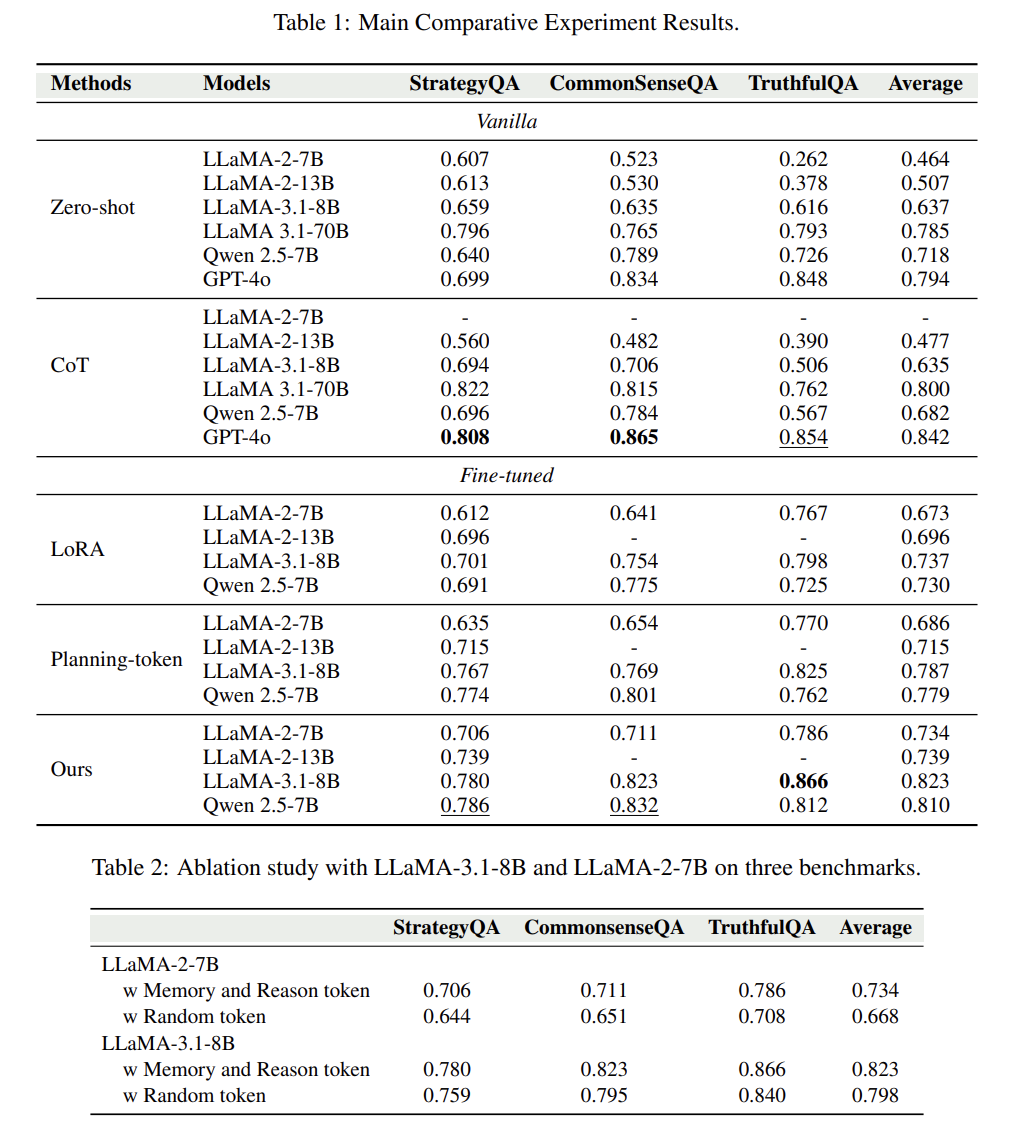
我们在三个主流推理评测集(StrategyQA, CommonsenseQA, TruthfulQA)上进行了系统性评估,结果令人惊喜:
准确率全面超越传统的Chain-of-Thought方法
在LLAMA-3、Qwen、LLaMA-2等多种模型上都取得一致提升
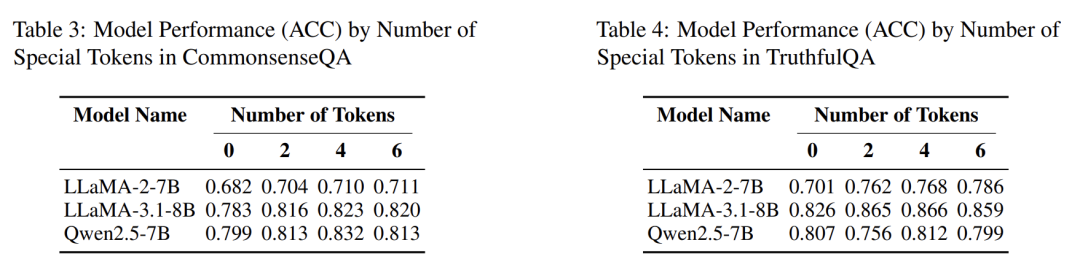
即使只用2~4个控制token,也能显著提升准确率(见表3、表4)
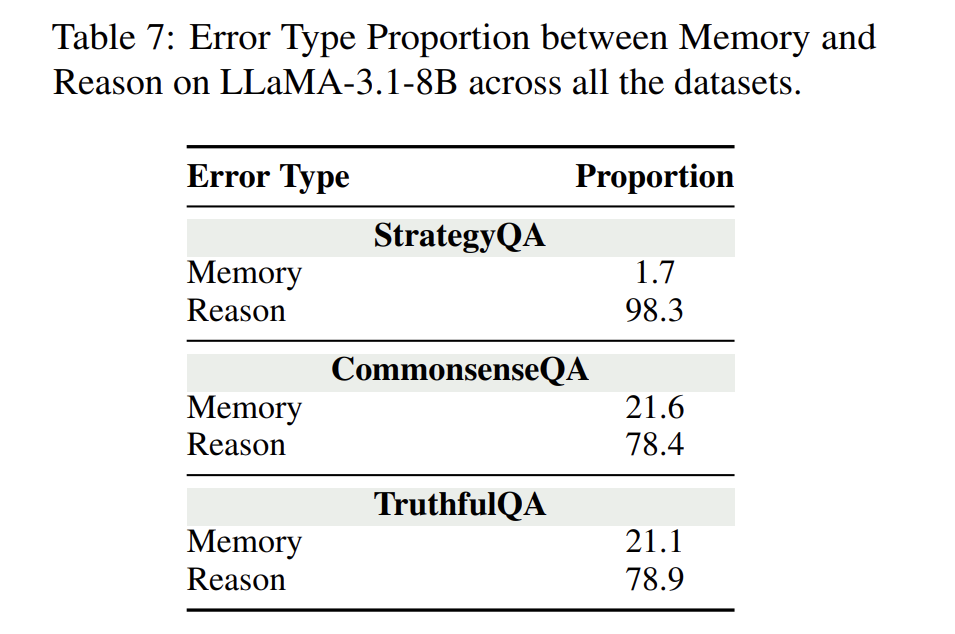
幻觉错误显著降低:我们发现大部分错误来自“推理步骤”而不是“知识回忆”(见表7)
我们不仅提升了准确率,还增强了模型的可控性和可解释性:
图2显示:我们的方法能够清晰地区分出“记忆”与“推理”的质量差异。
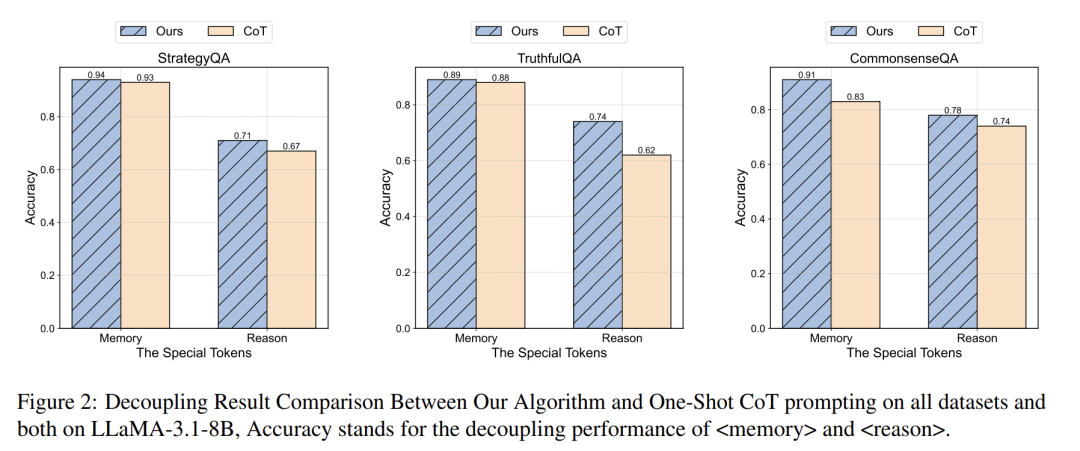
图3注意力热图显示:训练后模型确实学会在对应阶段关注对应token!
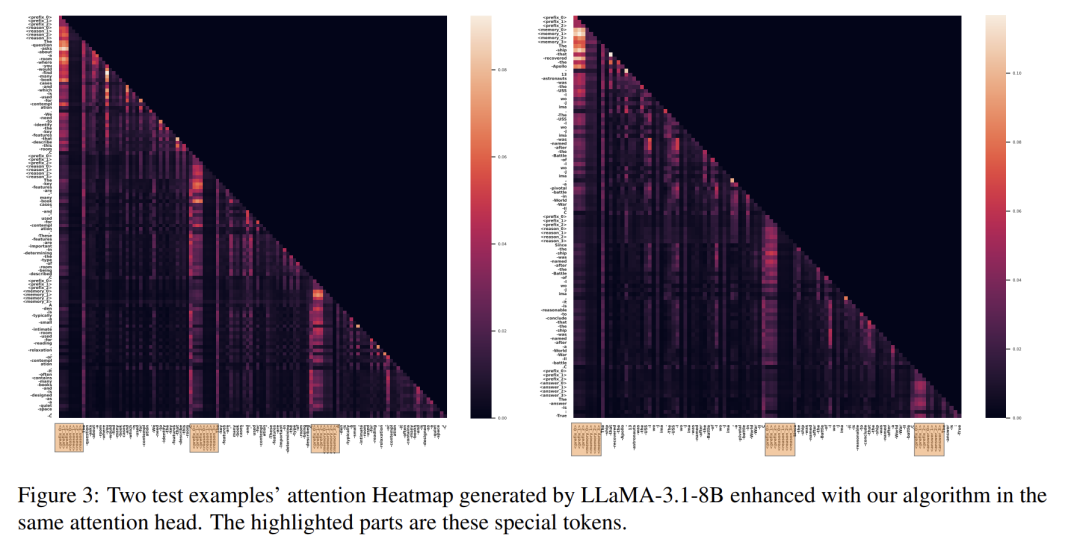
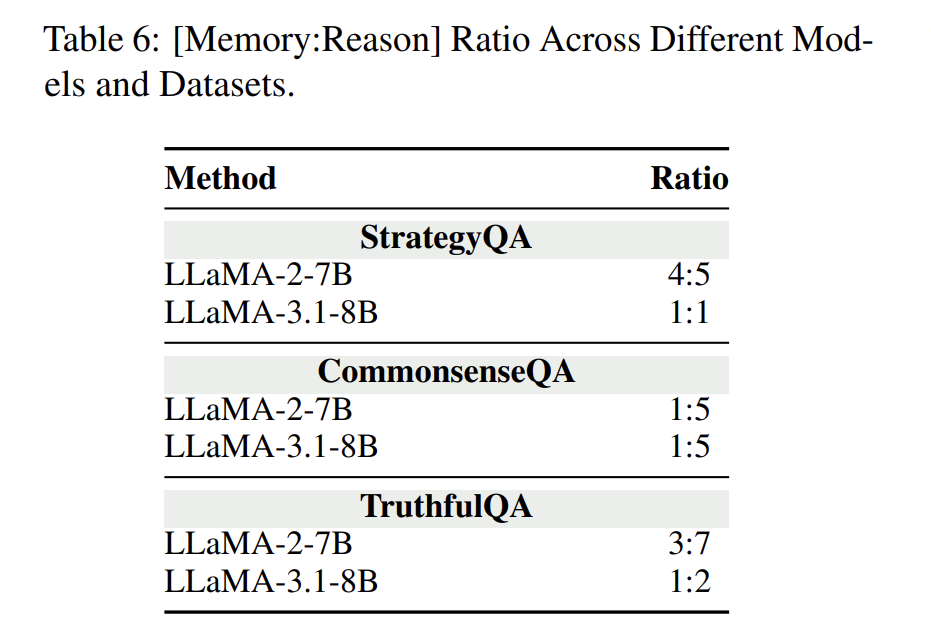
表6显示:我们框架下不同数据集具有稳定的Memory:Reason比率结构,有助于自动分析模型的推理过程。
总结
在LLM横行的时代,我们不能再满足于“结果对了就行”。 —— 我们希望训练出真正“理解自己为什么对”的模型。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









