






同学整理到有道云上面的,公司把有道云禁了,所以弄到这上面方便看,顺便有需要的也可以看看
常见算法相关:
(2)其次,线性表必须是顺序存储。所以链表不能采用二分查找。
二分查找(Binary Search)基本思想:在有序表中,取中间记录作为比较对象,若给定值与中间记录的关键字相等,则查找成功;若给定值小于中间记录的关键字,则在中间记录的左半区继续查找;若给定值大于中间记录的关键字,则在中间记录的右半区继续查找。不断重复上述过程,知道查找成功,或者所有查找区域无记录,查找失败为止。

重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。名字由来是因为越大的元素会经由交换慢慢“浮”到数列的顶端,故名。
比较相邻的元素。如果第一个比第二个大,就交换他们两个。对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。针对所有的元素重复以上的步骤,除了最后一个。持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。

给出一堆大批量数据(比如10亿),如何从中快速查找出前N个最大值?
解决方案:采用最小堆的形式。先取出N个数据生成最小堆,然后再取出后面的值依次与堆顶比较,比堆顶小,则继续;比堆顶大,则交换值,并更新最小堆,直到所有值全部比较完,最后生成的最小堆就是最大的N个数据。
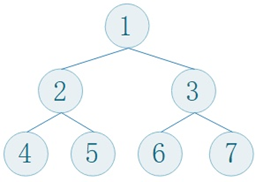
最小堆概念:最小堆是一种经过排序的完全二叉树,其中任一非终端节点的数据值均不大于其左子节点和右子节点的值。如下图所示,即有节点2、节点3大于等于节点1;节点4、节点5大于等于节点2;节点6、节点7大于等于节点3。

常见设计模式:

上图是Strategy 模式的结构图,让我们可以进行更方便的描述:
- Builder:为创建一个Product对象的各个部件指定抽象接口。
- ConcreteBuilder:实现Builder的接口以构造和装配该产品的各个部件,定义并明确它所创建的表示,提供一个检索产品的接口
- Director:构造一个使用Builder接口的对象。
- Product:表示被构造的复杂对象。ConcreateBuilder创建该产品的内部表示并定义它的装配过程。
- 单例模式
单例模式确保某个类只有一个实例,而且自行实例化并向整个系统提供这个实例。
懒汉式单例的实现没有考虑线程安全问题,它是线程不安全的,并发环境下很可能出现多个Singleton实例

饿汉式在类创建的同时就已经创建好一个静态的对象供系统使用,以后不再改变,所以是线程安全的。


多例模式的特点跟单例模式不同的是,在类中定义了有限个可实例化的对象个数;目的是提供对此类有多个访问入口,在多线程模式下可提高异步效率。
基础概念相关:
byte:8位,最大存储数据量是255,存放的数据范围是-128~127之间。
short:16位,最大数据存储量是65536,数据范围是-32768~32767之间。
int:32位,最大数据存储容量是2的32次方减1,数据范围是负的2的31次方到正的2的31次方减1。
long:64位,最大数据存储容量是2的64次方减1,数据范围为负的2的63次方到正的2的63次方减1。
float:32位,数据范围在3.4e-45~1.4e38,直接赋值时必须在数字后加上f或F。
double:64位,数据范围在4.9e-324~1.8e308,赋值时可以加d或D也可以不加。
1、确保它们不会在子类中改变语义。String类是final类,这意味着不允许任何人定义String的子类。
如果有一个String的引用,它引用的一定是一个String对象,而不可能是其他类的对象。
2、String 一旦被创建是不能被修改的,因为 java 设计者将 String 为可以共享的
1、设计成final,JVM才不用对相关方法在虚函数表中查询,而直接定位到String类的相关方法上,提高了执行效率。
总而言之,就是要保证 java.lang.String 引用的对象一定是 java.lang.String的对象,而不是引用它的子孙类,这样才能保证它的效率和安全。
为什么Java中1000==1000为false而100==100为true?
我们知道,如果两个引用指向同一个对象,用==表示它们是相等的。如果两个引用指向不同的对象,用==表示它们是不相等的,即使它们的内容相同。
这就是它有趣的地方了。如果你看去看 Integer.java 类,你会发现有一个内部私有类,IntegerCache.java,它缓存了从-128到127之间的所有的整数对象如果值的范围在-128到127之间,它就从高速缓存返回实例。

String,StringBuffer与StringBuilder的区别?
String 类型和 StringBuffer 类型的主要性能区别其实在于 String 是不可变的对象, 因此在每次对 String 类型进行改变的时候其实都等同于生成了一个新的 String 对象,然后将指针指向新的 String 对象,所以经常改变内容的字符串最好不要用 String ,因为每次生成对象都会对系统性能产生影响,特别当内存中无引用对象多了以后, JVM 的 GC 就会开始工作,那速度是一定会相当慢的。
在大部分情况下 StringBuilder >StringBuffer > String
Java.lang.StringBuffer线程安全的可变字符序列。一个类似于 String 的字符串缓冲区,但不能修改。
java.lang.StringBuilder一个可变的字符序列是5.0新增的。此类提供一个与 StringBuffer 兼容的 API,但不保证同步。
String声明为final类的目的:
用final关键字修饰,这说明String不可继承;保证了安全 如果有一个String的引用,它引用的一定是一个String对象,而不可能是其他类的对象。
保证String是不可变(immutable)。不可变就是第二次给一个String 变量赋值的时候,不是在原内存地址上修改数据,而是重新指向一个新对象,新地址。
Java 动态代理
在java中规定,要想产生一个对象的代理对象,那么这个对象必须要有一个接口
java在JDK1.5之后提供了一个"java.lang.reflect.Proxy"类,通过"Proxy"类提供的一个newProxyInstance方法用来创建一个对象的代理对象
static Object newProxyInstance(ClassLoader loader, Class<?>[] interfaces, InvocationHandler h)
newProxyInstance方法用来返回一个代理对象,这个方法总共有3个参数,ClassLoader loader用来指明生成代理对象使用哪个类装载器,Class<?>[] interfaces用来指明生成哪个对象的代理对象,通过接口指定,InvocationHandler h用来指明产生的这个代理对象要做什么事情。所以我们只需要调用newProxyInstance方法就可以得到某一个对象的代理对象了。
Java动态代理的两种实现方法_implements 动态代理 增加方法的参数-CSDN博客
Java 里的反射机制在默认情况下,方法的反射调用为委派实现,委派给本地实现来进行方法调用。在调用超过 15 次之后,委派实现便会将委派对象切换至动态实现。这个动态实现的字节码是自动生成的,它将直接使用 invoke 指令来调用目标方法。
方法的反射调用会带来不少性能开销,原因主要有三个:变长参数方法导致的 Object 数组,基本类型的自动装箱、拆箱,还有最重要的方法内联。
Java 抽象类和接口的区别及具体使用场景
2.抽象类可以包含具体的方法 , 接口的所有方法都是抽象的。
3.抽象类可以声明和使用字段 ,接口则不能,但接口可以创建静态的final常量。
4.接口的方法都是public的,抽象类的方法可以是public,protected,private或者默认的package;
作为能够实现特定功能的标识存在,也可以是什么接口方法都没有的纯粹标识。
需要将一组类视为单一的类,而调用者只通过接口来与这组类发生联系。
需要实现特定的多项功能,而这些功能之间可能完全没有任何联系。
一句话,在既需要统一的接口,又需要实例变量或缺省的方法的情况下,就可以使用它。最常见的有:定义了一组接口,但又不想强迫每个实现类都必须实现所有的接口。可以用abstract class定义一组方法体,甚至可以是空方法体,然后由子类选择自己所感兴趣的方法来覆盖。
某些场合下,只靠纯粹的接口不能满足类与类之间的协调,还必需类中表示状态的变量来区别不同的关系。abstract的中介作用可以很好地满足这一点。
规范了一组相互协调的方法,其中一些方法是共同的,与状态无关的,可以共享的,无需子类分别实现;而另一些方法却需要各个子类根据自己特定的状态来实现特定的功能
HashMap基于hash原理,我们通过put()和get()方法储存和获取对象。当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,让后找到bucket位置来储存值对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。HashMap使用链表来解决碰撞问题,当发生碰撞了,对象将会储存在链表的下一个节点中。 HashMap在每个链表节点中储存键值对对象。
Hash算法本质上就是三步:取key的hashCode值、高位运算、取模运算

①.判断键值对数组table[i]是否为空或为null,否则执行resize()进行扩容;
②.根据键值key计算hash值得到插入的数组索引i,如果table[i]==null,直接新建节点添加,转向⑥,如果table[i]不为空,转向③;
③.判断table[i]的首个元素是否和key一样,如果相同直接覆盖value,否则转向④,这里的相同指的是hashCode以及equals;
④.判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对,否则转向⑤;
⑤.遍历table[i],判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操作,否则进行链表的插入操作;遍历过程中若发现key已经存在直接覆盖value即可;
⑥.插入成功后,判断实际存在的键值对数量size是否超多了最大容量threshold,如果超过,进行扩容。
它们会储存在同一个bucket位置的链表中。键对象的equals()方法用来找到键值对。
Hash碰撞产生及解决:
Hashmap里面的bucket出现了单链表的形式,散列表要解决的一个问题就是散列值的冲突问题,通常是两种方法:链表法和开放地址法。链表法就是将相同hash值的对象组织成一个链表放在hash值对应的槽位;开放地址法是通过一个探测算法,当某个槽位已经被占据的情况下继续查找下一个可以使用的槽位。
* HashMap是最常用的Map,它根据键的HashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度,遍历时,取得数据的顺序是完全随机的。因为键对象不可以重复,所以HashMap最多只允许一条记录的键为Null,允许多条记录的值为Null,是非同步的
JDK1.8中,HashMap采用数组+链表+红黑树实现,当链表长度超过阈值(8)时,并且数组总容量超过64时,将链表转换为红黑树,这样大大减少了查找时间。从链表转换为红黑树后增加的时候效率低点,查询、删除的效率都高。
在java jdk8中对HashMap的源码进行了优化,在jdk7中,HashMap处理“碰撞”的时候,都是采用链表来存储,当碰撞的结点很多时,查询时间是O(n)。
在jdk8中,HashMap处理“碰撞”增加了红黑树这种数据结构,当碰撞结点较少时,采用链表存储,当较大时(>8个),采用红黑树(特点是查询时间是O(logn))存储(有一个阀值控制,大于阀值(8个),将链表存储转换成红黑树存储)

* Hashtable与HashMap类似,是HashMap的线程安全版,它支持线程的同步,即任一时刻只有一个线程能写Hashtable,因此也导致了Hashtale在写入时会比较慢,它继承自Dictionary类,不同的是它不允许记录的键或者值为null,同时效率较低。
LinkedHashMap保存了记录的插入顺序,在用Iteraor遍历LinkedHashMap时,先得到的记录肯定是先插入的,在遍历的时候会比HashMap慢,有HashMap的全部特性。
LinkedHashMap还使用了一个双向链表实现顺序存取,这个双向链表的实现依赖于Entry这个内部类,这个Entry内部类在集合中非常常见,在删除和增加时,都在修改前面的引用和后面的引用。LinkedHashMap中还用到了链表记录顺序,在LinkedHashMap中并没有put方法,而是利用了HashMap中的put方法,但是重写了put方法中调用的的addEntry()方法,在添加节点的时候(由于是双向链表)都会在尾部进行添加
* TreeMap实现SortMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序(自然顺序),也可以指定排序的比较器,当用Iterator遍历TreeMap时,得到的记录是排过序的。不允许key值为空,非同步的;
* 线程安全,并且锁分离。ConcurrentHashMap内部使用段(Segment)来表示这些不同的部分,每个段其实就是一个小的hash table,它们有自己的锁。只要多个修改操作发生在不同的段上,它们就可以并发进行。
- List
* ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
* 对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
* 对于新增和删除操作add和remove,LinkedList比较占优势,因为ArrayList要移动数据。 这一点要看实际情况的。若只对单条数据插入或删除,ArrayList的速度反而优于LinkedList。但若是批量随机的插入删除数据,LinkedList的速度大大优于ArrayList. 因为ArrayList每插入一条数据,要移动插入点及之后的所有数据。
* vector是线程同步的,所以它也是线程安全的,而arraylist是线程异步的,是不安全的。如果不考虑到线程的安全因素,一般用arraylist效率比较高。
java自动增加ArrayList大小的思路是:向ArrayList添加对象时,原对象数目加1如果大于原底层数组长度,则以适当长度新建一个原数组的拷贝,并修改原数组,指向这个新建数组。原数组自动抛弃(java垃圾回收机制会自动回收)。size则在向数组添加对象,自增1。
ArrayList追加对象时,Java总是要先计算容量(Capacity)是否适当,若容量不足则把原数组拷贝到以指定容量为长度创建的 新数组内,并对原数组变量重新赋值,指向新数组。在这同时,size进行自增1。
删除对象时,先使用拷贝方法把指定index后面的对象前移1位(如果 有的话),然后把空出来的位置置null,交给Junk收集器销毁,size自减1,即完成了。
数组:是将元素在内存中连续存储的;它的优点:因为数据是连续存储的,内存地址连续,所以在查找数据的时候效率比较高;它的缺点:在存储之前,我们需要申请一块连续的内存空间,并且在编译的时候就必须确定好它的空间的大小。在运行的时候空间的大小是无法随着你的需要进行增加和减少而改变的,当数据两比较大的时候,有可能会出现越界的情况,数据比较小的时候,又有可能会浪费掉内存空间。在改变数据个数时,增加、插入、删除数据效率比较低。
链表:是动态申请内存空间,不需要像数组需要提前申请好内存的大小,链表只需在用的时候申请就可以,根据需要来动态申请或者删除内存空间,对于数据增加和删除以及插入比数组灵活。还有就是链表中数据在内存中可以在任意的位置,通过应用来关联数据(就是通过存在元素的指针来联系)。
数组和链表就拿增加数据来说,数组中增加一个元素,需要移动大量的元素,在内存中空出一个元素的空间,然后将增加的元素放到空出的空间中;而链表就是将链表中最后的一个元素的指针指向新增的元素,在指出新增元素是尾元素就好了。

数组和链表对比
| 分类 | 数组 | 链表 |
| 逻辑结构角度 | 数组必须事先定义固定的长度(元素个数),不能适应数据动态地增减的情况。当数据增加时,可能超出原先定义的元素个数;当数据减少时,造成内存浪费 | 链表动态地进行存储分配,可以适应数据动态地增减的情况,且可以方便地插入、删除数据项。(数组中插入、删除数据项时,需要移动其它数据项) |
| 内存存储角度 | (静态)数组从栈中分配空间, 对于程序员方便快速,但自由度小 | 链表从堆中分配空间, 自由度大但申请管理比较麻烦 |
数组链表对比总结
- 数组静态分配内存,链表动态分配内存;
- 数组在内存中连续,链表不连续;
- 数组元素在栈区,链表元素在堆区;
- 数组利用下标定位,时间复杂度为O(1),链表定位元素时间复杂度O(n);
- 数组插入或删除元素的时间复杂度O(n),链表的时间复杂度O(1);
数据库相关:
第一, 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
第二, 可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
第三, 可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
第四, 在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
第五, 通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
也许会有人要问:增加索引有如此多的优点,为什么不对表中的每一个列创建一个索引呢?这种想法固然有其合理性,然而也有其片面性。虽然,索引有许多优点,但是,为表中的每一个列都增加索引,是非常不明智的。这是因为,增加索引也有许多不利的一个方面。
第一, 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
第二, 索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
第三, 当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
mysql


statement, row,mixed,mixed其实它就是前两种格式的混合。
binlog_format=statement 时,binlog 里面记录的就是 SQL 语句的原文;
当 binlog_format 使用 row 格式的时候,binlog 里面记录了真实删除行的主键 id,这样 binlog 传到备库去的时候,就肯定会删除 id=4 的行,不会有主备删除不同行的问题。
mixed 格式的意思是,MySQL 自己会判断这条 SQL 语句是否可能引起主备不一致,如果有可能,就用 row 格式,否则就用 statement 格式。

EXPLAIN SELECT surname,first_name form a,b WHERE a.id=b.id
EXPLAIN命令结果的每一列进行说明:
| 类型 | 说明 |
| SIMPLE | 简单表,不使用表连接或子查询 |
| PRIMARY | 主查询,即外层的查询 |
| UNION | UNION中的第二个或者后面的查询语句 |
| SUBQUERY | 子查询中的第一个 |
| ALL | 全表扫描 |
| index | 索引全扫描 |
| range | 索引范围扫描 |
| ref | 非唯一索引扫描 |
| eq_ref | 唯一索引扫描 |
| const,system | 单表最多有一个匹配行 |
| NULL | 不用扫描表或索引 |
一般是没有where条件或者where条件没有使用索引的查询语句
EXPLAIN SELECT * FROM customer WHERE active=0;

EXPLAIN SELECT store_id FROM customer;

EXPLAIN SELECT * FROM customer WHERE customer_id>=10 AND customer_id<=20;

注意这种情况下比较的字段是需要加索引的,如果没有索引,则MySQL会进行全表扫描,如下面这种情况,create_date字段没有加索引:
EXPLAIN SELECT * FROM customer WHERE create_date>='2006-02-13' ;

EXPLAIN SELECT * FROM customer WHERE store_id=10;

customer、payment表关联查询,关联字段customer.customer_id(主键),payment.customer_id(非唯一索引)。表关联查询时必定会有一张表进行全表扫描,此表一定是几张表中记录行数最少的表,然后再通过非唯一索引寻找其他关联表中的匹配行,以此达到表关联时扫描行数最少。

因为customer、payment两表中customer表的记录行数最少,所以customer表进行全表扫描,payment表通过非唯一索引寻找匹配行。
EXPLAIN SELECT * FROM customer customer INNER JOIN payment payment ON customer.customer_id = payment.customer_id;

eq_ref一般出现在多表连接时使用primary key或者unique index作为关联条件。
film、film_text表关联查询和上一条所说的基本一致,只不过关联条件由非唯一索引变成了主键。
EXPLAIN SELECT * FROM film film INNER JOIN film_text film_text ON film.film_id = film_text.film_id;

const/system出现在根据主键primary key或者 唯一索引 unique index 进行的查询
EXPLAIN SELECT * FROM customer WHERE customer_id =10;

EXPLAIN SELECT * FROM customer WHERE email ='MARY.SMITH@sakilacustomer.org';



- possible_keys: 表示查询可能使用的索引
- key: 实际使用的索引
- key_len: 使用索引字段的长度
- ref: 使用哪个列或常数与key一起从表中选择行。
- rows: 扫描行的数量
- filtered: 存储引擎返回的数据在server层过滤后,剩下多少满足查询的记录数量的比例(百分比)
- Extra: 执行情况的说明和描述,包含不适合在其他列中显示但是对执行计划非常重要的额外信息
最主要的有一下三种:
| Using Index | 表示索引覆盖,不会回表查询 |
| Using Where | 表示进行了回表查询 |
| Using Index Condition | 表示进行了ICP优化 |
| Using Flesort | 表示MySQL需额外排序操作, 不能通过索引顺序达到排序效果 |
- 当语句中带有or的时候 即使有索引也会失效。
- 当语句索引 like 带%的时候索引失效(注意:如果上句为 like‘xzz’此时索引是生效的)
- 如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引
- mysql联合所以有最左原则
- 索引失效,不要在索引上进行操作,否则索引会失效(是有类似时间转换的问题和上诉问题一样)select * from USER where age-1>11;
- 列数据字段值为Null 索引失效
Hash索引和B+ Tree索引,我们使用的是InnoDB引擎,默认的是B+树。
哈希索引适合等值查询,但是不无法进行范围查询 哈希索引没办法利用索引完成排序 哈希索引不支持多列联合索引的最左匹配规则 如果有大量重复键值得情况下,哈希索引的效率会很低,因为存在哈希碰撞问题
以上分页查询的问题在于,我们查询获取的 10020 行数据结果都返回给我们了,我们能否先查询出所需要的 20 行数据中的最小 ID 值,然后通过偏移量返回所需要的 20 行数据给我们呢?我们可以通过索引覆盖扫描,使用子查询的方式来实现分页查询:
| select * from `demo`.`order` where id> (select id from `demo`.`order` order by order_no limit 10000, 1) limit 20; |
MYSQL数据库引擎 MYISAM和 INNODB区别:
MyISAM:每个MyISAM在磁盘上存储成三个文件。第一个文件的名字以表的名字开始,扩展名指出文件类型。.frm文件存储表定义。数据文件的扩展名为.MYD (MYData)。索引文件的扩展名是.MYI (MYIndex)。
InnoDB:所有的表都保存在同一个数据文件中(也可能是多个文件,或者是独立的表空间文件),InnoDB表的大小只受限于操作系统文件的大小,一般为2GB。
MyISAM:可被压缩,存储空间较小。支持三种不同的存储格式:静态表(默认,但是注意数据末尾不能有空格,会被去掉)、动态表、压缩表。
InnoDB:需要更多的内存和存储,它会在主内存中建立其专用的缓冲池用于高速缓冲数据和索引。
MyISAM:强调的是性能,每次查询具有原子性,其执行数度比InnoDB类型更快,但是不提供事务支持。
InnoDB:提供事务支持事务,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
MyISAM:如果执行大量的SELECT,MyISAM是更好的选择。(因为没有支持行级锁),在增删的时候需要锁定整个表格,效率会低一些。相关的是innodb支持行级锁,删除插入的时候只需要锁定改行就行,效率较高
InnoDB:如果你的数据执行大量的INSERT或UPDATE,出于性能方面的考虑,应该使用InnoDB表。DELETE 从性能上InnoDB更优,但DELETE FROM table时,InnoDB不会重新建立表,而是一行一行的删除,在innodb上如果要清空保存有大量数据的表,最好使用truncate table这个命令。
原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚,这和前面两篇博客介绍事务的功能是一样的概念,因此事务的操作如果成功就必须要完全应用到数据库,如果操作失败则不能对数据库有任何影响。
一致性是指事务必须使数据库从一个一致性状态变换到另一个一致性状态,也就是说一个事务执行之前和执行之后都必须处于一致性状态。
拿转账来说,假设用户A和用户B两者的钱加起来一共是5000,那么不管A和B之间如何转账,转几次账,事务结束后两个用户的钱相加起来应该还得是5000,这就是事务的一致性。
隔离性是当多个用户并发访问数据库时,比如操作同一张表时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。
即要达到这么一种效果:对于任意两个并发的事务T1和T2,在事务T1看来,T2要么在T1开始之前就已经结束,要么在T1结束之后才开始,这样每个事务都感觉不到有其他事务在并发地执行。
持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。
例如我们在使用JDBC操作数据库时,在提交事务方法后,提示用户事务操作完成,当我们程序执行完成直到看到提示后,就可以认定事务以及正确提交,即使这时候数据库出现了问题,也必须要将我们的事务完全执行完成,否则就会造成我们看到提示事务处理完毕,但是数据库因为故障而没有执行事务的重大错误。
脏读 脏读是指在一个事务处理过程里读取了另一个未提交的事务中的数据。 当一个事务正在多次修改某个数据,而在这个事务中这多次的修改都还未提交,这时一个并发的事务来访问该数据,就会造成两个事务得到的数据不一致。
#{xxx},使用的是PreparedStatement,会有类型转换,所以比较安全;
mybatis用sql预编译的;其实框架底层使用的正是PreparedStatement类。PreparedStaement类不但能够避免SQL注入,因为已经预编译,当N次执行同一条sql语句时,节约了(N-1)次的编译时间,从而能够提高效率。
MyBatis 查询缓存来缓存

一级缓存
一级缓存是 SqlSession 级别的缓存,是基于 HashMap 的本地缓存。不同的 SqlSession 之间的缓存数据区域互不影响。
一级缓存的作用域是 SqlSession 范围,当同一个 SqlSession 执行两次相同的 sql 语句时,第一次执行完后会将数据库中查询的数据写到缓存,第二次查询时直接从缓存获取不用去数据库查询。当 SqlSession 执行 insert、update、delete 操做并提交到数据库时,会清空缓存,保证缓存中的信息是最新的。
二级缓存是 mapper 级别的缓存,同样是基于 HashMap 进行存储,多个 SqlSession 可以共用二级缓存,其作用域是 mapper 的同一个 namespace。不同的 SqlSession 两次执行相同的 namespace 下的 sql 语句,会执行相同的 sql,第二次查询只会查询第一次查询时读取数据库后写到缓存的数据,不会再去数据库查询。
1.手动代码方式:使用Mybatis提供的API进行操作,通过获取SqlSession对象,然后根据Statement Id 和参数来操作数据库。
2.使用注解自动方式: MapperScannerConfigurer类动态的注册Bean信息
- 扫描mapper接口基本包,将为注册为BeanDefinition对象。
- 设置BeanDefinition的对象的beanClass和sqlSessionFactory属性。
- 设置sqlSessionFactory属性的时候,调用SqlSessionTemplate的构造方法,创建SqlSession接口的代理类。
- 获取BeanDefinition对象的时候,调用其工厂方法getObject,返回mapper接口的代理类。
Spring相关:
- 首先@PostConstruct 会被最先调用
- 其次 InitializingBean.afterPropertiesSet() 方法将会被调用
- 最后调用通过 XML 配置的 init-method 方法或通过设置 @Bean 注解 设置 initMethod 属性的方法

Spring MVC的设计是围绕DispatcherServlet展开的,DispatcherServlet负责将请求派发到特定的handler。通过可配置的handler mappings、view resolution、locale以及theme resolution来处理请求并且转到对应的视图。
DispatcherServlet 核心流程:
一个特定的 DispatcherServlet 请求过来之后,它的工作流程如下:
(1)WebApplicationContext 上下文寻求并绑定控制器和 ,默认情况下会绑定 DispatcherServlet.WEB_APPLICATION_CONTEXT_ATTRIBUTE下的默认值。
(2)语言解析器绑定到请求启动过程中的元素来解决所使用的语言环境处理请求(渲染视图、准备数据等),如果不需要处理国际化,就不需要这步。
(3)主题解析器绑定请求让视图这样的元素知道需要使用哪种主题,如果没有使用主题,同样忽略此步骤。
(4)如果指定一个多文件解析器,请求就会检查这些文件,如果找到这些文件,请求就会被包装到 MultipartHttpServletRequest中,进一步处理其他元素。
(5)接下来,寻找一个合适的处理器,如果找到了,处理器相关执行链就会执行,为数据模型或渲染视图做准备。
(6)如果返回了模型,就会渲染视图。如果没有返回模型(可能是为了安全考虑,预处理或后处理程序拦截了请求),就不需要渲染视图,请求可能已经完成了。

1) REQUIRED ,这个是默认的属性
Support a current transaction, create a new one if none exists.
如果存在一个事务,则支持当前事务。如果没有事务则开启一个新的事务。
被设置成这个级别时,会为每一个被调用的方法创建一个逻辑事务域。如果前面的方法已经创建了事务,那么后面的方法支持当前的事务,如果当前没有事务会重新建立事务。
Support a current transaction, throw an exception if none exists.支持当前事务,如果当前没有事务,就抛出异常。
Execute non-transactionally, throw an exception if a transaction exists.
Execute non-transactionally, suspend the current transaction if one exists.
Create a new transaction, suspend the current transaction if one exists.
Support a current transaction, execute non-transactionally if none exists.
Execute within a nested transaction if a current transaction exists, behave like PROPAGATION_REQUIRED else.
支持当前事务,新增Savepoint点,与当前事务同步提交或回滚。
嵌套事务一个非常重要的概念就是内层事务依赖于外层事务。外层事务失败时,会回滚内层事务所做的动作。而内层事务操作失败并不会引起外层事务的回滚。
8) PROPAGATION_NESTED 与PROPAGATION_REQUIRES_NEW的区别
它们非常 类似,都像一个嵌套事务,如果不存在一个活动的事务,都会开启一个新的事务。使用PROPAGATION_REQUIRES_NEW时,内层事务与外层事务就像两个独立的事务一样,一旦内层事务进行了提交后,外层事务不能对其进行回滚。两个事务互不影响。两个事务不是一个真正的嵌套事务。同时它需要JTA 事务管理器的支持。
使用PROPAGATION_NESTED时,外层事务的回滚可以引起内层事务的回滚。而内层事务的异常并不会导致外层事务的回滚,它是一个真正的嵌套事务。
事务的隔离级别(Isolation Level)
一个事务正在对数据进行更新操作,但是更新还未提交,另一个事务这时也来操作这组数据,并且读取了前一个事务还未提交的数据,而前一个事务如果操作失败进行了回滚,后一个事务读取的就是错误数据,这样就造成了脏读。
ii. Non-Repeatable Reads 不可重复读
一个事务多次读取同一数据,在该事务还未结束时,另一个事务也对该数据进行了操作,而且在第一个事务两次次读取之间,第二个事务对数据进行了更新,那么第一个事务前后两次读取到的数据是不同的,这样就造成了不可重复读。
第一个数据正在查询符合某一条件的数据,这时,另一个事务又插入了一条符合条件的数据,第一个事务在第二次查询符合同一条件的数据时,发现多了一条前一次查询时没有的数据,仿佛幻觉一样,这就是幻像读。
非重复读是指同一查询在同一事务中多次进行,由于其他提交事务所做的修改或删除,每次返回不同的结果集,此时发生非重复读。(A transaction rereads data it has previously read and finds that another committed transaction has modified or deleted the data. )
幻像读是指同一查询在同一事务中多次进行,由于其他提交事务所做的插入操作,每次返回不同的结果集,此时发生幻像读。(A transaction reexecutes a query returning a set of rows that satisfies a search condition and finds that another committed transaction has inserted additional rows that satisfy the condition. )
表面上看,区别就在于非重复读能看见其他事务提交的修改和删除,而幻像能看见其他事务提交的插入。
嵌套事物
可能大家对PROPAGATION_NESTED还不怎么了解,觉得有必要再补充一下^_^!
PROPAGATION_NESTED: 嵌套事务类型,是相对上面提到的六种情况(上面的六种应该称为平面事务类型),打个比方我现在有一个事务主要有一下几部分:
这样看和以前不同的事务可能没有什么区别,那我现在有点特殊的要求就是,A用户有3个帐户,B用户有2个帐户,现在我的要求就是只要再A用户的3个帐户里面任意一个减去100元,往B用户的两个帐户中任意一个里面增加100元就可以了!
一旦你有这样的要求那嵌套事务类型就非常适合你!我们可以这样理解,
一:将“从A用户帐户里面减去100元钱” 和 “往B用户帐户里面增加100元钱”我们暂时认为是一级事务操作
二:将从A用户的3个帐户的任意一个帐户里面减钱看做是“从A用户帐户里面减去100元钱”这个一级事务的子事务(二级事务),同样把后面存钱的看成是另一个的二级事务。
问题一:当二级事务被rollback一级事务会不会被rollback?
问题二:什么时候这个一级事务会commit,什么时候会被rollback呢?
我们主要看二级里面出现的情况,当所有的二级事务被commit了并且一级事务没有失败的操作,那整个事务就算是一个成功的事务,这种情况整个事务会被commit。
当任意一个二级事务没有被commit那整个事务就是失败的,整个事务会被roolback。
还是拿上面的例子来说明吧!如果我在a的三个帐户里面减钱的操作都被二级事务给rollback了,也就是3个帐户里面都没有减钱成功,整个事务就失败了就会被rollback。如果A用户帐户三个帐户里面有一个可以扣钱而且B用户的两个帐户里面也有一个帐户可以增加钱,那整个事务就算成功的,会被 commit。
看了一下觉得上面的例子好像不是很深刻,看这个情况(A用户的3个帐户都是有信用额度的,也就是说可以超支,但是超支有金额限制)。
AOP--Aspect Oriented Programming面向切面编程;用来封装横切关注点,具体可以在下面的场景中使用:
Authentication 权限、Caching 缓存、Context passing 内容传递、Error handling 错误处理Lazy loading懒加载、Debugging调试、logging, tracing, profiling and monitoring 记录跟踪优化 校准、Performance optimization 性能优化、Persistence 持久化、Resource pooling 资源池、Synchronization 同步、Transactions 事务
原理:AOP是面向切面编程,是通过动态代理的方式为程序添加统一功能,集中解决一些公共问题。
IOC--Inversion of Control控制反转。当某个角色需要另外一个角色协助的时候,在传统的程序设计过程中,通常由调用者来创建被调用者的实例对象。但在spring中创建被调用者的工作不再由调用者来完成,因此称为控制反转。创建被调用者的工作由spring来完成,然后注入调用者 直接使用。
原理:Spring 通过一个配置文件描述 Bean 及 Bean 之间的依赖关系,利用 Java 语言的反射功能实例化 Bean 并建立 Bean 之间的依赖关系。 Spring 的 IoC 容器在完成这些底层工作的基础上,还提供了 Bean 实例缓存、生命周期管理、 Bean 实例代理、事件发布、资源装载等高级服务。
JDK 自身提供的动态代理,就是主要利用了上面提到的反射机制。
还有其他的实现方式,比如利用传说中更高性能的字节码操作机制,类似 ASM、cglib(基于 ASM)、Javassist 等。
BeanFactory 和 ApplicationContext 的不同点:
这是一个用来访问 Spring 容器的 root 接口,要访问 Spring 容器,我们将使用 Spring 依赖注入功能,使用 BeanFactory 接口和它的子接口
ApplicationContext 是 Spring 应用程序中的中央接口,用于向应用程序提供配置信息它继承了 BeanFactory 接口,所以 ApplicationContext 包含 BeanFactory 的所有功能以及更多功能!它的主要功能是支持大型的业务应用的创建
- Bean instantiation/wiring
- Bean 的实例化/串联
- 自动的 BeanPostProcessor 注册
- 自动的 BeanFactoryPostProcessor 注册
- 方便的 MessageSource 访问(i18n)
- ApplicationEvent 的发布
与 BeanFactory 懒加载的方式不同,它是预加载,所以,每一个 bean 都在 ApplicationContext 启动之后实例化
BeanFactory和ApplicationContext有什么区别?
BeanFactory 可以理解为含有bean集合的工厂类。BeanFactory 包含了种bean的定义,以便在接收到客户端请求时将对应的bean实例化。
BeanFactory还能在实例化对象的时生成协作类之间的关系。此举将bean自身与bean客户端的配置中解放出来。BeanFactory还包含了bean生命周期的控制,调用客户端的初始化方法(initialization methods)和销毁方法(destruction methods)。
从表面上看,application context如同bean factory一样具有bean定义、bean关联关系的设置,根据请求分发bean的功能。但application context在此基础上还提供了其他的功能。
以下是三种较常见的 ApplicationContext 实现方式:
1、ClassPathXmlApplicationContext:从classpath的XML配置文件中读取上下文,并生成上下文定义。应用程序上下文从程序环境变量中取得。
![]()
2、FileSystemXmlApplicationContext :由文件系统中的XML配置文件读取上下文。
![]()
3、XmlWebApplicationContext:由Web应用的XML文件读取上下文。
Spring框架并没有对单例bean进行任何多线程的封装处理。关于单例bean的线程安全和并发问题需要开发者自行去搞定。但实际上,大部分的Spring bean并没有可变的状态(比如Serview类和DAO类),所以在某种程度上说Spring的单例bean是线程安全的。如果你的bean有多种状态的话(比如 View Model 对象),就需要自行保证线程安全。
最浅显的解决办法就是将多态bean的作用域由“singleton”变更为“prototype”。
多线程相关:
并发编程中很常用的实用工具类,用于定义类似于线程的自定义子系统,包括线程池、异步IO 和轻量级任务框架。提供可调的、灵活的线程池。还提供了设计用于多线程上下文中的Collection 实现等:
1、使用synchronized关键字同步方法、同步类。(由于java的每个对象都有一个内置锁,当用此关键字修饰方法时, 内置锁会保护整个方法。在调用该方法前,需要获得内置锁,否则就处于阻塞状态。 注:同步是一种高开销的操作,因此应该尽量减少同步的内容。通常没有必要同步整个方法,使用synchronized代码块同步关键代码即可。 )
wait():使一个线程处于等待状态,并且释放所持有的对象的lock。
sleep():使一个正在运行的线程处于睡眠状态,是一个静态方法,调用此方法要捕捉InterruptedException异常。
notify():唤醒一个处于等待状态的线程,注意的是在调用此方法的时候,并不能确切的唤醒某一个等待状态的线程,而是由JVM确定唤醒哪个线程,而且不是按优先级。
Allnotity():唤醒所有处入等待状态的线程,注意并不是给所有唤醒线程一个对象的锁,而是让它们竞争。
b.使用volatile修饰域相当于告诉虚拟机该域可能会被其他线程更新
d.volatile不会提供任何原子操作,它也不能用来修饰final类型的变量
4、使用重入锁实现线程同步java.util.concurrent.ReentrantLock来支持同步
ReentrantLock类是可重入、互斥、实现了Lock接口的锁,它与使用synchronized方法和快具有相同的基本行为和语义,并且扩展了其能力。
ReentrantLock() : 创建一个ReentrantLock实例 lock() : 获得锁 unlock() : 释放锁
注:ReentrantLock()还有一个可以创建公平锁的构造方法,但由于能大幅度降低程序运行效率,不推荐使用
5、使用局部变量实现线程同步ThreadLocal管理变量,则每一个使用该变量的线程都获得该变量的副本,副本之间相互独立,这样每一个线程都可以随意修改自己的变量副本,而不会对其他线程产生影响。
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler)
- corePoolSize - 线程池核心池的大小。
- maximumPoolSize - 线程池的最大线程数。
- keepAliveTime - 当线程数大于核心时,此为终止前多余的空闲线程等待新任务的最长时间。
- unit - keepAliveTime 的时间单位。
- workQueue - 用来储存等待执行任务的队列。
- threadFactory - 线程工厂。
- handler - 拒绝策略。
线程池有两个线程数的设置,一个为核心池线程数,一个为最大线程数。
在创建了线程池后,默认情况下,线程池中并没有任何线程,等到有任务来才创建线程去执行任务,除非调用了prestartAllCoreThreads()或者prestartCoreThread()方法
当创建的线程数等于 corePoolSize 时,会加入设置的阻塞队列。当队列满时,会创建线程执行任务直到线程池中的数量等于maximumPoolSize。
java.lang.IllegalStateException: Queue full
插入方法 add(e) offer(e) put(e) offer(e,time,unit)
移除方法 remove() poll() take() poll(time,unit)
ArrayBlockingQueue :一个由数组结构组成的有界阻塞队列。
LinkedBlockingQueue :一个由链表结构组成的有界阻塞队列。
PriorityBlockingQueue :一个支持优先级排序的无界阻塞队列。
DelayQueue: 一个使用优先级队列实现的无界阻塞队列。
SynchronousQueue: 一个不存储元素的阻塞队列。
LinkedTransferQueue: 一个由链表结构组成的无界阻塞队列。
LinkedBlockingDeque: 一个由链表结构组成的双向阻塞队列。
ThreadPoolExecutor.AbortPolicy: 丢弃任务并抛出RejectedExecutionException异常。 (默认)
ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。
ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)
ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务
1)newFixedThreadPool 和 newSingleThreadExecutor:
主要问题是堆积的请求处理队列可能会耗费非常大的内存,甚至 OOM。
2)newCachedThreadPool 和 newScheduledThreadPool:
主要问题是线程数最大数是 Integer.MAX_VALUE,可能会创建数量非常多的线程,甚至 OOM。
创建一个单线程的线程池。这个线程池只有一个线程在工作,也就是相当于单线程串行执行所有任务。如果这个唯一的线程因为异常结束,那么会有一个新的线程来替代它。
new ThreadPoolExecutor(1, 1,0L,TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>())
创建固定大小的线程池。每次提交一个任务就创建一个线程,直到线程达到线程池的最大大小。
线程池的大小一旦达到最大值就会保持不变,如果某个线程因为执行异常而结束,那么线程池会补充一个新线程。
new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>());
创建一个可缓存的线程池。如果线程池的大小超过了处理任务所需要的线程,
那么就会回收部分空闲(60秒不执行任务)的线程,当任务数增加时,此线程池又可以智能的添加新线程来处理任务。
此线程池不会对线程池大小做限制,线程池大小完全依赖于操作系统(或者说JVM)能够创建的最大线程大小。
new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS,new SynchronousQueue<Runnable>());
- 解释下什么是ThreadLocal,具体的使用场景
每一个ThreadLocal(线程副本)能够放一个线程级别的变量,可是它本身能够被多个线程共享使用,并且又能够达到线程安全的目的,且绝对线程安全。
ThreadLocal() : 创建一个线程本地变量 get() : 返回此线程局部变量的当前线程副本中的值 initialValue() : 返回此线程局部变量的当前线程的"初始值" set(T value) : 将此线程局部变量的当前线程副本中的值设置为value
ThreadLocal 底层原理是使用Map实现的,在使用时利用map的key存储当前线程对象


synchronized同步锁比较重效率低,比较耗资源,不灵活智;代码开始行自动上锁解锁;


join 方法其实就是阻塞当前调用它的线程,等待join执行完毕,当前线程继续执行。
- 怎么获取一个线程执行后的结果
java中提供了Future<V>接口和实现了Future接口的FutureTask<V> 类来将线程执行之后的结果返回(通过get()方法)。
2. 可运行(RUNNABLE):线程对象创建后,其他线程(比如main线程)调用了该对象的start()方法。该状态的线程位于可运行线程池中,等待被线程调度选中,获取cpu 的使用权 。
3. 运行(RUNNING):可运行状态(runnable)的线程获得了cpu 时间片(timeslice) ,执行程序代码。
4. 阻塞(BLOCKED):阻塞状态是指线程因为某种原因放弃了cpu 使用权,也即让出了cpu timeslice,暂时停止运行。直到线程进入可运行(runnable)状态,才有机会再次获得cpu timeslice 转到运行(running)状态。阻塞的情况分三种:
(一). 等待阻塞:运行(running)的线程执行o.wait()方法,JVM会把该线程放入等待队列(waitting queue)中。
(二). 同步阻塞:运行(running)的线程在获取对象的同步锁时,若该同步锁被别的线程占用,则JVM会把该线程放入锁池(lock pool)中。
(三). 其他阻塞:运行(running)的线程执行Thread.sleep(long ms)或t.join()方法,或者发出了I/O请求时,JVM会把该线程置为阻塞状态。当sleep()状态超时、join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入可运行(runnable)状态。
5. 死亡(DEAD):线程run()、main() 方法执行结束,或者因异常退出了run()方法,则该线程结束生命周期。死亡的线程不可再次复生。
乐观锁:获得锁后一直持有锁以防本线程再次申请该锁造成无谓的解锁再加锁开销,或者假设没有冲突而去完成同步代码块如果冲突再循环重试,或者采取申请锁失败后不立刻挂起而是稍微等待再次尝试获取 等待策略,以减少线程因为挂起、阻塞、唤醒(发生CPU的调度切换) 而造成的开销。
悲观锁:不管是否发生多线程冲突,只要存在这种可能,就每次访问都加锁,加锁就会导致锁之间的争夺,有争夺就会有输赢,输者等待。
- synchronized关键字可以作为函数的修饰符,也可作为函数内的语句,也就是平时说的同步方法和同步语句块。如果 再细的分类,synchronized可作用于instance变量、object reference(对象引用)、static函数和class literals(类名称字面常量)身上。
- 无论synchronized关键字加在方法上还是对象上,它取得的锁都是对象,而不是把一段代码或函数当作锁――而且同步方法很可能还会被其他线程的对象访问。
- 每个对象只有一个锁(lock)与之相关联。
- 实现同步是要很大的系统开销作为代价的,甚至可能造成死锁,所以尽量避免无谓的同步控制。
- 某个对象实例内,synchronized aMethod(){}可以防止多个线程同时访问这个对象的synchronized方法(如果一个对象有多个synchronized方法,只要一个线 程访问了其中的一个synchronized方法,其它线程不能同时访问这个对象中任何一个synchronized方法)。这时,不同的对象实例的 synchronized方法是不相干扰的。也就是说,其它线程照样可以同时访问相同类的另一个对象实例中的synchronized方法;
- 某个类的静态方法范围,synchronized static aStaticMethod{}防止多个线程同时访问这个类中的synchronized static 方法。它可以对类的所有对象实例起作用。
synchronized 修饰在 static方法和非static方法的区别:
synchronized是对类的当前实例(当前对象)进行加锁,防止其他线程同时访问该类的该实例的所有synchronized块,注意这里是“类的当前实例”, 类的两个不同实例就没有这种约束了。
static synchronized恰好就是要控制类的所有实例的并发访问,static synchronized是限制多线程中该类的所有实例同时访问jvm中该类所对应的代码块。
JVM相关:


java内存模型有 方法区、堆、虚拟机栈、本地方法栈、程序计数器 组成;其中方法区也是各个线程共享的,主要用于存储已被虚拟机加载的类信息、常量、静态变量、编译后的代码等数据;虚拟机栈是描述Java方法执行的内存模型;本地方法栈是执行的Native服务;程序计数器是当前线程所执行的的字节码的指示器,只占用很小的内存空间。

虚拟机栈是线程私有的,而且它的生命周期和线程相同.虚拟机栈是描述Java方法执行的内存模型。每个方法在执行时都会创建一个栈帧,用于存储局部变量表、操作数栈、动态链接和方法出口信息等,这里主要了解局部变量表部分。
局部变量表存放了编译时可知的各种基本数据类型和对象引用。需要注意的是long和double数据会占用2个局部变量空间,其它的都占一个。局部变量表的大小在编译时已经确定,所以在方法执行时不会改变局部变量表的大小。
虚拟机栈区域会出现StackOverflowError异常和OutOfMemoryError异常。
程序计数器可以看作是当前线程所执行的的字节码的指示器,只占用很小的内存空间。每个线程都需要有一个独立的程序计数器,各个线程之间的计数器互不影响,所以它也是线程隔离的数据区。
本地方法栈和虚拟机栈非常相似,它们的区别是虚拟机栈执行的是Java方法服务,而本地方法栈执行的是Native服务。
本地方法栈区域也会出现StackOverflowError异常和OutOfMemoryError异常。
Java堆是被所有线程共享的,在虚拟机启动的时候创建,它的唯一目的就是存放对象实例。也就是说所有的对象实例和数组都要在堆上分配。
Java堆可以处于物理上不连续的内存空间,只要逻辑上是连续的即可。如果Java堆无法再继续扩展,而又有对象实例未完成分配,将会抛出OutOfMemoryError异常。
方法区也是各个线程共享的,主要用于存储已被虚拟机加载的类信息、常量、静态变量、编译后的代码等数据。
运行时常量池是方法区的一部分,主要用于存放编译生成的各种字面量和符号引用。

新生代几乎是所有 Java 对象出生的地方,即 Java 对象申请的内存以及存放都是在这个地方。Java 中的大部分对象通常不需长久存活,具有朝生夕灭的性质。 当一个对象被判定为 “死亡” 的时候,GC 就有责任来回收掉这部分对象的内存空间。新生代是 GC 收集垃圾的频繁区域。 当对象在 Eden 出生后,在经过一次 Minor GC 后,如果对象还存活,并且能够被另外一块 Survivor 区域所容纳,则使用复制算法将这些仍然还存活的对象复制到另外一块 Survivor 区域中,然后清理所使用过的 Eden 以及 Survivor 区域,并且将这些对象的年龄设置为1,以后对象在 Survivor 区每熬过一次 Minor GC,就将对象的年龄 + 1,当对象的年龄达到某个值时 ( 默认是 15 岁,可以通过参数 -XX:MaxTenuringThreshold 来设定 ),这些对象就会成为老年代。 但这也不是一定的,对于一些较大的对象 ( 即需要分配一块较大的连续内存空间 ) 则是直接进入到老年代。


新生代的垃圾回收器共有三个:Serial,Parallel Scavenge 和 Parallel New。这三个采用的都是标记 - 复制算法。其中,Serial 是一个单线程的,Parallel New 可以看成 Serial 的多线程版本。Parallel Scavenge 和 Parallel New 类似,但更加注重吞吐率。此外,Parallel Scavenge 不能与 CMS 一起使用。
老年代的垃圾回收器也有三个:刚刚提到的 Serial Old 和 Parallel Old,以及 CMS。Serial Old 和 Parallel Old 都是标记 - 压缩算法。同样,前者是单线程的,而后者可以看成前者的多线程版本。
CMS 采用的是标记 - 清除算法,并且是并发的。除了少数几个操作需要 Stop-the-world 之外,它可以在应用程序运行过程中进行垃圾回收。在并发收集失败的情况下,Java 虚拟机会使用其他两个压缩型垃圾回收器进行一次垃圾回收。由于 G1 的出现,CMS 在 Java 9 中已被废弃
G1(Garbage First)是一个横跨新生代和老年代的垃圾回收器。实际上,它已经打乱了前面所说的堆结构,直接将堆分成极其多个区域。每个区域都可以充当 Eden 区、Survivor 区或者老年代中的一个。它采用的是标记 - 压缩算法,而且和 CMS 一样都能够在应用程序运行过程中并发地进行垃圾回收
Java对象的创建
在Java中创建对象主要是通过new关键字,当虚拟机遇到new指令时,首先去检查这个指令的参数是否能在常量池中定位到一个类的符号引用.并检查这个类是否已经被加载 解析和初始化,如果没有先执行类的加载过程。
经过上面的步骤,确定类已经被加载后,JVM就会为新生对象分配内存.对象所需的内存大小在类加载完成后就已经确定,所以只需要在Java堆中划分出确定大小的空间。内存的划分方式分为”指针碰撞”和”空闲列表”。
Java通过栈上的本地变量表的reference数据来操作Java堆上的对象。reference数据可以通过句柄或者指针的方式区访问对象。
通过句柄方式的话,Java堆中会划分出一块内存来存放句柄池,reference中存储的是句柄的地址,如图:

指针访问,reference中存储的直接是对象的地址,如图:

强引用:如“Object obj = new Object()”,这类引用是Java程序中最普遍的。只要强引用还存在,垃圾收集器就永远不会回收掉被引用的对象。
软引用:它用来描述一些可能还有用,但并非必须的对象。在系统内存不够用时,这类引用关联的对象将被垃圾收集器回收。JDK1.2之后提供了SoftReference类来实现软引用。
弱引用:它也是用来描述非需对象的,但它的强度比软引用更弱些,被弱引用关联的对象只能生存岛下一次垃圾收集发生之前。当垃圾收集器工作时,无论当前内存是否足够,都会回收掉只被弱引用关联的对象。在JDK1.2之后,提供了WeakReference类来实现弱引用。
虚引用:最弱的一种引用关系,完全不会对其生存时间构成影响,也无法通过虚引用来取得一个对象实例。为一个对象设置虚引用关联的唯一目的是希望能在这个对象被收集器回收时收到一个系统通知。JDK1.2之后提供了PhantomReference类来实现虚引用。
栈内存存放的变量生命周期一旦结束就会被释放,而堆内存存放的实体会被垃圾回收机制不定时的回收。
引用计数器:为每个对象创建一个引用计数,有对象引用时计数器 +1,引用被释放时计数 -1,当计数器为 0 时就可以被回收。它有一个缺点不能解决循环引用的问题;
可达性分析:目前 Java 虚拟机的主流垃圾回收器采取的是可达性分析算法。这个算法的实质在于将一系列 GC Roots 作为初始的存活对象合集(live set),然后从该合集出发,探索所有能够被该集合引用到的对象,并将其加入到该集合中,这个过程我们也称之为标记(mark)。最终,未被探索到的对象便是死亡的,是可以回收的
Java堆中存放着几乎所有的对象实例,垃圾收集器对堆中的对象进行回收前,要先确定这些对象是否还有用,判定对象是否为垃圾对象有如下算法:
- 标记-清除:无用对象全部干掉
- 标记-整理:有用对象都向一边移动,边界以外的全部干掉
- 复制算法:左边内存快满时,将其中要保留的对象复制到右边内存中,然后整体干掉左边内存。右边同理,内存利用率仅有一半
- 分代算法:根据对象存活周期的不同将内存划分为几块,一般是新生代和老年代,新生代基本采用复制算法,老年代采用标记整理算法
给对象添加一个引用计数器,每当有一个地方引用它时,计数器值就加1,当引用失效时,计数器值就减1,任何时刻计数器都为0的对象就是不可能再被使用的。
引用计数算法的实现简单,判定效率也很高,在大部分情况下它都是一个不错的选择,当Java语言并没有选择这种算法来进行垃圾回收,主要原因是它很难解决对象之间的相互循环引用问题。
Java和C#中都是采用根搜索算法来判定对象是否存活的。这种算法的基本思路是通过一系列名为“GC Roots”的对象作为起始点,从这些节点开始向下搜索,搜索所走过的路径称为引用链,当一个对象到GC Roots没有任何引用链相连时,就证明此对象是不可用的。在Java语言里,可作为GC Roots的兑现包括下面几种:
实际上,在根搜索算法中,要真正宣告一个对象死亡,至少要经历两次标记过程:如果对象在进行根搜索后发现没有与GC Roots相连接的引用链,那它会被第一次标记并且进行一次筛选,筛选的条件是此对象是否有必要执行finalize()方法。当对象没有覆盖finalize()方法,或finalize()方法已经被虚拟机调用过,虚拟机将这两种情况都视为没有必要执行。如果该对象被判定为有必要执行finalize()方法,那么这个对象将会被放置在一个名为F-Queue队列中,并在稍后由一条由虚拟机自动建立的、低优先级的Finalizer线程去执行finalize()方法。finalize()方法是对象逃脱死亡命运的最后一次机会(因为一个对象的finalize()方法最多只会被系统自动调用一次),稍后GC将对F-Queue中的对象进行第二次小规模的标记,如果要在finalize()方法中成功拯救自己,只要在finalize()方法中让该对象重引用链上的任何一个对象建立关联即可。而如果对象这时还没有关联到任何链上的引用,那它就会被回收掉。
垃圾收集算法
判定除了垃圾对象之后,便可以进行垃圾回收了。下面介绍一些垃圾收集算法,由于垃圾收集算法的实现涉及大量的程序细节,因此这里主要是阐明各算法的实现思想,而不去细论算法的具体实现。
标记—清除算法是最基础的收集算法,它分为“标记”和“清除”两个阶段:首先标记出所需回收的对象,在标记完成后统一回收掉所有被标记的对象,它的标记过程其实就是前面的根搜索算法中判定垃圾对象的标记过程。标记—清除算法的执行情况如下图所示:
回收前状态:


标记清除后会产生大量不连续的内存碎片,空间碎片太多可能会导致,当程序在以后的运行过程中需要分配较大对象时无法找到足够的连续内存而不得不触发另一次垃圾收集动作。
复制算法是针对标记—清除算法的缺点,在其基础上进行改进而得到的,它讲课用内存按容量分为大小相等的两块,每次只使用其中的一块,当这一块的内存用完了,就将还存活着的对象复制到另外一块内存上面,然后再把已使用过的内存空间一次清理掉。复制算法有如下优点:

回收后状态:


复制算法比较适合于新生代,在老年代中,对象存活率比较高,如果执行较多的复制操作,效率将会变低,所以老年代一般会选用其他算法,如标记—整理算法。该算法标记的过程与标记—清除算法中的标记过程一样,但对标记后出的垃圾对象的处理情况有所不同,它不是直接对可回收对象进行清理,而是让所有的对象都向一端移动,然后直接清理掉端边界以外的内存。标记—整理算法的回收情况如下所示:
回收前状态:


分代收集
Java堆分为新生代和老年代。在新生代中,每次垃圾收集时都会发现有大量对象死去,只有少量存活,因此可选用复制算法来完成收集,而老年代中因为对象存活率高、没有额外空间对它进行分配担保,就必须使用标记—清除算法或标记—整理算法来进行回收。
Java堆分为新生代和老年代。在新生代中,每次垃圾收集时都会发现有大量对象死去,只有少量存活,因此可选用复制算法来完成收集,而老年代中因为对象存活率高、没有额外空间对它进行分配担保,就必须使用标记—清除算法或标记—整理算法来进行回收。
Redis:
缓存雪崩:缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是, 缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中。
缓存穿透:是指恶意攻击请求缓存和数据库中都没有的数据,而用户不断发起请求导致大量请求直接导向DB
解决方案:1.设置攻击的key值为null 并设置短暂过期时间
2. 接口设置拦截,二次缓存 第一次先把所有业务key统一列表缓存,第一次缓存查询 key列表是否存在 不存在则拒绝处理
缓存击穿:缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力
设置过期日期 expire key second:设置key的过期时间(秒)
redis 内存数据集大小上升到一定大小的时候,就会施行数据淘汰策略(回收策略)。
- volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
- volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
- volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
- allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
- allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
- no-enviction(驱逐):禁止驱逐数据
2.redis是单线程的,省去了很多上下文切换线程的时间(cpu在多线程之间进行轮流执行(抢战cpu资源),而redis单线程的,因此避免了繁琐的多线程上下文切换。);
3.redis使用多路复用技术,可以处理并发的连接(多个socket连接,复用-指的是复用一个线程);
惰性删除为被动删除:用到的时候才会去检验key是不是已过期,过期就删除
- 第一、配置redis.conf 的hz选项,默认为10 (即1秒执行10次,100ms一次,值越大说明刷新频率越快,最Redis性能损耗也越大)
- 第二、配置redis.conf的maxmemory最大值,当已用内存超过maxmemory限定时,就会触发主动清理策略
hset/hget 存储的是一个数据对象,相当于在学校塞入学生的时候,确定好了班级,查找的时候,先找到班级再找学生。
对于大量数据而言 hset/hget 要优于 set/get。
1 、Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
2 、Redis支持数据的备份,即master-slave模式的数据备份。
3 、Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用
从以下几个维度,对redis、memcache、mongoDB 做了对比,
总体来讲,TPS方面redis和memcache差不多,要大于mongodb
redis丰富一些,数据操作方面,redis更好一些,较少的网络IO次数
mongodb支持丰富的数据表达,索引,最类似关系型数据库,支持的查询语言非常丰富
redis在2.0版本后增加了自己的VM特性,突破物理内存的限制;可以对key value设置过期时间(类似memcache)
mongoDB适合大数据量的存储,依赖操作系统VM做内存管理,吃内存也比较厉害,服务不要和别的服务在一起
redis,依赖客户端来实现分布式读写;主从复制时,每次从节点重新连接主节点都要依赖整个快照,无增量复制,因性能和效率问题,
所以单点问题比较复杂;不支持自动sharding,需要依赖程序设定一致hash 机制。
一种替代方案是,不用redis本身的复制机制,采用自己做主动复制(多份存储),或者改成增量复制的方式(需要自己实现),一致性问题和性能的权衡
Memcache本身没有数据冗余机制,也没必要;对于故障预防,采用依赖成熟的hash或者环状的算法,解决单点故障引起的抖动问题。
mongoDB支持master-slave,replicaset(内部采用paxos选举算法,自动故障恢复),auto sharding机制,对客户端屏蔽了故障转移和切分机制。
redis支持(快照、AOF):依赖快照进行持久化,aof增强了可靠性的同时,对性能有所影响
MongoDB从1.8版本开始采用binlog方式支持持久化的可靠性
mongoDB内置了数据分析的功能(mapreduce),其他不支持
memcache:用于在动态系统中减少数据库负载,提升性能;做缓存,提高性能(适合读多写少,对于数据量比较大,可以采用sharding)
临界区:临界区用来表示一种公共资源或者是共享数据,可以被多个线程使用。但是每一次,只能有一个线程使用它,一旦临界区资源被占用,其他线程要想使用这个资源,就必须等待。

- SOA和微服务架构的区别?

SpringCloud项目简介
springCloud是基于SpringBoot的一整套实现微服务的框架。他提供了微服务开发所需的配置管理、服务发现、断路器、智能路由、微代理、控制总线、全局锁、决策竞选、分布式会话和集群状态管理等组件。最重要的是,
跟spring boot框架一起使用的话,会让你开发微服务架构的云服务非常好的方便。
SpringBoot旨在简化创建产品级的 Spring 应用和服务,简化了配置文件,使用嵌入式web服务器,含有诸多开箱即用微服务功能


Spring Cloud Config:配置管理开发工具包,可以让你把配置放到远程服务器,目前支持本地存储、Git以及Subversion。
Spring Cloud Bus:事件、消息总线,用于在集群(例如,配置变化事件)中传播状态变化,可与Spring Cloud Config联合实现热部署。
Spring Cloud Netflix:针对多种Netflix组件提供的开发工具包,其中包括Eureka、Hystrix、Zuul、Archaius等。
Netflix Eureka(读音:优瑞卡):云端负载均衡,一个基于 REST 的服务,用于定位服务,以实现云端的负载均衡和中间层服务器的故障转移。我们可以将自己定义的API 接口注册到Spring Cloud Eureka上,Eureka负责服务的注册于发现,Eureka的角色和 Zookeeper的角色差不多,都是服务的注册和发现,构成Eureka体系的包括:服务注册中心、服务提供者、服务消费者。
Netflix Hystrix(海斯拽克斯):容错管理工具,旨在通过控制服务和第三方库的节点,从而对延迟和故障提供更强大的容错能力。Spring Cloud Hystrix是防止对某一故障服务持续进行访问。Hystrix的含义是:断路器,断路器本身是一种开关装置,用于我们家庭的电路保护,防止电流的过载,当线路中有电器发生短路的时候,断路器能够及时切换故障的电器,防止发生过载、发热甚至起火等严重后果。
Netflix Zuul(读音:如儿):【服务网关】边缘服务工具,是提供动态路由,监控,弹性,安全等的边缘服务。服务网关是微服务架构中一个不可或缺的部分。通过服务网关统一向外系统提供REST API的过程中,除了具备服务路由、均衡负载功能之外,它还具备了权限控制等功能。Spring Cloud Netflix中的Zuul就担任了这样的一个角色,为微服务架构提供了前门保护的作用,同时将权限控制这些较重的非业务逻辑内容迁移到服务路由层面,使得服务集群主体能够具备更高的可复用性和可测试性。
Netflix Archaius:配置管理API,包含一系列配置管理API,提供动态类型化属性、线程安全配置操作、轮询框架、回调机制等功能。
Spring Cloud for Cloud Foundry:通过Oauth2协议绑定服务到CloudFoundry,CloudFoundry是VMware推出的开源PaaS云平台。
Spring Cloud Sleuth:日志收集工具包,封装了Dapper,Zipkin和HTrace操作。
Spring Cloud Data Flow:大数据操作工具,通过命令行方式操作数据流。
Spring Cloud Security:安全工具包,为你的应用程序添加安全控制,主要是指OAuth2。
Spring Cloud Consul(读音:康搜):封装了Consul操作,consul是一个服务发现与配置工具,与Docker容器可以无缝集成。
Spring Cloud Zookeeper(读音:如kei普儿):操作Zookeeper的工具包,用于使用zookeeper方式的服务注册和发现。
Spring Cloud Stream:数据流操作开发包,封装了与Redis,Rabbit、Kafka等发送接收消息。
Spring Cloud CLI:基于 Spring Boot CLI,可以让你以命令行方式快速建立云组件。
Spring Cloud Feign(读音:芬儿):Spring Cloud Feign 是一个声明web服务客户端,这使得编写Web服务客户端更容易,使用Feign 创建一个接口并对它进行注解,它具有可插拔的注解支持包括Feign注解与JAX-RS注解,Feign还支持可插拔的编码器与解码器,Spring Cloud 增加了对 Spring MVC的注解,Spring Web 默认使用了HttpMessageConverters, Spring Cloud 集成 Ribbon 和 Eureka 提供的负载均衡的HTTP客户端 Feign。简单的可以理解为:Spring Cloud Feign 的出现使得Eureka和Ribbon的使用更为简单。
--------------------- --------------------- --------------------- --------------------- --------------------- --------------
@EnableAutoConfiguration
启动自动装载:使用了这个注解之后,所有引入的jar的starters都会被自动注入。这个类的设计就是为starter工作的。
这个注解专门用于写RESTful的接口的,里面集成了@Controller和@ResponseBody注解。
@ResponseBody 这个注解会自动利用默认的Jackson将return的对象序列化成json格式。
@SpringBootApplication注解等价于以默认属性使用 @Configuration , @EnableAutoConfiguration
生产者将消息发送到指定的交换机,交换机再将消息发送到各个消息队列
在RPC请求中,定义了两个属性:replyTo,表示回调队列的名称; correlationId,表示请求任务的唯一编号,用来区分不同请求的返回结果。
RPC服务器等待rpc_queue队列的请求,如果有消息,就处理,它将计算结果发送到请求中的回调队列里。
客户端监听回调队列中的消息,如果有返回消息,它根据回调消息中的correlationid进行匹配计算结果。
通过匹配交换器,我们可以配置更灵活的消息系统,你可以在匹配交换器模式下发送这样的路由关键字:
“a.b.c”、“c.d”、“quick.orange.rabbit”
不过一定要记住,路由关键字【routingKey】不能超过255个字节(bytes)
削峰填谷,缓冲上下游瞬时突发流量,使其更平滑。特别是对于那种发送能力很强的上游系统,如果没有消息引擎的保护,“脆弱”的下游系统可能会直接被压垮导致全链路服务“雪崩”
kafka是用Replication(备份机制)和多个Broker(多个客户端分散在不同服务器)实现高可用的;备份的思想很简单,就是把相同的数据拷贝到多台机器上,而这些相同的数据拷贝在 Kafka 中被称为副本(Replica)。
Kafka 定义了两类副本:领导者副本(Leader Replica)和追随者副本(Follower Replica)。前者对外提供服务,这里的对外指的是与客户端程序进行交互;而后者只是被动地追随领导者副本而已,不能与外界进行交互。
即一个 Kafka 集群由多个 Broker 组成,Broker 负责接收和处理客户端发送过来的请求,以及对消息进行持久化。虽然多个 Broker 进程能够运行在同一台机器上,但更常见的做法是将不同的 Broker 分散运行在不同的机器上,这样如果集群中某一台机器宕机,即使在它上面运行的所有 Broker 进程都挂掉了,其他机器上的 Broker 也依然能够对外提供服务。这其实就是 Kafka 提供高可用的手段之一。
kafka副本的工作机制:生产者总是向领导者副本写消息;而消费者总是从领导者副本读消息。至于追随者副本,它只做一件事:向领导者副本发送请求,请求领导者把最新生产的消息发给它,这样它能保持与领导者的同步。
发布 / 订阅模型:一个主题(Topic)的概念,你可以理解成逻辑语义相近的消息容器。该模型也有发送方和接收方,只不过提法不同。发送方也称为发布者(Publisher),接收方称为订阅者(Subscriber)。和点对点模型不同的是,这个模型可能存在多个发布者向相同的主题发送消息,而订阅者也可能存在多个,它们都能接收到相同主题的消息。生活中的报纸订阅就是一种典型的发布 / 订阅模型。副本机制可以保证数据的持久化或消息不丢失。
分区(Partitioning)把数据分割成多份保存在不同的 Broker 上;Kafka 中的分区机制指的是将每个主题划分成多个分区(Partition),每个分区是一组有序的消息日志。生产者生产的每条消息只会被发送到一个分区中,也就是说如果向一个双分区的主题发送一条消息,这条消息要么在分区 0 中,要么在分区 1 中。如你所见,Kafka 的分区编号是从 0 开始的,如果 Topic 有 100 个分区,那么它们的分区号就是从 0 到 99。
- 第一层是主题层,每个主题可以配置 M 个分区,而每个分区又可以配置 N 个副本。
- 第二层是分区层,每个分区的 N 个副本中只能有一个充当领导者角色,对外提供服务;其他 N-1 个副本是追随者副本,只是提供数据冗余之用。
- 第三层是消息层,分区中包含若干条消息,每条消息的位移从 0 开始,依次递增。
- 最后,客户端程序只能与分区的领导者副本进行交互。
Kafka 使用消息日志(Log)来保存数据,一个日志就是磁盘上一个只能追加写(Append-only)消息的物理文件。因为只能追加写入,故避免了缓慢的随机 I/O 操作,改为性能较好的顺序 I/O 写操作,这也是实现 Kafka 高吞吐量特性的一个重要手段。在 Kafka 底层,一个日志又近一步细分成多个日志段,消息被追加写到当前最新的日志段中,当写满了一个日志段后,Kafka 会自动切分出一个新的日志段,并将老的日志段封存起来。Kafka 在后台还有定时任务会定期地检查老的日志段是否能够被删除,从而实现回收磁盘空间的目的。
kafka为什么要引入消费者组呢?(Consumer Group)
主要是为了提升消费者端的吞吐量。多个消费者实例同时消费,加速整个消费端的吞吐量(TPS)。消费者组里面的所有消费者实例不仅“瓜分”订阅主题的数据,而且更酷的是它们还能彼此协助。假设组内某个实例挂掉了,Kafka 能够自动检测到,然后把这个 Failed 实例之前负责的分区转移给其他活着的消费者。这个过程就是 Kafka 中大名鼎鼎的“重平衡”(Rebalance)。
消费者位移(Consumer Offset);表征消费者消费进度,每个消费者都有自己的消费者位移。

冷门面试题:
在Java中,有一种key值可以重复的map,就是IdentityHashMap。在IdentityHashMap中,判断两个键值k1和 k2相等的条件是 k1 == k2 。在正常的Map 实现(如 HashMap)中,当且仅当满足下列条件时才认为两个键 k1 和 k2 相等:(k1==null ? k2==null : e1.equals(e2))。
TCC 采用最终一致性的方式实现了一种柔性分布式事务,与 XA 规范实现的二阶事务不同的是,TCC 的实现是基于服务层实现的一种二阶事务提交。
TCC 分为三个阶段,即 Try、Confirm、Cancel 三个阶段。

- Try 阶段:主要尝试执行业务,执行各个服务中的 Try 方法,主要包括预留操作;
- Confirm 阶段:确认 Try 中的各个方法执行成功,然后通过 TM 调用各个服务的 Confirm 方法,这个阶段是提交阶段;
- Cancel 阶段:当在 Try 阶段发现其中一个 Try 方法失败,例如预留资源失败、代码异常等,则会触发 TM 调用各个服务的 Cancel 方法,对全局事务进行回滚,取消执行业务。
如果在 Confirm 和 Cancel 阶段出现异常情况,那 TCC 该如何处理呢?
此时 TCC 会不停地重试调用失败的 Confirm 或 Cancel 方法,直到成功为止。
- 下单减库存,即当买家下单后,在商品的总库存中减去买家购买数量。下单减库存是最简单的减库存方式,也是控制最精确的一种,下单时直接通过数据库的事务机制控制商品库存,这样一定不会出现超卖的情况。但是你要知道,有些人下完单可能并不会付款。
- 付款减库存,即买家下单后,并不立即减库存,而是等到有用户付款后才真正减库存,否则库存一直保留给其他买家。但因为付款时才减库存,如果并发比较高,有可能出现买家下单后付不了款的情况,因为可能商品已经被其他人买走了。
- 预扣库存,这种方式相对复杂一些,买家下单后,库存为其保留一定的时间(如 10 分钟),超过这个时间,库存将会自动释放,释放后其他买家就可以继续购买。在买家付款前,系统会校验该订单的库存是否还有保留:如果没有保留,则再次尝试预扣;如果库存不足(也就是预扣失败)则不允许继续付款;如果预扣成功,则完成付款并实际地减去库存。
一种是在应用程序中通过事务来判断,即保证减后库存不能为负数,否则就回滚;
另一种办法是直接设置数据库的字段数据为无符号整数,这样减后库存字段值小于零时会直接执行 SQL 语句来报错;
再有一种就是使用 CASE WHEN 判断语句,例如这样的 SQL 语句:
UPDATE item SET inventory = CASE WHEN inventory >= xxx THEN inventory-xxx ELSE inventory END
秒杀中并不需要对库存有精确的一致性读,把库存数据放到缓存(Cache)中,可以大大提升读性能。
- 应用层做排队。按照商品维度设置队列顺序执行,这样能减少同一台机器对数据库同一行记录进行操作的并发度,同时也能控制单个商品占用数据库连接的数量,防止热点商品占用太多的数据库连接。
- 数据库层做排队。应用层只能做到单机的排队,但是应用机器数本身很多,这种排队方式控制并发的能力仍然有限,所以如果能在数据库层做全局排队是最理想的。阿里的数据库团队开发了针对这种 MySQL 的 InnoDB 层上的补丁程序(patch),可以在数据库层上对单行记录做到并发排队。
而“乐观锁”则是认为大部分情况不会出现冲突,进而决定是否采取排他性措施。
悲观锁一般就是利用类似 SELECT … FOR UPDATE 这样的语句,对数据加锁,避免其他事务意外修改数据
乐观锁则与 Java 并发包中的 AtomicFieldUpdater 类似,也是利用 CAS 机制,并不会对数据加锁,而是通过对比数据的时间戳或者版本号,来实现乐观锁需要的版本判断。

- Redis 实现分布式锁
Redis 实现分布式锁的方式,都是使用 SETNX+EXPIRE 组合来实现;
通过 setnx() 方法设置锁,如果 lockKey 存在,则返回失败,否则返回成功。设置成功之后,为了能在完成同步代码之后成功释放锁,方法中还需要使用 expire() 方法给 lockKey 值设置一个过期时间,确认 key 值删除,避免出现锁无法释放,导致下一个线程无法获取到锁,即死锁问题。
public static boolean tryGetDistributedLock(Jedis jedis, String lockKey, String requestId, int expireTime) {
Long result = jedis.setnx(lockKey, requestId);// 设置锁
jedis.expire(lockKey, expireTime);// 通过过期时间删除锁
如果程序在设置过期时间之前、设置锁之后出现崩溃,此时如果 lockKey 没有设置过期时间,将会出现死锁问题。
Redisson 中实现了 Redis 分布式锁,且支持单点模式和集群模式。在集群模式下,Redisson 使用了 Redlock 算法,避免在 Master 节点崩溃切换到另外一个 Master 时,多个应用同时获得锁。















 844
844











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









