







前言
上篇博客已经推导出了原始最优化问题,这篇博客将会将问题利用拉格朗日对偶化使问题的到简化以方便处理。
拉格朗日对偶
让我们先暂时把SVM和最大化间隔分类器搁置在一边,来讨论解决限制最优化问题。
考虑一个如下形式的问题:
minwf(w)
s.t.hi(w)=0,i=1,...,l
我们使用拉格朗日数乘法来解决这个问题。在这个方法中,我们定义拉格朗日方程为:
L(w,β)=f(w)+∑li=1βihi(w)
这里,
βi
叫做拉格朗日乘数。我们可以通过令偏导数等于0来解决找到符合条件的
w
和
∂L∂wi=0
;
∂L∂βi=0
;
在这节中,我们将会泛化等式约束最优化问题到不等式约束。
考虑下面的问题我们称之为原始最优化问题:
minwf(w)
s.t.gi(w)≤0,i=1,....,k
hi(w)=0,i=1,.....,l
为了解决这个问题,我们首先定义泛化拉格朗日方程:
L(w,α,β)=f(w)+∑ki=1αigi(w)+∑li=1βihi(w)
这里,
αi
和
βi
叫做拉个朗日乘数,考虑这个等式:
ΘP(w)=maxα,β:αi≥0L(w,α,β)
这里“
P
”代表“原始”。如果
w
违反了任何原始约束条件(如果
你可以证实:
ΘP(w)=∞
因此,
ΘP
在所有的
w
满足初始条件的情况下与目标问题获得相同的值。因此,如果我们考虑最小化问题
我们看到这和我们描述的原始问题相同。在接下来,我们同样定义最优化值的目标为:
p∗=minwΘP(w)
现在来让我看一个有点不同的问题。我们定义:
ΘD(α,β)=maxwΘP(w)
这里的
D
代表的是”对偶”。介于定义
ΘP
是使问题最优化对应的
α,β
,这里代表的是使问题最小化对应的
w
。
现在我们能提出对偶最优化问题:
这里和我们之前提到的问题完全相同,除了”max”和”min”的顺序改变了。我们同样定义对偶问题的最优化值为
d∗=maxα,β:αi≥0ΘD(α,β)
对偶问题和原始问题是如何联系在一起的?可以通过下式:
d∗=maxα,β:αi≥0ΘD(α,β)≤minwmaxα,β:αi≥0L(w,α,β)=p∗
因此,在某些特定的条件下我们可以得到:
d∗=p∗
因此我们就可以通过对偶问题代替原始问题。让我们来看看条件是什么。
假设
f
和
基于上面的假设,一定存在这样的
w∗,α∗,β∗
,其中
w∗
是原始问题的解,
α∗,β∗
是对偶问题的最优解,同时
p∗=d∗=L(w∗,α∗,β∗)
。同时
w∗,α∗和β∗
满足KKT条件如下:
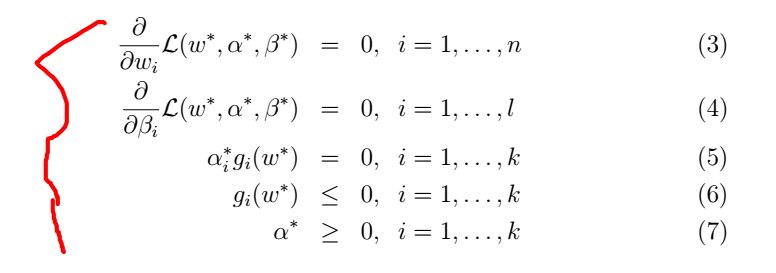
如果,一些
w∗,α∗,β∗
满足KKT条件,那么他们同时也是原始问题和对偶问题的解。
我们把注意力放在等式(5),叫做KKT对偶互补条件。特别的,它暗示了如果
α∗i>0
,那么
gi(w∗)=0
(比如”
gi(w)≤0
”约束条件满足,意味着此时满足等式而不是不等式)之后我们将会证明SVM只有很少的支持向量;当我们使用SMO算法时,KKT对偶互补条件同时也会提供我们收敛测试。
2 最优化间隔分类器
之前我们为了找到最优化间隔分类器我们提出的原始最优化问题如下:
minγ,w,b12||w||2s.t.y(i)(wTx(i)+b)≥1,i=1,…,m
我们可以把约束条件表示为:
gi(w)=−y(i)(wTx(i)+b)+1≤0
我们对于每个训练样例都有这样的约束条件。由于KKT对偶互补条件,我们可以得到只有训练样例的
αi>0
才能得到函数间隔等于1(等价于对应的约束条件满足
gi(w)=0
。考虑下图,其中最大间隔分隔超平面用实线表示。
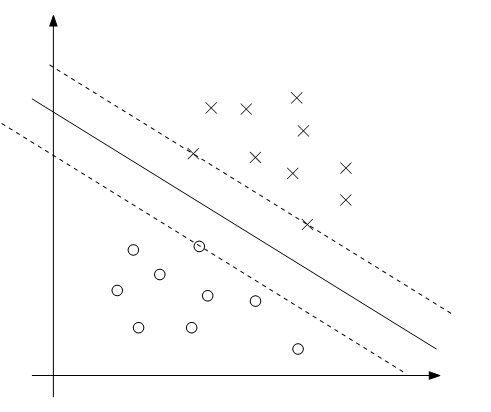
离决策边界最近的点就是有最小间隔的点;这里,有三个点(两正一负)位于平行于决策边界的虚线上,他们对应的
α
是非零的对于最优解问题。这三个点在这个问题里被叫做支持向量。事实是支持向量要比训练集少的很多将会在以后有用。
我们构造我们最初的最优化问题的拉格朗日方程:
L(w,b,α)=12||w||2−∑mi=1αi[y(i)(wTx(i)+b−1]
(8)
让我们找出这个问题的对偶问题。首先,我们要找出使
L(w,b,α)
最小化对应的
w,b
(固定
α
),得到了
ΘD
,因此我们需要对
L
做关于w和b的偏导数并使之等于0。我们有:
∇L(w,b,α)=w−∑mi=1αiy(i)x(i)=0
因此可以得到:
w=∑mi=1αiy(i)x(i)
(9)
对b求导可以得:
∂∂bL(w,b,α)=∑mi=1αiy(i)=0
(10)
如果我们把等式(9)带回到拉格朗日方程组,化解可以得到:
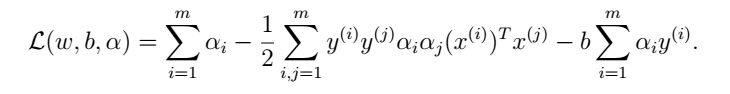
由于等式(10)最后一项等于0:,可以得到:
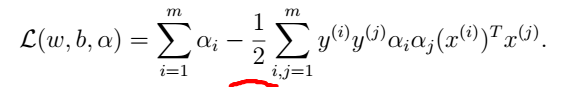
回想我们得到上述等式通过使最小化
L
对应的
w,b
,把这些和约束条件
αi≥0
和约束条件(10),我们获得如下的对偶问题:
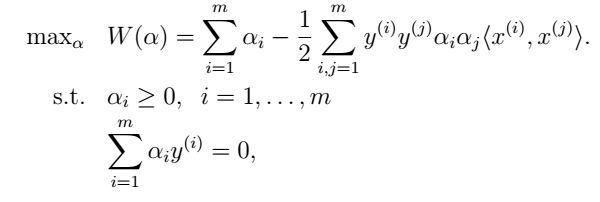
可以证实其确实满足KKT条件。因此我们可以用对偶问题代替原始问题。特别的,对偶问题中,我们要得到最大化问题对应的参数
αi
,在找到
α
之后可以通过等式(9)来求得
w
。在已经找到
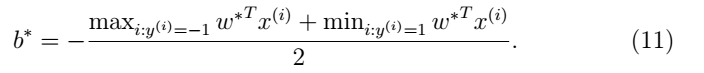
在等式(9)中,假设我们已经找到了一个训练样集的参数模型,我们想要预测一个新输入点x的值。我们可以计算
wTx+b
并且预测y=1当且仅当值大于0,但是使用(9)可以得到如下等式:
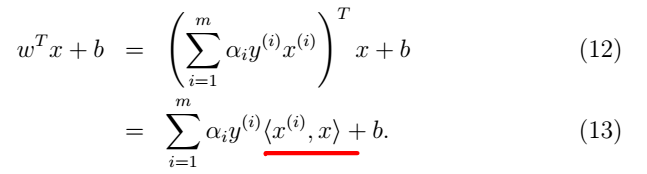
因此,如果我们已经找到了
αi
为了做预测我们要让
x
和所有的训练样例做内积。然而我们之前讨论过大多数的
下一篇博客将会介绍核,从而进一步提高SVM算法在高维空间的有效性。















 9860
9860

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









