







Distributed representations of words and phrases and their compositionality
基本信息
@inproceedings{mikolov2013distributed,
title={Distributed representations of words and phrases and their compositionality},
author={Mikolov, Tomas and Sutskever, Ilya and Chen, Kai and Corrado, Greg S and Dean, Jeff},
booktitle={Advances in neural information processing systems},
pages={3111–3119},
year={2013}
}
Abstract
- 研究内容:
continuous Skip-gram model → \rightarrow → distributed vector representations → \rightarrow → capture precise syntactic and semantic word relationships - 本文工作:提高词向量的质量与训练速度
- subsampling of the frequent words → \rightarrow → 提高训练速度,学习更常规的单词表征
- negative sampling:hierarchical softmax的简单替代
- 词表征的inherent limitation:
- 无差异的对待词序信息
- 不能表达习语 → \rightarrow → 本文:提出一个找到文本中习语的方法,展示学习习语向量表征的可能性。
Ⅰ. Introduction
- word representations的提出及应用
- 词的分布式表达:聚类相似的单词 → \rightarrow → 提高了自然语言处理任务的性能
- 提出:1986,Rumelhart, Hinton, and Williams
- 应用:statistical language modeling → \rightarrow → 自动语音识别,机器翻译,等一系列NLP tasks
- previous work:
- Mikolov, Skip-gram model (learn from unstructured text data)
- 优势:不包含稠密的矩阵乘法运算
→
\rightarrow
→ 计算高效
→
\rightarrow
→ 单机,100billion words, one day
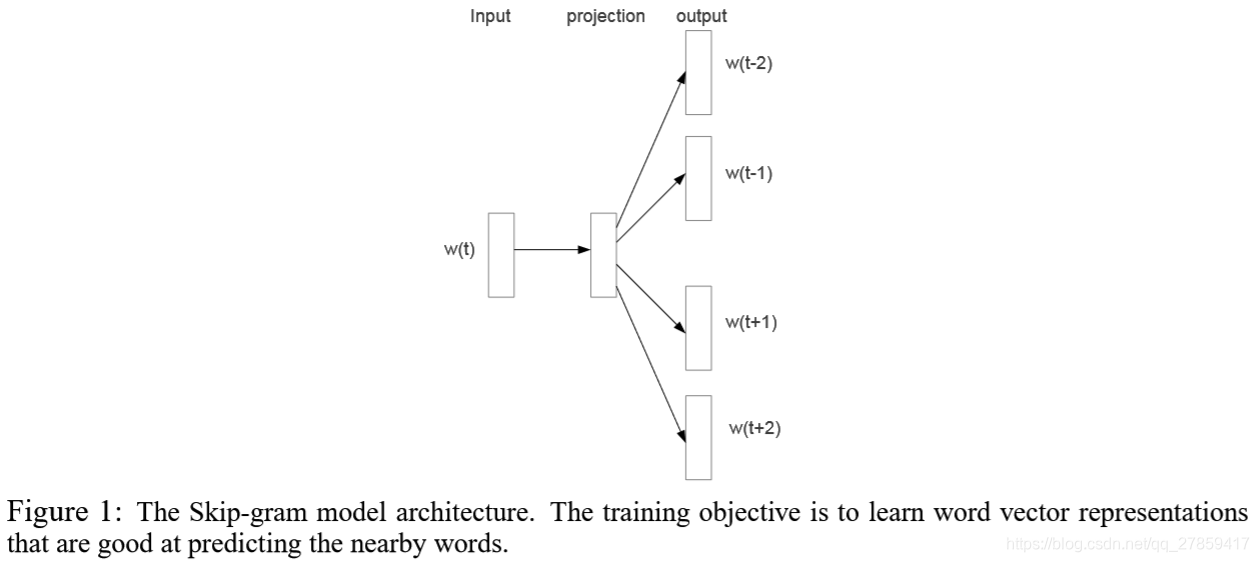
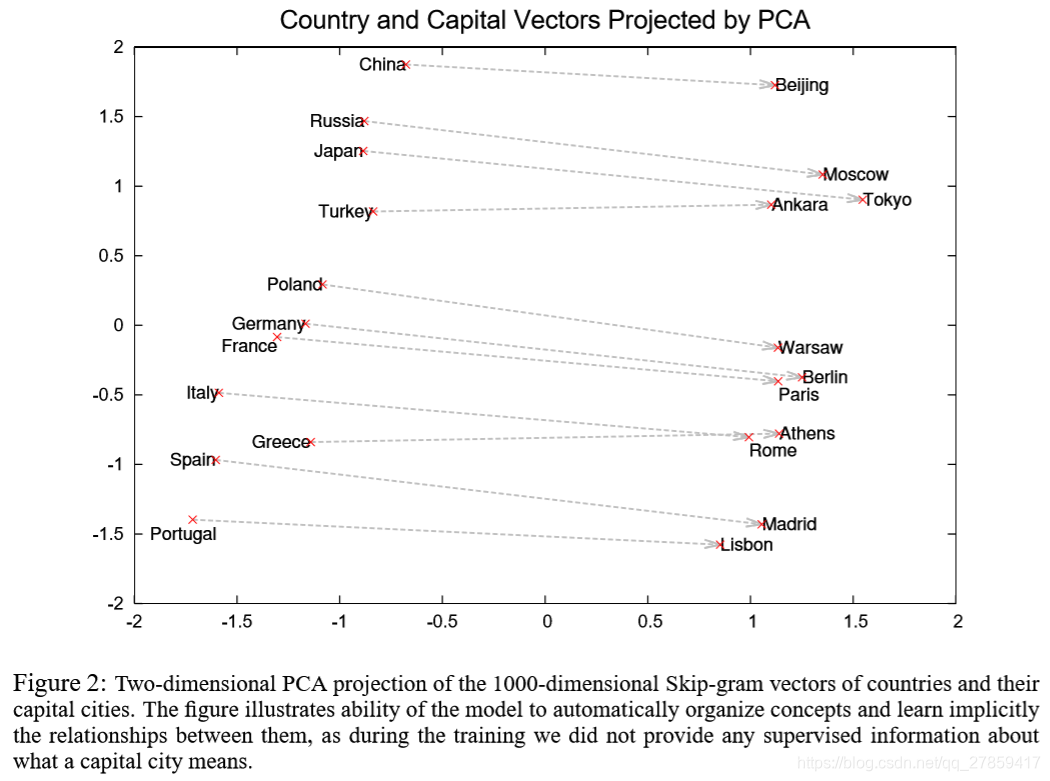
- 词向量的特点:
- learned vectors explicitly encode many linguistic regularities and patterns
- linear translations:vec(“Madrid”) - vec(“Spain”) + vec(“France”) = vec(“Paris”)
- 本文工作:Skip-gram model的升级版
- subsampling of frequent words(训练)
- 速度:significant speedup (around 2x - 10x)
- 低频词的表征:improves accuracy of the representations of less frequent words
- Noise Contrastive Estimation (NCE)的简单变体,替代了复杂的hierarchical softmax
- 速度:results in faster training
- 高频词的表征:better vector representations for frequent words
- subsampling of frequent words(训练)
- Word representations的局限:不能表征习语
→
\rightarrow
→ 令Skip-gram model可以表征习语是considerably more expressive
- 一项表征句子含义的技术:recursive autoencoders,使用phrase vector会比word vector表现更好
- 由word vector
→
\rightarrow
→ phrase vector
- 方法:以data-driven的方式识别大量phrases → \rightarrow → 将这些phrases当作individual tokens
- 测评:analogical reasoning tasks类比推理任务
- vec(“Montreal Canadiens”) - vec(“Montreal”) + vec(“Toronto”) = vec(“Toronto Maple Leafs”)
- Skip-gram model的一些有趣性质:
- 我们发现简单的向量加法通常可以产生有意义的结果: vec(“Russia”) + vec(“river”) $\approx $ vec(“Volga River”)
- 语义合成性:通过对词向量表示的基本数学运算,可以获得不明显的语言理解程度
Ⅱ. The Skip-gram Model
- 训练目标:根据中心词,预测周围的单词
- 目标函数:最大化平均对数概率
max 1 T ∑ t = 1 T ∑ − c ≤ j ≤ c , j ≠ 0 l o g p ( w t + j ∣ w t ) \max \frac{1}{T}\sum_{t=1}^{T}\sum_{-c\le j \le c,j\ne 0} log p(w_{t+j}\mid w_t) maxT1t=1∑T−c≤j≤c,j=0∑logp(wt+j∣wt)
p ( w O ∣ w I ) = e x p ( v w o ′ T v w I ) ∑ w = 1 W e x p ( v w ′ T v w I ) p(w_O \mid w_I) = \frac{{exp(v'_{w_o}}^Tv_{w_I})}{\sum_{w=1}^{W}{exp(v'_{w}}^Tv_{w_I})} p(wO∣wI)=∑w=1Wexp(vw′TvwI)exp(vwo′TvwI)
c c c:中心词的窗口大小, c c c越大 → \rightarrow → high accuracy, expense of the training time
v w v_w vw, v w ′ v'_w vw′:the “input” and “output” vector representations of w
备注:同一个单词有两个词向量,一个是作为中心词的词向量,一个是作为预测的周围单词的词向量
W W W:词典的大小
impractical不切实际的, ▽ p ( w O ∣ w I ) \bigtriangledown p(w_O \mid w_I) ▽p(wO∣wI)与 W W W成比例,通常在( 1 0 5 – 1 0 7 10^5–10^7 105–107 terms).
2.1 Hierarchical Softmax

- 利用hierarchical softax近似softmax的计算
- 首次提出:Morin and Bengio
- 计算复杂度有 O ( W ) O(W) O(W) 变为了 l o g 2 ( W ) log_2(W) log2(W)
- 方法:利用二叉树表示输出层的W各单词,W各单词为其叶节点;对于每个节点,表征了子节点的相对概率;碘杠一了一种random walk为单词分配概率
- 计算:
p ( w ∣ w i ) = ∏ j = 1 L ( w ) − 1 σ ( 【 n ( n ( w , j + 1 ) = c h ( n ( w , j ) ) 】 ⋅ v n ( w , j ) ′ T w w I ) p(w \mid w_i) = \prod_{j=1}^{L(w)-1}\sigma(【n(n(w,j+1)=ch(n(w,j))】 \cdot {v'_{n(w,j)}}^Tw_{wI}) p(w∣wi)=j=1∏L(w)−1σ(【n(n(w,j+1)=ch(n(w,j))】⋅vn(w,j)′TwwI)
n ( w , j ) n(w,j) n(w,j):从根节点到单词w的第j个中间节点
L ( w ) L(w) L(w):cong根节点到单词w的路径长度
c h ( n ) ch(n) ch(n):固定的子节点(左节点or右节点)
【 x 】 【x】 【x】:若x是true,则为1;反之为-1
σ ( x ) = 1 1 + e x p ( − x ) → ∑ w = 1 W p ( w ∣ w I ) = 1 \sigma(x) = \frac{1}{1+exp(-x)} \rightarrow \sum_{w=1}^{W}p(w\mid w_I)=1 σ(x)=1+exp(−x)1→∑w=1Wp(w∣wI)=1 - 特点:
- p ( w O ∣ w I ) p(wO \mid w_I) p(wO∣wI)与 ▽ p ( w O ∣ w I ) \bigtriangledown p(w_O \mid w_I) ▽p(wO∣wI)的计算复杂度与 L ( w O ) L(w_O) L(wO)成比例
- 不同于标准的Skip-gram,为每个单词分配两个表征 v w v_w vw,与 v w ′ v'_w vw′,hierarchical softmax为每个单词分配一个词向量 v w v_w vw,以及为每个内部节点分配向量表征 v n ′ v'_n vn′
- 优势:has a considerable effect on the performance
- Mnith and Hinton提出了构建树结构的方法,并且分析了对训练时间与模型准确率的影响
- 本文:Huffman树,高频词的编码较短(靠近根节点) → \rightarrow → fast training
- 在神经网络语言模型中,将单词按频率分组是一种非常简单的加速技术
2.2 Negative Sampling
- Noise Constrastive Estimation (NCE)
- hierarchical softmax的替代选择
- 由Gutmann and Hyvarinen提出,Mnih and Teh应用于语言模型
- 思路:一个好的模型应该能够通过逻辑回归将数据与噪声区分开来
- 类似工作:hinge loss, Collobert and Weston, 将数据置于噪声之上来训练模型
- NCE,近似,最大化softmax的log概率
→
\rightarrow
→ 只要保证vector的质量,可适度简化
→
\rightarrow
→ 定义了Negative sampling (NEG)
→
\rightarrow
→ 代替
l
o
g
P
(
w
O
∣
w
I
)
log P(w_O \mid w_I)
logP(wO∣wI)
l o g σ ( v w O ′ T v w I ) + ∑ i = 1 k E w i ∼ P n ( w ) [ l o g σ ( − v w i ′ T v w I ) ] log \sigma ({v'_{w_O}}^Tv_{w_I}) + \sum_{i=1}^{k}\mathbb{E}_{w_i \sim P_n(w)}[log \sigma{(-v'_{w_i}}^Tv_{w_I})] logσ(vwO′TvwI)+i=1∑kEwi∼Pn(w)[logσ(−vwi′TvwI)] - 目标:利用logistic回归将目标词 w O w_O wO与噪声分布 P n ( w ) P_n(w) Pn(w)进行区分,其中每个数据样本都有k个负样本。
- 经验值:
- small training datasets:$k=5 \sim 20 $
- large training datasets:$k=2 \sim 5 $
- NCE与NEG的区别:
- NCE:需要样本及噪声分布的数值概率;NEG:需要样本
- NCE近似地最大化了softmax的对数概率,但是这个特性对我们的应用程序并不重要
- 噪声分布 P n ( w ) P_n(w) Pn(w)的选择: U ( w ) 3 4 / Z U(w)^{\frac{3}{4}}/Z U(w)43/Z ,均匀分布
2.3 Subsampling of Frequent Words
- 思想:高频出现的词,信息价值很少 → \rightarrow → the经常与很多单词co-occurs → \rightarrow → 经过长时间训练,词向量没有显著的改变 → \rightarrow → 平衡rare and frequency words → \rightarrow → 对每个词按概率进行discard
- 概率计算:
P
(
w
i
)
=
1
−
t
f
(
w
i
)
P(w_i) = 1- \sqrt{\frac{t}{f(w_i)}}
P(wi)=1−f(wi)t
$ f(w_i) : 单 词 :单词 :单词w_i$的频率
t t t:阈值, 1 0 − 5 10^{-5} 10−5 - 优势:
- 在保留频率排序的同时,对频率大于 t t t的词进行了启发式的子抽样
- 加快了学习速度,提高了罕见词词向量的准确性
Ⅲ. Empirical Results
- 对比方法:
- Hierarchical Softmax (HS)
- Noise Contrastive Estimation
- Negative Sampling
- Subsampling of frequent words
- 测评任务:analogicalreasoning task → \rightarrow → 语义推理、语法推理
- 数据集:large dataset (news articles, one billion words, Google),去除频次低于5的单词
→
\rightarrow
→ vocabulary of size 692K
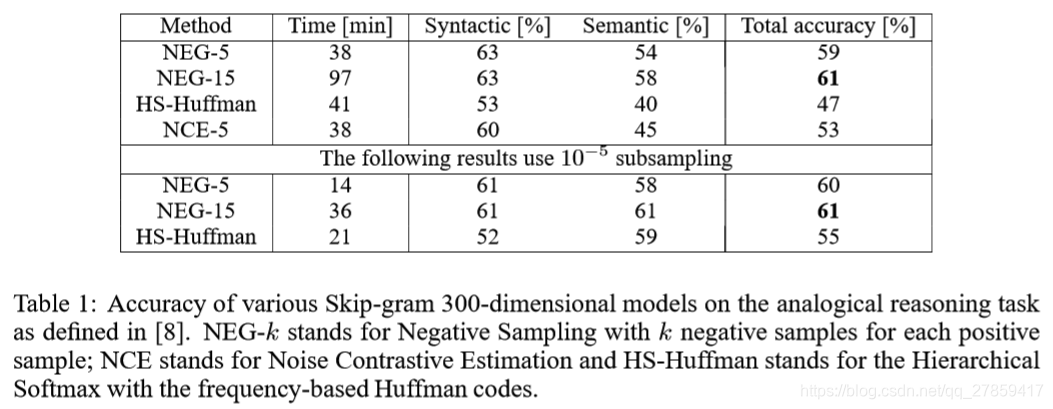
- 结论:
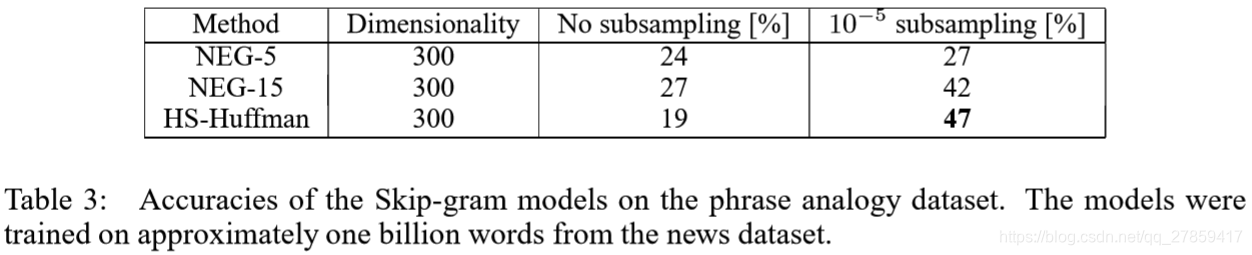
- Negative Sampling优于Hierarchical Softmax,稍好于Noise Contrastive Estimation
- Subsampling of frequent words提高了几倍的训练速度,准确率
- 线性的skip-gram模型 适合 线性类比推理;增加训练样本也可显著改善sigmoidal recurrent neural networks 的性能 → \rightarrow → 非线性模型也偏爱线性结构
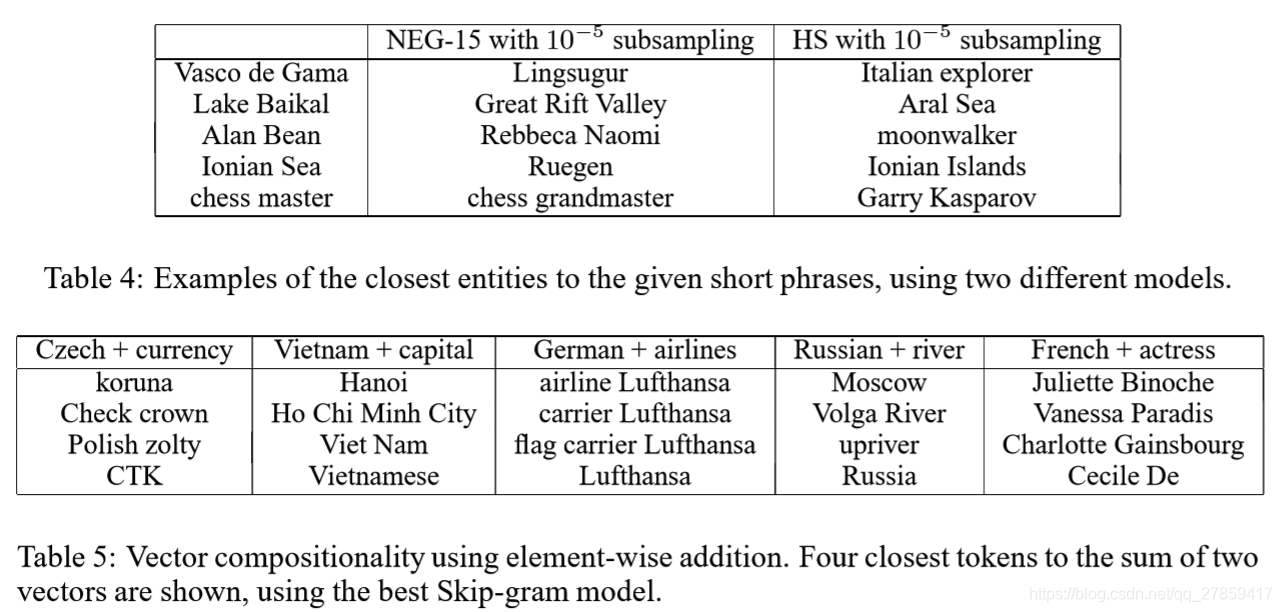
Ⅳ. Learning Phrases
- 要学习短语的向量表示,我们首先要找到经常出现在一起的词,以及在其他上下文中不经常出现的词。
- New York Times, Toronto Maple Leafs; this is
- 方法:data-driven
s c o r e ( w i , w j ) = c o u n t ( w i w j ) − δ c o u n t ( w i ) × c o u n t ( w j ) score(w_i,w_j) = \frac{count(w_iw_j)-\delta}{count(w_i) \times count(w_j)} score(wi,wj)=count(wi)×count(wj)count(wiwj)−δ
δ \delta δ: discounting coefficient → \rightarrow → 防止短语包含许多不常用词汇
选取阈值;特别地,以递增的阈值运行2-4个轮回,允许构建多个单词的短语 - 测评:以新的包含短语的推断任务进行测评
- 实验结果:
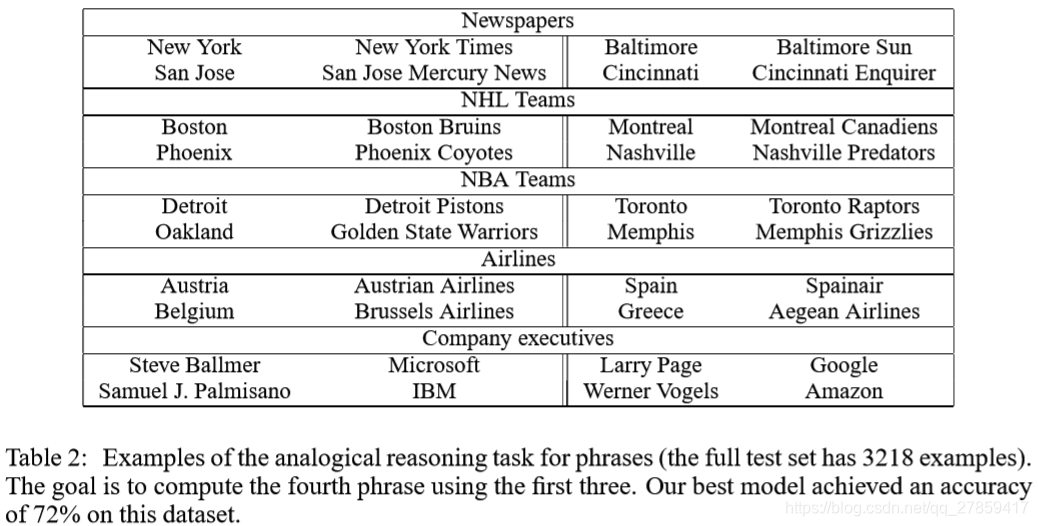
4.1 Phrase Skip-Gram Results
Ⅴ. Additive Compositionality(语义合成性)
- 线性运算:推理;直接向量相加合成新的有意义的组合
- 原因:由training objective决定的
- The word vectors are in a linear relationship with the inputs to the softmax nonlinearity
- 用中心单词预测周围的单词 → \rightarrow → 用中心单词表征周围单词的分布 → \rightarrow → 这些值与输出层计算的概率呈对数关系 → \rightarrow → 两个词向量的相加对应与两个上下文分布的乘积
- 由两个词向量分配高概率的词将具有高概率,而其他词将具有低概率
- vec(Russian) + vec(river) = vec(Volga River)
Ⅵ. Comparison to Published Word Representations
- 基于神经网络的词表征:
- Collobert and Weston
- Turian et al.
- Mnih and Hinton
- empirical comparison
- 性能好的原因:高于原来3个数量级的训练数据
- 训练时间复杂度低
Ⅶ. Conclusion
- 训练单词的分布式表示(Skip-Gram算法);表示中存在的线性结构;也可用于continuous bag-of-words.
- 模型高效的计算,可以训练高于几个数量级的数据 → \rightarrow → 提升了词向量表示的准确性,特别是对于频次较低的单词。
- subsampling of the frequent words → \rightarrow → faster training; better representations of uncommon words
- Negative sampling algorithm → \rightarrow → extremely simple training method; learns accurate representations ( frequent words)
- 训练算法与超参数的选择:task specific decision
- the model architecture
- the size of the vectors
- the subsampling rate
- the size of the training window
- 词向量可以通过简单的向量加法得到有意义的组合
- representations of phrases → \rightarrow → recursive matrix-vector operations
参考资料
[1] word2vec原理(二) 基于Hierarchical Softmax的模型, by 刘建平Pinard

















 3245
3245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









