






词和短语的分布表示及其构成
原作者:Tomas Mikolov等
#摘要
最近引入的连续Skip-gram模型是学习高质量分布向量表示的有效方法,分布向量表示可以捕获大量精确的句法和语义关系。在本文中,我们提出了几个扩展,提高了向量的质量和训练速度。通过对频繁的单词进行二次抽样,我们获得了显着的加速,同时还学习了更多的常规单词表示。我们还提出了一个分层soft max的简单替代方案,称为负采样。
单词表示的一个固有限制是:它们不关心词序,而且无法表示习惯用语。例如,不能简单地将“Canada/加拿大”和“Air/空中”的含义组合起来得到“Canada Air/加拿大航空公司”的含义。在这个例子的启发下,我们提出了一种在文本中查找短语的简单方法,并表明学习数百万个短语的好的向量表示是可能的。
#1 介绍
通过分组相似的单词,在向量空间中的分布表示可以帮助学习算法在NLP任务中获得更好的表现。最早使用单词表示可以追溯到1986年(Rumelhart,Hinton和Williams)。这个想法已经被应用于统计语言建模且取得了相当大的成功。后续工作包括应用于自动语音识别和机器翻译,以及大范围的NLP任务。
最近,Mikolov等人引入了Skip-gram模型,这是一种从大量非结构化文本数据中学习高质量向量表示的有效方法。与过去大部分用于学习word vectors的神经网络架构不同,Skip-gram模型的训练(参见图1)不涉及密集矩阵的乘法。这使得训练非常高效:一个优化过的单机实现可以在一天内训练超过1000亿字。
使用神经网
了许多语言规律和模式。有点令人惊讶的是,许多这些模式可以表示为线性翻译。例如,向量计算vec("Madrid")-vec("Spain")+vec("France")的结果比任何其他word vector更接近于vec("Paris")。
图1:Skip-gram模型架构。训练目标是学习善于预测附近单词的单词向量表示。
在本文中,我们提出了原始Skip-gram模型的几个扩展。在训练过程中,对频繁单词进行二次采样会导致显着的加速(大约2-10倍),并提高频率较低的单词表示的准确性。此外,我们提出了一种用于训练Skip-gram模型的简化NCE(噪声对比估计)。结果表明,与更复杂的分层softmax相比,它有更快的训练速度,而且频繁单词的向量表示也更好。
单词表示天生受限于惯用短语的表示。例如,“Boston Globe/波士顿环球报”是报纸,它不是“Boston/波士顿”和“Globe/地球”的含义的自然组合。因此,用向量来表示整个短语会使Skip-gram模型更具表现力。其他旨在通过组合单词向量(例如递归自动编码器)来表示句子意义的技术也将受益于使用短语向量而不是单词向量。
模型从基于单词扩展到基于短语模型相对简单。首先,我们使用数据驱动的方法识别大量的短语,然后在训练过程中将短语视为单独的标记。为了评估短语向量的质量,我们开发了一个包含单词和短语的类比推理任务测试集。测试集中一个典型类比对是"Montreal":"Montreal Canadiens" :: "Toronto":"TorontoMaple Leafs"如果最靠近vec("Montreal Canadiens") - vec("Montreal") + vec("Toronto")的表达是 vec("TorontoMaple Leafs"),则被认为回答正确。
最后,我们描述了Skip-gram模型的另一个有趣属性。我们发现简单的向量加法通常可以产生有意义的结果。例如,vec("俄罗斯")+vec("河流")接近 vec("伏尔加河"),而vec("德国")+vec("首都")接近 vec("柏林")。这种组合性表明,通过对单词向量表示使用基本的数学运算,可以获得非明显程度的语言理解。
#2 Skip-gram模型
Skip-gram模型的训练目标是找到可用于预测句子或文档中周围的单词的单词表示。更正式地,给出训练词w1 ,w2,w3,...,wT,Skip-gram模型的目标是使平均对数概率最大化:
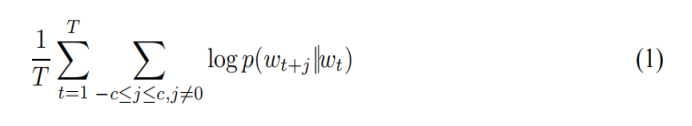
其中c是训练上下文(可以是中心单词ωT的一个函数)的大小。较大的c意味着更多的训练例,因此可以导致更高的准确性,同时也意味着更多的训练时间。基本Skip-gram公式使用softmax函数:
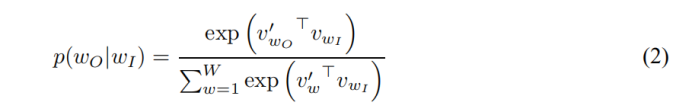
来定义。其中Vω和V’ω分别为ω的输入和输出向量表示,W为词汇表中的单词数。这个公式是不切实际的,因为计算
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 920
920











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









