






Adaptive Result Inference for Collecting Quantitative Data with Crowdsourcing
作者
Hailong Sun, Member, IEEE, Kefan Hu, Yili Fang, Yangqiu Song
摘要
在定量众包中,要求工人提供数字答案。与分类众包不同,定量众包中的结果聚合是通过对所有工人答案进行组合计算而不是仅仅从一组候选答案中选择一个来处理的。因此,现有的分类众包任务的结果聚合模型不能用于定量众包。此外,在众包过程中,工人的能力往往随着工人技能、意愿、努力等的变化而变化,在这项工作中,我们提出了一个概率模型,通过考虑工人能力的变化来描述定量众包问题,从而实现更好的质量控制。通过卡尔曼滤波器(Kalman Filtering)和平滑器(Smoother),获得了动态工作能力。我们设计了一个基于期望最大化(EM)的推理算法和一个动态工人过滤算法来计算聚合众包结果。最后,我们对CrowdFlower的实际数据进行了实验,结果表明,我们的方法可以有效地动态排除低质量工人,以较低的成本获得更准确的结果。
假设我们要研究的对象是一个房间的温度。根据你的经验判断,这个房间的温度是恒定的,也就是下一分钟的温度等于现在这一分钟的温度(假设我们用一分钟来做时间单位)。假设你对你的经验不是100%的相信,可能会有上下偏差几度。我们把这些偏差看成是高斯白噪声(White Gaussian Noise),也就是这些偏差跟前后时间是没有关系的而且符合高斯分布(Gaussian Distribution)。另外,我们在房间里放一个温度计,但是这个温度计也不准确的,测量值会比实际值偏差。我们也把这些偏差看成是高斯白噪声。
好了,现在对于某一分钟我们有两个有关于该房间的温度值:你根据经验的预测值(系统的预测值)和温度计的值(观测值)。下面我们要用这两个值结合他们各自的噪声来估算出房间的实际温度值。
假如我们要估算k时刻的是实际温度值。首先你要根据k-1时刻的温度值,来预测k时刻的温度。因为你相信温度是恒定的,所以你会得到k时刻的温度预测值是跟k-1时刻一样的,假设是23度,同时该值的高斯噪声的偏差是5度(5是这样得到的:如果k-1时刻估算出的最优温度值的偏差是3,你对自己预测的不确定度是4度,他们平方相加再开方,就是5)。然后,你从温度计那里得到了k时刻的温度值,假设是25度,同时该值的偏差是4度。
由于我们用于估算k时刻的实际温度有两个温度值, 分别是23度和25度。究竟实际温度是多少呢?相信自己还是相信温度计呢?究竟相信谁多一点,我们可以用他们的协方差来判断。因为 K g 2 = 5 2 / ( 5 2 + 4 2 ) Kg^2=5^2/(5^2+4^2) Kg2=52/(52+42),所以Kg=0.78,我们可以估算出k时刻的实际温度值是:23+0.78*(25-23)=24.56度。可以看出,因为温度计的协方差比较小(比较相信温度计),所以估算出的最优温度值偏向温度计的值。
现在我们已经得到k时刻的最优温度值了,下一步就是要进入k+1时刻,进行新的最优估算。到现在为止,好像还没看到什么自回归的东西出现。对了,在进入k+1时刻之前,我们还要算出k时刻那个最优值(24.56度)的偏差。算法如下: ( ( 1 − K g ) ∗ 5 2 ) 0.5 = 2.35 ((1-Kg)*5^2)^{0.5}=2.35 ((1−Kg)∗52)0.5=2.35。这里的5就是上面的k时刻你预测的那个23度温度值的偏差,得出的2.35就是进入k+1时刻以后k时刻估算出的最优温度值的偏差(对应于上面的3)。
就是这样,卡尔曼滤波器就不断的把协方差递归,从而估算出最优的温度值。他运行的很快,而且它只保留了上一时刻的协方差。上面的Kg,就是卡尔曼增益(Kalman Gain)。他可以随不同的时刻而改变他自己的值,是不是很神奇!
介绍
众包已经成功地被用来收集大量应用程序的数据。因此,开发了许多众包系统[1]来处理各种任务。例如,在图像标记、音频识别、视频注释和情感分析等任务中,众包已成为生成数据分析中机器学习算法训练集的重要方法;在数据感知任务中,众包(在这种情况下通常称为众包感知)用于收集数据。来自不同来源的数据。从本质上讲,众包的有效性取决于一定成本下任务结果的质量,即所谓的质量控制问题。此外,给定一个任务和一组由工人提供的候选答案,任务结果的质量完全取决于结果推理,这是一个通过将候选答案聚合而生成任务结果的过程。由于众包受到工人能力、任务难度、激励和其他因素的显著影响,因此单个候选人的回答质量通常不可靠。因此,从一组不可靠的答案中获得高质量的结果是一个非常重要的问题。因此,结果推理是众包面临的突出挑战之一。
在实践中,结果推理与众包任务的特点密切相关。不同的任务通常要求对结果推理进行特殊的设计。大多数现有的众包工作都集中在分类任务或分类众包任务上,要求工人提供标签,并从所有提交的答案中选择最终结果。例如,在典型的情绪分析任务[3]中,要求工人从 { “ p o s i t i v e ’ ’ , “ n e u t r a l ” , “ n e g a t i v e ” } \{“positive’’, “neutral”,“negative”\} {“positive’’,“neutral”,“negative”}中选择一个标签,最终结果在同一回答集中确定。分类任务结果推理的挑战集中在如何衡量每个候选答案的权重上。同时,定量众包任务,例如计算图片[4]、[5]和对等分级[6]中显示的对象,要求工人给出相对于离散标签的定量估计,并通过合并所有报告的数值计算最终结果。例如,如果任务是识别图片中包含的人数,工人可能提供 { 12 , 13 , 100 , 2 , 19 } \{12,13,100,2,19\} {12,13,100,2,19}的答案集。最后的结果可能是没有在任何候选答案。因此,定量众包任务需要不同的方法来有效地推断任务结果。此外,由于工人的能力直接影响到工人回答的质量,实质上影响了众包结果的质量,因此将工人的能力适当地纳入结果推理中具有重要意义。在众包中,工人在任务处理中的表现可以动态变化,这在[7]中通过UCI数据集得到确认。一方面,从长远来看,工人的能力通常应该得到提高,因为工人在处理越来越多的任务后,能够更好地理解任务并学习所需的专业知识。另一方面,如果一名工人在一段时间内一直在处理众包任务,那么由于疲劳或其他原因而分心,他的能力可能会相应下降。近年来,考虑到结果推理中工人能力的动态变化,引起了众包研究界的广泛关注[7]、[8]、[9]、[10]。
本文旨在研究定量众包任务的结果推理问题。关于在分类众包任务中发现真相,已经有许多著作[11]、[12]、[13]。工人通常被建模为分类器,其准确性受工人能力、偏差、任务难度等因素的影响,然后通过设计相应的算法来推断任务的最终输出,以评估工人提供的哪一个候选答案最可能是正确的。然而,要推断定量众包任务的结果,需要有效地聚合工人答案,而不是从候选答案中选择一个答案。因此,现有的分类众包方法不能应用于定量众包。此外,定量众包任务对工人能力更为敏感,因为答案集的范围在很大程度上取决于工人能力。因此,在处理定量众包任务时,考虑工人能力的变化具有重要意义。研究定量众包任务的努力并不多。[14]、[15]是这方面最新的作品。然而,他们都没有考虑工人能力的动态变化。综上所述,定量众包的结果推理面临两大挑战。首先,如何对应答生成和结果聚合过程进行建模。第二,如何将不断变化的工人能力融入到结果推理中。
我们提出了一个描述定量众包任务处理的生成模型,其中考虑了潜在的真值、工人的偏差、工人的能力和工人的评估。特别是,我们试图将工人动态的能力融入到我们的模型中。直观地说,工人的能力是一个随时间变化的变量。在这项工作中,基于任务完成时间,将工人能力建模为一个线性动态系统,并应用卡尔曼滤波器和平滑器跟踪工人能力的动态变化。然后,我们设计了一个基于EM算法来推断任务结果,并设计了一个算法来过滤低能力的工人。我们在CrowdFlower上进行了一组实验,让工人数一数一组图片中显示的物体。实验结果与人工获得的地面真实值进行了比较,验证了该方法的有效性。此外,我们还进行了广泛的模拟,以研究影响自适应结果推理方法有效性的因素。我们的贡献总结如下:
- 我们设计了一个在定量众包过程中考虑工人动态能力的模型。据我们所知,这是第一次将工人动态的可靠性考虑在内,以便在定量众包中更好地汇总答案。
- 我们研究了工人的精度漂移,并利用卡尔曼算法对其进行跟踪,然后将卡尔曼算法集成到我们的无监督概率模型中,可以跟踪工人的精度漂移,得到更准确的结果。
- 提出了一种在任务参与中动态选择合格工人的方法,从而降低了众包系统的成本,提高了汇总结果的准确性。
- 我们在CrowdFlower中对现实任务和模拟进行了两个实验。实验结果表明,考虑到工人能力的动态变化,有助于提高定量众包的结果质量。
本文的其余部分结构如下。我们在第2节中描述了这个问题和我们的框架。第3节介绍了我们的自适应结果推理模型。我们在第4节中介绍了工人过滤算法。第5节给出了实验结果,第6节讨论了分类众包中的建议方法。我们在第7节中描述了相关工作,并在第8节中结束本文。
2 问题描述
我们首先简要地描述了有关的问题。有 N N N个定量众包任务供 M M M个工人处理。对于任务 i i i,我们使用 μ i \mu_i μi表示潜在的真值和 r i , j r_{i,j} ri,j表示工人 j j j的判断报告, r i , j r_{i,j} ri,j是一个数值。最后,我们将 Q j Q_j Qj表示为工人 j j j回答的问题集,而 U i U_i Ui表示为回答问题 i i i的工人集。对于每个任务,我们的目标是根据所有报告的答案,获得尽可能接近基本事实的汇总结果。
此外,图1给出了本研究提出的适应性定量众包处理框架。定量任务(如计数对象)发布到公共众包平台,由众包工人进行处理,从而收集工人的回答。周期性地,我们用EM算法交替进行结果推理,并估计每个工人的能力。其次,根据对工人能力的估计,采用一种算法对低质量工人进行筛选,以提高结果质量。
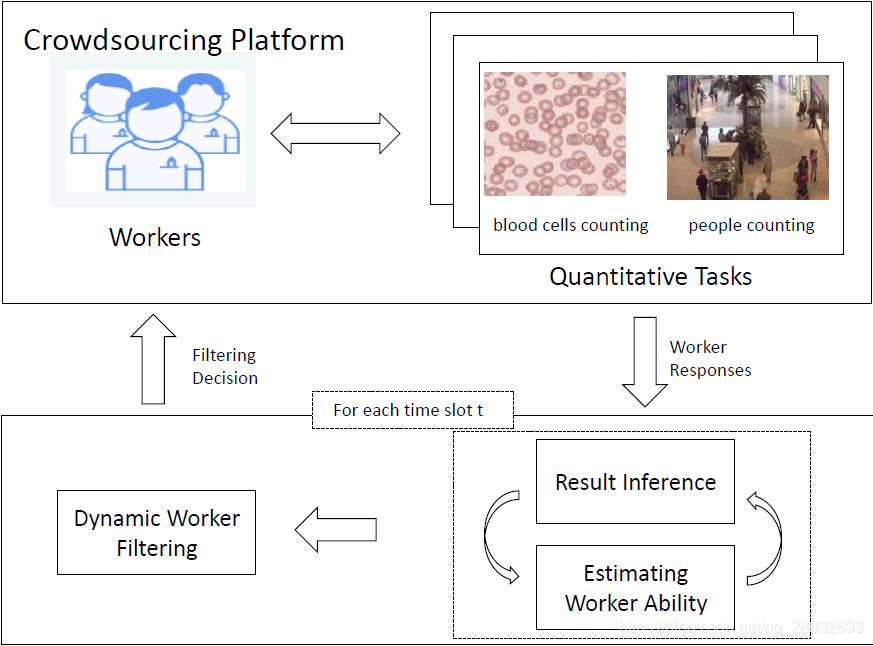
图.1:适应性定量众包框架
3 动态聚合模型
3.1 模型设计
实际上, r i , j r_{i,j} ri,j会受到许多因素的影响。这里我们主要考虑三个因素,包括工人偏差、工人能力和潜在的真值 ( μ i ) (\mu_i) (μi)。
工人的偏差(Worker Bias)。 偏差 b j b_j bj反映了一个工人在定量任务中倾向于低估或高估,这实际上是一个工人的回答和相应的基本事实之间的平均距离。
工人的能力(Worker Ability.)。 工人的能力是决定工人提供的答案是否精确的一个因素。因此,我们使用工人精度 φ j \varphi_j φj来表示工人的能力,这反映了工人对相应真值答案的接近程度的平均值。 φ j \varphi_j φj是一个工人答案的方差的倒数。工人的精确性取决于t他的技能流利性、专业知识、意愿等,因此可能不是固定值。在图2中,我们展示了第5节中描述的从CrowdFlower数据集中随机抽取的两名工人的偏差值 ( r i , j − μ i − b j ) (r_{i,j}-\mu_i-b_j) (ri,j−μi−bj)的图。我们可以观察到,即使消除了偏差,工人的回答与事实的偏差仍然在不断变化,这也证实了我们的论点。由于空间的限制,我们没有描绘出参与实验的286名工人的能力变化。请注意,这里的两个工人不是精心挑选的。事实上,所有的工人都表现出了他们能力的变化,但是所有工人的变化模式变化很大。在第5节中,我们进一步展示了完成最多任务的前五名工人的能力跟踪结果。因此,与现有的研究不同,我们将工作精度建模为随时间动态变化的随机变量。
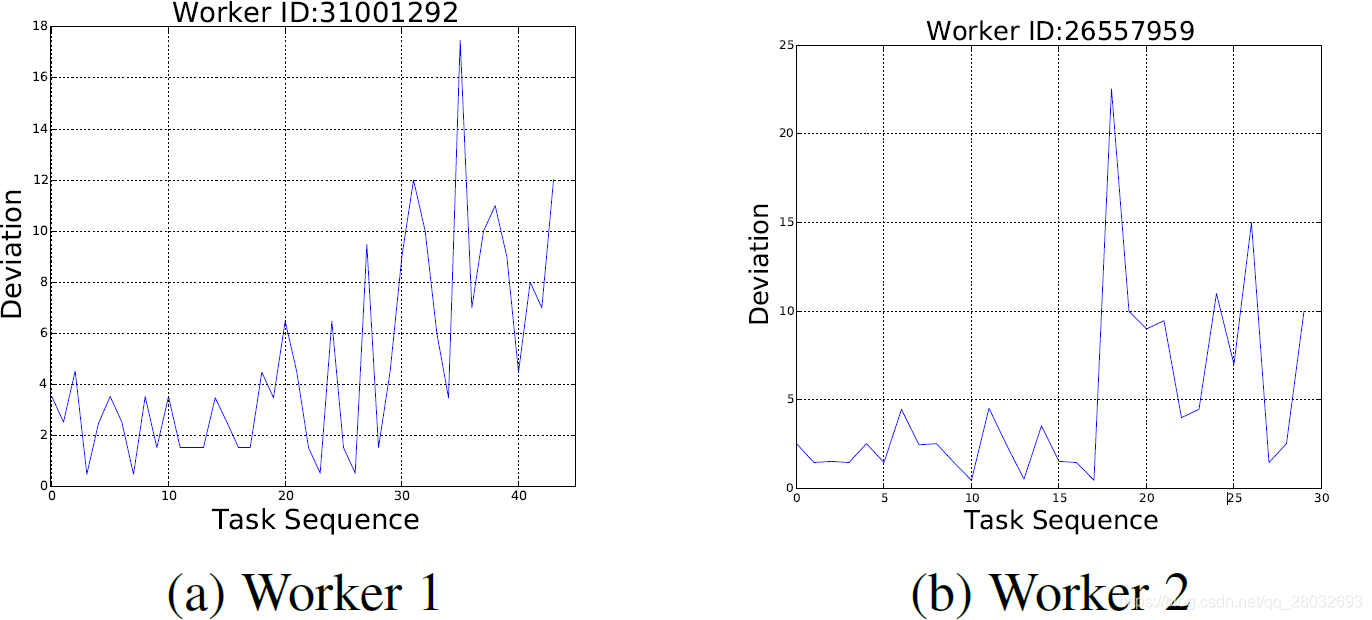
图.2:工人的精度随时间而变化
通过以上分析,我们提出了RID模型(Result Inference with Dynamic worker ability,包含工人动态能力的结果推理),如图3所示。阴影节点代表工人回答的观察变量,其他空白节点分别代表潜在的真值
μ
i
\mu_i
μi、工作偏差
b
j
b_j
bj和在时刻
t
t
t时的精度
φ
j
,
t
\varphi_{j,t}
φj,t,其中
φ
j
,
t
\varphi_{j,t}
φj,t被建模为从先前状态
φ
j
,
t
−
1
\varphi_{j,t-1}
φj,t−1过渡的LDS潜在状态。这些图版描述了图形模型中两个主要组件的复制。
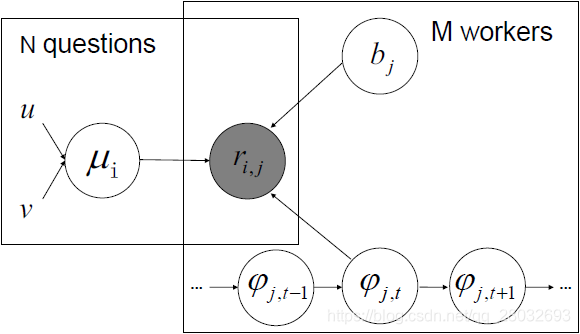
图.3:dOC模型的图形模型
潜在的真值(Latent truth)。
μ
i
\mu_i
μi用高斯模型建模:
(1)
μ
i
∼
N
(
u
,
v
)
\mu_i\sim\mathcal{N}(u,v)\tag{1}
μi∼N(u,v)(1)
其中 u u u和 v v v是分别表示平均值和方差的两个超参数。
然后,工人在某个时间
t
t
t的答案的产生示例如下:
(2)
r
i
,
j
∣
μ
i
,
b
j
,
φ
j
,
t
∼
N
(
r
i
,
j
∣
μ
i
+
b
j
,
1
/
φ
j
,
t
)
r_{i,j}|\mu_i,b_j,\varphi_{j,t}\sim\mathcal{N}(r_{i,j}|\mu_i+b_j,1/\varphi_{j,t})\tag{2}
ri,j∣μi,bj,φj,t∼N(ri,j∣μi+bj,1/φj,t)(2)
其中, φ j , t \varphi_{j,t} φj,t是依赖于前一状态的潜在状态 φ j , t − 1 \varphi_{j,t-1} φj,t−1。因此,通过在提供答案时考虑工人的精度,可以推断出每个任务的聚合结果。通过这种方式,我们希望能够提高聚集众包结果的质量。我们将在下面的小节中解释 φ j , t \varphi_{j,t} φj,t是如何建模和计算的。
3.2 工人精度的动态计算
由于工人的精度受到多种因素的影响,因此很难识别所有因素,并分别对其影响进行精确建模。相反,我们关注的是所有因素的总体影响。在这方面,[9]采用了LDS(Linear Dynamic Systems,线性动态系统)[16]来解决市民科学应用中的分类众包问题。同样地,在这项工作中,我们使用LDS来描述定量众包问题中工人精度的动态变化。我们使用
φ
j
,
t
\varphi_{j,t}
φj,t表示与在时隙
t
t
t时工人
j
j
j的精度相对应的LDS的潜在状态。状态转换定义如下:
(3)
φ
j
,
t
=
φ
j
,
t
−
1
+
w
\varphi_{j,t}=\varphi_{j,t-1}+w\tag{3}
φj,t=φj,t−1+w(3)
其中
w
w
w是服从高斯分布的变量:
(4)
w
∼
N
(
0
,
λ
2
)
w\sim\mathcal{N}(0,\lambda^2)\tag{4}
w∼N(0,λ2)(4)
它表明,工作精度可能会从以前的状态随机略有变化,并从高斯分布中取样,其中 λ \lambda λ控制精度漂移的变化。
我们需要用工人的答案和它们的方差来计算观察到的工人的精度。由于
r
i
,
j
r_{i,j}
ri,j是从高斯分布
N
(
μ
i
+
b
j
,
1
/
φ
j
,
t
)
\mathcal{N}(\mu_i+b_j,1/\varphi_{j,t})
N(μi+bj,1/φj,t)中提取的,因此我们可以通过采用绝对值
∣
r
i
,
j
−
μ
i
−
b
j
∣
|r_{i,j}-\mu_i-b_j|
∣ri,j−μi−bj∣的期望值,得出工作精度
φ
j
,
t
\varphi_{j,t}
φj,t的估计值:
(5)
E
(
∣
r
i
,
j
−
μ
i
−
b
j
∣
)
=
2
π
φ
j
\mathbb{E}(|r_{i,j}-\mu_i-b_j|)=\frac{\sqrt{2}}{\sqrt{\pi}\varphi_j}\tag{5}
E(∣ri,j−μi−bj∣)=πφj2(5)
因此
φ
j
,
t
\varphi_{j,t}
φj,t可通过以下方式估算:
(6)
φ
j
,
t
2
=
2
π
(
r
i
,
j
,
t
−
μ
i
−
b
j
)
2
\varphi_{j,t}^2 = \frac{2}{\pi(r_{i,j,t}-\mu_i-b_j)^2}\tag{6}
φj,t2=π(ri,j,t−μi−bj)22(6)
在时间
t
t
t,我们假设每个问题的真值
μ
i
\mu_i
μi已经聚合,下一小节将介绍推理过程。利用
μ
i
\mu_i
μi,精度
φ
j
,
t
\varphi_{j,t}
φj,t的发射函数可定义为:
(7)
o
i
,
j
=
φ
j
,
t
+
v
=
2
π
∣
r
i
,
j
−
μ
i
−
b
j
∣
+
v
o_{i,j}=\varphi_{j,t}+v=\frac{\sqrt{2}}{\sqrt{\pi}|r_{i,j}-\mu_i-b_j|}+v\tag{7}
oi,j=φj,t+v=π∣ri,j−μi−bj∣2+v(7)
其中 o i , j o_{i,j} oi,j表示潜在状态 φ j , t \varphi_{j,t} φj,t的观测值以及 v v v表示遵循 N ( 0 , γ 2 ) \mathcal{N}(0,\gamma^2) N(0,γ2)分布的高斯白噪声。
然后,我们可以使用卡尔曼滤波器[17]给出推理方案,卡尔曼滤波器是LDS中的一种估计模型。假设在
t
−
1
t-1
t−1时,工人的精度用
φ
t
−
1
∣
t
−
1
\varphi_{t-1|t-1}
φt−1∣t−1表示,即它是根据观测值
o
t
−
1
o_{t-1}
ot−1的最大后验值。使用
φ
t
−
1
∣
t
−
1
\varphi_{t-1|t-1}
φt−1∣t−1,我们可以预测下一个时隙
t
t
t的精度,如下所示:
(8)
φ
t
∣
t
−
1
∼
N
(
φ
t
−
1
∣
t
−
1
,
P
t
∣
t
−
1
)
\varphi_{t|t-1}\sim\mathcal{N}(\varphi_{t-1|t-1},P_{t|t-1})\tag{8}
φt∣t−1∼N(φt−1∣t−1,Pt∣t−1)(8)
其中,
P
t
∣
t
−
1
P_{t|t-1}
Pt∣t−1是与预测
φ
t
∣
t
−
1
\varphi_{t|t-1}
φt∣t−1相对应的方差。
P
t
∣
t
−
1
P_{t|t-1}
Pt∣t−1可以通过
φ
t
−
1
∣
t
−
1
\varphi_{t-1|t-1}
φt−1∣t−1的方差和
P
t
−
1
∣
t
−
1
P_{t-1|t-1}
Pt−1∣t−1更新:
(9)
P
t
∣
t
−
1
=
P
t
−
1
∣
t
−
1
+
λ
P_{t|t-1}=P_{t-1|t-1}+\lambda\tag{9}
Pt∣t−1=Pt−1∣t−1+λ(9)
在时间
t
t
t,我们使用
o
i
,
j
o_{i,j}
oi,j作为卡尔曼滤波器的观测值。对于在时间
t
t
t给出响应的每个工人,我们通过以下方式更新其精度:
(10)
φ
t
∣
t
=
φ
t
∣
t
−
1
+
K
t
(
o
i
,
j
−
φ
t
∣
t
−
1
)
\varphi_{t|t}=\varphi_{t|t-1}+\mathbf{K}_t(o_{i,j}-\varphi_{t|t-1})\tag{10}
φt∣t=φt∣t−1+Kt(oi,j−φt∣t−1)(10)
其中,
K
t
\mathbf{K}_t
Kt是卡尔曼增益,定义如下:
(11)
K
t
=
P
t
∣
t
−
1
(
P
t
∣
t
−
1
+
γ
)
−
1
\mathbf{K}_t=P_{t|t-1}(P_{t|t-1}+\gamma)^{-1}\tag{11}
Kt=Pt∣t−1(Pt∣t−1+γ)−1(11)
φ
t
∣
t
\varphi_{t|t}
φt∣t的方差的更新为:
(12)
P
t
∣
t
=
(
1
−
K
t
)
P
t
∣
t
−
1
P_{t|t}=(1-\mathbf{K}_t)P_{t|t-1}\tag{12}
Pt∣t=(1−Kt)Pt∣t−1(12)
对于每个工人,上述过程基于式(8)-(12)从 t = 1 t=1 t=1迭代到 T T T,其中 T T T是工人提供答案的最后一个时隙。
卡尔曼滤波器使用前向递归,其中
φ
j
,
t
∣
t
\varphi_{j,t|t}
φj,t∣t仅根据以前和现在的观测值计算。因此,我们对所有观测结果使用卡尔曼平滑器[18]以获得最佳后验状态
φ
j
,
t
∣
N
\varphi_{j,t|N}
φj,t∣N,其中
N
N
N表示所有观测结果。在时刻
t
t
t时,我们根据从
t
+
1
t+1
t+1到
T
T
T的观测结果,反向递归地更新
φ
j
,
t
∣
N
\varphi_{j,t|N}
φj,t∣N。在
t
t
t处,我们通过(10)有
φ
t
∣
t
\varphi_{t|t}
φt∣t,通过(12)有
P
t
∣
t
P_{t|t}
Pt∣t。已知
φ
^
t
+
1
∣
N
\hat{\varphi}_{t+1|N}
φ^t+1∣N,
φ
^
t
∣
N
\hat{\varphi}_{t|N}
φ^t∣N的最佳后验估计推导如下:
(13)
φ
^
t
∣
N
=
φ
t
∣
t
+
J
t
(
φ
^
t
+
1
∣
N
−
φ
t
∣
t
)
\hat{\varphi}_{t|N}=\varphi_{t|t}+J_t(\hat{\varphi}_{t+1|N}-\varphi_{t|t})\tag{13}
φ^t∣N=φt∣t+Jt(φ^t+1∣N−φt∣t)(13)
我们将后验方差
P
^
t
∣
N
\hat{P}_{t|N}
P^t∣N通过反向步长
t
+
1
t+1
t+1时间的
P
t
+
1
∣
N
P_{t+1|N}
Pt+1∣N更新为:
(14)
P
^
t
∣
N
=
P
t
−
J
t
2
(
P
t
+
1
∣
N
−
P
t
+
1
∣
t
)
\hat{P}_{t|N}=P_t-J_t^2(P_{t+1|N}-P_{t+1|t})\tag{14}
P^t∣N=Pt−Jt2(Pt+1∣N−Pt+1∣t)(14)
其中
J
t
J_t
Jt被定义为:
(15)
J
t
=
P
t
∣
t
P
t
+
1
∣
t
−
1
J_t=P_{t|t}P_{t+1|t}^{-1}\tag{15}
Jt=Pt∣tPt+1∣t−1(15)
我们将式(13)-(15)从 T T T反向运行到 1 1 1,然后可以得到 t t t时工人精度的最优后验估计。
3.3 模型推理
现在我们描述如何使用我们的RID模型进行推理,推理的目的是为每个众包任务找到真正的
μ
\mu
μ。如前一小节所述,我们将
μ
i
\mu_i
μi视为潜在变量,并将
Θ
=
{
φ
j
,
b
j
}
\Theta=\{\varphi_j,b_j \}
Θ={φj,bj}定义为模型的参数集。因此,观察到的工人回答集
D
=
{
r
i
,
j
}
\mathbf{D}=\{r_{i,j}\}
D={ri,j}的似然值表示为:
(16)
p
(
D
∣
Θ
,
μ
)
=
∏
i
=
1
N
p
(
μ
i
)
∏
j
=
1
U
i
p
(
r
i
.
j
∣
φ
j
,
t
i
m
e
(
j
,
i
)
,
μ
i
,
b
j
)
p(\mathbf{D}|\Theta,\mu)=\prod_{i=1}^{N}p(\mu_i)\prod_{j=1}^{U_i}p(r_{i.j}|\varphi_{j,time(j,i)},\mu_i,b_j)\tag{16}
p(D∣Θ,μ)=i=1∏Np(μi)j=1∏Uip(ri.j∣φj,time(j,i),μi,bj)(16)
其中, t i m e ( j , i ) time(j,i) time(j,i)是当工人 j提供对任务i的回答时的时隙的映射函数。
为了推断方程式(16)中的未知参数,自然要考虑使用最大似然估计算法。然而,由于 μ i \mu_i μi和 φ j , t i m e ( j , i ) \varphi_{j,time(j,i)} φj,time(j,i)都是不可观测的,因此不可能进行精确的推断。在这种情况下,期望最大化(Expectation-Maximization,EM)算法[19]通常用于迭代学习模型中的每个变量。EM算法由E步骤(Expectation,期望)和M步骤(Maximization,最大化)组成,其中E步骤负责估计方程式(16)确定的对数似然函数,M步骤使用最大似然估计算法求解未知参数。算法迭代这两个步骤,直到过程收敛。
E步骤。 对于每个任务,第
(
n
−
1
)
t
h
(n-1)^{th}
(n−1)th迭代中给定
Θ
n
−
1
\Theta^{n-1}
Θn−1,我们计算其潜在真值
μ
i
\mu_i
μi的后验概率如下所示:
(17)
p
(
μ
i
∣
Θ
n
−
1
,
D
U
i
)
∝
p
(
μ
i
)
p
(
D
U
i
∣
Θ
n
−
1
,
μ
i
)
=
N
(
μ
i
∣
u
,
v
)
∏
j
=
1
U
i
N
(
r
i
,
j
∣
μ
i
+
b
j
,
1
/
φ
j
,
t
i
m
e
(
j
,
i
)
)
\begin{aligned} p(\mu_i|\Theta^{n-1},\mathbf{D}_{U_i}) &\propto p(\mu_i)p(\mathbf{D}_{U_i}|\Theta^{n-1},\mu_i)\\ &=\mathcal{N}(\mu_i|u,v)\prod_{j=1}^{U_i}\mathcal{N}(r_{i,j}|\mu_i+b_j,1/\varphi_{j,time(j,i)})\tag{17} \end{aligned}
p(μi∣Θn−1,DUi)∝p(μi)p(DUi∣Θn−1,μi)=N(μi∣u,v)j=1∏UiN(ri,j∣μi+bj,1/φj,time(j,i))(17)
其中
D
U
i
\mathbf{D}_{U_i}
DUi是任务
i
i
i的回答集。本次迭代
μ
i
\mu_i
μi的后验分布计算如下:
(18)
μ
i
(
n
)
=
μ
N
=
u
j
v
j
+
∑
j
=
1
U
i
φ
j
,
t
i
m
e
(
j
,
i
)
(
r
i
,
j
−
b
j
)
v
j
+
∑
j
=
1
U
i
φ
j
,
t
i
m
e
(
j
,
i
)
\mu_i^{(n)}=\mu_N=\frac{u_jv_j+\sum_{j=1}^{U_i}\varphi_{j,time(j,i)}(r_{i,j}-b_j)}{v_j+\sum_{j=1}^{U_i}\varphi_{j,time(j,i)}}\tag{18}
μi(n)=μN=vj+∑j=1Uiφj,time(j,i)ujvj+∑j=1Uiφj,time(j,i)(ri,j−bj)(18)
M步骤。 我们重新估计了模型参数,给出了在E步骤中计算出的潜在真值的期望值
μ
i
(
n
)
\mu_i^{(n)}
μi(n),并将后验概率最大化,如下所示:
(19)
Θ
n
=
arg
max
Θ
f
(
Θ
,
Θ
(
n
−
1
)
)
=
Q
(
Θ
,
Θ
(
n
−
1
)
)
+
c
o
n
s
t
\Theta^{n}=\underset{\Theta}{\arg\max}f(\Theta,\Theta^{(n-1)}) =Q(\Theta,\Theta^{(n-1)})+const\tag{19}
Θn=Θargmaxf(Θ,Θ(n−1))=Q(Θ,Θ(n−1))+const(19)
其中 Q ( Θ , Θ ( n − 1 ) ) = E [ ln ( p ( D , μ ∣ Θ ) ) ] Q(\Theta,\Theta^{(n-1)})=\mathbb{E}[\ln(p(\mathbf{D},\mu|\Theta))] Q(Θ,Θ(n−1))=E[ln(p(D,μ∣Θ))]。
对于每个工人,我们使用梯度上升法(Radient Ascent)得到
b
j
∈
Θ
n
b_j\in\Theta^n
bj∈Θn的最优解:
(20)
b
j
∗
=
∑
i
=
1
Q
j
r
i
,
j
−
μ
i
∣
Q
j
∣
b_j^*=\frac{\sum_{i=1}^{Q_j}r_{i,j}-\mu_i}{|Q_j|}\tag{20}
bj∗=∣Qj∣∑i=1Qjri,j−μi(20)
然后我们用卡尔曼滤波器和平滑器更新每个时隙的每个工人的精度(7),(10),(3)。首先,我们使用E步骤中的 μ i ( n ) \mu_i^{(n)} μi(n)和 b j ∗ b_j^* bj∗根据(7)推导出按时间顺序排序的观测向量。然后,利用所获得的向量来估计LDS中的潜在状态,即每个时隙中的工作精度 φ j , t \varphi_{j,t} φj,t。接下来,我们应用卡尔曼滤波器,用(10)前向递归地从 t = 1 t=1 t=1到 T T T导出初步估计的 φ t ∣ t \varphi_{t|t} φt∣t。为了得到最优估计,用(13)我们使用卡尔曼平滑器反向递归地推导出最终估计的 φ ^ t ∣ N \hat{\varphi}_{t|N} φ^t∣N。
我们迭代E步骤和M步骤,直到每个参数收敛,然后我们得到 μ i \mu_i μi, b j ∗ b_j^* bj∗和 φ j , t \varphi_{j,t} φj,t的估计值。
4 动态筛选工人
在众包中,请求者需要向工人提供一定数量的奖励。而且,为一项任务雇佣的工人越多,所产生的成本就越高。同时,更多的工人可以帮助提高众包结果的质量,因为随着更多工人的参与,高能力工人的可能性会增加。因此,人们普遍认为,成本与结果质量之间存在着权衡。然而,当许多低能力的工人被雇用时,增加的成本对结果质量根本没有好处。在我们的RID模型中,我们可以使用卡尔曼滤波器和平滑器来动态计算工人的精度,这为筛选低能力工人带来了机会。因此,可以以较低的成本获得高质量的聚合结果。
由于工人的精度经常发生变化,我们定期跟踪工人在最新
L
L
L个任务中的表现,并解雇不合格的工人。我们定义以下指标来评估工人最近的表现:
(21)
L
−
P
r
e
c
i
s
i
o
n
(
j
)
=
log
∏
i
=
1
L
f
(
r
i
,
j
∣
μ
i
+
b
j
,
φ
j
,
t
i
m
e
(
j
,
i
)
)
L-Precision(j)=\log\prod_{i=1}^{L}f(r_{i,j}|\mu_i+b_j,\varphi_{j,time(j,i)})\tag{21}
L−Precision(j)=logi=1∏Lf(ri,j∣μi+bj,φj,time(j,i))(21)
其中
f
(
x
∣
a
,
b
)
f(x|a,b)
f(x∣a,b)是高斯分布概率密度函数定义如下:
(22)
f
(
x
∣
a
,
b
)
=
1
b
2
π
e
−
(
x
−
a
)
2
2
b
2
f(x|a,b)=\frac{1}{b\sqrt{2\pi}}e^{-\frac{(x-a)^2}{2b^2}}\tag{22}
f(x∣a,b)=b2π1e−2b2(x−a)2(22)
此函数用于测量工人 j j j在最近的 L L L个任务中的表现。质量数值越高,工人的贡献就越大。我们应用 L − P r e c i s i o n L-Precision L−Precision来开发我们的工人过滤方算, R I D − F i l t e r RID-Filter RID−Filter,如算法1所示。我们为每L个任务保留了一个要检查的工人库。用(21)计算每个工人的 L − P r e c i s i o n L-Precision L−Precision,过滤出 L − P r e c i s i o n L-Precision L−Precision低于预定阈值的工人。
算法1 RID-Filter

5 实验评估
5.1数据集和众包任务
我们使用了两个公共数据集[20],其中包含了分别安装在购物中心和道路上的摄像机拍摄的400张照片。这些图片实际上是从录制的视频中提取的帧。我们对所有图片进行了充分的洗牌,以消除它们之间明显的时间相关性。我们将这些图片批量发布到了众包平台CrowdFlower上。在线工人被要求报告他们对图片中的人数的估计,并将获得每项完成任务的金钱奖励。我们总共招募了286名工人。平台按顺序将图片分发给工人,每个图片由至少8名工人冗余处理。最后收到6400份报告,如表1所示。
| Datasets | mall dataset | road dataset |
|---|---|---|
| Total task number 任务总数 | 400 | 400 |
| Avg. num of people per image 每个照片中的平均人数 | 31 | 28 |
| Task redundancy 任务冗余 | 8 | 8 |
| Minimum tasks per worker 每个工人的最少任务数 | 15 | 15 |
| Total participating workers 参与工人总数 | 130 | 156 |
| Total answers 总回答数 | 3200 | 3200 |
5.2 比较方法
我们比较了RID模型与其他五种方法在定量聚合估计中的性能。由于计数对象的结果是整数值,我们的模型只能近似地描述回答生成过程,这足以说明RID的有效性。注意,我们没有与分类任务中使用的方法进行比较,因为结果聚合机制完全不同,将分类任务的方法(如多数投票)应用于我们的任务是毫无意义的。
- 平均值。 将平均值作为最终的聚合结果,这会受到异常值(outliers)的影响。
- 中位数。 收集到的定量答案的中位数被认为是输出,它应该对异常值具有健壮性。
- LOF(Local Outlier Factor,局部异常因子)[21]。 这是一种基于离群值检测的融合算法。它首先使用LOF得分识别和排除不可靠的报告,然后通过简单地对剩余报告值求平均值来计算结果。LOF得分用于确定报告值是否为离群值,该离群值通过比较对象与其相邻对象的局部密度计算得出,最近邻参数 k k k设置为3。
- 最大可信度。[23] 这是协方差交叉(Covariance Intersection,CI)[22]的一个扩展,它将每个工人的可信度作为参数,形成一个高斯似然模型,可以共同输出融合的定量真值和工人的可信度。然而,它不包含工人偏差和精度的动态变化。
- RIS模型。 为了证明考虑工人能力变化的好处,我们实现了RIS(Result Inference with Static worker ability,静态工人能力结果推理)模型,该模型在不考虑工人能力动态变化的情况下,将自身与RID区分开来。RIS的推理方法与RID模型相同,除了M步骤中,我们通过以下方式更新
φ
j
\varphi_j
φj:
(23) φ j = ∣ Q j ∣ / 2 + α − 1 ∑ i = 1 Q j ( r i , j − μ i − b j ) 2 / 2 + β \varphi_j=\frac{|Q_j|/2+\alpha-1}{\sum_{i=1}^{Q_j}(r_{i,j}-\mu_i-b_j)^2/2+\beta}\tag{23} φj=∑i=1Qj(ri,j−μi−bj)2/2+β∣Qj∣/2+α−1(23)
其中 φ \varphi φ被建模为带有参数 α \alpha α和 β \beta β的伽马分布。我们设置了 α = 1 \alpha=1 α=1和 β = 1 \beta=1 β=1,这意味着我们之前不知道 φ \varphi φ。
5.3 评价指标
我们主要使用均方根误差(Root Mean Square Error,RMSE)来测量预测定量估计的准确性,定义如下:
(24)
R
M
S
E
=
1
N
∑
i
(
μ
i
^
−
μ
i
)
2
RMSE=\sqrt{\frac{1}{N}\sum_{i}(\hat{\mu_i}-\mu_i)^2}\tag{24}
RMSE=N1i∑(μi^−μi)2(24)
其中, μ i ^ \hat{\mu_i} μi^代表任务 i i i的估计结果, μ i \mu_i μi是任务 i i i的真实结果。需要注意的是,原始数据集已经提供了真实结果。
5.4 实验结果
结果聚合(不用工人筛选)。 我们首先将RID模型与其他五种不过滤低能力工人的方法进行了比较。我们运行了所有的方法并计算了RMSE值。结果如图4所示,它说明了当工人数量减少时,六种方法的RMSE是如何变化的。每次我们随机抽取10名工人的答案,但在整个实验过程中任务总数固定为400。图4(a)和(b)分别显示了两个数据集的结果。RIS模型考虑了工人的偏差,在两个数据集上RMSE平均比最大可信度法分别低28.5%和低34.1%,只考虑了工人的可信度,而没有考虑偏差。这进一步证实了工人偏差的存在,RIS能够了解偏差并减少偏差对汇总结果的影响。中位数,简单且性能较好,优于LOF和最大可信度法。LOF的性能比最大可信度法差,这表明仅仅删除异常值是不足以发现真值的。不出所料,平均水平表现最差。我们的RID模型在这六种方法中表现最好,在这两种数据集上分别比RIS模型优10.5%和9.7%。事实上,RID相对于RIS的优势取决于总工作时间和任务难度等几个因素,为此,我们稍后将给出另一组模拟结果。
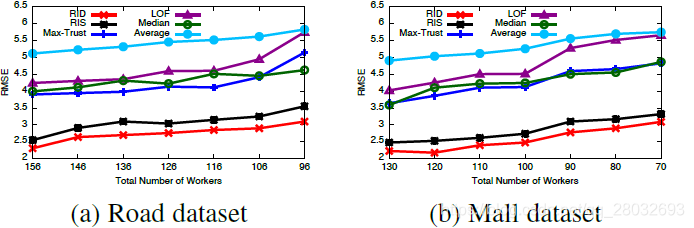
图4:RID的性能
此外,我们还可以观察到,随着工人数量的减少,最大可信度法和LOF的RMSE显著增加。如图4(a)所示,当工人人数从116人减少到96人时,LOF和最大可信度法的RMSE分别增加24%和25%,RID和RIS模型的性能相对稳定,其RMSE得分别只增加8%和12%。这说明了我们方法的健壮性。
结果聚合(使用工人筛选)。 接下来,我们评估了RID-Filter算法的性能,该算法旨在通过动态过滤出低质量的工人,以获得更准确的聚合结果,成本更低。由于CrowdFlower不支持在众包过程中过滤特定工人,因此我们不能直接在CrowdFlower上运行RID-Filter。相应的,我们在收集的数据上运行我们的算法,并通过排除被过滤掉的假设工人提供的答案来模拟工人过滤。一旦AMT或CrowdFlower等众包平台支持特定工人的过滤,RID过滤就可以轻松实现。
图5显示了RID-Filter的RMSE值,因为过滤掉了不同数量的最低质量工人。我们还将RID-R-Filter作为基线绘制结果,该基线随机筛选出与RID筛选器相同数量的工人,并将RID应用于其余答案。水平虚线显示RMSE值,不过滤任何工人。RID-Filter总是优于RID-R-Filter,因为随机过滤可能排除高质量的工人。与RID相比,我们可以看到,当过滤掉不到40个最低质量的工人时,RID-Filter在两个数据集上都优于单纯的RID模型。此外,当30名和20名最低质量的工人分别被过滤出这两个数据集时,RID-Filter的性能最好。这表明,过滤掉太多工人并不总是值得的,因为当剩下的工人很少时,群体智慧的影响将受到负面影响。此外,我们可以得出结论,RID-Filter可以获得与单纯的RID模型相同的结果质量,但成本更低。
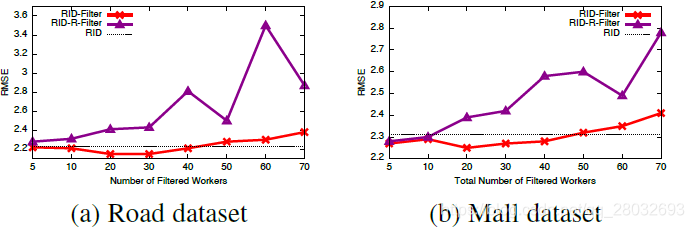
图5:RID滤波器的性能
跟踪工人能力。 图6显示了前5名在两个数据集中完成最多任务的工人展示的精度(即 φ j \varphi_j φj)的倒数。较高的值表示工人能力较低。其中3人完成60项任务,其余7人完成45项任务。在整个任务处理过程中,工人的能力不断变化。此外,这10名工人表现出不同的能力变化模式,这表明在实践中假设某一学习曲线或变化模式可能不正确。此外,图7显示了任务之间的偏差和精度。由于空间限制,我们只显示4名工人完成商场数据集上的45项任务。
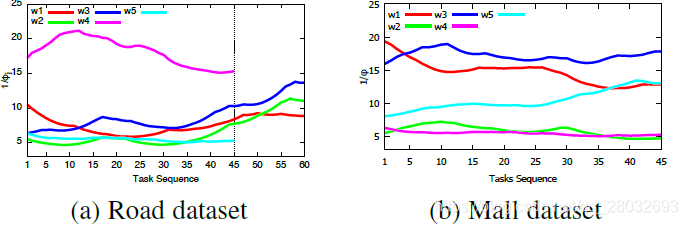
图6:工人能力跟踪(
1
/
φ
j
1/\varphi_j
1/φj)
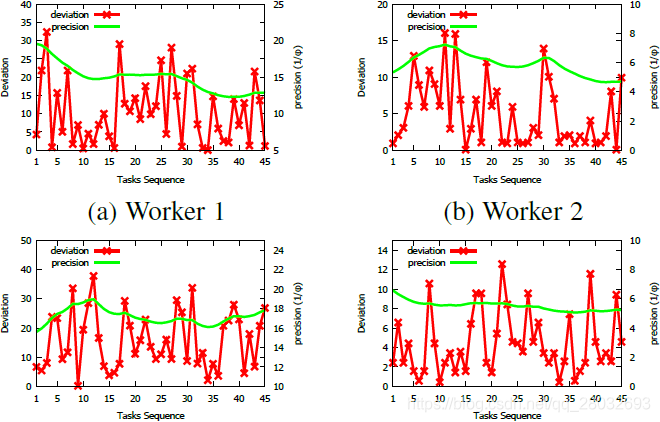
图7:跟踪工人的偏差和能力
模型效率。 接下来,我们研究了我们的方法的效率。所有的算法都运行在一台拥有2.7GHz CPU和4GB RAM的笔记本电脑上。我们对这两个数据集进行了实验。由于空间限制,我们只使用购物中心数据集显示结果。图8(a)显示了我们的方法在5次迭代后收敛,这类似于RIS。由于RIS的似然值比RID的似然值小得多,我们设置比例因子19绘制了它们,以获得更好的视觉效果。图8(b)绘制了在不同数量的工人下运行不同方法的时间。RID模型是最耗时的模型,这并不奇怪,它是由工人能力的动态计算引起的。我们还可以观察到,时间成本随着工人数量的增加而线性增加,这与推理算法的复杂性相一致,这表明我们的方法可以用于大规模的众包任务。
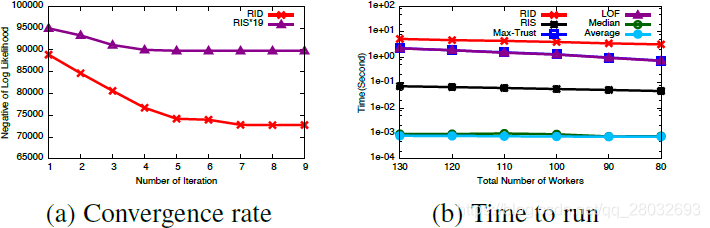
图8:模型效率
5.5 理解RID和RIS之间的性能差距
我们的实验结果表明,RID优于RIS,这得益于对工人精度漂移的跟踪。现在,我们与RIS相比,进一步研究了影响RID性能增益的潜在因素。具体来说,我们进行了模拟,以了解两个重要因素,包括工人的工作量和控制精度漂移变化的方程式(4)中的 λ \lambda λ。这两个因素都影响着工人能力的变化程度。直观地说,当工人的能力发生变化时,RID和RIS之间的性能差距应该增大。
我们生成了200名工人,他们的偏差和初始精度是随机分配的。将平均真值为20的模拟任务分配给8名工人进行处理。我们分别用RID和RIS来推断真值,并计算出相应的RMSE。
首先,我们调查工人工作量的影响。直观地说,当一个工人处理更多的任务时,他的能力改变的机会就越多,因此RID将获得更多的性能提升。参数
λ
\lambda
λ设置为1。时间
t
t
t时工人
j
j
j对任务
i
i
i的回答模拟为:
(25)
A
n
s
j
,
t
=
s
a
m
p
l
e
(
N
(
μ
i
+
b
j
,
1
/
φ
j
,
t
)
)
Ans_{j,t}=sample(N(\mu_i+b_j,1/\varphi_{j,t}))\tag{25}
Ansj,t=sample(N(μi+bj,1/φj,t))(25)
所有工人被分配相同数量的任务,从30到130不等。对于每一个工作量案例,我们进行了10次模拟,并报告了平均值,以消除随机性的影响。结果如图9(a)所示。我们可以观察到,随着工作负载的增加,带有RIS的RMSE会迅速降级,而RID的性能相对稳定。
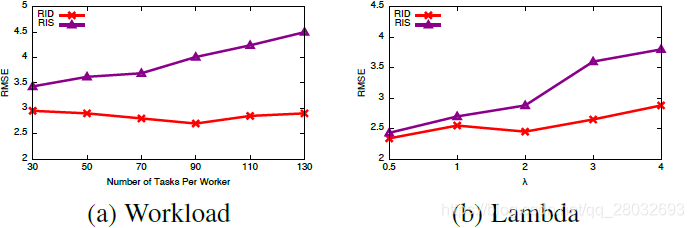
图9:RID如何超越RIS
其次,由于 λ \lambda λ是控制精度漂移变化的高斯分布的方差,较大的 λ \lambda λ意味着工作精度会发生较大的变化。图9(b)表明,随着 λ \lambda λ的增加,RID和RIS之间的性能差距增大。
6 讨论
我们讨论了这项工作的一些局限性和可能的扩展。
分类众包任务的扩展。 在这项工作中,RID模型证明了其比现有的方法在实际实验中具有更高的精度和健壮性,并且在保持精度的同时,通过过滤掉低质量的工人,RID滤波器可以大大降低成本。然而,RID模型是为聚集定量众包任务而设计的,不能直接用于解决类别众包任务。其原因在于,在RID模型中,工人的反应被模拟为高斯分布,其条件是真值、工人的偏差和精度,但对于分类众包任务,答案是离散值,不能被建模为高斯分布,对于大多数分类任务,偏差不是一个适当的工人属性。为了扩展当前支持分类众包任务动态聚合的工作,我们仍然可以使用LDS来模拟工人不断变化的准确性,而我们需要利用其他模型(例如BCC模型[24])来模拟响应生成过程。
RID滤波算法的改进。 在RID过滤算法中,一旦一个工人被确定为不合格,他将不会被考虑用于以后的任务。由于工人的能力受到各种因素的动态影响,经过一定的时间可以提高。从这个意义上讲,过滤后的工人可能需要重新考虑以处理未来的任务。然而,确定何时重新考虑被淘汰的工人是非常重要的。如果一个工人的能力经常和巨大的变化,这意味着相应的工人是高度不可靠的,因此重新考虑一个过滤工人是没有帮助的。在这种情况下,此工作中使用的LDS模型可能无法正常工作,因为在上述场景中,噪声主导系统。为了回答重新考虑被过滤的工人是否有帮助,我们需要改进我们的动态工人能力模型,并将其留给未来的工作。
7 相关工作
近年来,众包在解决文本处理、图像分类、语音识别、视频注释等复杂问题上的成功应用,证明了众包的重要性,其核心问题在于如何在不知名工人可能发出嘈杂答案的情况下获得高质量的结果。
大多数现有的作品主要涉及分类众包问题,在这类问题中,工人们需要为某些对象提供准确的分类标签。在[11]中,作者讨论了几种典型的模型,如多数投票、ZenCrowd[25]、DS & Naive Bayes[26]、GLAD[12]在分类问题上获得共识。近年来,针对特定问题,提出了考虑更为详细因素和领域特定特征的新方法[27]、[28],以充分发挥人群的智慧。然而,这些方法不能直接用于解决本文所讨论的定量真相发现的众包问题。
目前,定量众包在许多领域得到了越来越多的关注,包括一些公民科学项目[29]、数据库[30]、大数据分析[14]、群体感知[15]、MOOC中的同行评分[6]等。有些作品只是使用平均或中位数为基础的方法来汇总结果,同时也有一些先进的模型设计。例如,局部异常因子法(LOF)[21]识别不可靠的报告并删除这些异常值,然后用平均法融合剩余的数据项;最大可信度法[22]通过学习每个参与者的精度来合并工人的响应;[6],[14]进一步引入了更多的参数,包括工人偏差、精度和任务差异。对模特的崇拜。
最近,一些众包研究工作开始关注众包工人的特点。例如,Zhang等[31]研究了中国通过一次真实事件形成的网络众包社区,揭示了群体工人的典型结构和角色特征。然而,在定量众包中,还没有关于工人能力动态的研究。对分类众包中的工人能力动态变化进行了研究。[7]提出了一种用粒子滤波器跟踪工人精度变化的方法,并有选择地查询最可靠的工人,以保证结果质量。此外,在二元分类问题中,通过考虑偏移变量和决策拒绝选择策略,改进了[7]中提出的模型。[9]提出了一个动态贝叶斯模型来同时推断公民科学问题中的绝对真理。[10]假设学习曲线模型,考虑到工人能力的提高,随着更多任务的处理,工人的技能逐渐提高。然而,由于这些方法的概率建模假设是为离散标签设计的,因此不能用于定量寻真方案。据我们所知,我们的工作是第一次尝试动态跟踪工人能力,并将其纳入定量众包问题。
8 结论
定量众包是众包工作的一个重要范畴,但目前还没有得到足够的重视。在这项工作中,我们主要关注的是建立一个模型,以在定量众包任务中获得更好的聚合结果。特别是考虑了工人能力的动态变化,这对最终结果有显著影响。我们设计了一个图形化模型来描述定量众包过程,其中考虑了工人的偏差、工人的能力和潜在的真值。将工人能力进一步建模为一个线性动态系统,在众包过程中采用卡尔曼滤波器和平滑器对其进行动态计算。然后,我们设计了基于EM算法来推断定量任务的潜在真值,并进一步提供了一种工人过滤算法来排除低能力工人,从而以较低的成本保证结果的质量。最后,我们评估了我们的方法,对在公共众包平台中获得的两个公共数据集计算任务。
未来的工作有三个方向。
- 首先,我们将进一步研究不同因素对工人绩效的影响,以便更好地了解工人能力的变化。
- 其次,在改进的工人能力模型的基础上,从确定何时淘汰工人和必要时重新考虑被淘汰工人的角度,对工人过滤算法进行了改进。
- 第三,除了定量众包任务外,我们还将调整解决一般众包任务的方法。
致谢
This work was supported partly by China 973 program (No. 2015CB358700 and No. 2014CB340304), partly by National Key Research and Development Program of China (2016YFB1000804) and partly by NSFC program (61421003).
参考文献
[1] A. Doan, R. Ramakrishnan, and A. Y. Halevy, “Crowdsourcing systems on the world-wide web,” Commun. ACM, vol. 54, no. 4, pp. 86–96, Apr. 2011.
[2] T. Liu, Y. Zhu, Q. Zhang, and A. V. Vasilakos, “Stochastic optimal control for participatory sensing systems with heterogenous requests,” IEEE Trans. Computers, vol. 65, no. 5, pp. 1619–1631, 2016.
[3] H. Wu, H. Sun, Y. Fang, K. Hu, Y. Xie, Y. Song, and X. Liu, “Combining machine learning and crowdsourcing for better understanding commodity reviews,” in Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, 2015, pp. 4220–4221.
[4] J. Aslam, S. Lim, X. Pan, and D. Rus, “City-scale traffic estimation from a roving sensor network,” Proceedings of the 10th ACM Conference on Embedded Network Sensor Systems, pp. 141–154, 2012.
[5] H. Wang, D. Lymberopoulos, and J. Liu, “Local business ambience characterization through mobile audio sensing,” in Proceedings of the 23rd international conference on World wide web, 2014, pp. 293–304.
[6] C. Piech, J. Huang, Z. Chen, C. Do, A. Ng, and D. Koller, “Tuned models of peer assessment in moocs,” Proceedings of The 6th International Conference on Educational Data Mining, 2013.
[7] P. Donmez, J. G. Carbonell, and J. G. Schneider, “A probabilistic framework to learn from multiple annotators with time-varying accuracy,” SIAM International Conference on Data Mining, 2010.
[8] H. J. Jung, Y. Park, and M. Lease, “Predicting next label quality: A time-series model of crowdwork,” in Proceedings of the Seconf AAAI Conference on Human Computation and Crowdsourcing, 2014.
[9] E. Simpson, S. Roberts, I. Psorakis, and A. Smith, “Dynamic bayesian combination of multiple imperfect classifiers,” in Decision Making and Imperfection. Springer, 2013, pp. 1–35.
[10] S. Pan, K. Larson, J. Bradshaw, and E. Law, “Dynamic task allocation algorithm for hiring workers that learn,” in Proceedings of the Twenty- Fifth International Joint Conference on Artificial Intelligence, IJCAI 2016, New York, NY, USA, 9-15 July 2016, 2016, pp. 3825–3831.
[11] A. Sheshadri and M. Lease, “Square: A benchmark for research on computing crowd consensus,” in First AAAI Conference on Human Computation and Crowdsourcing, 2013.
[12] J. Whitehill, P. Ruvolo, T. Wu, J. Bergsma, and J. R. Movellan, “Whose vote should count more: Optimal integration of labels from labelers of unknown expertise.” Advances in Neural Information Processing Systems, pp. 2035–2043, 2009.
[13] T. Han, H. Sun, Y. Song, Y. Fang, and X. Liu, “Incorporating external knowledge into crowd intelligence for more specific knowledge acquisition,” in Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, 2016, pp. 1541–1547.
[14] R. W. Ouyang, L. Kaplan, P. Martin, A. Toniolo, M. Srivastava, and T. J. Norman, “Debiasing crowdsourced quantitative characteristics in local businesses and services,” in Proceedings of the 14th International Conference on Information Processing in Sensor Networks. ACM, 2015, pp. 190–201.
[15] M. Venanzi, W. T. L. Teacy, A. Rogers, and N. R. Jennings, “Bayesian modelling of community-based multidimensional trust in participatory sensing under data sparsity,” in Proceedings of the 24th International Conference on Artificial Intelligence, ser. IJCAI’15, 2015, pp. 717–724.
[16] R. E. Kalman, “Mathematical description of linear dynamical systems,” Journal of the Society for Industrial and Applied Mathematics, vol. 1, no. 2, pp. 152–192, 1963.
[17] G. Welch and G. Bishop, “An introduction to the Kalman Filter,” University of North Carolina at Chapel Hill, vol. 785. ISBN 978-3-642- 02287-6. Springer-Verlag Berlin Heidelberg, no. 7, pp. 127–132, 1995.
[18] M. Shuster, “A simple Kalman Filter and Smoother for spacecraft attitude,” in Journal of the Astronautical Sciences, 1989, pp. 89–106.
[19] C. M. Bishop, Pattern Recognition and Machine Learning (Information Science and Statistics). Secaucus, NJ, USA: Springer-Verlag New York, Inc., 2006.
[20] A. B. Chan, M. Morrow, and N. Vasconcelos, “Analysis of crowded scenes using holistic properties,” in Performance Evaluation of Tracking and Surveillance workshop at CVPR, 2009, pp. 101–108.
[21] M. M. Breunig, H. P. Kriegel, R. T. Ng, and J. Sander, “Lof: Identifying density-based local outliers.” Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, vol. 29, no. 2, pp. 93–104, 2000.
[22] M. Venanzi, A. Rogers, and N. R. Jennings, “Trust-based fusion of untrustworthy information in crowdsourcing applications,” in Proceedings of the 2013 International Conference on Autonomous Agents and Multiagent Systems, 2013, pp. 829–836.
[23] S. J. Julier and J. K. Uhlmann, “A non-divergent estimation algorithm in the presence of unknown correlations,” in In Proceedings of the American Control Conference, 1997.
[24] M. Venanzi, J. Guiver, G. Kazai, P. Kohli, and M. Shokouhi, “Community-based bayesian aggregation models for crowdsourcing,” in Proceedings of the 23rd international conference on World wide web. ACM, 2014, pp. 155–164.
[25] G. Demartini, D. E. Difallah, and P. Cudr´e-Mauroux, “Zencrowd: Leveraging probabilistic reasoning and crowdsourcing techniques for largescale entity linking,” in Proceedings of the 21st International Conference on World Wide Web, ser. WWW ’12, 2012, pp. 469–478.
[26] P. Dawid, A. M. Skene, A. P. Dawidt, and A. M. Skene, “Maximum likelihood estimation of observer error-rates using the em algorithm,” Applied Statistics, pp. 20–28, 1979.
[27] Y. Sun, A. Singla, D. Fox, and A. Krause, “Building hierarchies of concepts via crowdsourcing,” in Proceedings of the 24th International Conference on Artificial Intelligence, 2015, pp. 844–851.
[28] E. D. Simpson, M. Venanzi, S. Reece, P. Kohli, J. Guiver, S. J. Roberts, and N. R. Jennings, “Language understanding in the wild: Combining crowdsourcing and machine learning,” in Proceedings of the 24th International Conference on World Wide Web, 2015, pp. 992–1002.
[29] A. M. Smith, S. Lynn, and C. J. Lintott, “An introduction to the zooniverse,” in First AAAI conference on human computation and crowdsourcing, 2013.
[30] G. Li, J. Wang, Y. Zheng, and M. J. Franklin, “Crowdsourced data management: A survey,” IEEE Trans. Knowl. Data Eng., vol. 28, no. 9, pp. 2296–2319, 2016.
[31] Q. Zhang, D. D. Zeng, F. Y. Wang, R. Breiger, and J. A. Hendler, “Brokers or bridges? exploring structural holes in a crowdsourcing system,” Computer, vol. 49, no. 6, pp. 56–64, June 2016.

















 582
582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









