







 现有行人重识别方法多基于监督学习,人工标注成本高,传统无监督方法性能低。本文提出自底向上聚类方法(BUC)解决无监督行人重识别问题,通过联合优化CNN和无标签样本关系,利用repelled loss优化模型,加入多样性归一化项,经实验验证有一定效果。
现有行人重识别方法多基于监督学习,人工标注成本高,传统无监督方法性能低。本文提出自底向上聚类方法(BUC)解决无监督行人重识别问题,通过联合优化CNN和无标签样本关系,利用repelled loss优化模型,加入多样性归一化项,经实验验证有一定效果。
A Bottom-up Clustering Approach to Unsupervised Person Re-identification
目录
A Bottom-up Clustering Approach to Unsupervised Person Re-identification
4.2 Bottom-Up Clustering method (BUC)
1. Introduction
现有的大部分行人重识别方法都是基于监督学习的,需要对训练数据进行人工标注,然后对于大型的数据集,人工标注的成本太高。
传统的无监督方法侧重于手工特性。这些方法产生的性能比监督方法低得多,不适用于大规模的实际数据。
基于深度学习方法的“无监督”行人重识别利用了从其他reid数据集中学到的先验知识。
这篇文章解决的是无任何标签的无监督行人再识别问题,作者提出了一种自底向上聚类方法(bottom-up clustering BUC)来联合优化CNN和无标签样本间的关系。

2. 贡献:
提出了自底向上聚类框架来解决无监督行人重识别,在保持最大化相同身份的行人之间的相似性的同时最大化的保存行人之间的多样性。
利用repelled loss 直接优化样本或聚类的之间的余弦距离来优化没有标签的模型。使得不同类之间的多样性最大化,每个聚类或样本的相似性最大化。
多样性归一化项能够平衡每个聚类的聚类数目,使得聚类结果与真实分布更加的接近。

3. 流程图
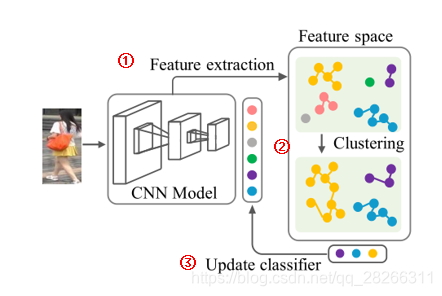
本文的流程图如图所示,主要分为三个步骤,将一个没有标签的行人图片作为输入
1.首先通过CNN网络来提取行人特征用来聚类。
2.然后在整个数据集中聚类合并,
3. 最后根据聚类后的结果重新训练模型,
不断迭代执行这三个步骤,直到行人身份多样以及相似性达到最大化之后结束。
示例
该图是对本文执行过程举一个简单的例子。N表示训练样本的数量,C表示聚类之后的聚类数量。在最开始执行的时候,我们将数据集中的每个样本都作为一个单独的聚类,由于本文是没有真实的标签,因此,我们将聚类序列ID作为标签。随着聚类的不断迭代,每次聚类都是利用前一个阶段的聚类的结果以及现阶段的特征相似性进行聚类。这样就可以不断的合并相同身份的样本,聚类结果也在不断的更新变化,每次聚类结束之后都将新的聚类ID 作为训练样本的标签。
这样,通过自底向上的聚类可以将身份相同的行人样本聚为一类。

4. Methodology
4.1 Preliminary

4.2 Bottom-Up Clustering method (BUC)

CNN提取特征后,和查找表计算cosine距离:?其中,每个样本属于第C个聚类的可能性可以用下面的式子表示。X表示训练样本数据,C表示聚类数量。V表示一个查找表,查找表中存储的是每个聚类特征,Vj表示V中的第j个元素,包含第j个聚类中所有图片的特征信息。分别计算当前样本特征x和查找表每类特征间的cosine距离,然后除以和所有类特征间距离之和(类似softmax)作为x属于这类的概率。除以温度参数τ,控制每个样本的聚类结果的柔软性,然后,对x所属的类y^i使用下式计算loss。在反向传播过程中,V的更新通过式子进行更新,将原来聚类的特征与新的数据特征进行求和并求平均。查找表V可以避免在每个训练步骤中从所有数据中提取特征的冗长计算。
每次聚类完成之后,训练图片的标签都会更新为最新的聚类ID。

对于迭代过程中,聚类的合并方式,作者采用层次聚类的方法来自底向上合并类。
步骤一:(初始化)将每个样本都视为一个聚类;
步骤二:计算各个聚类之间的相似度;
步骤三:寻找最近的两个聚类,将他们归为一类;
作者聚类的合并采用最小距离策略来计算两个聚类之间的多样性。最小距离策略是计算两个聚类之间每个元素的欧几里得距离,然后将聚类之间元素的最短聚类作为两个聚类之间的多样性距离,用下面的式子表示。但是每次合并时,聚类的合并并不是任意的。从小到大合并固定数量,作者通过指定每次聚类合并过程中聚类合并数量来控制聚类合并的速度。每次迭代剩余类数:C=N-t*m。类间距离计算公式如下:
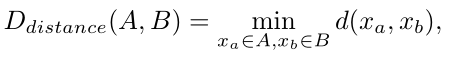
此外,作者还测试了另外两种合并策略,一种是最大距离策略,选择每个聚类元素之间的最大距离作为多样性,这种策略可能导致同一身份不同摄像头的行人被划分为不同的类。另外一种是中心聚类策略,选择每个聚类的元素平均特征进行度量。但是平均操作可能忽视掉有用的相机信息,最终使用最小距离策略的准确率最高,因此,作者最终采用了最小距离策略作为聚类合并的策略。

4.3 Diversity Regularization
由于我们在实验过程中不知道每个样本图片的身份,但是我们假定每个身份的行人图片的数量是相近的。基于这一点考虑,作者加入了一项多样性归一化项约束,约束项如下面的公式所示:其中|A|表示聚类A的数量。最终的多样性距离公式可以用下式表示。这样当我们两个聚类的欧几里得距离较近,但是两个聚类都包含较多的图片时,总的距离较大,这样就避免了这两个聚类的合并,在一定程度上可以提高准确率。


第一次迭代C=N,然后使用X,Y和训练CNN。训练完成后根据类间距离合并m个类,然后重新用样本所属的新类作为新标签Y,再次训练CNN。然后迭代这个过程。每次迭代后,在测试集上测试网络的表现,当网络表现下降时停止迭代。
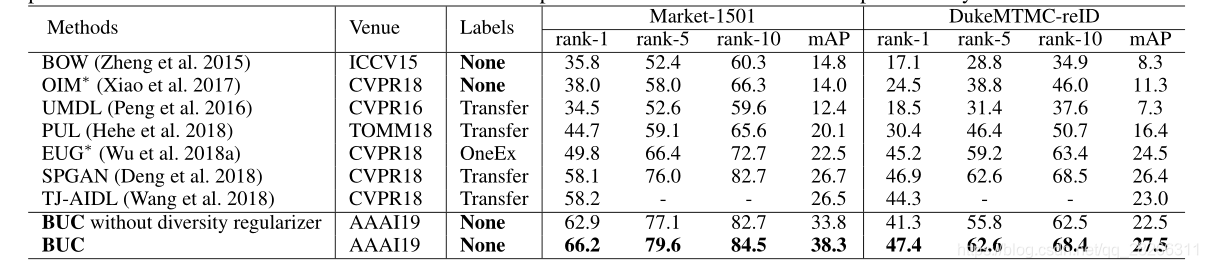
5. 实验结果

相同颜色的点表示相同身份的图像。我们展示了一个正面示例(绿色圆圈)和一个负面示例(红色圆圈)的详细图像。绿色圆圈中的点是相同的。在红圈中,绿点和黄点聚集在一起,说明我们的算法误将它们合并成一个簇。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









