






摘要
我们将问答(QA)框架定义为强化学习任务,这种方法称为主动问答。我们提出一个agent,该agent位于用户和黑盒问答系统之间,并学会重新制定问题以得出最佳答案。agent使用对初始问题进行的许多自然语言重构成来探查系统,并汇总返回的证据以得出最佳答案。对重构系统进行了端到端训练,以使用策略梯度最大程度地提高回答质量。我们对SearchQA进行评估,SearchQA是从Jeopardy!中提取的复杂问题的数据集。该agent的性能超过了最新的基本模型,发挥了环境和其他基准的作用。我们还分析了agent与问答系统交互时所学的语言。我们发现成功的问题改写从自然语言复述上看起来完全不同。该agent能够发现类似于经典信息检索技术的非凡重构策略,例如词频重新加权(tf-idf)和词干。
1.介绍
网络和社交媒体已成为信息的主要来源。用户的期望和信息搜索活动随着这些资源的日益复杂而发展。除了导航,文档检索和简单的事实问答之外,用户还寻求对复杂和组合问题的直接答案。这样的搜索会话可能需要多次迭代,严格评估和综合。
自然语言的复杂性会产生无数种提出问题的方式。面对复杂的信息需求,人类可以通过重新构造问题,进行多次搜索以及汇总响应来克服不确定性。受人类提出正确问题的能力的启发,我们提出了一种agent,可以为用户学习如何执行此过程。agent位于用户和我们称为“环境”的后端问答系统之间。我们将其称为agnet AQA,因为它实施了主动的问答策略。AQA旨在通过向环境发送重新制定的问题来最大程度地获得正确答案的机会。agent通过询问许多问题并汇总返回的证据来寻求最佳答案。该环境的内部内容不适用于agent,因此它必须学会仅使用问题字符串来最佳地探测黑盒。AQA agent程序的关键组件是Seq2Seq模型,该模型使用基于环境返回的答案的奖赏通过强化学习(RL)进行训练。AQA的第二个组成部分结合了使用卷积神经网络与环境交互的证据来选择答案。
我们对Jeopardy!中提取的问题数据集SearchQA进行评估。这些问题很难用规则来回答,因为它们使用了令人费解的语言,例如,Travel doesn’t seem to be an issue for this sorcerer & onetime surgeon; astral projection & teleportation are no prob (answer: Doctor Strange)。因此,SearchQA测试了AQA重新制定问题的能力,以使QA系统返回最有可能的正确答案。AQA改善了为QA构建的深度网络BiDAF的性能,该网络在多个任务上产生了最新的结果,绝对F1提升了11.4%,相对F1提升了32% 。此外,AQA优于其他竞争性启发式查询重新制定基准。
AQA定义了机器-机器通信的实例。对话的一方,即AQA agent,正在尝试调整其语言,以改善另一方(即QA环境)的响应。为了阐明这一过程,我们对AQA agent生成的语言进行了定性分析。通过对MSCOCO进行评估,我们发现agent的问题改写在自然语言释义有很大不同。但是,值得注意的是,agent能够学习到非凡和明显的策略。特别是,agent能够发现经典的IR查询操作,例如词频重新加权,类似tf-idf和形态简化/词干化。一个可能的原因是,当前的机器理解任务涉及对短文本片段的排名,从而激发了相关性,而不仅仅是对语言的深刻理解。
2.相关工作
Lin & Pantel (2001)通过比较依存解析树来学习问题变种的模式。Duboue & Chu-Carroll (2006)表明,基于MT的复述原则上可以通过在基于Oracle的QA性能评估中提供足够的空间来使用。 最近,Berant & Liang (2014)使用复述扩展了作为潜在表示的释义,从而增强了语义解析器的训练。双语语料库和MT已通过在第二语言中翻转来生成复述。最近的工作使用神经翻译模型和多重翻转。相反,我们的方法不使用翻转,而据我们所知,它是第一个直接的神经复述系统。Riezler et al. (2007)提出了基于短语的复述来进行问题扩展。与该工作线相反,我们的目标是在优化端到端目标性能的同时重新生成完整的问题表述。
强化学习在自然语言理解的许多问题上日益受到关注。例如,Narasimhan et al. (2015) 使用RL来学习多用户地下城游戏的控制策略,其中游戏状态通过文字描述进行了总结,而Li et al. (2016)使用RL进行对话生成。最近针对MT和其他序列间问题研究了策略梯度方法。它们减轻了交叉熵损失的单词级优化所固有的局限性,从而允许使用序列级奖赏函数(例如BLEU)。基于语言模型和重构错误的奖赏函数可用于以更少的资源自举MT。 RL训练还可以防止产生偏差:训练和推理之间的不一致是由于模型在训练过程中从未发现自己的错误。我们还使用策略梯度来优化agent,但是,我们使用端到端的问答质量作为奖赏。
在QA上使用策略梯度的方法包括Liang et al. (2017),他训练了语义解析器来查询知识库, Seo et al. (2017b) 提出了将问题转换为回答涉及多个常识推理的问题的问题减少网络。 Nogueira & Cho (2016)的工作与我们的工作最相关。他们通过跟随图上的链接来识别包含问题答案的文档。通过评估游戏Jeopardy!中的一系列问题,他们学习遍历Wikipedia图,直到达到预期的答案。在后续工作中,Nogueira & Cho (2017)通过相关性反馈与RL相结合的启发来改进文档检索。他们通过添加从搜索引擎检索的文档中的术语来重新构造原始问题。我们的工作不同之处在于,我们生成完整的序列表述而不是添加单个术语,并且我们针对问题解答而不是文档检索。
主动QA还与最近的事实检查研究有关:Wu et al. (2017)提出扰动数据库问题,以估计对定量声明的支持。在主动QA中,问题会以类似的目的在语义上受到干扰,尽管直接以表面自然语言形式出现。
3.主动问答模型
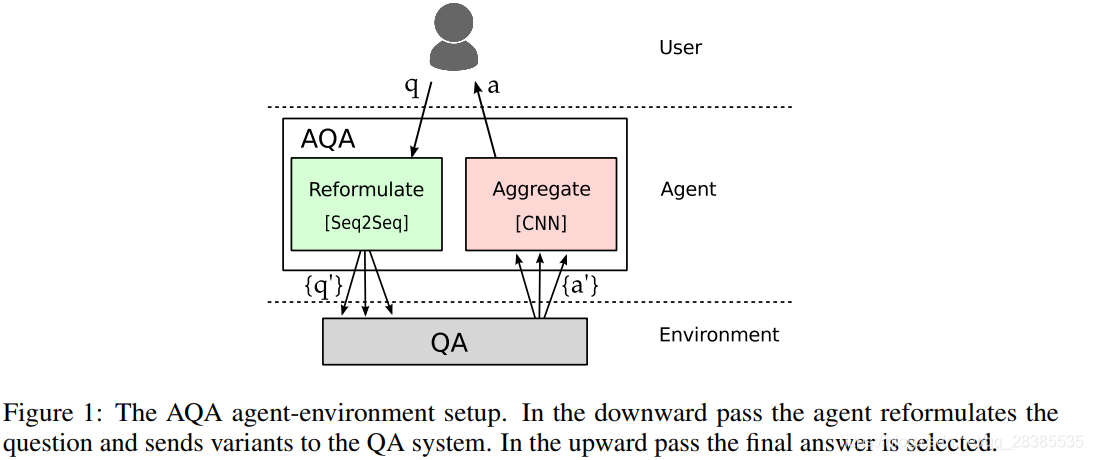
图1显示了主动问答(AQA)agent环境设置。AQA模型与黑盒环境进行交互。AQA用一个问题的多个版本对其进行查询,最后返回找到的最佳答案。每一个情节从原始问题
q
0
q_0
q0开始。然后,agent生成一组重新制定的问题
{
q
i
}
i
=
1
N
\{q_i\}^N_{i=1}
{qi}i=1N。这些被发送到返回答案
{
a
i
}
i
=
1
N
\{a_i\}^N_{i=1}
{ai}i=1N的环境。然后,选拔模型从这些候选答案中选出最好的。
3.1 问答环境
对于QA环境,我们使用一种较好的神经问答模型,双向注意力流(BiDAF)。BiDAF是一种提取QA系统,它从给定文档的连续跨度中选择答案。给定一个问题,环境将返回一个答案,并在训练期间返回奖赏。奖赏可以是返回答案的任何质量指标,我们使用字符级别的F1分数。注意,针对每个答案 a i a_i ai的奖赏是针对原始问题 q 0 q_0 q0计算的。我们假设环境是不透明的。agent无法访问其参数,激活函数或梯度。这项设置原则上使agent也可以与其他信息源进行交互,从而可能以不同的模式提供反馈,例如图像和知识库中的结构化数据。但是,如果不能通过环境传播梯度,我们将会丢失信息,而对问题重构的质量反馈却很嘈杂,这给训练带来了挑战。
3.2 重构模型
重构器是一个Seq2Seq模型,在神经机器翻译中很流行。我们以Britz et al. (2017)的实现为基础。与标准MT设置的主要不同之处在于,我们的模型以相同的语言重构了话语。与MT不同,几乎没有高质量的训练数据可用于单语复述。高度参数化的神经网络的有效训练依赖于大量数据。我们首先通过对相关任务进行预训练,多语言翻译,然后使用与环境交互过程中产生的信号进行调整来应对这一挑战。
3.3 答案选择模型
在训练期间,我们能够获得每个重构的 q i q_i qi所返回答案的奖赏。但是,在测试时,我们必须预测最佳答案 a ∗ a^∗ a∗。选择模型通过预测所有变种的 F 1 F1 F1得分与平均 F 1 F1 F1的差异,从交互过程中观察到的 { a i } i = 1 N \{a_i\}^N_{i=1} {ai}i=1N中选择最佳答案。我们将预训练的嵌入用于问题,重写和答案的字符。对于上述的每一个,我们添加一维 C N N CNN CNN,然后进行最大池化。然后将三个结果向量连接起来并通过前馈网络,该网络会产生输出。
4.训练
4.1 问答环境
我们将针对即将进行的QA任务在训练集上训练模型,有关详细信息,请参见第5.4节。此后,BiDAF成为黑盒环境,其参数不再进一步更新。原则上,我们可以共同训练agent和环境,以进一步提高性能。但是,这不是我们期望的任务:我们的目标是使agent学习使用自然语言在无法控制的环境中进行通信。
4.2 策略梯度训练重构模型
对于给定的问题
q
0
q_0
q0,我们希望返回最佳答案
a
∗
a^*
a∗,从而使奖励
a
∗
=
a
r
g
m
a
x
a
R
(
a
∣
q
0
)
a^*=argmax_a R(a|q_0)
a∗=argmaxaR(a∣q0)最大化。通常,
R
R
R是答案上的字符级别
F
1
F1
F1分数。答案
a
=
f
(
q
)
a=f(q)
a=f(q)是问题
q
q
q的未知函数,由环境计算得出。针对原始问题
q
0
q_0
q0计算奖励,同时为
q
q
q提供答案。根据策略
π
θ
π_θ
πθ生成问题,其中
θ
θ
θ是策略的参数
q
〜
π
θ
(
⋅
∣
q
0
)
q〜π_θ(·| q_0)
q〜πθ(⋅∣q0)。该策略(在这种情况下为Seq2Seq模型)分配的概率为:
π
θ
(
q
∣
q
0
)
=
∏
t
=
1
T
p
(
w
t
∣
w
1
,
.
.
.
,
w
t
−
1
,
q
0
)
\pi_{\theta}(q|q_0)=\prod^{T}_{t=1}p(w_t|w_1,...,w_{t-1},q_0)
πθ(q∣q0)=t=1∏Tp(wt∣w1,...,wt−1,q0)
对于任何可能的问题
q
=
w
1
,
…
,
w
T
q=w_1,\dots,w_T
q=w1,…,wT,其中
T
T
T是
q
q
q的长度,包含来自固定词汇表
V
V
V的字符
w
t
∈
V
w_t∈V
wt∈V。目的是使根据策略
E
q
〜
π
θ
(
⋅
∣
q
0
)
[
R
(
f
(
q
)
)
]
\mathbb E_{q〜π_θ(·|q_0)}[R(f(q))]
Eq〜πθ(⋅∣q0)[R(f(q))]返回的答案的期望奖赏最大化。我们使用Policy Gradient方法直接针对策略参数优化奖赏。预期奖赏无法以封闭形式进行计算,因此我们使用蒙特卡洛抽样来计算无偏估计,即
E
q
〜
π
θ
(
⋅
∣
q
0
)
[
R
(
f
(
q
)
)
]
≈
1
N
∑
i
=
1
N
R
(
f
(
q
i
)
)
,
q
i
∼
π
θ
(
⋅
∣
q
0
)
(2)
\mathbb E_{q〜π_θ(·|q_0)}[R(f(q))]\thickapprox\frac{1}{N}\sum^{N}_{i=1}R(f(q_i)),q_i\sim \pi_{\theta}(\cdot|q_0)\tag{2}
Eq〜πθ(⋅∣q0)[R(f(q))]≈N1i=1∑NR(f(qi)),qi∼πθ(⋅∣q0)(2)
为了计算梯度用于训练,我们使用REINFORCE,
∇
E
q
〜
π
θ
(
⋅
∣
q
0
)
[
R
(
f
(
q
)
)
]
=
E
q
∼
π
θ
(
⋅
∣
q
0
)
∇
θ
l
o
g
(
π
θ
(
q
∣
q
0
)
)
R
(
f
(
q
)
)
(3)
\nabla \mathbb E_{q〜π_θ(·|q_0)}[R(f(q))]=\mathbb E_{q\sim\pi_{\theta}(\cdot|q_0)}\nabla_{\theta}log(\pi_{\theta}(q|q_0))R(f(q))\tag{3}
∇Eq〜πθ(⋅∣q0)[R(f(q))]=Eq∼πθ(⋅∣q0)∇θlog(πθ(q∣q0))R(f(q))(3)
≈
1
N
∑
i
=
1
N
∇
θ
l
o
g
(
π
(
q
i
∣
q
0
)
)
R
(
f
(
q
i
)
)
,
q
i
∼
π
θ
(
⋅
∣
q
0
)
(4)
\thickapprox\frac{1}{N}\sum^{N}_{i=1}\nabla_{\theta}log(\pi(q_i|q_0))R(f(q_i)),\quad q_i\sim\pi_{\theta}(\cdot|q_0)\tag{4}
≈N1i=1∑N∇θlog(π(qi∣q0))R(f(qi)),qi∼πθ(⋅∣q0)(4)
通常发现该估计器具有较高的方差,导致训练不稳定。我们通过减去以下基线奖励来减少方差:
B
(
q
0
)
=
E
q
〜
π
θ
(
⋅
∣
q
0
)
[
R
(
f
(
q
)
)
]
B(q_0)=\mathbb E_{q〜π_θ(·| q_0)}[R(f(q))]
B(q0)=Eq〜πθ(⋅∣q0)[R(f(q))],此期望可以通过从给定
q
0
q_0
q0的策略中采样来计算。 我们经常观察到收敛于次优的确定性策略。为了解决这个问题,我们使用熵正则化:
H
[
π
θ
(
q
∣
q
0
)
]
=
−
∑
t
=
1
T
∑
w
t
∈
V
p
θ
(
w
t
∣
w
<
t
,
q
0
)
l
o
g
p
θ
(
w
t
∣
w
<
t
,
q
0
)
(5)
H[\pi_{\theta}(q|q_0)]=-\sum^T_{t=1}\sum_{w_t\in V}p_{\theta}(w_t|w_{<t},q_0)log~p_{\theta}(w_t|w_{<t},q_0)\tag{5}
H[πθ(q∣q0)]=−t=1∑Twt∈V∑pθ(wt∣w<t,q0)log pθ(wt∣w<t,q0)(5)
最终的目标函数为:
E
q
∼
π
θ
(
⋅
∣
q
0
)
[
R
(
f
(
q
)
)
−
B
(
q
0
)
]
+
λ
H
[
π
(
q
∣
q
0
)
]
,
(6)
\mathbb E_{q\sim\pi_{\theta}(\cdot|q_0)}[R(f(q))-B(q_0)]+\lambda H[\pi(q|q_0)],\tag{6}
Eq∼πθ(⋅∣q0)[R(f(q))−B(q0)]+λH[π(q∣q0)],(6)
其中,
λ
\lambda
λ是正则化权重。
4.3 答案选择
与重构策略不同,我们通过集束搜索或抽样来训练答案。我们可以从我们的重构系统中对单个问题进行多次重写。我们向QA环境发出每次重写,生成一个 ( q u e r y , r e w r i t e , a n s w e r ) (query, rewrite, answer) (query,rewrite,answer)元组集合,我们需要从中选择最佳实例。我们训练另一个神经网络,从候选中选出最佳答案。我们将此任务定义为二分类,以区分高于和低于平均表现。在训练中,我们为每个实例计算答案的F1分数。如果重写产生的F1分数大于其他重写的平均分数的答案,则为该实例分配一个肯定标签。我们忽略所有重写都会产生相同的好/坏答案的问题。我们评估了FFNN,LSTM和CNN,发现所有系统的性能都是差不多的。我们选择的CNN具有良好的计算效率和准确性(请参阅3.3)。
4.4 预训练重构模型
我们通过构建可以将英语翻译成英语的神经MT模型来对策略进行预训练。尽管并行语料库可用于许多语言对,但英语-英语语料库却很少。我们首先建立了一种多语言翻译系统,可以在几种语言之间进行翻译。这使我们可以使用可用的双语语料库。多语言训练只需要在每行中添加两个特殊标记来表示源语言和目标语言。转换模型的编码器-解码器体系结构保持不变。
如Johnson et al. (2016)显示,该模型可用于零样本翻译,即在没有训练样例的语言对之间进行翻译。例如,在训练了英语到西班牙语,英语到法语,法语到英语和西班牙语到英语之后,该模型学会了单个编码器,该编码器对英语,西班牙语和法语进行编码,以及一个针对相同三种语言的解码器。 因此,通过将相应的标记添加到源中,我们可以为法语-西班牙语,西班牙语-法语以及英语-英语翻译使用相同的模型。Johnson et al. (2016)指出,零样本翻译通常比桥接差,另外一种方式是两次使用该模型:首先,翻译成枢轴语言,然后翻译成目标语言。但是,可以通过针对所需语言对进行一些训练来弥补性能差距。因此,我们首先训练多语言数据,然后训练一小部分单语言数据。

















 870
870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









