






摘要
神经机器翻译(NMT)是一种用于自动翻译的端到端学习方法,具有克服传统基于短语的翻译系统的许多弱点的潜力。不幸的是,众所周知,NMT系统在训练和翻译推理方面在计算上都是昂贵的–在非常大的数据集和大型模型的情况下,有时会令人望而却步。一些研究人员还指控NMT系统缺乏鲁棒性,特别是当输入句子包含稀有单词时。这些问题阻碍了NMT在实际部署和服务中的使用,这些部署和服务中准确性和速度都至关重要的。在这项工作中,我们介绍了GNMT,即Google的神经机器翻译系统,该系统试图解决其中的许多问题。我们的模型包括一系列深度LSTM网络,该网络具有8个编码器和8个解码器层,使用残差连接以及从解码器网络到编码器的注意力连接。为了提高并行度并因此减少训练时间,我们的注意力机制将解码器的底层连接到编码器的顶层。为了加快最终翻译速度,我们在推理计算过程中采用了低精度算法。为了改善对稀有单词的处理,我们将单词分为有限的一组公共子词单元(wordpieces)集合,用于输入和输出。这种方法在“字符”级模型的灵活性与“单词”级模型的效率之间取得了良好的平衡,自然地处理了稀有单词的翻译,并最终提高了系统的整体准确性。我们的集束搜索技术采用长度归一化方法并使用覆盖率惩罚,这会鼓励生成最有可能覆盖源句子中所有单词的输出句子。为了直接优化翻译BLEU分数,我们考虑使用强化学习来完善模型,但是我们发现BLEU分数的提高并未反映在人工评估中。在WMT’14的英语到法语和英语到德语的基准测试中,GNMT取得了最好的测试结果。与一组基于短语的生成系统相比,通过对一组孤立的简单句子进行人工并排评估,可将翻译错误平均减少60%。
1.介绍
神经机器翻译(NMT)最近被引入作为一种有效的方法,有可能解决传统机器翻译系统的许多缺点。NMT的优势在于它能够以端到端的方式直接学习从输入文本到关联的输出文本的映射的能力。它的体系结构通常由两个循环神经网络(RNN)组成,一个用于获取输入文本序列,另一个用于生成翻译的输出文本。NMT通常伴随着注意力机制,该机制可以帮助它有效地应对较长的输入序列。
神经机器翻译的一个优点是它避免了传统的基于短语的机器翻译中许多脆弱的设计选择。然而,实际上,NMT系统过去的准确性要比基于短语的翻译系统差,特别是在针对非常好的公共翻译系统所使用的超大规模数据集进行训练时。
神经机器翻译的三个固有弱点是造成这种差距的原因:
(1)训练速度和推理速度较慢;
(2)处理稀有单词的效率低下;
(3)有时无法翻译源句子中的所有单词。
首先,在大规模翻译数据集上训练NMT系统通常需要花费大量时间和计算资源,从而减慢了实验周转时间和创新的速度。在翻译推理时,由于使用了大量参数,它们通常比基于短语的系统慢得多。其次,NMT在翻译稀有单词方面缺乏鲁棒性。尽管原则上可以通过训练“复制模型”来模仿传统的对齐模型来解决,或通过使用注意力机制来复制稀有词来解决,但由于对齐质量因语言而异,这些方法在大规模上都不可靠,并且当网络较深时,由注意力机制产生的潜在对齐方式是不稳定的。同样,简单复制可能并不总是应付稀有字词的最佳策略,例如在音译更合适的情况下。最后,NMT系统有时会产生无法翻译输入句子所有部分的输出句子,换句话说,它们无法完全“覆盖”输入内容,这可能导致令人诧异的翻译结果。
这项工作介绍了GNMT的设计和实现,这是Google提供的NMT系统,旨在为上述问题提供解决方案。在我们的实现中,循环网络是长短期记忆(LSTM)RNN 。我们的LSTM RNN具有8层,各层之间具残差连接以加速梯度传播。对于并行性,我们将注意力从解码器网络的底层连接到编码器网络的顶层。为了缩短推理时间,我们采用了低精度的推理算法,并通过特殊硬件(Google的Tensor Processing Unit,即TPU)进一步加快了推理速度。为了有效处理稀有单词,我们在系统中使用子词单元(也称为“wordpieces”)作为输入和输出。使用wordpieces可以在单个字符的灵活性和完整单词的解码效率之间取得良好的平衡,并且也避免了对未知字词进行特殊处理的需求。我们的集束搜索技术包括一个长度归一化过程,可以有效地处理在解码过程中比较不同长度的假设的问题,另外,我们还提供了一个覆盖损失,可以鼓励模型覆盖所有提供的输入。
我们的实现是健壮的,并且在许多语言对之间的一系列数据集上表现良好,而无需进行特定于语言的调整。使用相同的实现,我们获得的结果可以与标准基准上的最新技术相媲美或优于以前的最新系统,同时对Google的基于短语的生成翻译系统进行了重大改进。具体而言,在WMT’14英语到法语中,我们的单个模型得分为38.95 BLEU,比[31]中报告的没有外部对齐模型的单个模型得分高了7.5 BLEU,而比[45]中报告的与没有外部对齐模型的单个模型得分则为高了1.2 BLEU。我们的单个模型也可以与[45]中的单个模型进行比较,而没有像[45]中那样使用任何对齐模型。同样,在WMT’14英语到德语的比赛中,我们的单个模型得分为24.17 BLEU,比以前的基准高3.4 BLEU。在生产数据上,我们的实施更加有效。人工评估显示,与我们先前基于短语的系统相比,GNMT在许多语言对上的翻译错误减少了60%:英语↔法语,英语↔西班牙语和英语↔中文。其他实验表明,最终翻译系统的质量已接近普通译员的质量。
2.相关工作
统计机器翻译(SMT)几十年来一直是主要的翻译方法。SMT的实现通常是基于短语的机器翻译系统(PBMT),该系统翻译长度不同的单词或短语序列。
甚至在神经机器翻译问世之前,神经网络已被用作SMT系统中的组件,并取得了一些成功。 也许最引人注目的尝试之一是使用联合语言模型来学习短语表示,当与基于短语的翻译结合使用时,这产生了很大的改进。但是,这种方法仍然以基于短语的翻译系统为核心,因此继承了它们的缺点。其他所提出的学习短语表示或使用神经网络学习端到端翻译的方法提供了较好的结果,但与基于短语的系统相比,最终的总体准确性较差。
过去的研究人员已经尝试了用于机器翻译的端到端学习的概念,但收效甚微。在该领域的开创性论文[41,2]之后,NMT的翻译质量已逐渐接近传统研究基准的基于短语的翻译系统的水平。可能在[31]中描述了超过基于短语的翻译的首次成功尝试。与最新的基于词组的系统相比,该系统在WMT’14英译法上实现了0.5 BLEU的改进。
从那以后,已经提出了许多新技术来进一步改善NMT:使用注意力机制处理稀有词,为翻译覆盖率建模的机制,多任务和半监督训练以合并更多数据,字符解码器,字符编码器,处理稀有词输出的子词单元,不同种类的注意机制和句子级最小化损失。尽管这些系统的翻译准确性令人鼓舞,但仍缺乏与大规模,基于短语的翻译系统的系统性比较。
3.模型结构
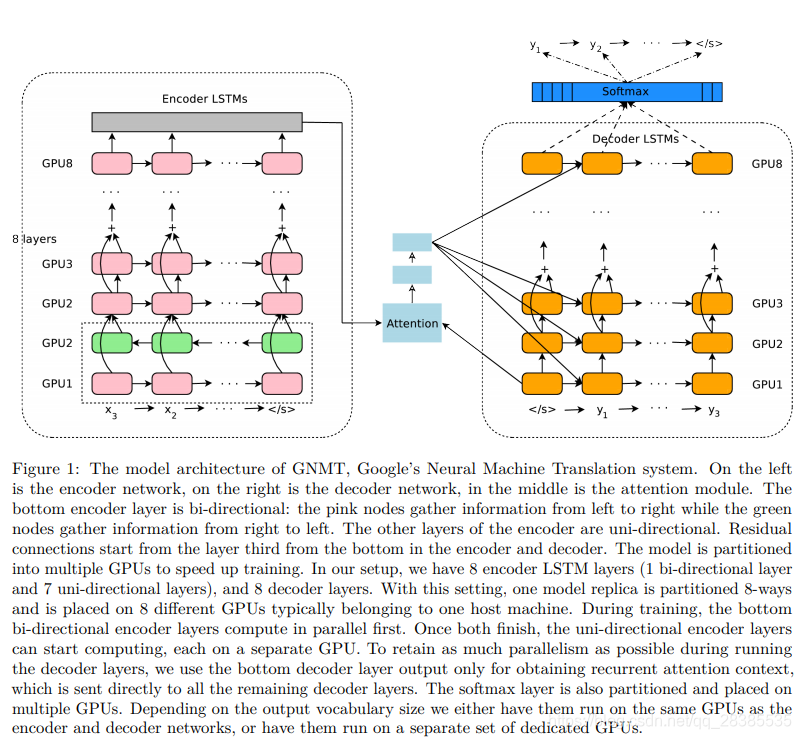
我们的模型(见图1)遵循传统的序列到序列学习框架,并引入注意力机制。它具有三个组成部分:a.编码器网络,b.解码器网络和c.注意力网络。编码器将源语句转换为向量列表,每个输入符号输出一个向量。 给定此向量列表,解码器一次生成一个符号,直到生成特殊的句子结束符号(EOS)。 编码器和解码器通过注意力模块连接,该模块允许解码器在解码过程中专注于源语句的不同区域。
对于所使用的符号,我们使用粗体小写字母表示向量(例如
v
,
o
i
\pmb v,\pmb o_i
vvv,oooi),使用粗体大写字母表示矩阵(例如
U
,
W
\pmb U,\pmb W
UUU,WWW),使用草书大写字母表示集合(例如
V
,
T
\mathcal V,\mathcal T
V,T),使用大写字母表示表示序列(例如
X
,
Y
X,Y
X,Y),小写字母表示序列中的各个符号(例如
x
1
,
x
2
x_1,x_2
x1,x2)。
令
(
X
,
Y
)
(X,Y)
(X,Y)为源句和目标句对。 令
X
=
x
1
,
x
2
,
x
3
,
.
.
.
,
x
M
X=x_1,x_2,x_3,...,x_M
X=x1,x2,x3,...,xM是源句子中
M
M
M个符号的序列,而
Y
=
y
1
,
y
2
,
y
3
,
.
.
.
,
y
N
Y=y_1,y_2,y_3,...,y_N
Y=y1,y2,y3,...,yN是目标句子中
N
N
N个符号的序列。编码器只是以下形式的函数:
x
1
,
x
2
,
…
,
x
M
=
E
n
c
o
d
e
r
R
N
N
(
x
1
,
x
2
,
x
3
,
…
,
x
M
)
(1)
\pmb x_1,\pmb x_2,\dots,\pmb x_M=EncoderRNN(x_1,x_2,x_3,\dots,x_M)\tag{1}
xxx1,xxx2,…,xxxM=EncoderRNN(x1,x2,x3,…,xM)(1)
在此等式中,
x
1
,
x
2
,
…
,
x
M
\pmb x_1,\pmb x_2,\dots,\pmb x_M
xxx1,xxx2,…,xxxM是固定向量维度的列表。列表中的成员数与源句子中的符号数相同(在此示例中为
M
M
M)。使用链式规则,可以将序列
P
(
Y
∣
X
)
P(Y|X)
P(Y∣X)的条件概率分解为:
P
(
Y
∣
X
)
=
P
(
Y
∣
x
1
,
x
2
,
…
,
x
M
)
=
∏
i
=
1
N
P
(
y
i
∣
y
0
,
y
1
,
y
2
,
.
.
.
,
y
i
−
1
;
x
1
,
x
2
,
…
,
x
M
)
(2)
P(Y|X)=P(Y|\pmb x_1,\pmb x_2,\dots,\pmb x_M)=\prod^N_{i=1}P(y_i|y_0,y_1,y_2,...,y_{i-1};\pmb x_1,\pmb x_2,\dots,\pmb x_M)\tag{2}
P(Y∣X)=P(Y∣xxx1,xxx2,…,xxxM)=i=1∏NP(yi∣y0,y1,y2,...,yi−1;xxx1,xxx2,…,xxxM)(2)
其中
y
0
y_0
y0是用于表示“句子开头”的特殊符号,位于每个目标句子之前。
在推理过程中,我们计算到目前为止给定源句编码和已解码目标序列的下一个符号的概率:
P
(
y
i
∣
y
0
,
y
1
,
y
2
,
.
.
.
,
y
i
−
1
;
x
1
,
x
2
,
…
,
x
M
)
(3)
P(y_i|y_0,y_1,y_2,...,y_{i-1};\pmb x_1,\pmb x_2,\dots,\pmb x_M)\tag{3}
P(yi∣y0,y1,y2,...,yi−1;xxx1,xxx2,…,xxxM)(3)
我们的解码器实现为RNN网络和softmax层的组合。解码器RNN网络为要预测的下一个符号生成隐藏状态
y
i
\pmb y_i
yyyi,然后将其通过softmax层以在候选输出符号上生成概率分布。
在我们的实验中,我们发现,要使NMT系统达到良好的精度,编码器和解码器RNN都必须足够深,以捕获源语言和目标语言中的细微不规则性。这种观测结果与以前的相似,即深LSTM明显优于浅LSTM。在这项工作中,每个额外的层将困惑度降低了近10%。与[31]相似,我们对编码器RNN和解码器RNN都使用了深度堆叠的长短期记忆(LSTM)网络。
我们的注意力模块类似于[2]。更具体地说,令
y
i
−
1
\pmb y_{i-1}
yyyi−1为上一时刻的解码器-RNN输出。当前时刻的注意上下文
a
i
\pmb a_i
aaai根据以下公式计算:
s
t
=
A
t
t
e
n
t
i
o
n
F
u
n
c
t
i
o
n
(
y
i
−
1
,
x
t
)
∀
t
,
1
≤
t
≤
M
s_t=AttentionFunction(\pmb y_{i-1},\pmb x_t)\quad \forall t,\quad 1\le t \le M
st=AttentionFunction(yyyi−1,xxxt)∀t,1≤t≤M
p
t
=
e
x
p
(
s
t
)
/
∑
t
=
1
M
e
x
p
(
s
t
)
∀
t
,
1
≤
t
≤
M
(4)
p_t=exp(s_t)/\sum^M_{t=1}exp(s_t)\quad \forall t,\quad 1\le t \le M \tag{4}
pt=exp(st)/t=1∑Mexp(st)∀t,1≤t≤M(4)
a
i
=
∑
t
=
1
M
p
t
x
t
\pmb a_i=\sum^M_{t=1}p_t\pmb x_t
aaai=t=1∑Mptxxxt
其中,我们实现的AttentionFunction是具有一个隐藏层的前馈网络。
3.1 残差链接
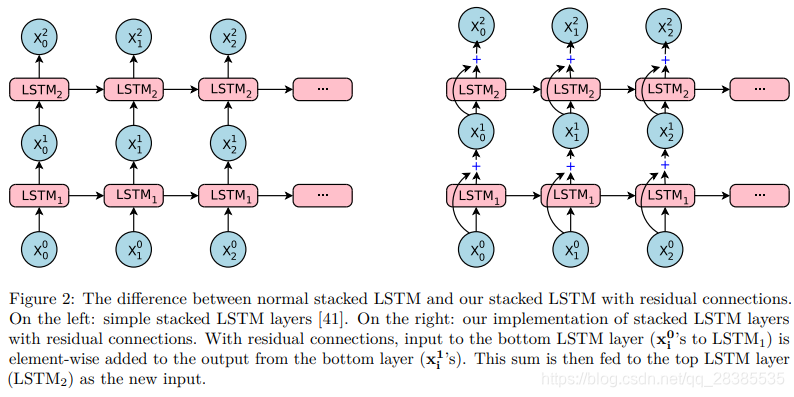
如上所述,与浅层模型相比,较深的LSTM通常会提供更高的精度。然而,简单地堆叠更多的LSTM层只能在一定数量的层上起作用,超过这些层,网络变得太慢且难以训练,这可能是由于梯度爆炸和梯度消失问题引起的。根据我们在大规模翻译任务方面的经验,简单的堆叠LSTM层可以很好地工作到4层,极限只有6层,而超过8层则会导致非常差的性能。
出于对中间层的输出和目标之间的差异进行建模的想法的推动,这种想法在过去的论文中已显示对许多任务都适用,我们在堆栈中的LSTM层之间引入了残差连接(请参见图2)。更具体地,令
L
S
T
M
i
LSTM_i
LSTMi和
L
S
T
M
i
+
1
LSTM_{i+1}
LSTMi+1为堆栈中的第
i
i
i个和第
i
+
1
i+1
i+1个LSTM层,其参数分别为
W
i
\pmb W_i
WWWi和
W
i
+
1
\pmb W_{i+1}
WWWi+1。在第
t
t
t步,对于没有残留连接的堆叠LSTM,我们有:
c
t
i
,
m
t
i
=
L
S
T
M
i
(
c
t
−
1
i
,
m
t
−
1
i
,
x
t
i
−
1
;
W
i
)
\pmb c^i_t,\pmb m^i_t=LSTM_i(\pmb c^i_{t-1}, \pmb m^i_{t-1},\pmb x^{i-1}_t;\pmb W^i)
cccti,mmmti=LSTMi(ccct−1i,mmmt−1i,xxxti−1;WWWi)
x
t
i
=
m
t
i
(5)
\pmb x^i_t=\pmb m^i_t\tag{5}
xxxti=mmmti(5)
c
t
i
+
1
,
m
t
i
+
1
=
L
S
T
M
i
+
1
(
c
t
−
1
i
+
1
,
m
t
−
1
i
+
1
,
x
t
i
;
W
i
+
1
)
\pmb c^{i+1}_t,\pmb m^{i+1}_t=LSTM_{i+1}(\pmb c^{i+1}_{t-1}, \pmb m^{i+1}_{t-1},\pmb x^{i}_t;\pmb W^{i+1})
cccti+1,mmmti+1=LSTMi+1(ccct−1i+1,mmmt−1i+1,xxxti;WWWi+1)
其中
x
t
i
−
1
x^{i-1}_t
xti−1是在时刻
t
t
t处
L
S
T
M
i
LSTM_i
LSTMi的输入,而
m
t
i
m^i_t
mti和
c
t
i
c^i_t
cti分别是在时刻
t
t
t处
L
S
T
M
i
LSTM_i
LSTMi的隐藏状态和记忆状态。
在
L
S
T
M
i
LSTM_i
LSTMi和
L
S
T
M
i
+
1
LSTM_{i+1}
LSTMi+1之间存在残差链接的情况下,上述公式变为:
c
t
i
,
m
t
i
=
L
S
T
M
i
(
c
t
−
1
i
,
m
t
−
1
i
,
x
t
i
−
1
;
W
i
)
\pmb c^i_t,\pmb m^i_t=LSTM_i(\pmb c^i_{t-1}, \pmb m^i_{t-1},\pmb x^{i-1}_t;\pmb W^i)
cccti,mmmti=LSTMi(ccct−1i,mmmt−1i,xxxti−1;WWWi)
x
t
i
=
m
t
i
+
x
t
i
−
1
(6)
\pmb x^i_t=\pmb m^i_t+\pmb x^{i-1}_t\tag{6}
xxxti=mmmti+xxxti−1(6)
c
t
i
+
1
,
m
t
i
+
1
=
L
S
T
M
i
+
1
(
c
t
−
1
i
+
1
,
m
t
−
1
i
+
1
,
x
t
i
;
W
i
+
1
)
\pmb c^{i+1}_t,\pmb m^{i+1}_t=LSTM_{i+1}(\pmb c^{i+1}_{t-1}, \pmb m^{i+1}_{t-1},\pmb x^{i}_t;\pmb W^{i+1})
cccti+1,mmmti+1=LSTMi+1(ccct−1i+1,mmmt−1i+1,xxxti;WWWi+1)
残留连接极大地改善了反向梯度传播,这使我们能够训练非常深的编码器和解码器网络。在我们的大多数实验中,我们使用8个LSTM层作为编码器和解码器,尽管残差连接可以使我们训练更深的网络(类似于[45]中观察到的网络)。
3.2 对于第一层的双向编码器
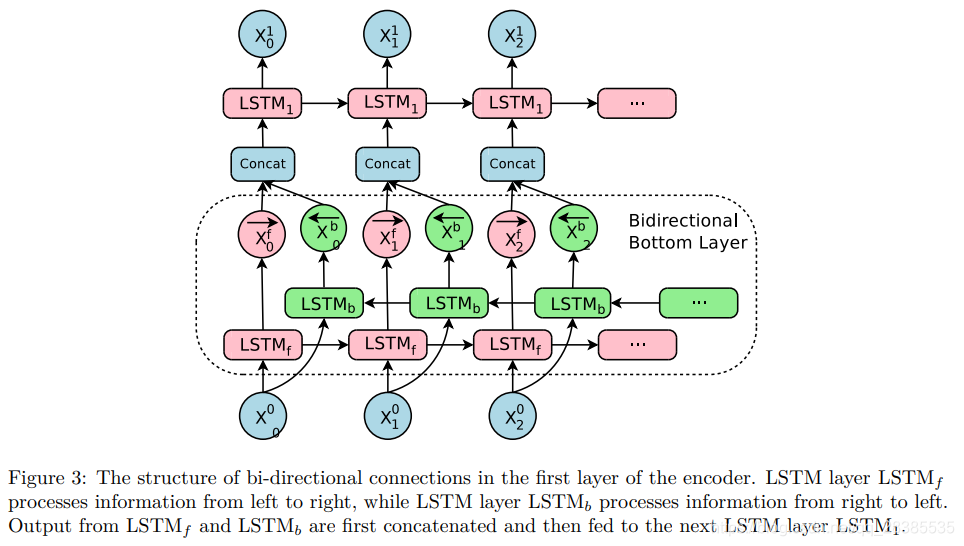
对于翻译系统,在输出端翻译某些单词所需的信息可以出现在源端的任何位置。通常,源端的信息是类似于目标端从左到右的,但是取决于语言对,一个具体输出单词的信息能够被分配甚至拆分到输入端的某个区域。
为了能在编码器网络的每个位置都获得最佳的上下文,对编码器使用双向RNN是有意义的,在[2]中也使用了双向RNN。另外,为了在计算过程中最大程度地实现并行化(将在第3.3节中进行详细讨论),双向连接仅用于底部编码器层-所有其他编码器层均为单向的。 图3说明了我们在底部编码器层使用双向LSTM的情况。
L
S
T
M
f
LSTM_f
LSTMf层从左到右处理源语句,
L
S
T
M
b
LSTM_b
LSTMb层则是从右到左处理。来自
L
S
T
M
f
(
x
→
t
f
)
LSTM_f(\overrightarrow{\pmb x}^f_t)
LSTMf(xxxtf)和
L
S
T
M
b
(
x
←
t
b
)
LSTM_b(\overleftarrow{\pmb x}^b_t)
LSTMb(xxxtb)的输出首先需要串联起来,然后才馈送到下一层
L
S
T
M
1
LSTM_1
LSTM1。
3.3 模型并行
由于模型的复杂性,我们同时使用模型并行和数据并行来加快训练速度。
(1)数据并行
数据并行很简单:我们使用Downpour SGD算法同时训练
n
n
n个模型副本。
n
n
n个副本都共享一个模型参数,每个副本使用Adam和SGD算法的组合异步更新参数。在我们的实验中,
n
n
n通常约为10。每个副本一次处理
m
m
m个句子对的mini-batch,在我们的实验中通常为
128
128
128。
(2)模型并行
除数据并行外,模型并行还用于提高每个副本上梯度计算的速度。 编码器和解码器网络沿深度方向划分,并放置在多个GPU上,从而有效地在不同GPU上运行每一层。由于除第一个编码器层以外的所有层都是单向的,因此第
i
+
1
i+1
i+1层可以在第
i
i
i层完全完成之前开始其计算,从而提高了训练速度。softmax层也被分区,每个分区负责输出词汇表中符号的子集。图1显示了如何完成分区的更多细节。
模型并行对我们可以使用的模型架构施加了某些约束。例如,我们不能为所有编码器层都设置双向LSTM层,因为这样做会降低后续层之间的并行度,因为每一层都必须等待,直到前一层的正反两个方向都完成为止。这将有效地限制我们仅并行使用2个GPU(一个用于前向,一个用于后向)。对于模型的注意力部分,我们选择将底部解码器输出与顶部编码器输出对齐,以在运行解码器网络时最大程度地提高并行度。如果我们将顶部解码器层与顶部编码器层对齐,我们将消除解码器网络中的所有并行性,并且不会受益于使用多个GPU进行解码。
4.分段方法
即使翻译从根本上来说是一个开放的词汇问题(名称,数字,日期等),但是神经机器翻译模型也经常使用固定的单词词汇进行操作。解决未登录(OOV)单词的方法有两大类。一种方法是根据注意力模型,使用外部对齐模型,简单地将稀有词从源复制到目标(因为最稀有词是名称或数字,而正确的翻译只是副本)。甚至使用更复杂的专用指向网络。另一类广泛使用的方法是使用子词单元,例如字符,词/字符的混合或更好的子词。
4.1 wordpiece
我们最成功的方法属于第二类(子词单元),并且我们采用最初为解决Google语音识别系统的日语/韩语分割问题而开发的wordpiece模型(WPM)实现。这种方法完全由数据驱动,并保证为任何可能的字符序列生成确定性分段。它类似于[38]中处理神经机器翻译中稀有词的方法。
为了处理任意单词,我们首先根据训练好的wordpiece模型将单词分解为wordpiece。在训练模型之前添加特殊的单词边界符号,以便可以从单词序列中恢复原始单词序列而不会产生歧义。在解码时,模型首先生成一个wordpiece序列,然后将其转换为相应的word序列。
这是一个word序列和相应的wordpiece序列的示例:
- Word: Jet makers feud over seat width with big orders at stake
- wordpieces: _J et _makers _fe ud _over _seat _width _with _big _orders _at _stak
在以上示例中,单词“Jet”被分解为两个单词“_J”和“et”,单词“feud”被分解为两个单词“_fe”和“ud”。其他单词保持为单个单词。“ _”是添加的特殊字符,用于标记单词的开头。
给定一个不断发展的单词定义,使用数据驱动的方法来生成wordpiece模型,以使训练数据的语言模型概率最大化。给定一个训练语料和多个所需的字符D,最优化问题是选择D个单词,使得当根据所选wordpiece模型进行分段时,所得语料的单词数最小。我们针对此优化问题的贪婪算法类似于[38],并在[35]中进行了更详细的描述。与[35]中使用的原始实现相比,我们仅在单词的开头而不是两端使用特殊符号。我们还根据数据将基本字符的数量减少到一个可控的数量(西方语言大约为500,亚洲语言更多),并将其余映射到一个特殊的未知字符,以避免用非常稀有的字符污染给定的单词词汇。我们发现,使用8k到32k个字词的总词汇量可以在我们尝试过的所有语言对之间达到良好的准确性(BLEU分数)和并或得快速的解码速度。
如上所述,在翻译中,将稀有实体名称或数字直接从源复制到目标通常很有意义。为了促进这种直接复制,我们始终对源语言和目标语言都使用共享的Wordpieces模型。使用这种方法,可以确保以完全相同的方式对源句子和目标句子中的相同字符串进行分段,从而使系统更轻松地学习复制这些字符。
Wordpieces在字符的灵活性和单词的效率之间取得了平衡。我们还发现,使用wordpieces时,我们的模型在BLEU上获得了更好的总体评分-可能是由于我们的模型现在可以有效地处理本质上无限的词汇,而无需求助于字符。后者会使输入和输出序列的平均长度更长,因此需要更多的计算。
4.2 词/字符的混合
我们使用的第二种方法是词/字符的混合模型。就像在单词模型中一样,我们保留固定大小的单词词汇。但是,与将OOV单词折叠为单个UNK符号的常规单词模型不同,我们将OOV单词转换为其组成字符的序列。字符前面带有特殊的前缀,其中1)显示字符在单词中的位置,2)在词汇字符中将它们与普通字符区分开。有三个前缀:,和,分别表示单词的开头,单词的中间和单词的结尾。例如,假设词汇中没有单词Miki。它将被预处理为一系列特殊标记: M i k i。该过程在源句子和目标句子上都进行实现。在解码期间,输出还可能包含特殊字符序列。使用前缀,在将字符反转为原始单词时很简单。
5.训练准则
给定包含N个输入-输出序列对的并行文本数据集,表示为
D
≡
{
(
X
(
i
)
,
Y
∗
(
i
)
)
}
i
=
1
N
\mathcal D≡\{(X^{(i)},Y^{∗(i)})\}^N_{i=1}
D≡{(X(i),Y∗(i))}i=1N,标准的最大似然训练旨在给定输入的情况下,最大化真值输出的对数概率,
O
M
L
(
θ
)
=
∑
i
=
1
N
l
o
g
P
θ
(
Y
∗
(
i
)
∣
X
(
i
)
)
.
(7)
\mathcal O_{ML}(\theta)=\sum^N_{i=1}log~P_{\theta}(Y^{∗(i)}|X^{(i)}).\tag{7}
OML(θ)=i=1∑Nlog Pθ(Y∗(i)∣X(i)).(7)
这个目标函数的主要问题是它不能反映翻译中BLEU分数所衡量的任务奖赏函数。此外,该目标函数并不明确鼓励在不正确的输出序列之间进行排名,即在模型中,具有较高BLEU分数的输出仍应在模型中获得较高的概率,但是在训练期间从未观察到不正确的输出。换句话说,仅使用最大似然训练,该模型将不会学习到解码过程中产生错误的鲁棒性,因为它们从未被观察到,这在训练和测试过程之间是相当不匹配的。
最近的几篇论文考虑了将任务奖赏纳入神经序列到序列模型优化的不同方法。在这项工作中,我们还尝试完善针对最大似然目标进行预训练的模型,以直接针对任务奖赏进行优化。我们表明,即使在大型数据集上,使用任务奖赏对最新的最大似然模型进行细化也可以显着改善结果。
我们考虑使用期望奖赏目标函数对模型进行细化,可以表示为:
O
R
L
(
θ
)
=
∑
i
=
1
N
∑
Y
∈
Y
l
o
g
P
θ
(
Y
∣
X
(
i
)
)
r
(
Y
,
Y
∗
(
i
)
)
.
(8)
\mathcal O_{RL}(\theta)=\sum^N_{i=1}\sum_{Y\in{\mathcal Y }}log~P_{\theta}(Y|X^{(i)})r(Y,Y^{∗(i)}).\tag{8}
ORL(θ)=i=1∑NY∈Y∑log Pθ(Y∣X(i))r(Y,Y∗(i)).(8)
在这里,
r
(
Y
,
Y
∗
(
i
)
)
r(Y,Y^{∗(i)})
r(Y,Y∗(i))表示句子分数,并且我们正在计算所有输出句子
Y
Y
Y的期望值,直到一定长度。
当用于单句时,BLEU评分具有一些不良的特性,因为它被设计为语料量度。因此,我们在RL实验中使用的分数略有不同,我们称之为“ GLEU分数”。对于GLEU分数,我们在输出和目标序列中记录1、2、3或4个字符的所有子序列(n-gram)。 然后,我们计算召回率(即目标序列中匹配的n-gram数量与总n-gram数量的比率)以及精度(即匹配的n-gram数量的比率)。 那么GLEU分数就是召回率和精确度的最小值。GLEU分数的范围始终在0(不匹配)和1(所有匹配)之间,并且在切换输出和目标时对称。根据我们的实验,GLEU分数在语料库水平上与BLEU指标具有很好的相关性,但是对于我们的每句话奖赏函数没有缺点。
按照强化学习的惯例,我们从等式8中的
r
(
Y
,
Y
∗
(
i
)
)
r(Y,Y^{∗(i)})
r(Y,Y∗(i))中减去平均奖赏。该平均值估计为独立于分布
P
θ
(
Y
∣
X
(
i
)
)
P_θ(Y|X^{(i)})
Pθ(Y∣X(i))得到的
m
m
m个序列的样本平均值。在我们的实现中,
m
m
m设置为15。为进一步稳定训练,我们优化ML(方程7)和RL(方程8)目标的线性组合,如下所示:
O
M
i
x
e
d
(
θ
)
=
α
∗
O
M
L
(
θ
)
+
O
R
L
(
θ
)
(9)
\mathcal O_{Mixed}(\theta)=\alpha ∗ O_{ML}(\theta)+\mathcal O_{RL}(\theta)\tag{9}
OMixed(θ)=α∗OML(θ)+ORL(θ)(9)
在我们的实现中,α通常设置为0.017。
在我们的设置中,我们首先使用最大似然目标(等式7)训练模型,直到收敛为止。然后,我们使用混合的最大似然和期望奖赏函数(等式9)细化此模型,直到开发集的BLEU分数不再提高。其中第二步是可选的。
6.量化模型和量化推理
将我们的神经机器翻译模型部署到我们的交互式产品翻译服务中的主要挑战之一是推理上的计算量很大,难以进行低延迟的翻译,并且大量部署的计算量很大。使用降低精度的方法进行量化推理是一种可以显着降低这些模型推理成本的技术,通常可以在同一计算设备上提高效率。例如,在[43]中,证明了在ILSVRC-12基准上,在保证分类精度损失最小的情况下,卷积神经网络模型可以以4-6的倍数加速。在[27]中,证明了神经网络模型权重只能量化为-1、0和+1这三个状态。
然而,许多先前的研究[19、20、43、27]大多集中在具有相对较少层的CNN模型上。具有长序列的深度LSTM提出了一个新的挑战,因为在许多次的循环计算之后或经过深度LSTM堆栈后,量化误差会显着放大。
在本节中,我们介绍了使用量化算法加快推理速度的方法。我们的解决方案是针对Google提供的硬件选项量身定制的。为了减少量化误差,在训练过程中保证对模型输出的影响最小的情况下,向我们的模型添加了其他约束,以便可以量化该模型。也就是说,一旦使用这些附加约束训练了模型,就可以随后对其进行量化而不会损失翻译质量。我们的实验结果表明,这些附加约束不会影响模型收敛能力,也不会影响模型的质量。
根据等式6可知,在带有残差连接的LSTM堆栈中,有两个累加器:沿时间轴的
c
t
i
\pmb c^i_t
cccti和沿深度轴的
x
t
i
\pmb x^i_t
xxxti。从理论上讲,这两个累加器都是不受限制的,但实际上,我们注意到它们的值仍然很小。对于量化推理,我们明确地将这些累加器的值限制在
[
−
δ
,
δ
]
[-δ,δ]
[−δ,δ]以内,以确保可以在以后特定范围内进行量化。具有残差连接的LSTM堆栈的正向计算被修改为以下内容:
c
t
′
i
,
m
t
i
=
L
S
T
M
i
(
c
t
−
1
i
,
m
t
−
1
i
,
x
t
i
−
1
;
W
i
)
\pmb c'^i_t,\pmb m^i_t=LSTM_i(\pmb c^i_{t-1},\pmb m^i_{t-1},\pmb x^{i-1}_t;\pmb W^i)
ccct′i,mmmti=LSTMi(ccct−1i,mmmt−1i,xxxti−1;WWWi)
c
t
i
=
m
a
x
(
−
σ
,
m
i
n
(
σ
,
c
t
′
i
)
)
\pmb c^i_t=max(-\sigma, min(\sigma, \pmb c'^i_t))
cccti=max(−σ,min(σ,ccct′i))
x
t
′
i
=
m
t
i
+
x
t
i
−
1
(10)
\pmb x'^i_t=\pmb m^i_t+\pmb x^{i-1}_t \tag{10}
xxxt′i=mmmti+xxxti−1(10)
x
t
i
=
m
a
x
(
−
σ
,
m
i
n
(
σ
,
x
t
′
i
)
)
\pmb x^i_t=max(-\sigma, min(\sigma, \pmb x'^i_t))
xxxti=max(−σ,min(σ,xxxt′i))
c
t
′
i
+
1
,
m
t
i
+
1
=
L
S
T
M
i
+
1
(
c
t
−
1
i
+
1
,
m
t
−
1
i
+
1
,
x
t
i
;
W
i
+
1
)
\pmb c'^{i+1}_t,\pmb m^{i+1}_t=LSTM_{i+1}(\pmb c^{i+1}_{t-1},\pmb m^{i+1}_{t-1},\pmb x^{i}_t;\pmb W^{i+1})
ccct′i+1,mmmti+1=LSTMi+1(ccct−1i+1,mmmt−1i+1,xxxti;WWWi+1)
c
t
i
+
1
=
m
a
x
(
−
σ
,
m
i
n
(
σ
,
c
t
′
i
+
1
)
)
\pmb c^{i+1}_t=max(-\sigma, min(\sigma, \pmb c'^{i+1}_t))
cccti+1=max(−σ,min(σ,ccct′i+1))
让我们在等式10中扩展
L
S
T
M
i
LSTM_i
LSTMi以展示内部门控逻辑。为简便起见,我们删除所有上标
i
i
i。
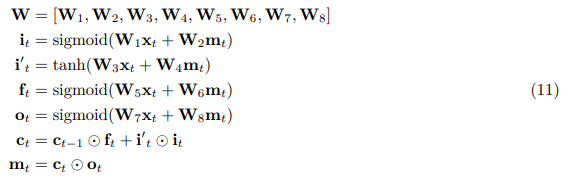
在进行量化推理时,我们将等式10和11中的所有浮点运算都替换为具有8位或16位分辨率的定点整数运算。上面的权重矩阵
W
\pmb W
WWW使用8位整数矩阵
W
Q
\pmb{WQ}
WQWQWQ和浮点向量
s
\pmb s
sss表示,如下所示:
s
i
=
n
a
x
(
a
b
s
(
W
[
i
,
:
]
)
)
W
Q
[
i
,
j
]
=
r
o
u
n
d
(
W
[
i
,
j
]
/
s
i
×
127.0
)
(12)
\pmb s_i=nax(abs(\pmb W[i,:]))\\ \pmb{WQ}[i,j]=round(\pmb W[i,j]/\pmb s_i\times 127.0)\tag{12}
sssi=nax(abs(WWW[i,:]))WQWQWQ[i,j]=round(WWW[i,j]/sssi×127.0)(12)
所有累加器值(
c
t
i
\pmb c^i_t
cccti和
x
t
i
x^i_t
xti)都使用范围
[
−
δ
,
δ
]
[-δ,δ]
[−δ,δ]内的16位整数表示。公式11中的所有矩阵乘法(例如,
W
1
x
t
\pmb W_1\pmb x_t
WWW1xxxt,
W
2
m
t
\pmb W_2\pmb m_t
WWW2mmmt等)是使用累加到较大累加器中的8位整数乘法完成的。所有其他操作(包括所有激活(Sigmoid,tanh)和逐元素操作(
⊙
\odot
⊙,
+
+
+))均使用16位整数操作完成。
现在,我们将注意力转向对数线性softmax层。在训练期间,给定解码器RNN网络输出
y
t
\pmb y_t
yyyt,我们如下所示计算所有候选输出符号上的概率矢量
p
t
\pmb p_t
pppt:
v
t
=
W
s
∗
y
t
v
t
′
=
m
a
x
(
−
γ
,
m
i
n
(
γ
,
v
t
)
)
p
t
=
s
o
f
t
m
a
x
(
v
t
′
)
(13)
\pmb v_t=\pmb W_s*\pmb y_t\\ \pmb v'_t=max(-\gamma, min(\gamma, \pmb v_t))\\ \pmb p_t=softmax(\pmb v'_t)\tag{13}
vvvt=WWWs∗yyytvvvt′=max(−γ,min(γ,vvvt))pppt=softmax(vvvt′)(13)
在等式13中,
W
s
\pmb W_s
WWWs是线性层的权重矩阵,其具有与目标词汇表中的符号数相同的行数,并且每一行对应于一个唯一的目标符号。
v
\pmb v
vvv表示原始logit,将其首先裁剪到
−
γ
-γ
−γ和
γ
γ
γ之间,然后归一化为概率向量
p
\pmb p
ppp。由于我们应用于解码器RNN的量化方案,输入
y
t
\pmb y_t
yyyt保证在
−
δ
-δ
−δ和
δ
δ
δ之间。logit
v
\pmb v
vvv的限幅范围
γ
γ
γ凭经验确定,在本例中为25。在量化推理中,权重矩阵
W
s
\pmb W_s
WWWs量化为8位,如公式12所示,矩阵乘法使用8位算术。在推理过程中,不会对softmax函数和注意力模型内的计算进行量化。
值得强调的是,在训练模型期间,我们使用了全精度浮点数。我们在训练期间添加到模型的唯一约束是将RNN累加器值裁剪为
[
−
δ
,
δ
]
[-δ,δ]
[−δ,δ]和softmax logits裁剪为
[
−
γ
,
γ
]
[-γ,γ]
[−γ,γ]。
γ
γ
γ固定为25.0,而
δ
δ
δ的值从训练开始时从
δ
=
8.0
δ= 8.0
δ=8.0的大范围逐渐退火,直到训练结束时达到
δ
=
1.0
δ= 1.0
δ=1.0。在推理时,
δ
δ
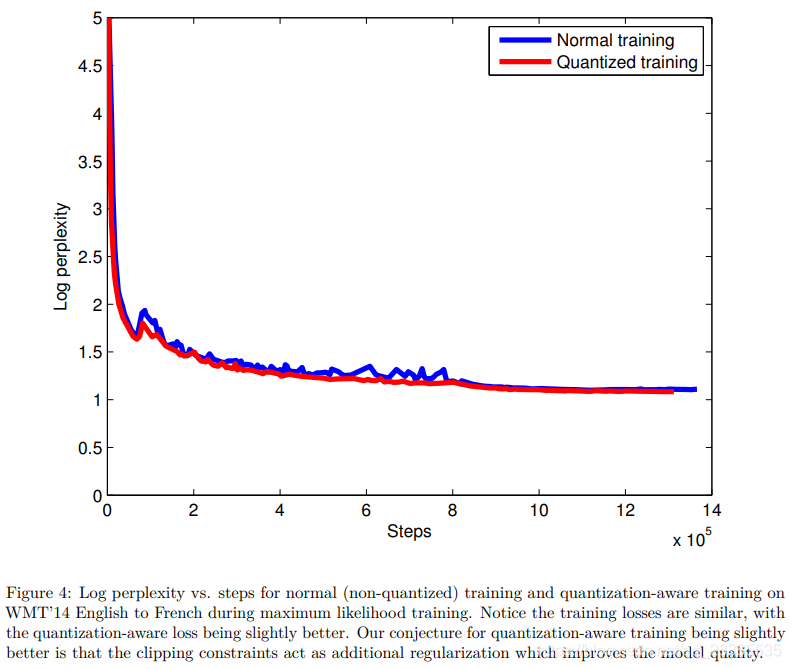
δ固定为1.0。这些附加约束不会降低模型收敛性,也不会降低模型收敛后的解码质量。在图4中,我们比较了WMT’14英法文中不受约束的模型(蓝色曲线)和受约束的模型(红色曲线)的损失与迭代步数的关系。我们可以看到,约束模型的损失要好一些,这可能是由于这些约束发挥的正则化作用。
我们的解决方案在效率和准确性之间取得了很好的平衡。由于使用8位整数运算完成了计算量大的运算(矩阵乘法),因此我们的量化推理非常有效。而且,由于对错误敏感的累加器值是使用16位整数存储的,因此我们的解决方案非常准确,并且对量化误差具有鲁棒性。

在表1中,我们比较了在CPU,GPU和Google的Tensor处理单元(TPU)上解码WMT’14英法开发集(newstest2012和newstest2013测试集的级联,总共6003个句子)时的推理速度和质量。此处用于比较的模型仅在ML目标函数上使用量化约束进行训练(即,不进行基于强化学习的模型优化)。在CPU和GPU上对模型进行解码时,不会对其进行量化,并且所有操作均使用全精度浮点数完成。当在TPU上对其进行解码时,某些操作(如词嵌入查找和注意力模块)仍保留在CPU上,所有其他量化操作均被装载到TPU。在所有情况下,解码都是在一台具有两个Intel Haswell CPU的计算机上完成的,该计算机总共包含88个CPU内核(超线程)。该机器配备了用于GPU实验的NVIDIA GPU(Tesla k80)或用于TPU实验的单个Google TPU。
表1显示,在TPU上使用降低的精度算法进行解码时,对数困惑的损失非常小,仅为0.0072,而BLEU则完全没有损失。 该结果与以前的工作报告相符,即对卷积神经网络模型进行量化可以保留大多数模型质量。
表1还显示,在CPU上解码我们的模型实际上比在GPU上快2.3倍。首先,我们的双CPU主机在理论上提供了最高的FLOP性能,是GPU的三分之二。其次,集束搜索算法会迫使解码器在每个解码步骤中在主机和GPU之间进行大量的数据传输。因此,我们当前的解码器实现无法充分利用GPU在理论上可以在推理过程中提供的计算能力。
最后,表1显示,在TPU上的解码比在CPU上的解码快3.4倍,这表明TPU上的量化算法比CPU或GPU都快得多。
除非另有说明,否则我们始终在实验中训练和评估量化模型。因为从质量角度来看,在CPU上解码的模型与在TPU上解码的模型之间几乎没有区别,所以我们在训练和实验期间使用CPU进行解码以进行模型评估,并使用TPU来服务产品。
7.解码器
在给定已训练模型的情况下,我们在解码过程中使用集束搜索来找到最高得分函数
s
(
Y
,
X
)
s(Y,X)
s(Y,X)对应的序列
Y
Y
Y。我们对基于最大概率的集束搜索算法进行了两个重要的改进:覆盖罚分和长度归一化。通过长度归一化,我们旨在说明必须比较不同长度的假设这一事实。如果没有某种形式的长度归一化,则常规集束搜索将平均倾向于较短的结果,而不是较长的结果,这是因为在每个步骤中都添加了对数概率,从而为较长的句子生成了较低(较负数)的分数。我们首先尝试简单地除以长度以进行归一化。然后,我们通过除以
l
e
n
g
t
h
α
length^α
lengthα来改进原始启发式算法,其中
0
<
α
<
1
0<α<1
0<α<1,其中α在开发集上得到了优化(通常发现
α
∈
[
0.6
−
0.7
]
α∈[0.6-0.7]
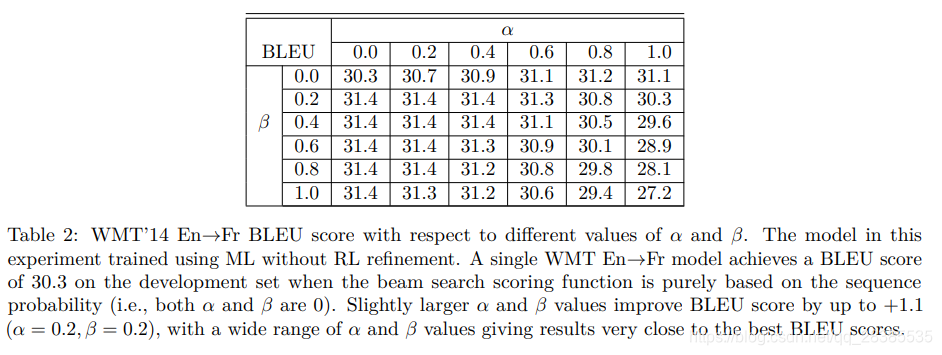
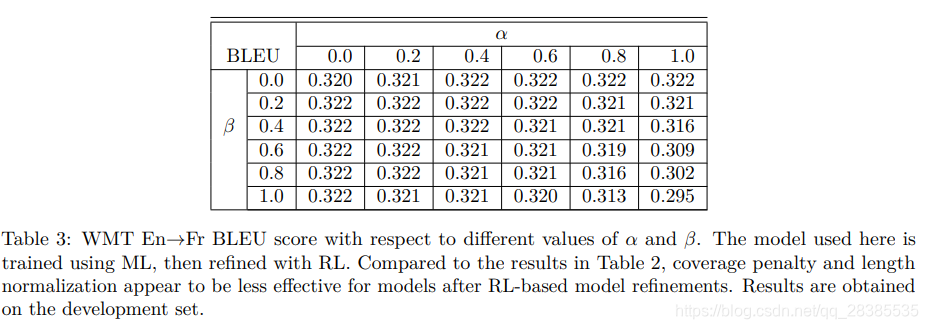
α∈[0.6−0.7]是最佳的)。最终,我们在下面设计了经验上更好的评分函数,该函数还包括覆盖率惩罚,以便根据注意力模块支持完全覆盖源语句的翻译。
更具体地说,我们用来对候选翻译进行排名的评分函数
s
(
Y
,
X
)
s(Y,X)
s(Y,X)定义如下:
s
(
Y
,
X
)
=
l
o
g
(
P
(
Y
∣
X
)
)
/
l
p
(
Y
)
+
c
p
(
X
;
Y
)
s(Y,X)=log(P(Y|X))/lp(Y)+cp(X;Y)
s(Y,X)=log(P(Y∣X))/lp(Y)+cp(X;Y)
l
p
(
Y
)
=
(
5
+
∣
Y
∣
)
α
(
5
+
1
)
α
(14)
lp(Y)=\frac{(5+|Y|)^\alpha}{(5+1)^\alpha}\tag{14}
lp(Y)=(5+1)α(5+∣Y∣)α(14)
c
p
(
X
;
Y
)
=
β
∗
∑
i
=
1
∣
X
∣
l
o
g
(
m
i
n
(
∑
j
=
1
∣
Y
∣
p
i
,
j
,
1.0
)
)
,
cp(X;Y)=\beta * \sum^{|X|}_{i=1}log(min(\sum^{|Y|}_{j=1}p_{i,j},1.0)),
cp(X;Y)=β∗i=1∑∣X∣log(min(j=1∑∣Y∣pi,j,1.0)),
其中
p
i
,
j
p_{i,j}
pi,j是第
j
j
j个目标词
y
j
y_j
yj对第
i
i
i个源词
x
i
x_i
xi的注意力概率。通过构造(等式4),
∑
i
=
0
∣
X
∣
p
i
,
j
\sum^{|X|}_{i=0}p_{i,j}
∑i=0∣X∣pi,j等于1。参数
α
α
α和
β
β
β控制长度归一化和覆盖损失的强度。当
α
=
0
α=0
α=0和
β
=
0
β=0
β=0时,我们的解码器会按概率退回到纯集束搜索。
在集束搜索期间,我们通常保留8-12个假设,但我们发现使用较少的假设(4或2)只会对BLEU分数产生轻微的负面影响。除了修剪一些假设的数目外,还使用了其他两种修剪形式。首先,在每个步骤中,我们仅考虑具有局部得分不超过该步骤的最佳字符的beamsize的字符。其次,在根据等式14找到归一化的最佳分数之后,我们删去所有比beamsize低于到目前为止的最佳归一化分数更大的假设。后者的修剪类型仅适用于完整假设,因为它会比较归一化空间中的分数,该空间仅在假设结束时才可用。后一种修剪形式还具有以下作用:一旦找到足够好的假设,就不会很快生成更多的假设,因此搜索将很快结束。与未修剪相比,在CPU上运行时,修剪将搜索速度提高了30%-40%(在这种情况下,我们会在预先确定的最大输出长度为源长度的两倍后停止解码)。通常,除非另有说明,否则我们使用
b
e
a
m
s
i
z
e
=
3.0
beamsize=3.0
beamsize=3.0。
为了提高解码期间的吞吐量,我们可以将许多类似长度的句子(通常最多35个)放入批处理中,并对所有这些句子进行并行解码,以利用针对并行计算优化的可用硬件。在这种情况下,只有在批次中所有句子的所有假设都超出集束的情况下,集束搜索才会结束,这在理论上效率较低,但实际上附加计算成本可忽略不计。

















 2028
2028

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









