







 谷歌GNMT通过结合attention机制和seq-seq模型,解决了NMT中的OOV问题,采用sub-word units。模型使用8层LSTM,利用残差网络、attention、encoder-decoder结构,并在训练中应用数据并行和模型并行。通过length normalization和coverage penalty提升翻译质量。使用低精度算法加速训练和翻译,提高了NMT系统在实际应用中的表现。
谷歌GNMT通过结合attention机制和seq-seq模型,解决了NMT中的OOV问题,采用sub-word units。模型使用8层LSTM,利用残差网络、attention、encoder-decoder结构,并在训练中应用数据并行和模型并行。通过length normalization和coverage penalty提升翻译质量。使用低精度算法加速训练和翻译,提高了NMT系统在实际应用中的表现。
总结:1. GNMT 模型的成功,背后依靠的是 attention 机制和 seq-seq 的结合。
2. 为了解决 OOV(out-of-vocabulary)问题,使用 sub-word units(wordpieces)
3. Encoder 和 decoder 均使用 LSTM 和残差网络搭建,其中 encoder 第一层使用双向 LSTM,decoder 过程中,在 beam search 基础上,增加了 coverage penalty 和 length normalization,以提升翻译质量。
4. 为了加快训练速度和翻译速度,使用模型并行和数据并行,对于没卡的个人玩家, 数据并行更有帮助。
5. 提出了 GLEU,将 reward 融入 seq-seq 模型中,先使用公式 7 来训练模型到收敛, 然后使用公式 9 来重建模型,直到 BLEU 值不再提高。
6. 为了量化模型,提高效率,谷歌限制了 Cti , Xti 的范围,并且在翻译过程中将所有 的浮点运算改成 8-bit 或 16-bit。
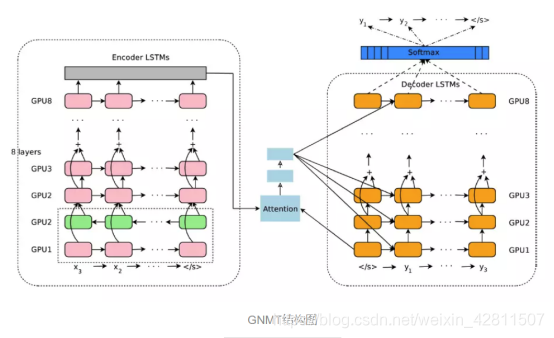
最后,附上系统的网络结构图,全文阅读难度不大,但阅读前需要先了解残差网络,LSTM,attention,seq-seq等模型。
1.摘要和简介
目前NMT的主要缺陷有:1.训练速度慢,2.很难处理生词,3.处理长句无法完全覆盖source sentence,出现漏翻。
因此,谷歌提出了GNMT来解决上述的问题。GNMT包含采用encoder-decoder结构,encoder和decoder中都包含8层LSTM网络,encoder和decoder内部均使用残差连接,encoder和decoder之间使用attention。
为了提高翻译的效率,谷歌在翻译过程中使用低精度的算法。
为了解决输入的生词,谷歌在输入和输出中使用了sub-word units(wordpieces),(比如把’higher’拆分成’high’和’er’)。
在beam search中加入关于长度的正则化项(length normalization),和一个
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1169
1169

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









