






 本文提出NS-Solver,通过结合数学符号约束和四个辅助任务(数量预测、常数预测、一致性检查和对偶利用)提升数学单词问题解决的准确性。通过编码器-解码器结构,引入符号方程生成,有效解释和生成预测,适用于不同类型的MWP,包括算术、线性、非线性及方程组。新数据集CM17K提供挑战性测试,实验结果优于现有方法。
本文提出NS-Solver,通过结合数学符号约束和四个辅助任务(数量预测、常数预测、一致性检查和对偶利用)提升数学单词问题解决的准确性。通过编码器-解码器结构,引入符号方程生成,有效解释和生成预测,适用于不同类型的MWP,包括算术、线性、非线性及方程组。新数据集CM17K提供挑战性测试,实验结果优于现有方法。
摘要
数学单词问题任务中,先前使用encoder-decoder框架的工作未明确地结合数学符号约束,导致无法解释和生成不合理的预测。这里,我们提出了神经符号求解器(NS-Solver)以通过辅助任务来显示地纳入不同级别的符号约束。我们的NS-Solver包括一个problem reader来编码问题,programmer来生成符号方程,以及symbolic executor以获得答案。与目标表达式的监督学习一起,我们的NS-Solver还通过4个新的辅助目标进行了优化,以强制执行不同的符号推理:a)self-supervised number prediction task,以预测数字数量和数字位置。b)commonsense constant prediction task,以预测需要哪些先验知识(例如,鸡有多少腿); c)program consistency checker,以计算预测的方程和目标方程之间的语义损失,从而确保合理的等式映射;d) duality exploiting task,利用生成的符号方程和问题词性之间的对偶性,以增强solver的理解能力。此外,为了能够开发出通用的和可扩展的求解器,我们还构建了由4种类型MWP(arithmetic, one-unknown linear, one-unknown non-linear, equation set)组成的超过17k的数据集,以提供更加现实和具有挑战性的benchmark。我们在Math23K和CM17K上的实验结果表明,与最先进的方法相比我们NS-Solver方法更好。
1.介绍
深度神经网络最近在自然语言处理中取得了显着成功。虽然神经模型已经表现出在某些任务中优于人类(例如,阅读理解),但是它仍然缺乏离散推理的能力,导致数学推理的准确性低。因此,纯粹的神经网络难以解决解决数学单词问题(MWP)任务,该任务需要模型能够同时进行自然语言理解和离散推理。MWP求解的目的是通过理解问题的文本描述,并推理处潜在答案来自动回答数学单词问题。典型的MWP是一个简短的故事,该故事对世界的部分状态,以及未知变量或多个未知变量构成问题进行描述。要解决MWP,需要从文本中识别相关的变量。此外,需要确定正确的运算符以及它们之间的计算顺序。因此,具有符号推理的神经网络对求解MWP来说至关重要。受最近神经语义解析和阅读理解工作的启发,我们通过神经符号计算来解决这个问题。
最近,许多研究人员受编码器-解码器框架的启发,通过应用神经网络学习一个从问题到其对应方程之间的映射函数来解决MWP,并实现了显着的成功。编码器使用神经网络的输出矢量来表示一个问题,并且解码器使用另一个神经网络来生成等式或表达式的字符。先前方法之间的主要区别是解码表达式或方程的方法。但是,它们仅遵循编码器-解码器模型,并缺乏显示地引入数学符号约束的能力(例如,致辞常量,制定正规化),导致无法解释和生成不合理的预测。此外,其中大多数工作仅关注算术类型的MWP,从而无法泛化到各种类型的MWP问题,例如等式集问题。
为了解决上述问题,我们提出了一种新的神经符号求解器(NS-Solver),其通过引入辅助学习任务来显示地纳入不同级别的符号约束。我们的NS-Solver由三个主要组件组成:一个 problem reader 将数学单词问题编码为矢量表示,一个programmer来生成符号方程,用来对其执行以生成答案,并且还有一个symbolic executor来获得最终的结果。除了使用生成的符号方程和目标方程之间的有监督训练目标外,我们的求解器还通过四个新的辅助目标进行了优化,该目标强制模型执行四个级别的问题理解和符号推理:a)self-supervised number prediction task,以预测数字数量和数字位置。b)commonsense constant prediction task,以预测需要哪些先验知识(例如,鸡有多少腿); c)program consistency checker,以计算预测的方程和目标方程之间的语义损失,从而确保合理的等式映射;d) duality exploiting task,利用生成的符号方程和问题词性之间的对偶性,以增强solver的理解能力。我们解决方案有一些关键优势:首先,上述四个辅助任务可以产生额外的训练信号,这提高了信赖中的数据效率,并使我们的求解器更加强大。其次,使用预测的常数来约束目标符号表可以大大减少搜索空间,这意味着我们的求解器可以更轻松地产生正确的符号方程。第三,已证明辅助任务有助于降低所已知和未知类型MWP之间的领域差距,从而提高我们求解器的推理能力。
此外,除了目前只有一种类型的大规模高质量MWP测试基准之外,我们还构建了一个大型具有挑战性的中文MWP数据集CM17K,其中包含4种类型的MWP((arithmetic MWPs, oneunknown linear MWPs, one-unknown non-linear
MWPs, equation set problems),具有超过17K的样本,这为开发出通用的和可扩展的数学求解器提供更现实和具有挑战性的基准。在公开Math23k数据集的广泛实验和在我们提出的CM17K数据集上实验,显示了我们的NS-Solver的优越性,我们的模型在确保中间方程合理性的同时能够预测最终结果。
2.相关工作
Deep learning-based MWP Solvers。已经提出了许多方法来解决MWP任务,从基于规则的方法,统计机器学习方法,语义解析方法,再到深度学习方法等等。但是,由于基于深度学习的方法仅遵循编码器解码器框架,而没有明确地结合必要的数学符号约束,导致一些无法解释的和不合理的预测。此外,它们中的大多数仅关注算术类型MWP,从而无法泛化到各种类型的MWP问题,例如等式集问题。
Neural-Symbolic Computing。神经符号计算极大地促进了语义解析的发展。Jia and Liang (2016); Dong and Lapata (2016); Zhong et al. (2017) 将神经seq2seq和seq2tree模型应用于有监督的语义解析。Liang et al. (2017b, 2018b) 在知识图谱和表格数据库上凭借弱监督的语义解析达到了最好的性能。虽然语义解析的大多数成功仅限于结构化数据源,但对于MWP来说代价并不昂贵,因为很容易爬取到有标注方程和答案的问题。因此,MWP求解可以受益于有监督的神经符号计算。
Self-Supervised Learning。自监督的辅助任务已广泛应用于自然语言理解的领域。Devlin et al. (2019) 应用了两个自监督的辅助任务,masked LM和next sentence prediction,以通过预训练来改善BERT的理解能力。Albert引入了sentence-order prediction任务,以解决BERTnext sentence prediction任务的无效性。Hendrycks et al. (2019) 表明,自监督的学习可以改善模型鲁棒性和不确定性。
Dual Learning。双重学习,首先由He et al. (2016) 提出,是一个通过共同训练一个原始任务及其对偶任务来强化训练的过程。然后 Xia et al. (2017) 将其视为有监督学习的一种方式,并设计了概率正则化项来利用其对偶性。它已广泛应用于各种领域,例如机器翻译,情感分类,问答,视觉问答,机器阅读理解和代码生成。据我们所知,我们是第一个利用MWP对偶性的工作。与以前的工作不同,我们在符号方程生成和问题部分之间设计了一种对偶学习方法,通过缓解来自符号方程的问题的难度来增强理解能力。
3.Neural-Symbolic Solver
在本节中,我们介绍了所提出的NS-Solver的设计。 其主干部分主要由一个problem reader组成,该problem reader将数学单词问题编码为矢量表示,programmer以前缀顺序生成符号方程,然后再通过symbolic executor以获得最终结果。我们的NS-Solver方法如图1所示。我们首先在3.1节中介绍我们的NS-Solver的主干,然后我们在第3.2节中引入其他辅助任务。
3.1 Backbone
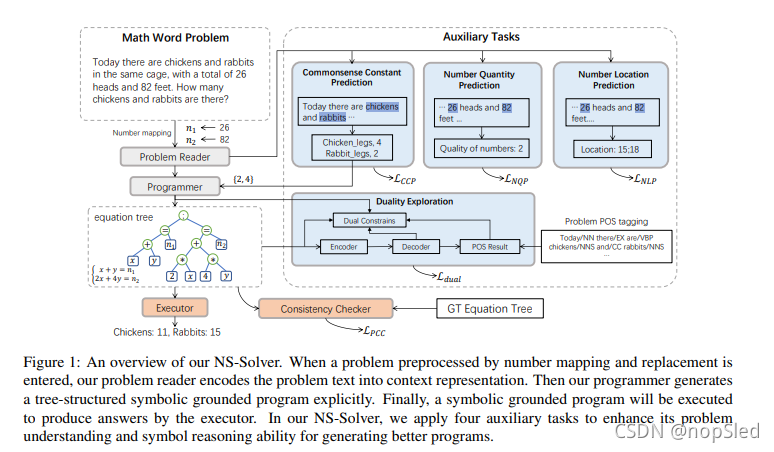
Problem Reader。给定由数字模板替换处理后的问题文本
P
=
{
x
i
}
i
=
1
n
P=\{x_i\}^n_{i=1}
P={xi}i=1n,该数字模板替换将数值映射到数字模板(例如,图1中的26和82映射到了
n
1
n_1
n1和
n
2
n_2
n2),problem reader将问题文本中的每个字符
x
i
x_i
xi编码到嵌入
e
i
e_i
ei。在这项工作中,我们使用了双层双向GRU,以将每个字符
x
i
x_i
xi编码为对应的嵌入
e
i
=
h
i
→
+
h
i
←
e_i=\overrightarrow{\textbf h_i}+\overleftarrow{\textbf h_i}
ei=hi+hi,其中
h
i
→
\overrightarrow{\textbf h_i}
hi和
h
i
←
\overleftarrow{\textbf h_i}
hi分别来自前向和后向GRU。此外,我们的问题编码器还输出问题表示
g
0
=
h
n
→
+
h
0
←
\textbf g_0=\overrightarrow{\textbf h_n}+\overleftarrow{\textbf h_0}
g0=hn+h0作为programmer的初始隐藏状态,其中
h
n
→
\overrightarrow{\textbf h_n}
hn和
h
0
←
\overleftarrow{\textbf h_0}
h0分别是前向和后向GRU的最后一个隐藏状态。
Programmer。programmer将problem reader的输出作为输入,并将问题表示作为初始隐藏状态,然后将问题解码为字符序列
{
y
i
}
i
=
1
m
\{y_i\}^m_{i=1}
{yi}i=1m,它们被组织为前缀等式树。在这项工作中,我们将带有注意力机制的树结构解码器作为programmer,并使用UET表示修改它们,以支持多种类型MWP中的更多符号。在我们的programmer中,符号表包括四个部分。对于每个问题,特定问题的符号表包含数学运算符(+,- ,*,^,/,=,;),未知变量(x和y),由 Commonsense Constant Prediction 任务预测的一系列常数(1,3.14等),以及特定问题的的数字模板(
n
1
n_1
n1,
n
2
n_2
n2,
n
3
n_3
n3等)。应该被注意到的是,
;
;
;是一个具有最低优先级的特殊运算符,可以将多个方程树集成为集合方程树,因此可以将方程式集合问题作为算术问题进行简单求解。
Executor。我们使用Sympy,它是一个符号数学的Python库,来作为通过生成的方程来获取最终结果的符号执行器。
3.2 The Design of Auxiliary Tasks
MWP求解任务仍然具有挑战性,因为之前的方法没有充分利用问题所包含的丰富语义,并且缺乏显示纳入数学符号约束的能力。在本节中,我们介绍了四个辅助学习任务,以利用从不同任务获得的额外训练信号,并利用了commonsense constant prediction 任务的结果,以明确限制常数符号表,这可以减少符号生成的搜索空间,并缓解生成正确常数的难度。
(1)Self-supervised Number Prediction (SNP) Tasks
如果求解器可以完全理解问题的语义,则它应该能够识别问题中数值的数量(即,计算问题中有多少数值),并且准确地预测出这些数值在问题文本中的相应位置。例如,如果求解器可以理解图1中的问题,那么它应该能够预测问题中有两个数(26和82),并且它们的位置分别为15和18。因此,数值的数量预测和位置预测是两个关键的自监督任务,以帮助problem reader完全理解问题的语义并测量求解器的问题理解能力。两个数值预测任务都将问题编码器输出
{
e
i
}
i
=
1
n
\{e_i\}^n_{i=1}
{ei}i=1n的均值作为其输入,并应用单层前馈神经网络来计算数值数量和数字位置的分布。这两个任务的训练目标被定义为:
L
N
Q
P
=
−
∑
i
=
1
Q
q
t
i
l
o
g
p
(
q
i
∣
P
)
,
L
N
L
P
=
−
∑
i
=
1
L
l
t
i
l
o
g
p
(
l
i
∣
P
)
.
(1)
\mathcal L_{NQP}=-\sum^Q_{i=1}qt_i~log~p(q_i|P),\\ \mathcal L_{NLP}=-\sum^L_{i=1}lt_i~log~p(l_i|P).\tag{1}
LNQP=−i=1∑Qqti log p(qi∣P),LNLP=−i=1∑Llti log p(li∣P).(1)
其中
L
N
Q
P
\mathcal L_{NQP}
LNQP和
L
N
L
P
\mathcal L_{NLP}
LNLP分别表示数值数量预测(NQP)任务和数值位置预测(NLP)任务的损失。
Q
Q
Q和
L
L
L是数据集中最大的数值数量和最长的数值位置。
q
t
i
qt_i
qti和
l
t
i
lt_i
lti分别代表了NQP和NLP输出概率分布中第
i
i
i个索引的真实值。
(2)Commonsense Constant Prediction (CCP) Task
常识常数对于解决一些MWP很重要,而大部分先前的工作只考虑常数1和3.14,这对求解器来解决需要其他类型的常数问题是不够的。然而,将所有常数附加到特定问题的符号表将放大搜索空间,从而提高了生成合理的符号方程的难度。因此,我们提出了一种常识常数预测任务来预测先验的常识知识(例如对于图1中的问题,鸡具有2.0腿,并且兔子具有4.0条腿)。求解器需要根据这些先验只是来解决问题。通过这种方式,我们可以大大减少搜索空间,从而提高了我们的求解器的性能。类似于数字预测任务,常识常数预测任务将问题编码器输出
{
e
i
}
i
=
1
n
\{e_i\}^n_{i=1}
{ei}i=1n的均值作为其输入,并应用单层前馈神经网络来计算数值数量和位置的分布。训练目标被定义为:
L
C
C
P
=
−
∑
i
=
1
C
c
t
j
l
o
g
p
(
c
i
∣
P
)
.
(2)
\mathcal L_{CCP}=-\sum^C_{i=1}ct_j~log~p(c_i|P).\tag{2}
LCCP=−i=1∑Cctj log p(ci∣P).(2)
其中
C
C
C是符号表中的常量的总数,
c
t
i
ct_i
cti表示输出概率分布中第
i
i
i个索引的真实值。由于常识常数预测任务不可能实现100%的准确性,除了预测的常数之外,我们还添加了三个在符号表中具有最高概率的未预测的额外常数,从而平衡了搜索空间的大小和预测的准确性。
(3)Program Consistency Checker (PCC)
尽管可以通过多个不同的方程来解决问题,但是预测的等式应该在监督学习设置中尽可能多地与目标方程一致。因此,我们提出了一个Program Consistency Checker,以检查符号方程的一致性,并通过计算预测的符号方程和真实方程之间的语义损失来规范模型,以确保合理的符号方程映射。令
y
^
i
\hat y_i
y^i和
y
i
y_i
yi表示预测的符号方程和真实符号方程,
p
i
p_i
pi表示
y
^
i
\hat y_i
y^i的概率,通过计算预测分布和真实分布之间的距离来获得语义损失:
L
P
C
C
=
−
l
o
g
∑
i
∏
y
^
i
=
y
i
p
i
∏
y
^
i
≠
y
i
(
1
−
p
i
)
.
(3)
\mathcal L_{PCC}=-log\sum_i\prod_{\hat y_i=y_i}p_i\prod_{\hat y_i\ne y_i}(1-p_i).\tag{3}
LPCC=−logi∑y^i=yi∏piy^i=yi∏(1−pi).(3)
(4)Duality Exploiting (DE) Task
先前的许多使用双重学习框架的工作显示了有希望的结果。直观上,MWP求解和MWP生成彼此相关,即,MWP求解的输入是MWP生成的输出,反之亦然,MWP生成任务(通过没有任何主题信息的方程式生成足够好的问题)是非常困难的。 因此,我们提出了一种对偶性利用任务,通过利用真实符号方程生成与问题词性生成之间的对偶性来增强我们求解器的理解能力。给定一个问题及其相应的等式
(
P
,
T
)
(P,T)
(P,T),并且
P
′
P'
P′是
P
P
P的词性,对偶利用任务的训练目标被定义为:
L
d
u
a
l
=
[
l
o
g
p
^
(
P
′
)
+
l
o
g
p
(
T
∣
P
)
−
l
o
g
p
^
(
T
)
−
l
o
g
p
(
P
′
∣
T
)
]
2
.
(4)
\mathcal L_{dual}=[log~\hat p(P')+log~p(T|P)-log~\hat p(T)-log~p(P'|T)]^2.\tag{4}
Ldual=[log p^(P′)+log p(T∣P)−log p^(T)−log p(P′∣T)]2.(4)
其中
p
^
(
P
′
)
\hat p(P')
p^(P′)和
p
^
(
T
)
\hat p(T)
p^(T)是边缘分布,其可以分别由基于LSTM的语言模型建模。此外,我们使用了由GTS启发的树结构编码器,以编码用于POS生成的方程。
3.3 Training Objective
给定训练数据集
D
=
{
(
P
1
,
T
1
)
,
(
P
2
,
T
2
)
,
.
.
.
(
P
N
,
T
N
)
}
\textbf D= \{(P^1,T^1),(P^2,T^2),...(P^N,T^N)\}
D={(P1,T1),(P2,T2),...(PN,TN)},其中
T
i
T^i
Ti是问题
P
i
P^i
Pi的通用表达式树,为了优化NS-Solver,我们最下化以下损失函数:
L
=
∑
(
P
,
T
)
∈
D
[
L
e
n
t
1
+
λ
1
∗
L
d
u
a
l
+
λ
2
∗
L
P
C
C
+
λ
3
(
L
N
Q
P
+
L
N
L
P
)
+
λ
4
∗
L
C
C
P
]
.
(5)
\mathcal L=\sum_{(P,T)\in \textbf D}[\mathcal L_{ent1}+\lambda_1*\mathcal L_{dual}+\lambda_2*\mathcal L_{PCC}+\lambda_3(\mathcal L_{NQP}+\mathcal L_{NLP})+\lambda_4*\mathcal L_{CCP}].\tag{5}
L=(P,T)∈D∑[Lent1+λ1∗Ldual+λ2∗LPCC+λ3(LNQP+LNLP)+λ4∗LCCP].(5)
其中:
L
e
n
t
1
=
−
l
o
g
∏
t
=
1
m
p
r
o
b
(
y
t
∣
P
)
(6)
\mathcal L_{ent1}=-log\prod^m_{t=1}prob(y_t|P)\tag{6}
Lent1=−logt=1∏mprob(yt∣P)(6)
其中
m
m
m表示
T
T
T的大小,并且
y
t
y_t
yt表示第
t
t
t时刻的输出。
{
λ
i
}
i
=
1
4
\{λ_i\}^4_{i=1}
{λi}i=14是将在第4.2节中详述的超参。
对于 duality exploitin任务,还有另一个用于训练问题词性生成模型的损失:
L
P
O
S
=
∑
(
P
′
,
T
)
∈
D
[
L
e
n
t
2
+
λ
5
∗
L
d
u
a
l
+
λ
6
∗
L
P
C
C
′
]
.
(7)
\mathcal L_{POS}=\sum_{(P',T)\in \textbf D}[\mathcal L_{ent2}+\lambda_5*\mathcal L_{dual}+\lambda_6*\mathcal L_{PCC'}].\tag{7}
LPOS=(P′,T)∈D∑[Lent2+λ5∗Ldual+λ6∗LPCC′].(7)
其中:
L
e
n
t
2
=
−
l
o
g
∏
t
=
1
n
p
r
o
b
(
x
t
∣
T
)
(6)
\mathcal L_{ent2}=-log\prod^n_{t=1}prob(x_t|T)\tag{6}
Lent2=−logt=1∏nprob(xt∣T)(6)
其中
n
n
n表示
P
P
P的大小,并且
x
t
x_t
xt表示第
t
t
t时刻的输出。
L
P
C
C
‘
\mathcal L_{PCC‘}
LPCC‘是预测POS和真实POS之间的语义损失。
{
λ
i
}
i
=
5
6
\{λ_i\}^6_{i=5}
{λi}i=56是在第4.2节中将详细说明的超参。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









