






 提出一种新的跨模态记忆网络模型以增强放射学报告生成。该模型通过存储矩阵记录图像和文本间的对齐信息,实现更好的跨模态交互。实验表明,此方法能显著提升报告生成的准确性。
提出一种新的跨模态记忆网络模型以增强放射学报告生成。该模型通过存储矩阵记录图像和文本间的对齐信息,实现更好的跨模态交互。实验表明,此方法能显著提升报告生成的准确性。
摘要
医学成像在医学诊断的临床实践中起着重要作用,其中基于图像的文本报告对于了解它们并促进后期治疗至关重要。通过自动生成报告,有助于减轻放射科医师的负担,并显着促进临床自动化,这已经吸引了向医疗领域使用人工智能技术的兴趣。以前的研究主要遵循编码器 - 解码器框架并专注于文本生成的方面,几乎没有考虑跨模态映射的重要性,并明确利用这种映射以促进放射学报告生成。在本文中,我们提出了一种跨模态存储器网络(CMN)来增强用于放射学报告生成的编码器-解码器框架,其中共享存储器被设计为记录图像和文本之间的对齐,以便于跨模态的交互和生成。实验结果说明了我们所提出的模型的有效性,其中最优的性能是在两个广泛使用的基准数据集中达到的,即IU X-Ray和MIMIC-CXR。进一步的分析还证明我们的模型能够更好地从放射学图像和文本对准信息,以帮助在临床指标方面产生更准确的报告。
1.介绍
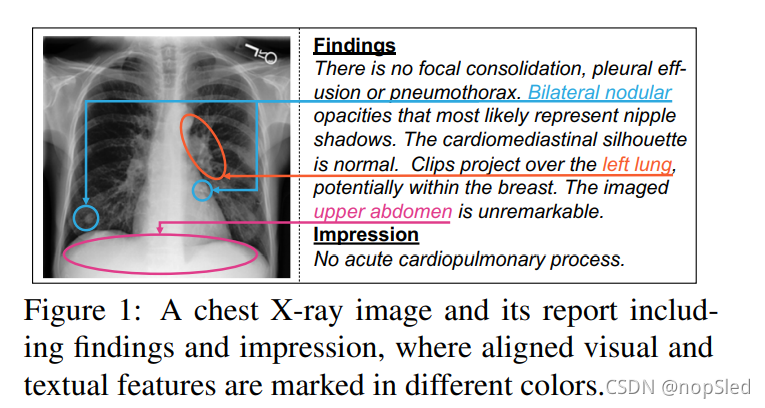
解释放射学图像(例如,胸部X射线)并将其写入诊断报告是临床实践中的基本操作,通常需要相当大的手动工作量。因此, radiology report generation旨在自动生成基于X照片的文本描述的放射学报告,这非常有希望能够缓解放射科医师的负担,同时保持较高的质量。最近,放射学报告自动生成模型已经取得了实质性进展。大多数现有研究采用传统的编码器-解码器架构,其中使用卷积神经网络(CNNS)作为编码器,循环网络(例如,LSTM / GRU)或非循环网络(例如,Transformer)作为解码器。虽然这些方法已经实现了显着的性能提升,但它们仍然无法完全利用放射学图像和报告的信息,例如图1中所示的映射,其对齐了视觉和文本的特征点到相同的内容。无法充分利用信息的原因来自通过使用与图像和文本对应的标注进行有监督学习的限制,以及缺乏良好的模型设计来学习对应关系。不幸的是,很少有研究致力于解决这些限制。因此,期望可以有更好地解决跨模态的对齐方式并进一步提高生成能力。
在本文中,我们提出了一种通过跨模态存储器网络(CMN)增强的放射学报告生成的有效且简单的方法,旨在促进跨模态(即图像和文本)的交互。详细地,我们使用存储矩阵来存储跨模态信息并使用它来执行对视觉和文本特征的存储查询和响应,其中对于存储查询,我们从矩阵中提取最相关的存储向量并根据输入的视觉和文本特征计算它们权重,然后通过加权查询到的存储矢量来生成响应。之后,对于输入视觉和文本特征的响应被馈送到编码器和解码器中,以便通过显式的可学习的跨模态信息生成增强的报告。在两个基准数据集,IU X-Ray和MIMIC-CXR上的实验结果证实了我们所提出的方法的有效性和高效性,并在这两个数据集上实现了最好的性能。我们还执行了几种分析来分析影响我们模型的不同因素,表明我们的模型能够通过有意义的图像文本映射生成报告,同时仅需要几个额外的参数。
2.方法
我们将放射学报告生成看作一种image-to-text生成任务,对于该任务目前已经有几种解决方案。虽然图像被组织为2-D格式,但我们在该任务中仍然遵循标准的序列到序列框架,正如Chen et al. (2020)中所做。更详细地,源序列是
X
=
{
x
1
,
x
2
,
.
.
.
,
x
s
,
.
.
.
,
x
S
}
\textbf X=\{\textbf x_1,\textbf x_2,...,\textbf x_s,...,\textbf x_S\}
X={x1,x2,...,xs,...,xS},其中
x
s
∈
R
d
\textbf x_s\in \mathbb R^d
xs∈Rd是通用使用视觉抽取器从放射学图像
I
\textbf I
I中抽取的特征,目标序列是相应的报告
Y
=
{
y
1
,
y
2
,
.
.
.
,
y
t
,
.
.
.
,
y
T
}
\textbf Y=\{y_1,y_2,...,y_t,...,y_T\}
Y={y1,y2,...,yt,...,yT},其中
y
t
∈
V
y_t∈\mathbb V
yt∈V是生成的字符,
T
T
T是报告的长度,
V
\mathbb V
V是表示所有可能字符的词表。因此,整个生成过程被形式化为通过链式规则进行的递归生成:
p
(
Y
∣
I
)
=
∏
t
=
1
T
p
(
y
t
∣
y
1
,
.
.
.
,
y
t
−
1
,
I
)
(1)
p(\textbf Y|\textbf I)=\prod^T_{t=1}p(y_t|y_1,...,y_{t-1},\textbf I)\tag{1}
p(Y∣I)=t=1∏Tp(yt∣y1,...,yt−1,I)(1)
然后,该模型可以通过给定
I
\textbf I
I的
Y
\textbf Y
Y的条件对数似然来最大化
p
(
Y
∣
I
)
p(\textbf Y|\textbf I)
p(Y∣I),以进行训练:
θ
∗
=
a
r
g
m
a
x
θ
∑
t
=
1
T
l
o
g
p
(
y
t
∣
y
1
,
.
.
.
,
y
t
−
1
,
I
;
θ
)
(2)
\theta^*=\mathop{argmax}\limits_{\theta}\sum^T_{t=1}log~p(y_t|y_1,...,y_{t-1},\textbf I;\theta)\tag{2}
θ∗=θargmaxt=1∑Tlog p(yt∣y1,...,yt−1,I;θ)(2)
其中
θ
θ
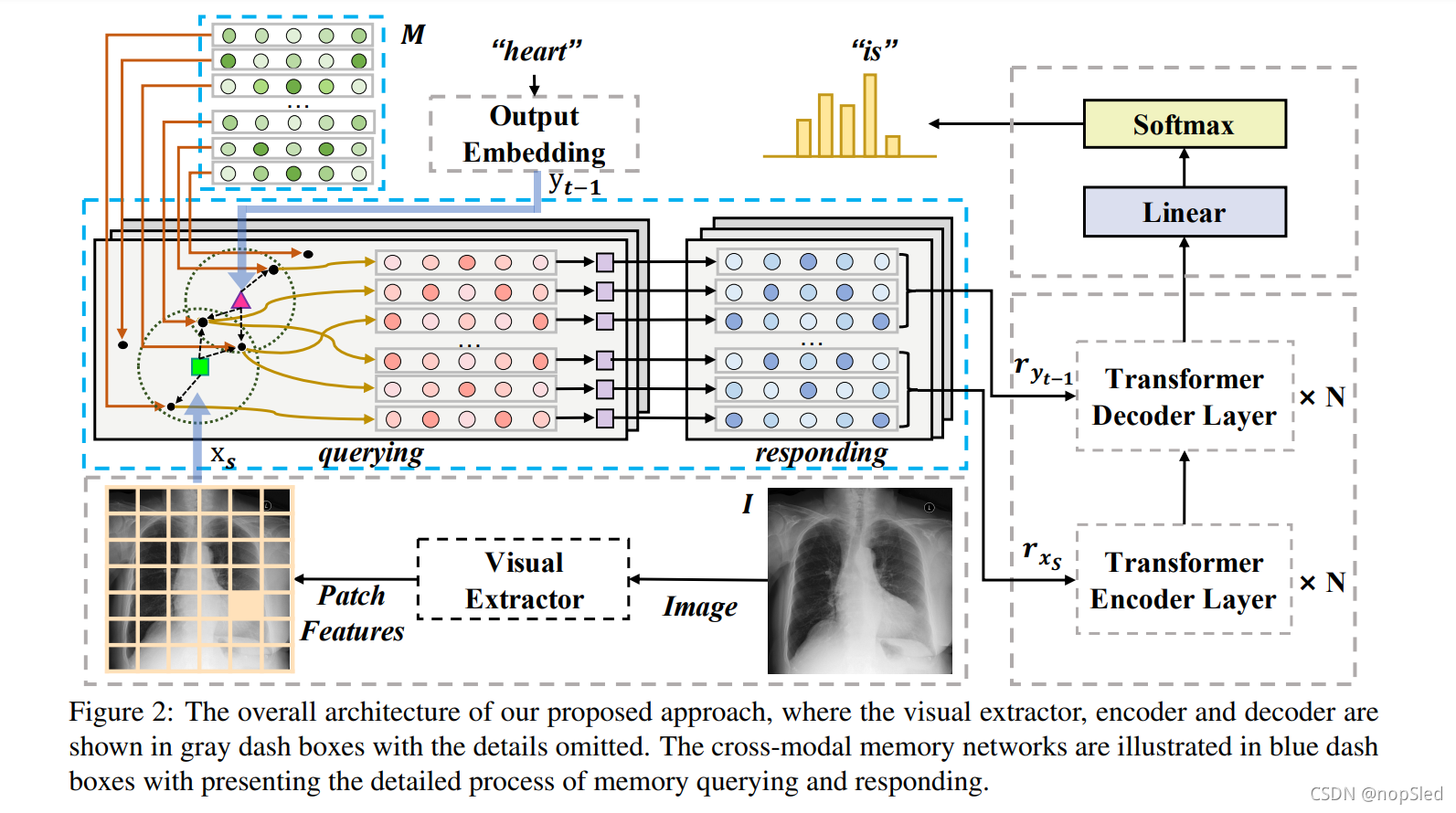
θ是模型的参数。图2中展示了所提出的具有跨模态存储器模型的概述。我们方法中关于三个主要组件的细节将在以下各节中描述,即visual extractor,cross-modal memory network和存储器增强的encoder-decoder。
2.1 Visual Extractor
为了生成放射学报告,第一步是从放射学图像中提取视觉特征。在我们的方法中,通过预训练的卷积神经网络(CNN,例如VGG或ResNet)提取放射学图像
I
\textbf I
I的视觉特征
X
\textbf X
X。通常,图像被分解成相等尺寸的区域,即patches,然后这些patches的特征(或表示)从CNN的最后的卷积层中提取。一旦提取完毕,在我们的研究中,这些特征通过按图像上每行的顺序拼接而被扩展为序列。然后,所得到的表示序列用作所有后续模块的源输入,该过程被形式化为:
{
x
1
,
x
2
,
.
.
.
,
x
s
,
.
.
.
,
x
S
}
=
f
v
(
I
)
(3)
\{\textbf x_1,\textbf x_2,...,\textbf x_s,...,\textbf x_S\}=f_v(\textbf I)\tag{3}
{x1,x2,...,xs,...,xS}=fv(I)(3)
其中
f
v
(
⋅
)
f_v(·)
fv(⋅)是指视觉提取器。
2.2 Cross-modal Memory Networks
为了建模图像和文本之间的对齐,现有研究倾向于直接从其编码表示之间映射图像和文本(例如,Jing et al. (2018) 使用co-attention这样做)。然而,该过程总会有一定限制,跨模态的表示是难以对齐的,从而需要期望中间表示可以增强和平滑这种映射。为了解决该限制,我们提出使用CMN来更好地建模图像文本对齐,以便于报告生成过程。
使用所提出的CMN,可以用以下过程中描述映射和编码。给定一个来自于图像的源序列
{
x
1
,
x
2
,
.
.
.
,
x
S
}
\{\textbf x_1,\textbf x_2,...,\textbf x_S\}
{x1,x2,...,xS}(从视觉提取器中提取的特征),我们将该序列送入此模块以获取视觉特征的存储响应
{
r
x
1
,
r
x
2
,
.
.
.
,
r
x
S
}
\{\textbf r_{\textbf x_1},\textbf r_{\textbf x_2},...,\textbf r_{\textbf x_S}\}
{rx1,rx2,...,rxS}。类似地,给定生成的序列
{
y
1
,
y
2
,
.
.
.
,
y
t
−
1
}
\{y_1,y_2,...,y_{t-1}\}
{y1,y2,...,yt−1}及其嵌入
{
y
1
,
y
2
,
.
.
.
,
y
t
−
1
}
\{\textbf y_1,\textbf y_2,...,\textbf y_{t-1}\}
{y1,y2,...,yt−1},它也被送入到跨模态存储器网络以输出文本特征的存储响应
{
r
y
1
,
r
y
2
,
.
.
.
,
r
y
t
−
1
}
\{\textbf r_{\textbf y_1},\textbf r_{\textbf y_2},...,\textbf r_{\textbf y_{t-1}}\}
{ry1,ry2,...,ryt−1}。这样做的目的,是可以在存储器中记录视觉和文本特征的共享信息,以便整个学习过程能够在图像和文本之间显式地映射。具体地,跨模态存储器网络采用矩阵来保存用于编码和解码过程的信息,其中矩阵的每一行(即,存储器向量)记录连接图像和文本的特定跨模型信息。我们将这个矩阵表示为
M
=
{
m
1
,
m
2
,
.
.
.
,
m
i
,
.
.
.
,
m
N
}
\textbf M=\{\textbf m_1,\textbf m_2,...,\textbf m_i,...,\textbf m_{\mathcal N}\}
M={m1,m2,...,mi,...,mN},其中
N
\mathcal N
N表示存储器矢量的数量,
m
i
∈
R
d
\textbf m_i∈\mathbb R^d
mi∈Rd表示矩阵中维度为
d
d
d的第
i
i
i行向量。在报告生成过程中,CMN用到两个主要步骤操作,即查询和响应,其细节描述如下。
Memory Querying。我们应用多线程查询以执行此操作,其中在每个线程中,查询过程都遵循相同的如下所述的过程。
在存储器向量查询过程中,第一步是确保输入的视觉和文本特征是在相同的表示空间中。因此,我们通过线性变换将
M
\textbf M
M以及输入特征中的向量进行转换:
k
i
=
m
i
⋅
W
k
(4)
\textbf k_i=\textbf m_i\cdot \textbf W_k\tag{4}
ki=mi⋅Wk(4)
q
s
=
x
s
⋅
W
q
(5)
\textbf q_s=\textbf x_s\cdot \textbf W_q\tag{5}
qs=xs⋅Wq(5)
q
t
=
y
t
⋅
W
q
(6)
\textbf q_t=\textbf y_t\cdot \textbf W_q\tag{6}
qt=yt⋅Wq(6)
其中,
W
k
\textbf W_k
Wk和
W
q
\textbf W_q
Wq是可训练的权重矩阵。然后,我们分别根据视觉和文本特征将最相关的存储器向量进行提取,这主要根据其距离
D
s
i
D_{s_i}
Dsi和
D
t
i
D_{t_i}
Dti来计算:
D
s
i
=
q
s
⋅
k
i
T
d
(7)
D_{s_i}=\frac{\textbf q_s\cdot \textbf k^T_i}{\sqrt{d}}\tag{7}
Dsi=dqs⋅kiT(7)
D
t
i
=
q
t
⋅
k
i
T
d
(8)
D_{t_i}=\frac{\textbf q_t\cdot \textbf k^T_i}{\sqrt{d}}\tag{8}
Dti=dqt⋅kiT(8)
其中,需要提取的存储器矢量的数量可以通过超参数
K
\mathcal K
K控制以规范使用多少个存储值。我们将查询到的存储矢量表示为
{
k
s
1
,
k
s
2
,
.
.
.
,
k
s
j
,
.
.
.
,
k
s
K
}
\{\textbf k_{s_1},\textbf k_{s_2},...,\textbf k_{s_j},...,\textbf k_{s_{\mathcal K}}\}
{ks1,ks2,...,ksj,...,ksK}和
{
k
t
1
,
k
t
2
,
.
.
.
,
k
t
j
,
.
.
.
,
k
t
K
}
\{\textbf k_{t_1},\textbf k_{t_2},...,\textbf k_{t_j},...,\textbf k_{t_{\mathcal K}}\}
{kt1,kt2,...,ktj,...,ktK}。之后,通过通过归一化所抽取向量的距离来获得相对于视觉和文本特征的重要性权重:
w
s
i
=
e
x
p
(
D
s
i
)
∑
j
=
1
K
e
x
p
(
D
s
j
)
(9)
w_{s_i}=\frac{exp(D_{s_i})}{\sum^{\mathcal K}_{j=1}exp(D_{s_j})}\tag{9}
wsi=∑j=1Kexp(Dsj)exp(Dsi)(9)
w
t
i
=
e
x
p
(
D
t
i
)
∑
j
=
1
K
e
x
p
(
D
t
j
)
(10)
w_{t_i}=\frac{exp(D_{t_i})}{\sum^{\mathcal K}_{j=1}exp(D_{t_j})}\tag{10}
wti=∑j=1Kexp(Dtj)exp(Dti)(10)
注意,在每个线程中应用上述步骤以模拟来自不同的存储表示子空间的存储查询。
Memory Responding。响应过程也以与查询过程对应的多线程方式进行。对于每个线程,我们首先在查询到的存储矢量上执行如下线性变换:
v
i
=
m
i
⋅
W
v
(11)
\textbf v_i=\textbf m_i\cdot \textbf W_v\tag{11}
vi=mi⋅Wv(11)
其中
W
v
\textbf W_v
Wv是用于
m
i
\textbf m_i
mi的可训练矩阵。因此,所有存储矢量
{
v
s
1
,
v
s
2
,
.
.
.
,
v
s
j
,
.
.
.
,
v
s
K
}
\{\textbf v_{s_1},\textbf v_{s_2},...,\textbf v_{s_j},...,\textbf v_{s_{\mathcal K}}\}
{vs1,vs2,...,vsj,...,vsK}被转移到
{
v
t
1
,
v
t
2
,
.
.
.
,
v
t
j
,
.
.
.
,
v
t
K
}
\{\textbf v_{t_1},\textbf v_{t_2},...,\textbf v_{t_j},...,\textbf v_{t_{\mathcal K}}\}
{vt1,vt2,...,vtj,...,vtK}中。然后,我们通过在转移的存储向量上加权来获得用于视觉和文本特征的存储器响应:
r
x
s
=
∑
i
=
1
K
w
s
i
v
s
i
(12)
\textbf r_{\textbf x_s}=\sum^{\mathcal K}_{i=1}w_{s_i}\textbf v_{s_i}\tag{12}
rxs=i=1∑Kwsivsi(12)
r
y
t
=
∑
i
=
1
K
w
t
i
v
t
i
(13)
\textbf r_{\textbf y_t}=\sum^{\mathcal K}_{i=1}w_{t_i}\textbf v_{t_i}\tag{13}
ryt=i=1∑Kwtivti(13)
其中,
w
s
i
w_{s_i}
wsi和
w
t
i
w_{t_i}
wti是从存储查询获得的权重。类似于存储查询,我们将存储应用于所有线程,以便从不同的存储表示子空间获取响应。
2.3 Encoder-Decoder
由于输入表示的质量在模型性能方面发挥着重要作用,因此我们模型中的编码器-解码器是在标准Transformer上构建的(这是一个强大的架构,在许多任务中实现了最先进的架构),其中视觉和文本特征的存储响应被用作编码器和解码器的输入,以增强生成过程。详细地,作为第一步,视觉特征的存储响应
{
r
x
1
,
r
x
2
,
.
.
.
,
r
x
S
}
\{\textbf r_{\textbf x_1},\textbf r_{\textbf x_2},...,\textbf r_{\textbf x_S}\}
{rx1,rx2,...,rxS}被送入到编码器中:
{
z
1
,
z
2
,
.
.
.
,
z
S
}
=
f
e
(
r
x
1
,
r
x
2
,
.
.
.
,
r
x
S
)
(14)
\{\textbf z_1,\textbf z_2,...,\textbf z_S\}=f_e(\textbf r_{\textbf x_1},\textbf r_{\textbf x_2},...,\textbf r_{\textbf x_S})\tag{14}
{z1,z2,...,zS}=fe(rx1,rx2,...,rxS)(14)
其中
f
e
(
⋅
)
f_e(·)
fe(⋅)表示编码器。然后将生成的中间状态
{
z
1
,
z
2
,
.
.
.
,
z
S
}
\{\textbf z_1,\textbf z_2,...,\textbf z_S\}
{z1,z2,...,zS}在每个解码步骤发送到解码器,与来自先前时刻的文本特征获取的存储响应
{
r
y
1
,
r
y
2
,
.
.
.
,
r
y
t
−
1
}
\{\textbf r_{y_1},\textbf r_{y_2},...,\textbf r_{y_{t-1}}\}
{ry1,ry2,...,ryt−1}一起,共同生成当前输出
y
t
y_t
yt:
y
t
=
f
d
(
z
1
,
z
2
,
.
.
.
,
z
S
,
r
y
1
,
r
y
2
,
.
.
.
,
r
y
t
−
1
)
(15)
y_t=f_d(\textbf z_1,\textbf z_2,...,\textbf z_S,\textbf r_{y_1},\textbf r_{y_2},...,\textbf r_{y_{t-1}})\tag{15}
yt=fd(z1,z2,...,zS,ry1,ry2,...,ryt−1)(15)
其中
f
d
(
⋅
)
f_d(·)
fd(⋅)表示解码器。因此,想要生成完整的报告,只重复上述过程直到生成完成。

















 2452
2452

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









