






摘要
normalizing flows提供了一种定义复杂概率分布的通用机制,仅需要指定一个基本分布(非常简单)和一系列双映射变换。最近有很多关于使用normalizing flows的工作,范围从提高建模复杂分布的能力到扩展应用。 我们认为该领域现在已经成熟,并且需要将观点进行统一。在这篇综述中,我们试图通过从概率建模和推理两个方面来描述这些观点。我们特别强调flow设计的基本原理,并讨论了诸如分布建模能力和计算效率之间平衡等基本主题。我们还通过将flow与更通用的概率变换联系起来,以扩展flow的概念框架。最后,我们总结了如何将flow用于生成式建模,近似推理和有监督学习等任务。
1.介绍
搜索一个明确指定的概率模型(即能正确描述生成数据过程的模型)是统计科学的持久理想之一。但是,只有最简单的设置才能实现这一目标。因此,所有统计学和机器学习的核心需求是提出一个允许定义任意概率分布的工具和理论,因此,这使得开发更加明确的模型成为可能。
本文回顾了我们用来解决此需求的一种工具:将概率分布作为normalizing flows构建。normalizing flows通过一系列变换将简单的概率密度映射到更丰富,更多模式的分布,这就像流过一组管子的液体。正如我们将看到的那样,重复将简单变换应用到一个单峰初始密度分布,会导致生成精细复杂的分布。这种灵活性意味着flow可以应用到建模,推理和仿真等关键统计任务中。
normalizing flows是机器学习研究中越来越活跃的领域。然而,目前缺乏统一的观点来理解最新工作与先前工作的关系。Papamakarios (2019) 的论文和Kobyzev et al. (2020) 的调查已经在建立这种更广泛理解上做出了努力。我们的综述对这些现有论文进行了补充。 特别是,我们对flows的观点比Papamakarios (2019)更全面,但共享一些基本原则。Kobyzev et al. (2020) 的文章在文献的覆盖范围和综合程度上值得称赞,同时讨论了有限流和无限流(就像我们一样),并在密度估计中组织了最新结果。我们的综述本质上是一种教程,并对Kobyzev et al. (2020) 中的几个被标记为开放问题的领域提供了深入的讨论(例如离散变量的扩展和黎曼流形)。
我们对标准化流的探索试图阐明一种原则,这些原则将指导其在可预见的未来的建设和应用。具体而言,我们的综述首先在第2节中建立normalizing flows的形式和概念结构。Flow的构建细节分别在第三节(有限流)和第四节(无限流)中进行了描述,然后在第5节中提出了更通用的观点,这又允许扩展到结构化领域和几何形状。 最后,我们在第6节中讨论了常见的应用。
Notation。我们使用粗体符号来表示向量(小写)和矩阵(大写),其余变量为标量。我们使用
P
r
(
⋅
)
Pr(·)
Pr(⋅)表示概率,使用
p
(
⋅
)
p(·)
p(⋅)表示概率密度。我们还将使用
p
(
⋅
)
p(·)
p(⋅)表示具有该密度函数的分布。我们经常向概率密度添加下标(例如
p
x
(
x
)
p_x(\textbf x)
px(x))强调它们所指的随机变量。符号
p
(
x
;
θ
)
p(\textbf x;\textbf θ)
p(x;θ)代表具有分布参数
θ
\textbf θ
θ的随机变量
x
\textbf x
x的分布。符号
∇
θ
∇_{\textbf θ}
∇θ代表梯度运算符,该梯度运算符收集所有与
θ
\textbf θ
θ相关的偏导数,即对于
K
K
K维参数有
∇
θ
f
=
[
∂
f
∂
θ
1
,
.
.
.
,
∂
f
∂
θ
K
]
∇_{\textbf θ}f=[\frac{∂f}{∂_{θ_1}},...,\frac{∂f}{∂_{θ_K}}]
∇θf=[∂θ1∂f,...,∂θK∂f]。函数
f
:
R
D
→
R
D
f:\mathbb R^D→\mathbb R^D
f:RD→RD的雅可比矩阵比被表示为
J
f
(
⋅
)
J_f(·)
Jf(⋅)。最后,我们使用符号
x
〜
p
(
x
)
\textbf x〜p(\textbf x)
x〜p(x)表示从分布
p
(
x
)
p(\textbf x)
p(x)中采样或模拟的变量
x
\textbf x
x。
2.Normalizing Flows
我们首先概述normalizing flows的基本定义和属性。我们建立了基于flow的模型的表现力,这解释了如何在实践中使用flows,并提供一些历史背景。本节不要求事先对normalizing flows熟悉,并且可以作为该领域的介绍。
2.1 Definition and Basics
normalizing flows提供了一种在连续随机变量上构建灵活概率分布的通用方法。令
x
\textbf x
x为
D
D
D维真实矢量,假设我们想定义
x
\textbf x
x上的联合分布。基于flow建模的主要思想是将
x
\textbf x
x表示为从
p
u
(
u
)
p_u(\textbf u)
pu(u)中采样的真实向量
u
\textbf u
u的变换
T
T
T:
x
=
T
(
u
)
w
h
e
r
e
u
∼
p
u
(
u
)
.
(1)
\textbf x=T(\textbf u)\quad where\quad \textbf u\sim p_u(\textbf u).\tag{1}
x=T(u)whereu∼pu(u).(1)
我们将
p
u
(
u
)
p_u(\textbf u)
pu(u)称为flow模型的基本分布。变换
T
T
T和基本分布
p
u
(
u
)
p_u(\textbf u)
pu(u)可以具有自己的参数(分别为
ϕ
\phi
ϕ和
ψ
ψ
ψ);这产生了由
{
ϕ
,
ψ
}
\{\phi,ψ\}
{ϕ,ψ}参数化的
x
\textbf x
x上的一系列分布。
flow模型的一个属性是变换
T
T
T必须是可逆的,且
T
T
T和
T
−
1
T^{-1}
T−1必须是可微分的。这种变换被称为diffeomorphisms(可微分变换),同样也要求
u
\textbf u
u是D维的。在这些条件下,
x
\textbf x
x的密度分布定义明确,且可以通过变量变换来获得:
p
x
(
x
)
=
p
u
(
u
)
∣
d
e
t
J
T
(
u
)
∣
−
1
w
h
e
r
e
u
=
T
−
1
(
x
)
.
(2)
p_x(\textbf x)=p_u(\textbf u)|det~J_T(\textbf u)|^{-1}\quad where\quad \textbf u=T^{-1}(\textbf x).\tag{2}
px(x)=pu(u)∣det JT(u)∣−1whereu=T−1(x).(2)
同样地,我们还可以根据
T
−
1
T^{-1}
T−1的雅可比矩阵来编写
p
x
(
x
)
p_x(\textbf x)
px(x):
p
x
(
x
)
=
p
u
(
T
−
1
(
x
)
)
∣
d
e
t
J
T
−
1
(
x
)
∣
.
(3)
p_x(\textbf x)=p_u(T^{-1}(\textbf x))|det~J_{T^{-1}}(\textbf x)|.\tag{3}
px(x)=pu(T−1(x))∣det JT−1(x)∣.(3)
雅可比矩阵
J
T
(
u
)
J_T(\textbf u)
JT(u)是
T
T
T的所有偏导数组成的
D
×
D
D\times D
D×D矩阵:
J
T
(
u
)
=
[
∂
T
1
∂
u
1
⋯
∂
T
1
∂
u
D
⋮
⋱
⋮
∂
T
D
∂
u
1
⋯
∂
T
D
∂
u
D
]
.
(3)
J_T(\textbf u)=\left[ \begin{matrix} \frac{∂T_1}{∂u_1} & \cdots & \frac{∂T_1}{∂u_D} \\ \vdots & \ddots & \vdots \\ \frac{∂T_D}{∂u_1} & \cdots & \frac{∂T_D}{∂u_D} \end{matrix} \right]. \tag{3}
JT(u)=⎣⎢⎡∂u1∂T1⋮∂u1∂TD⋯⋱⋯∂uD∂T1⋮∂uD∂TD⎦⎥⎤.(3)
实际上,我们通常通过使用神经网络来实现
T
T
T(或
T
−
1
T^{-1}
T−1),以构建基于流的模型,并将
p
u
(
u
)
p_u(\textbf u)
pu(u)作为一个简单密度分布,例如多元正态分布。在第3和4节中,我们将详细讨论如何实现
T
T
T(或
T
−
1
T^{-1}
T−1)。
直观上,我们可以将变换
T
T
T视为对空间
R
D
\mathbb R^D
RD的扭曲,以将分布
p
u
(
u
)
p_u(\textbf u)
pu(u)变换到
p
x
(
x
)
p_x(\textbf x)
px(x)中。雅可比行列式的绝对值
∣
d
e
t
J
T
(
u
)
∣
|det~J_T(\textbf u)|
∣det JT(u)∣量化了由
T
T
T导致的
u
\textbf u
u的一个极小空间的相对变化。即,令
du
\textbf {du}
du为
u
\textbf u
u附近的一个较小空间,
dx
\textbf {dx}
dx为
x
\textbf x
x附近的一个较小空间,且由
du
\textbf {du}
du变换得到。然后,我们有
∣
d
e
t
J
T
(
u
)
∣
≈
V
o
l
(
dx
)
/
V
o
l
(
du
)
|det~J_T(\textbf u)|\approx Vol(\textbf {dx})/Vol(\textbf {du})
∣det JT(u)∣≈Vol(dx)/Vol(du),即
dx
\textbf {dx}
dx的大小除以
du
\textbf {du}
du的大小。同时,
dx
\textbf {dx}
dx中的概率质量必须等于
du
\textbf {du}
du中的概率质量。 因此,如果
d
u
\textbf du
du被扩展,则
x
\textbf x
x处的密度小于
u
\textbf u
u处的密度。 如果
d
u
\textbf du
du收缩,则
x
\textbf x
x处的密度更大。
可逆和可微分变换的一个重要属性是可组合的。给定两个这样的变换
T
1
T_1
T1和
T
2
T_2
T2,它们的组合
T
2
◦
T
1
T_2◦T_1
T2◦T1也是可逆的和可微分的。它的逆和雅各比行列式如下所示:
(
T
2
◦
T
1
)
−
1
=
T
1
−
1
◦
T
2
−
1
(5)
(T_2◦T_1)^{-1}=T^{-1}_1◦T^{-1}_2\tag{5}
(T2◦T1)−1=T1−1◦T2−1(5)
d
e
t
J
T
2
◦
T
1
(
u
)
=
d
e
t
J
T
2
(
T
1
(
u
)
)
⋅
d
e
t
J
T
1
(
u
)
.
(6)
det~J_{T_2◦T_1}(\textbf u)=det~J_{T_2}(T_1(\textbf u))\cdot det~J_{T_1}(\textbf u).\tag{6}
det JT2◦T1(u)=det JT2(T1(u))⋅det JT1(u).(6)
因此,我们可以通过组合多个简单变换来构建复杂变换,而不会损害可逆性和可微分的要求,因此也不会失去计算密度
p
x
(
x
)
p_x(\textbf x)
px(x)的能力。
在实践中,通常将多个变换
T
1
,
.
.
.
,
T
K
T_1,...,T_K
T1,...,TK结合在一起来获得
T
=
T
K
◦
⋯
◦
T
1
T=T_K◦\cdots ◦T_1
T=TK◦⋯◦T1是很常见的,其中每个
T
k
T_k
Tk将
z
k
−
1
\textbf z_{k-1}
zk−1转换为
z
k
\textbf z_k
zk,假设
z
0
=
u
\textbf z_0=\textbf u
z0=u且
z
K
=
x
\textbf z_K=\textbf x
zK=x。因此,术语“‘flow’”是指从
p
u
(
u
)
p_u(\textbf u)
pu(u)中获得的样本集通过变换序列
T
1
,
.
.
.
,
T
K
T_1,...,T_K
T1,...,TK逐渐发生变换的轨迹。“normalizing”是指从
p
x
(
x
)
p_x(\textbf x)
px(x)中获得的样本集通过逆flow序列
T
K
−
1
,
.
.
.
,
T
1
−
1
T^{-1}_K,...,T^{-1}_1
TK−1,...,T1−1,将其转换为服从密度
p
u
(
u
)
p_u(\textbf u)
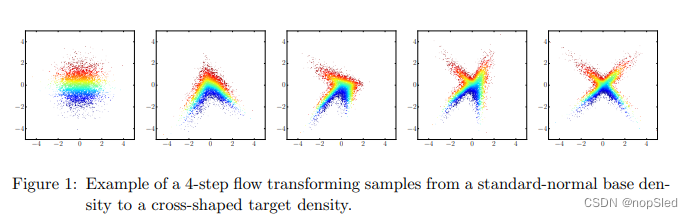
pu(u)的样品集(通常被认为是多元正态分布 )。图1说明了将标准正态基本分布转换为十字形状的目标密度的flow(
K
=
4
K=4
K=4)。
在功能方面,基于flow的模型提供了两个操作:通过公式(1)从模型中进行采样,或者通过公式(3)来评估模型的密度。这些操作具有不同的计算要求。从模型采样要求具有从
p
u
(
u
)
p_u(\textbf u)
pu(u)采样并计算正向变换
T
T
T的能力。评估模型密度要求具有计算逆向变换
T
−
1
T^{-1}
T−1和其雅可比行列式,并评估密度
p
u
(
u
)
p_u(\textbf u)
pu(u)的能力。这种应用将决定需要采用哪些操作以及它们需要的效率。我们在第3和4节中使用各种实现方式讨论了相关的操作和计算的权衡。
2.2 Expressive Power of Flow-Based Models
在讨论flows的细节之前,最重要的问题是:基于flow模型的表现性如何? 即使基本分布简单,它们也可以表示任何分布
p
x
(
x
)
p_x(\textbf x)
px(x)吗?我们表明,在
p
x
(
x
)
p_x(\textbf x)
px(x)具有合理条件的情况下,这种通用表示是可能的。具体而言,我们将证明,对于任何一对目标分布
p
x
(
x
)
p_x(\textbf x)
px(x)和基本分布
p
u
(
u
)
p_u(\textbf u)
pu(u),存在将
p
u
(
u
)
p_u(\textbf u)
pu(u)变成
p
x
(
x
)
p_x(\textbf x)
px(x)的可微分变换。该论点是建设性的,是基于Hyv¨arinen and Pajunen (1999) 的非线性ICA存在的类似证明。
假设对于所有的
x
∈
R
D
\textbf x∈\mathbb R^D
x∈RD,有
p
x
(
x
)
>
0
p_x(\textbf x)>0
px(x)>0,并假设所有条件概率
P
r
(
x
i
′
≤
x
i
∣
x
<
i
)
Pr(x'_i≤x_i|\textbf x_{<i})
Pr(xi′≤xi∣x<i)相对于
(
x
i
,
x
<
i
)
(x_i,\textbf x_{\lt i})
(xi,x<i)是可微分的。使用概率链式法则,我们可以将
p
x
(
x
)
p_x(\textbf x)
px(x)分解为条件密度的乘积,如下所示:
p
x
(
x
)
=
∏
i
=
1
D
p
x
(
x
i
∣
x
<
i
)
.
(7)
p_x(\textbf x)=\prod^D_{i=1}p_x(x_i|\textbf x_{\lt i}).\tag{7}
px(x)=i=1∏Dpx(xi∣x<i).(7)
由于
p
x
(
x
)
p_x(\textbf x)
px(x)每一个地方都是非零的,即
p
x
(
x
i
∣
x
<
i
)
>
0
p_x(x_i|\textbf x_{\lt i})\gt 0
px(xi∣x<i)>0。接下来,定义变换
F
:
x
↦
z
∈
(
0
,
1
)
D
F:\textbf x\mapsto \textbf z∈(0,1)^D
F:x↦z∈(0,1)D,其第
i
i
i个元素由第
i
i
i个条件密度的累积分布函数(CDF)给出:
z
i
=
F
i
(
x
i
,
x
<
i
)
=
∫
−
∞
x
i
p
x
(
x
i
′
∣
x
<
i
)
d
x
i
′
=
P
r
(
x
i
′
≤
x
i
∣
x
<
i
)
.
(8)
z_i=F_i(x_i,\textbf x_{\lt i})=\int^{x_i}_{-∞}p_x(x'_i|\textbf x_{\lt i})dx'_i=Pr(x'_i\le x_i|\textbf x_{\lt i}).\tag{8}
zi=Fi(xi,x<i)=∫−∞xipx(xi′∣x<i)dxi′=Pr(xi′≤xi∣x<i).(8)
由于每个
F
i
F_i
Fi相对于其输入都是可微分的,因此相对于
x
\textbf x
x也是可微分的。并且,每个
F
i
(
⋅
,
x
<
i
)
:
R
↦
(
0
,
1
)
F_i(·,\textbf x_{<i}):\mathbb R\mapsto (0,1)
Fi(⋅,x<i):R↦(0,1)是可逆的,因为它的导数
∂
F
i
∂
x
i
=
p
x
(
x
i
∣
x
<
i
)
\frac{∂F_i}{∂x_i}=p_x(x_i|\textbf x_{<i})
∂xi∂Fi=px(xi∣x<i)都是正的。因为
z
i
z_i
zi不依赖于
i
<
j
i<j
i<j的
x
j
x_j
xj,这意味着我们可以反转
F
F
F,其对每个元素的逆
F
i
−
1
F^{-1}_i
Fi−1如下:
x
i
=
(
F
i
(
⋅
,
x
<
i
)
)
−
1
(
z
i
)
f
o
r
i
=
1
,
.
.
.
,
D
.
(9)
x_i=(F_i(·,\textbf x_{\lt i}))^{-1}(z_i)\quad for~i=1,...,D.\tag{9}
xi=(Fi(⋅,x<i))−1(zi)for i=1,...,D.(9)
F
F
F的雅可比矩阵是下三角形矩阵,因为丢
i
<
j
i<j
i<j,有
∂
F
i
∂
x
j
=
0
\frac{∂F_i}{∂x_j}=0
∂xj∂Fi=0。因此,
F
F
F的雅可比行列式等于其对角线元素的乘积:
d
e
t
J
F
(
x
)
=
∏
i
=
1
D
∂
F
i
∂
x
i
=
∏
i
=
1
D
p
x
(
x
i
∣
x
<
i
)
=
p
x
(
x
)
.
(10)
det~J_F(\textbf x)=\prod^D_{i=1}\frac{∂F_i}{∂x_i}=\prod^D_{i=1}p_x(x_i|x_{\lt i})=p_x(\textbf x).\tag{10}
det JF(x)=i=1∏D∂xi∂Fi=i=1∏Dpx(xi∣x<i)=px(x).(10)
由于
p
x
(
x
)
>
0
p_x(\textbf x)>0
px(x)>0,因此雅可比行列式是非零的。因此,存在
J
F
(
x
)
J_F(\textbf x)
JF(x)的逆,等于
F
−
1
F^{-1}
F−1的雅可比矩阵,因此
F
F
F是可微分变换。使用变量变换定理,我们可以按以下方式计算
z
z
z的密度:
p
z
(
z
)
=
p
x
(
x
)
∣
d
e
t
J
F
(
x
)
∣
−
1
=
p
x
(
x
)
∣
p
x
(
x
)
∣
−
1
=
1
,
(11)
p_z(\textbf z)=p_x(\textbf x)|det~J_F(\textbf x)|^{-1}=p_x(\textbf x)|p_x(\textbf x)|^{-1}=1,\tag{11}
pz(z)=px(x)∣det JF(x)∣−1=px(x)∣px(x)∣−1=1,(11)
这意味着
z
\textbf z
z在
(
0
,
1
)
D
(0,1)^D
(0,1)D中服从均匀分布。
上述观点表明,即使我们将基本分布限制为
(
0
,
1
)
D
(0,1)^D
(0,1)D中的均匀分布,基于流的模型也可以表达任何分布
p
x
(
x
)
p_x(\textbf x)
px(x)(满足上述条件)。我们可以首先将
u
\textbf u
u变换到均匀分布
z
∈
(
0
,
1
)
D
\textbf z\in(0,1)^D
z∈(0,1)D,以作为中间步骤,从而将此观点扩展到任何基本分布
p
u
(
u
)
p_u(\textbf u)
pu(u)(满足与
p
x
(
x
)
p_x(\textbf x)
px(x)相同的条件)。特别地,对于任何满足上述条件的
p
u
(
u
)
p_u(\textbf u)
pu(u),可以将
G
G
G定义为以下变换:
z
i
=
G
i
(
u
i
,
u
<
i
)
=
∫
−
∞
u
i
p
u
(
u
i
′
∣
u
<
i
)
d
u
i
′
=
P
r
(
u
i
′
≤
u
i
∣
u
<
i
)
.
(12)
z_i=G_i(u_i,\textbf u_{\lt i})=\int^{u_i}_{-∞}p_u(u'_i|\textbf u_{\lt i})du'_i=Pr(u'_i\le u_i|\textbf u_{\lt i}).\tag{12}
zi=Gi(ui,u<i)=∫−∞uipu(ui′∣u<i)dui′=Pr(ui′≤ui∣u<i).(12)
通过与上述相同的观点,
G
G
G是可微分变换,
z
\textbf z
z在
(
0
,
1
)
D
(0,1)^D
(0,1)D中服从均匀分布。因此,带有变换
T
=
F
−
1
T=F^{-1}
T=F−1的flow可以将
p
u
(
u
)
p_u(\textbf u)
pu(u)变成
p
x
(
x
)
p_x(\textbf x)
px(x)。
2.3 Using Flows for Modeling and Inference
与拟合任何概率模型类似,将一个基于flow的模型 p x ( x ; θ ) p_x(\textbf x;\textbf θ) px(x;θ)拟合到目标分布 p x ∗ ( x ) p^*_x(\textbf x) px∗(x)是可以通过最小化它们之间的散度或差异来完成。最小化是通过优化模型参数 θ = { ϕ , ψ } \textbf θ=\{\textbf ϕ, \textbf ψ\} θ={ϕ,ψ}来完成的,其中 ϕ \textbf ϕ ϕ是变换 T T T的参数, ψ \textbf ψ ψ是基本分布 p u ( u ) p_u(\textbf u) pu(u)的参数。在以下各节中,我们讨论了一些用于拟合flow模型的散度,特别关注Kullback–Leibler (KL)散度,因为它是最受欢迎的选择之一。
2.3.1 Forward KL Divergence and Maximum Likelihood Estimation
目标分布
p
x
∗
(
x
)
p^∗_x(\textbf x)
px∗(x)与基于flow的模型
p
x
(
x
;
θ
)
p_x(\textbf x;\textbf θ)
px(x;θ)之间的前向KL散度可以写为如下所示:
L
(
θ
)
=
D
K
L
[
p
x
∗
(
x
)
∣
∣
p
x
(
x
;
θ
)
]
=
−
E
p
x
∗
(
x
)
[
l
o
g
p
x
(
x
;
θ
)
]
+
c
o
n
s
t
.
=
−
E
p
x
∗
(
x
)
[
l
o
g
p
u
(
T
−
1
(
x
;
ϕ
)
;
ψ
)
+
l
o
g
∣
d
e
t
J
T
−
1
(
x
;
ϕ
)
∣
]
+
c
o
n
s
t
.
(13)
\mathcal L(\textbf θ)=D_{KL}[p^*_x(\textbf x)||p_x(\textbf x;\textbf θ)]\\ =-\mathbb E_{p^*_x(\textbf x)}[log~p_x(\textbf x;\textbf θ)]+const.\tag{13}\\ =-\mathbb E_{p^*_x(\textbf x)}[log~p_u(T^{-1}(\textbf x;\textbf ϕ);\textbf ψ)+log~|det~J_{T^{-1}}(\textbf x;\textbf ϕ)|]+const.
L(θ)=DKL[px∗(x)∣∣px(x;θ)]=−Epx∗(x)[log px(x;θ)]+const.=−Epx∗(x)[log pu(T−1(x;ϕ);ψ)+log ∣det JT−1(x;ϕ)∣]+const.(13)
前向KL散度非常适合我们从目标分布采样(或生成它们)的情况,但是我们不一定能够评估目标密度
p
x
∗
(
x
)
p^∗_x(\textbf x)
px∗(x)。假设我们有有一组来自
p
x
∗
(
x
)
p^∗_x(\textbf x)
px∗(x)中的样本集
{
x
n
}
n
=
1
N
\{\textbf x_n\}^N_{n=1}
{xn}n=1N,我们可以通过蒙特卡洛(Monte Carlo)来估计
p
x
∗
(
x
)
p^∗_x(\textbf x)
px∗(x)的期望,如下所示:
L
(
θ
)
≈
−
1
N
∑
n
=
1
N
l
o
g
p
u
(
T
−
1
(
x
n
;
ϕ
)
;
ψ
)
+
l
o
g
∣
d
e
t
J
T
−
1
(
x
n
;
ϕ
)
∣
+
c
o
n
s
t
.
(14)
\mathcal L(\textbf θ)\approx -\frac{1}{N}\sum^N_{n=1}log~p_u(T^{-1}(\textbf x_n;\textbf ϕ);\textbf ψ)+log~|det ~J_{T^{-1}}(\textbf x_n;\textbf ϕ)|+const.\tag{14}
L(θ)≈−N1n=1∑Nlog pu(T−1(xn;ϕ);ψ)+log ∣det JT−1(xn;ϕ)∣+const.(14)
最小化上述KL散度的蒙特卡洛近似相当于通过最大似然估计将基于flow的模型拟合到样本集上
{
x
n
}
n
=
1
N
\{\textbf x_n\}^N_{n=1}
{xn}n=1N。
实际上,我们通常使用基于随机梯度的方法在迭代中优化参数
θ
\textbf θ
θ。我们可以获得KL散度相对于参数的无偏梯度估计,如下所示:
∇
ϕ
L
(
θ
)
=
1
N
∑
n
=
1
N
∇
ϕ
l
o
g
p
u
(
T
−
1
(
x
n
;
ϕ
)
;
ψ
)
+
∇
ϕ
l
o
g
∣
d
e
t
J
T
−
1
(
x
n
;
ϕ
)
∣
(15)
\nabla_{\textbf ϕ}\mathcal L(\textbf θ)=\frac{1}{N}\sum^N_{n=1}\nabla_{\textbf ϕ}log~p_u(T^{-1}(\textbf x_n;\textbf ϕ);\textbf ψ)+\nabla_{\textbf ϕ}log~|det~J_{T^{-1}}(\textbf x_n;\textbf ϕ)|\tag{15}
∇ϕL(θ)=N1n=1∑N∇ϕlog pu(T−1(xn;ϕ);ψ)+∇ϕlog ∣det JT−1(xn;ϕ)∣(15)
∇
ψ
L
(
θ
)
=
1
N
∑
n
=
1
N
∇
ψ
l
o
g
p
u
(
T
−
1
(
x
n
;
ϕ
)
;
ψ
)
.
(16)
\nabla_{\textbf ψ}\mathcal L(\textbf θ)=\frac{1}{N}\sum^N_{n=1}\nabla_{\textbf ψ}log~p_u(T^{-1}(\textbf x_n;\textbf ϕ);\textbf ψ).\tag{16}
∇ψL(θ)=N1n=1∑N∇ψlog pu(T−1(xn;ϕ);ψ).(16)
如果
p
u
(
u
;
ψ
)
p_u(\textbf u;\textbf ψ)
pu(u;ψ)接受闭式的最大似然估计,那么关于
ψ
\textbf ψ
ψ的更新也可以以闭式进行,例如高斯分布的情况。
为了通过最大似然拟合基于flow的模型,我们需要计算
T
−
1
T^{-1}
T−1,其雅可比行列式以及密度分布
p
u
(
u
;
ψ
)
p_u(\textbf u;\textbf ψ)
pu(u;ψ),如果使用基于梯度的优化,则可以对这三项进行微分。这意味着即使我们无法计算
T
T
T或从
p
u
(
u
;
ψ
)
p_u(\textbf u;\textbf ψ)
pu(u;ψ)中采样,我们也可以训练具有最大似然的flow模型。但是,如果我们要在模型拟合后从模型中采样
x
\textbf x
x,则仍然需要这些操作。
2.3.2 Reverse KL Divergence
另外,我们可以通过最小化反向KL散度来拟合基于flow的模型,这可以写为:
L
(
θ
)
=
D
K
L
[
p
x
(
x
;
θ
)
∣
∣
p
x
∗
(
x
)
]
=
E
p
x
(
x
;
θ
)
[
l
o
g
p
x
(
x
;
θ
)
−
l
o
g
p
x
∗
(
x
)
]
=
E
p
u
(
u
;
ψ
)
[
l
o
g
p
x
(
u
;
ψ
)
−
l
o
g
∣
d
e
t
J
T
(
u
;
ϕ
)
∣
−
l
o
g
p
x
∗
(
T
(
u
;
ϕ
)
)
]
.
(17)
\mathcal L(\textbf θ)=D_{KL}[p_x(\textbf x;\textbf θ)||p^*_x(\textbf x)]\\ =\mathbb E_{p_x(\textbf x;\textbf θ)}[log~p_x(\textbf x;\textbf θ)-log~p^*_x(\textbf x)]\\ =\mathbb E_{p_u(\textbf u;\textbf ψ)}[log~p_x(\textbf u;\textbf ψ)-log~|det~J_T(\textbf u;\textbf ϕ)|-log~p^*_x(T(\textbf u;\textbf ϕ))].\tag{17}
L(θ)=DKL[px(x;θ)∣∣px∗(x)]=Epx(x;θ)[log px(x;θ)−log px∗(x)]=Epu(u;ψ)[log px(u;ψ)−log ∣det JT(u;ϕ)∣−log px∗(T(u;ϕ))].(17)
我们利用变量变换,以表示对
u
\textbf u
u的期望。当我们有能力评估目标密度
p
x
∗
(
x
)
p^*_x(\textbf x)
px∗(x),且不用从中采样时,反向KL散度是适合的。实际上,即使我们将
p
x
∗
(
x
)
p^*_x(\textbf x)
px∗(x)评估为乘法归一化常数
C
C
C,我们也可以最小化
L
(
θ
)
\mathcal L(\textbf θ)
L(θ),因为在这种情况下,
l
o
g
C
log~C
log C将是上述表达式
L
(
θ
)
\mathcal L(\textbf θ)
L(θ)中的加法常数。因此,我们可以假设
p
x
∗
(
x
)
=
p
~
x
(
x
)
/
C
p^∗_x(\textbf x)=\widetilde{p}_x(\textbf x)/C
px∗(x)=p
x(x)/C,其中
p
~
x
(
x
)
\widetilde{p}_x(\textbf x)
p
x(x)是可处理的,但是
C
=
∫
p
~
x
(
x
)
d
x
C=\int \widetilde{p}_x(\textbf x)d\textbf x
C=∫p
x(x)dx不是,并将反向KL散度重写为:
L
(
θ
)
=
E
p
u
(
u
;
ψ
)
[
l
o
g
p
x
(
u
;
ψ
)
−
l
o
g
∣
d
e
t
J
T
(
u
;
ϕ
)
∣
−
l
o
g
p
~
x
(
T
(
u
;
ϕ
)
)
]
+
c
o
n
s
t
.
(18)
\mathcal L(\textbf θ)=\mathbb E_{p_u(\textbf u;\textbf ψ)}[log~p_x(\textbf u;\textbf ψ)-log~|det~J_T(\textbf u;\textbf ϕ)|-log~\widetilde p_x(T(\textbf u;\textbf ϕ))]+const.\tag{18}
L(θ)=Epu(u;ψ)[log px(u;ψ)−log ∣det JT(u;ϕ)∣−log p
x(T(u;ϕ))]+const.(18)
实际上,我们可以使用基于随机梯度的方法将
L
(
θ
)
\mathcal L(\textbf θ)
L(θ)迭代最小化。由于我们将期望重参数化为与基本分布
p
u
(
u
;
ψ
)
p_u(\textbf u;\textbf ψ)
pu(u;ψ)相关,因此我们可以通过蒙特卡洛来获得
L
(
θ
)
\mathcal L(\textbf θ)
L(θ)相对于
ϕ
\textbf ϕ
ϕ梯度的无偏估计。特别是,令
{
u
n
}
n
=
1
N
\{\textbf u_n\}^N_{n=1}
{un}n=1N为从
p
u
(
u
;
ψ
)
p_u(\textbf u;\textbf ψ)
pu(u;ψ)采样的一组样本,
L
(
θ
)
\mathcal L(\textbf θ)
L(θ)相对于
ϕ
\textbf ϕ
ϕ梯度可以估计如下:
∇
ϕ
L
θ
≈
−
1
N
∑
n
=
1
N
∇
ϕ
l
o
g
∣
d
e
t
J
T
(
u
;
ϕ
)
∣
+
∇
ϕ
l
o
g
p
~
x
(
T
(
u
;
ϕ
)
)
.
(19)
\nabla_{\textbf ϕ}\mathcal L{\textbf θ}\approx -\frac{1}{N}\sum^N_{n=1}\nabla_{\textbf ϕ}log~|det~J_T(\textbf u;\textbf ϕ)|+\nabla_{\textbf ϕ}log~\widetilde p_x(T(\textbf u;\textbf ϕ)).\tag{19}
∇ϕLθ≈−N1n=1∑N∇ϕlog ∣det JT(u;ϕ)∣+∇ϕlog p
x(T(u;ϕ)).(19)
类似地,我们可以重参数化
u
\textbf u
u来估计与
ψ
\textbf ψ
ψ相关的梯度:
u
=
T
′
(
u
′
;
ψ
)
w
h
e
r
e
u
′
∼
p
u
′
(
u
′
)
,
(20)
\textbf u=T'(\textbf u';\textbf ψ)\quad where\quad u'\sim p_{u'}(\textbf u'),\tag{20}
u=T′(u′;ψ)whereu′∼pu′(u′),(20)
然后将期望写成与
p
u
′
(
u
′
)
p_{u'}(\textbf u')
pu′(u′)相关。但是,由于我们可以等效地将重参数化
T
′
T'
T′包含到
T
T
T中,并用
p
u
′
(
u
′
)
p_{u'}(\textbf u')
pu′(u′)替换基本分布,因此我们可以假设而不失一般性,即参数
ψ
\textbf ψ
ψ是固定的,并且仅用对
ϕ
\textbf ϕ
ϕ进行优化。
为了最小化上述反向KL散度,我们需要能够从基本分布
p
u
(
u
;
ψ
)
p_u(\textbf u;\textbf ψ)
pu(u;ψ)中采样,并通过变换
T
T
T及其雅可比行列式进行计算和微分。这意味着我们可以通过最小化反向KL散度来拟合基于flow的模型,即使我们无法评估基本密度或计算逆变换
T
−
1
T^{-1}
T−1。但是,如果我们想评估受过训练的模型的密度,我们将需要这些操作。
反向KL散度通常用于变分推断,这是一种贝叶斯推断的近似形式。在这种情况下,目标是计算后验
p
x
∗
(
x
)
p^∗_x(\textbf x)
px∗(x),以作为似然函数和先验密度之间的产物。
有关flow在变分推断中的应用样例可以参考Rezende and Mohamed (2015); van den Berg et al. (2018); Kingma et al. (2016); Tomczak and Welling (2016); Louizos and Welling (2017)。我们在第6.2.3节中更详细地介绍此主题。
反向KL散度的另一个应用是在模型蒸馏的场景:训练一个flow模型,以替换可以进行密度评估但不是很方便的目标模型
p
x
∗
(
x
)
p^*_x(\textbf x)
px∗(x)。van den Oord et al. (2018)等人给出了用flow蒸馏的一个示例。 在他们的情况下,不能有效地从目标模型中采样样本,因此它们将其蒸馏成支持快速采样的flow。
2.3.3 Relationship Between Forward and Reverse KL Divergence
基于flow模型的另一种理解方法是将目标
p
x
∗
(
x
)
p^∗_x(\textbf x)
px∗(x)视为基本分布,逆flow则作为分布
p
u
∗
(
u
;
ϕ
)
p^∗_u(\textbf u;\textbf ϕ)
pu∗(u;ϕ)的推导。直觉上,
p
u
∗
(
u
;
ϕ
)
p^∗_u(\textbf u;\textbf ϕ)
pu∗(u;ϕ)是通过
T
−
1
T^{-1}
T−1变换时训练数据将遵循的分布。由于目标和基本分布在给定它们之间变换的情况下,彼此唯一确定,因此,
p
u
∗
(
u
;
ϕ
)
=
p
u
(
u
;
ψ
)
p^∗_u(\textbf u;\textbf ϕ)=p_u(\textbf u;\textbf ψ)
pu∗(u;ϕ)=pu(u;ψ),仅且仅当
p
x
∗
(
x
)
=
p
x
(
x
;
θ
)
\textbf p^∗_x(\textbf x)=p_x(\textbf x;\textbf θ)
px∗(x)=px(x;θ)。因此,将模型
p
x
(
x
;
θ
)
p_x(\textbf x;\textbf θ)
px(x;θ)拟合到目标
p
x
∗
(
x
)
\textbf p^∗_x(\textbf x)
px∗(x),可以等价为将推导分布
p
u
∗
(
u
;
ϕ
)
p^∗_u(\textbf u;\textbf ϕ)
pu∗(u;ϕ)拟合到基础
p
u
(
u
;
ψ
)
p_u(\textbf u;\textbf ψ)
pu(u;ψ)中。
我们现在可能会问:将
p
x
(
x
;
θ
)
p_x(\textbf x;\textbf θ)
px(x;θ)拟合到目标分布与将
p
u
∗
(
u
;
ϕ
)
p^∗_u(\textbf u;\textbf ϕ)
pu∗(u;ϕ)拟合到基本分布有何关系?使用变量变换,我们可以得到以下等式(有关详细信息,请参见附录A):
D
K
L
[
p
x
∗
(
x
)
∣
∣
p
x
(
x
∣
θ
)
]
=
D
K
L
[
p
u
∗
(
u
;
ϕ
)
∣
∣
p
u
(
u
;
ψ
)
]
.
(21)
D_{KL}[p^*_x(\textbf x)||p_x(\textbf x|\textbf θ)]=D_{KL}[p^*_u(\textbf u;\textbf ϕ)||p_u(\textbf u;\textbf ψ)].\tag{21}
DKL[px∗(x)∣∣px(x∣θ)]=DKL[pu∗(u;ϕ)∣∣pu(u;ψ)].(21)
上述等式说明,使用正向KL散度(最大似然)将模型拟合到目标等同于通过反向KL散度将推导分布
p
u
∗
(
u
;
ϕ
)
p^∗_u(\textbf u;\textbf ϕ)
pu∗(u;ϕ)拟合到基本分布
p
u
(
u
;
ψ
)
p_u(\textbf u;\textbf ψ)
pu(u;ψ)。在附录中,我们还表明:
D
K
L
[
p
x
(
x
;
θ
)
∣
∣
p
x
∗
(
x
)
]
=
D
K
L
[
p
u
(
u
;
ψ
)
∣
∣
p
u
∗
(
u
;
ϕ
)
]
,
(22)
D_{KL}[p_x(\textbf x;θ)||p^*_x(\textbf x)]=D_{KL}[p_u(\textbf u;\textbf ψ)||p^*_u(\textbf u;\textbf ϕ)],\tag{22}
DKL[px(x;θ)∣∣px∗(x)]=DKL[pu(u;ψ)∣∣pu∗(u;ϕ)],(22)
这意味着通过反向KL散度将模型拟合到目标分布等同于通过正向KL散度(最大似然)将推导分布
p
u
∗
(
u
;
ϕ
)
p^∗_u(\textbf u;\textbf ϕ)
pu∗(u;ϕ)拟合到基本分布
p
u
(
u
;
ψ
)
p_u(\textbf u;\textbf ψ)
pu(u;ψ)。
2.3.4 Alternative Divergences
flow模型参数的学习不限于使用KL散度。分布之间差异的测量有许多替代的方法。这些替代方案通常分为两个通用类别,f-divergences使用密度比进行比较,integral probability metrics(IPMs)使用差值进行比较:
f
−
d
i
v
e
r
g
e
n
c
e
D
f
[
p
x
∗
(
x
)
∣
∣
p
x
(
x
;
θ
)
]
=
E
p
x
(
x
;
θ
)
[
f
(
p
x
∗
(
x
)
p
x
(
x
;
θ
)
)
]
(23)
f-divergence \qquad D_f[p^*_x(x)||p_x(\textbf x;\textbf θ)]=\mathbb E_{p_x(\textbf x;\textbf θ)}\bigg [f(\frac{p^*_x(\textbf x)}{p_x(\textbf x;\textbf θ)})\bigg ]\tag{23}
f−divergenceDf[px∗(x)∣∣px(x;θ)]=Epx(x;θ)[f(px(x;θ)px∗(x))](23)
I
P
M
δ
s
[
p
x
∗
(
x
)
∣
∣
p
x
(
x
;
θ
)
]
=
E
p
x
∗
(
x
)
[
s
(
x
)
]
−
E
p
x
(
x
;
θ
)
[
s
(
x
)
]
.
(24)
IPM\qquad \delta_s[p^*_x(x)||p_x(\textbf x;\textbf θ)]=\mathbb E_{p^*_x(\textbf x)}[s(\textbf x)]-\mathbb E_{p_x(\textbf x;\textbf θ)}[s(\textbf x)].\tag{24}
IPMδs[px∗(x)∣∣px(x;θ)]=Epx∗(x)[s(x)]−Epx(x;θ)[s(x)].(24)
对于f-divergences,函数
f
f
f为凸函数,当此函数为
f
(
r
)
=
r
l
o
g
r
f(r)=r~log~r
f(r)=r log r时,则恢复为KL散度。对于IPM,可以从一组测试统计数据中选择该函数
s
s
s,也可以是对抗选择的witness函数。
无论先前的KL散度以及当前可选的散度都需考虑:我们是否可以从模型
p
x
(
x
;
θ
)
p_x(\textbf x;\textbf θ)
px(x;θ)中仿真,我们是否知道乘法常数的真实分布,我们是否可以使用该分布的变换或其逆变换? 在考虑这些散度时,我们会看到基于flow的模型(其设计原理都使用组合和变量变化)与更通用的隐式概率模型类别之间的联系。如果我们选择生成对抗网络的生成器作为归一化流,则可以使用对抗训练,Wasserstein损失或其他方法来训练flow参数。
2.4 Brief Historical Overview
Whitening transformations(将数据转化为白噪声)是在机器学习中使用normalizing flows的前身。Chen and Gopinath (2000) 是第一个使用白化作为密度估计技术而不是用于特征预处理的工作,其被称为Gaussianization。Tabak and Vanden-Eijnden (2010) 从扩散过程的角度进行了高斯化,并与统计力学建立了连接,特别是使用刘维尔方程来表征flow。在后续论文中,Tabak and Turner (2013) 引入了可以将其视为normalizing flows现代概念的内容:引入术语normalizing flows并将flow定义为
K
K
K个简单映射的组合。正如我们将在第3节中讨论的那样,这种可组合的定义对于Flow模型在保留计算和分析能力的同时,也具有丰富表达能力是至关重要的。
组合链的想法最初在机器学习中出现是Rippel and Adams (2013)这一工作,他们认识到具有深层神经网络的参数化flow可能会导致相当通用和丰富表示的分布。Dinh et al. (2015) 随后引入了可扩展且计算高效的架构,在图像建模和推理上取得了进一步改进。Rezende and Mohamed (2015) 使用 Tabak and Turner (2013) 的想法和语言在变分推段的设置中应用normalizing flows。此后,正如这里回顾的论文将显示的那样,normalizing flows 现在已经具有大量的文献,这些大量的工作扩大了flow的适用性和可扩展性。
由于与变量变换有关,我们还可以将机器学习中normalizing flows的使用与许多其他领域中的历史联系起来。在统计力学的发展中,对度量的变化进行了深入研究,一个著名的例子是上述的刘维尔定理。Copulas可以看作是基本的flow,其中每个维度都使用经验估计的边源累积分布函数独立变换。最优运输(Optimal transport)和Wasserstein度量也可以根据度量的转换来制定(也称为Monge Problem)。特别是,三角映射(与自回归flow有关的概念)可以证明是对一类Monge–Kantorovich问题的约束解决方案。这类三角映射本身具有悠久的历史,Rosenblatt (1952) 研究了它们的特性,以统一地在超立方体上变换多元分布。最佳传输本身就是一个tutorial,因此我们主要避开了这个框架,而是选择考虑变量变化。
3.Constructing Flows Part I: Finite Compositions
在描述了flow的一些高级属性和用途之后,我们接下来将描述,分类和统一构造flow的各种方式。如第2.1节所述,normalizing flows是可以组合的。也就是说,我们可以通过组合有限数量的简单变换
T
k
T_k
Tk来构造带有变换
T
T
T的flow,如下所示:
T
=
T
K
◦
⋯
◦
T
1
.
(25)
T=T_K◦\cdots ◦T_1.\tag{25}
T=TK◦⋯◦T1.(25)
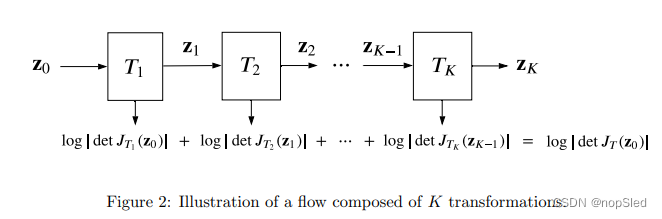
想法是使用简单的变换作为构建块(每个块具有简单的逆变换和雅可比行列式)来定义具有丰富表达能力的复杂变换。重要的是,flow的前向和逆向评估以及雅可比行列式的计算可以定位到单个块(sub-flow)。如图2所示,假设
z
0
=
u
\textbf z_0=\textbf u
z0=u和
z
K
=
x
\textbf z_K=\textbf x
zK=x,正向评估是:
z
k
=
T
k
(
z
k
−
1
)
f
o
r
k
=
1
,
.
.
.
,
K
,
(26)
\textbf z_k=T_k(\textbf z_{k-1})\quad for~k=1,...,K,\tag{26}
zk=Tk(zk−1)for k=1,...,K,(26)
逆向评估是:
z
k
−
1
=
T
k
−
1
(
z
k
)
f
o
r
k
=
K
,
.
.
.
,
1
,
(27)
\textbf z_{k-1}=T^{-1}_k(\textbf z_k)\quad for~k=K,...,1,\tag{27}
zk−1=Tk−1(zk)for k=K,...,1,(27)
而且雅可比行列式计算(对数域)为:
l
o
g
∣
d
e
t
J
T
(
z
0
)
∣
=
l
o
g
∣
∏
k
=
1
K
d
e
t
J
T
k
(
z
k
−
1
)
∣
=
∑
k
=
1
K
l
o
g
∣
d
e
t
J
T
k
(
z
k
−
1
)
∣
.
(28)
log|det~J_T(\textbf z_0)|=log\bigg |\prod^K_{k=1}det~J_{T_k}(\textbf z_{k-1})\bigg |=\sum^K_{k=1}log~|det~J_{T_k}(\textbf z_{k-1})|.\tag{28}
log∣det JT(z0)∣=log∣∣∣∣k=1∏Kdet JTk(zk−1)∣∣∣∣=k=1∑Klog ∣det JTk(zk−1)∣.(28)
增加变换的“深度”(即sub-flow的数目)将导致计算复杂性
O
(
K
)
\mathcal O(K)
O(K)的增长,这是能够增加表达能力需要支付的成本。
在实践中,我们使用具有参数
ϕ
k
\phi_k
ϕk的模型(例如神经网络)来实现
T
k
T_k
Tk或
T
k
−
1
T^{-1}_k
Tk−1,并将其表示为
f
ϕ
k
f_{\phi_k}
fϕk。也就是说,我们可以采用模型
f
ϕ
k
f_{\phi_k}
fϕk实现
T
k
T_k
Tk,在这种情况下,它以
z
k
−
1
\textbf z_{k-1}
zk−1作为输入并输出
z
k
\textbf z_k
zk(或实现
T
k
−
1
T^{-1}_k
Tk−1,在这种情况下,它以
z
k
\textbf z_k
zk作为输入并输出
z
k
−
1
\textbf z_{k-1}
zk−1)。无论哪种情况,我们都必须确保模型可逆,并且其雅可比行列式容易计算。在本节的其余部分中,我们将描述几种构建
f
ϕ
k
f_{\phi_k}
fϕk的方法,以便满足这些要求。表1显示了本节中讨论的所有方法的概述。
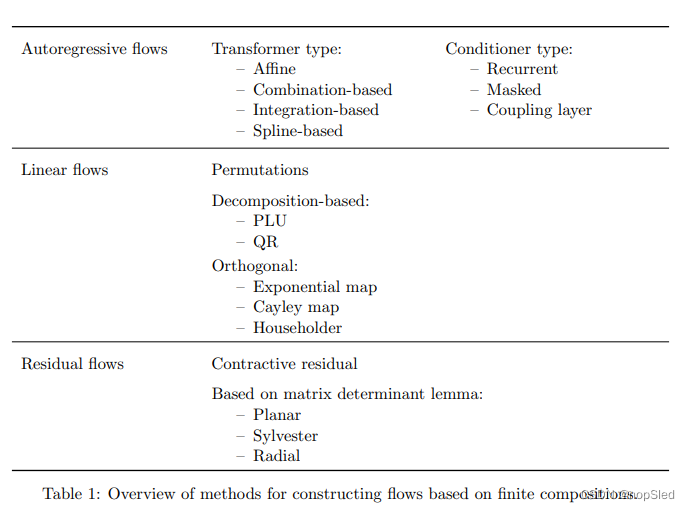
确保
f
ϕ
k
f_{\phi_k}
fϕk可逆和其逆能够显示计算不是一个同义词。在许多实现中,即使能保证存在
f
ϕ
k
f_{\phi_k}
fϕk的逆,其逆的计算也可能是昂贵甚至是棘手的。如第2节所述,当采样时使用正向变换
T
T
T,当进行密度评估时则使用逆向变换
T
−
1
T^{-1}
T−1。如果
f
ϕ
k
f_{\phi_k}
fϕk的逆不是高效的,则密度评估或采样将导致效率低下甚至是棘手的。
f
ϕ
k
f_{\phi_k}
fϕk是否应设计为具有高效的逆,以及是否应采取
T
k
T_k
Tk或
T
k
−
1
T^{-1}_k
Tk−1的实现是由用法来决定的。
我们还应该阐明“雅可比行列式容易计算”的含义。我们可以使用
D
D
D遍前向或逆向自动微分,以计算具有
D
D
D维输入和
D
D
D维输出的可微分函数的雅可比矩阵。然后,我们可以显式计算该雅可比矩阵的行列式。但是,该计算的时间成本为
O
(
D
3
)
\mathcal O(D^3)
O(D3),当
D
D
D很大时是非常棘手的。对于大多数基于flow的模型的应用,雅可比行列式的计算最多应为
O
(
D
)
\mathcal O(D)
O(D)。因此,在以下各节中,我们将描述允许雅各布行列式相对于输入维度在线性时间完成计算的函数形式。
为了简化符号,我们将删除模型参数对
k
k
k的依赖性,并用
f
ϕ
f_{\phi}
fϕ表示模型。另外,无论该模型是实现
T
k
T_k
Tk还是
T
k
−
1
T^{-1}_k
Tk−1,我们都将模型的输入表示为
z
\textbf z
z,输出表示为
z
′
\textbf z'
z′。
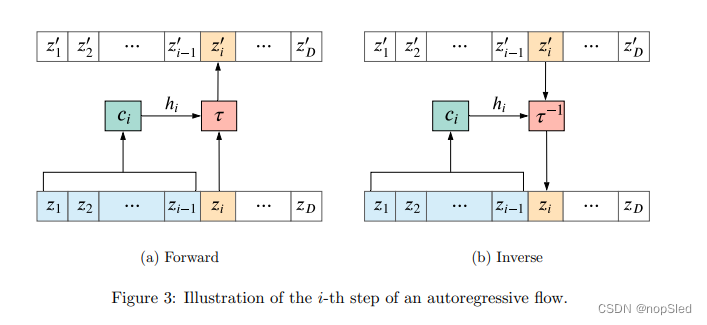
3.1 Autoregressive Flows
自回归flow是首先被提出的第一类flow之一,并且仍然是最受欢迎的flow之一。在第2.2节中,我们看到,在较软的条件下,我们可以使用具有三角雅可比矩阵的映射将任何分布
p
x
(
x
)
p_x(\textbf x)
px(x)转化为
(
0
,
1
)
D
(0,1)^D
(0,1)D中的均匀分布。自回归flow是该结构的一种直接实现,指定
f
ϕ
f_{\phi}
fϕ具有以下形式:
z
i
′
=
τ
(
z
i
,
h
i
)
w
h
e
r
e
h
i
=
c
i
(
z
<
i
)
,
(29)
z'_i=\tau(z_i,\textbf h_i)\quad where\quad \textbf h_i=c_i(\textbf z_{\lt i}),\tag{29}
zi′=τ(zi,hi)wherehi=ci(z<i),(29)
其中
τ
τ
τ称为变换器,而
c
i
c_i
ci则是第
i
i
i个调节器,这在图3a中进行了说明。变换器对
z
i
z_i
zi是一个严格单调的函数(因此可逆),并且由
h
i
\textbf h_i
hi参数化,同时指定flow如何对
z
i
z_i
zi进行操作以输出
z
i
′
z'_i
zi′。调节器确定了变换器的参数,进而可以修改变换器的行为。调节器不需要进行双向映射,因为它的一个约束是,第
i
i
i个调节器只能将维度小于
i
i
i的变量作为输入。此时,
f
ϕ
f_{\phi}
fϕ的参数
ϕ
\phi
ϕ通常是调节器的参数,但有时变换器也有其自己的参数(即除了
h
i
\textbf h_i
hi之外的参数)。
只要变换器可逆,那么就可以认为对于任何
τ
\tau
τ和
c
i
c_i
ci的选择,上述构造都是可逆的。给定
z
′
z'
z′,我们可以按以下方式迭代计算
z
z
z:
z
i
=
τ
−
1
(
z
i
′
,
h
i
)
w
h
e
r
e
h
i
=
c
i
(
z
<
i
)
.
(30)
z_i=\tau^{-1}(z'_i,\textbf h_i)\quad where\quad \textbf h_i=c_i(\textbf z_{\lt i}).\tag{30}
zi=τ−1(zi′,hi)wherehi=ci(z<i).(30)
这在图3b中进行了说明。在forward计算中,每个
h
i
\textbf h_i
hi和
z
i
′
z'_i
zi′都可以按任何顺序或并行地独立计算。但是,在 invers计算中,所有
z
<
i
\textbf z_{<i}
z<i都需要在
z
i
z_i
zi之前进行计算,因此
z
<
i
\textbf z_{<i}
z<i作为用于计算
h
i
\textbf h_i
hi的调节剂。
同样很容易地表明,上述变换的雅可比矩阵是三角形的,因此雅各布行列式是易计算的。由于每个
z
i
′
z'_i
zi′不依赖于
z
>
i
\textbf z_{>i}
z>i,因此每当
j
>
i
j>i
j>i时,
z
i
′
z'_i
zi′对
z
j
z_j
zj的偏导数为零。因此,可以以以下形式写出
f
ϕ
f_{\phi}
fϕ的雅可比矩阵:
J
f
ϕ
(
z
)
=
[
∂
τ
∂
z
1
(
z
1
;
h
1
)
0
⋱
L
(
z
)
∂
τ
∂
z
D
(
z
D
;
h
D
)
]
.
(31)
J_{f_{\phi}}(\textbf z)=\left[ \begin{matrix} \frac{∂\tau}{∂z_1}(z_1;\textbf h_1) & & \textbf 0 \\ & \ddots & \\ \textbf L(\textbf z) & & \frac{∂\tau}{∂z_D}(z_D;\textbf h_D) \end{matrix} \right]. \tag{31}
Jfϕ(z)=⎣⎡∂z1∂τ(z1;h1)L(z)⋱0∂zD∂τ(zD;hD)⎦⎤.(31)
上述雅可比矩阵是下三角矩阵,其对角线元素是变换器对
z
\textbf z
z的每个元素的偏导数。由于任何三角矩阵的行列式都等于其对角线元素的乘积,因此可以在
O
(
D
)
\mathcal O(D)
O(D)时间复杂度内计算
J
f
ϕ
(
z
)
J_{f_{\phi}}(\textbf z)
Jfϕ(z)的对数绝对值行列式,如下所示:
l
o
g
∣
d
e
t
J
f
ϕ
(
z
)
∣
=
l
o
g
∣
∏
i
=
1
D
∂
τ
∂
z
i
(
z
i
;
h
i
)
∣
=
∑
i
=
1
D
l
o
g
∣
∂
τ
∂
z
i
(
z
i
;
h
i
)
∣
.
(32)
log|det~J_{f_{\phi}(\textbf z)}|=log\bigg |\prod^D_{i=1}\frac{∂\tau}{∂z_i}(z_i;\textbf h_i)\bigg |=\sum^D_{i=1}log|\frac{∂\tau}{∂z_i}(z_i;\textbf h_i)|.\tag{32}
log∣det Jfϕ(z)∣=log∣∣∣∣i=1∏D∂zi∂τ(zi;hi)∣∣∣∣=i=1∑Dlog∣∂zi∂τ(zi;hi)∣.(32)
雅可比矩阵的下三角形部分(在这里用
L
(
z
)
\textbf L(\textbf z)
L(z)表示)是无关的。变换器的偏导数可以根据实现方式来计算。
自回归flow是一种通用近似器(在第2.2节中讨论的条件下),当变换器和调节器足够灵活时,可以很好地表示任何函数。这是基于2.2节中遵循的通用变换假设,即基于条件性的累积分布函数是自回归flow。但是,这只是表示能力的声明,在实际情况中无法保证flow的行为。
自回归flow的一种可替代但在数学上等效的形式,是将调节器
c
i
c_i
ci以
z
<
i
′
\textbf z'_{<i}
z<i′作为输入而不是
z
<
i
\textbf z_{<i}
z<i。这等同于在上述公式中用
τ
−
1
\tau^{-1}
τ−1替换
τ
\tau
τ,用
z
′
\textbf z'
z′替换
z
\textbf z
z。 两种表述在文献中都是常见的。不失一般性,我们使用
z
<
i
\textbf z_{<i}
z<i作为
c
i
c_i
ci的输入。有关这两种替代方案之间的计算差异可参考Kingma et al. (2016); Papamakarios et al. (2017)。
实现一个自回归flow可以总结为:(a)变换器
τ
τ
τ的实现;(b)调节器
c
i
c_i
ci的实现。这些实现都是独立选择的:任何类型的变换器都可以与任何类型的调节器配对,从而产生文献中出现的各种组合。在以下段落中,我们将列出许多变换器的实现(第3.1.1节)和许多调节器的实现(第3.1.2节)。 然后,我们将讨论他们的利弊,并指出文献中特定实现的组合。
3.1.1 Implementing the Transformer
(1)Affine transformers
affine transformers是变换器最简单的选择之一,也是被首先应用的,其形式如下:
τ
(
z
i
;
h
i
)
=
α
i
z
i
+
β
i
w
h
e
r
e
h
i
=
{
α
i
,
β
i
}
.
(33)
\tau(z_i;\textbf h_i)=\alpha_i z_i+\beta_i\quad where\quad \textbf h_i=\{\alpha_i,\beta_i\}.\tag{33}
τ(zi;hi)=αizi+βiwherehi={αi,βi}.(33)
上述变换可以视为位置尺度变换,其中
α
i
α_i
αi控制尺度,
β
i
β_i
βi控制位置。如果
α
i
≠
0
α_i\ne 0
αi=0,则可以保证可逆性。并且可以令
α
i
=
e
x
p
α
~
i
α_i=exp~\tilde α_i
αi=exp α~i(其中
α
~
i
\tilde α_i
α~i是一个无约束参数,且
h
i
=
{
α
~
i
,
β
i
}
\textbf h_i=\{\tilde α_i,β_i\}
hi={α~i,βi})使雅可比行列式容易计算。由于变换器对
z
i
z_i
zi的偏导数等于
α
i
α_i
αi。因此,对数绝对值雅可比行列式为:
l
o
g
∣
d
e
t
J
f
ϕ
(
z
)
∣
=
∑
i
=
1
D
l
o
g
∣
α
i
∣
=
∑
i
=
1
D
α
~
i
.
(34)
log|det~J_{f_{\phi}}(\textbf z)|=\sum^D_{i=1}log|\alpha_i|=\sum^D_{i=1}\tilde α_i.\tag{34}
log∣det Jfϕ(z)∣=i=1∑Dlog∣αi∣=i=1∑Dα~i.(34)
具有affine transformers的自回归flow由于其简单性和易分析性而具有很大吸引力,但其表示能力是有限的。为了说明为什么,假设
z
\textbf z
z遵循高斯分布;然后,以
z
<
i
′
\textbf z'_{<i}
z<i′为条件的
z
i
′
z'_i
zi′也将遵循高斯分布。换句话说,多元高斯的单个仿射自回归变换导致其条件分布
p
z
′
(
z
i
′
∣
z
<
i
′
)
p_{z'}(z'_i|\textbf z'_{<i})
pz′(zi′∣z<i′)必然也是高斯的。尽管如此,仍然可以通过堆叠多个仿射自回归层来获得强大的表现力,但是尚不清楚具有多少层的仿射自回归flow才能是一个通用近似器。affine transformers在文献中很受欢迎,它已用于诸如NICE,REAL NVP,IAF,MAF和GLOW之类的模型中。
(2)Combination-based transformers
基于单调函数的组合也是单调的这一观察结果,可以通过简单的组合来构建Non-affine transformers。给定真实变量z的单调函数
τ
1
,
.
.
.
,
τ
K
τ_1,...,τ_K
τ1,...,τK,下列函数同样是单调的:
- Conic combination: τ ( z ) = ∑ k = 1 K w k τ k ( z ) \tau(z)=\sum^K_{k=1}w_k\tau_k(z) τ(z)=∑k=1Kwkτk(z),其中对于所有的 k k k,有 w k > 0 w_k\gt 0 wk>0。
- Composition: τ ( z ) = τ K ◦ ⋯ ◦ τ 1 ( z ) \tau(z)=\tau_K◦\cdots ◦\tau_1(z) τ(z)=τK◦⋯◦τ1(z)。
例如,可以使用单调递增激活函数
σ
(
⋅
)
σ(·)
σ(⋅)的conic combination来构建non-affine transformer(例如Logistic Sigmoid,Tanh,Leaky Relu等):
τ
(
z
i
;
h
i
)
=
w
i
0
+
∑
k
=
1
K
w
i
k
σ
(
α
i
k
z
i
+
β
i
k
)
w
h
e
r
e
h
i
=
{
w
i
0
,
.
.
.
,
w
i
k
,
α
i
k
,
β
i
k
}
,
(35)
\tau(z_i;\textbf h_i)=w_{i0}+\sum^K_{k=1}w_{ik}\sigma(\alpha_{ik}z_i+\beta_{ik})\quad where\quad \textbf h_i=\{w_{i0},...,w_{ik},\alpha_{ik},\beta_{ik}\},\tag{35}
τ(zi;hi)=wi0+k=1∑Kwikσ(αikzi+βik)wherehi={wi0,...,wik,αik,βik},(35)
对于所有
k
≥
1
k≥1
k≥1,有
α
i
k
>
0
α_{ik}>0
αik>0和
w
i
k
>
0
w_{ik}> 0
wik>0。显然,上述构造对应一个单调的单层感知。通过反复组合单调激活函数,我们可以构建一个单调的多层感知器,前提是其所有权重严格为正。
上述的变换器可以任意地表示任何单调函数,这与多层感知器的通用近似能力有关(有关详细信息,请参见Huang et al., 2018)。计算变换器雅可比行列式所需的偏导数原则上是可分析的,但更常见的是,它们是通过反向传播来计算。combination-based transformers的缺点是,通常不能分析它们的逆,并且只能迭代地进行逆变换,例如使用bisection搜索。combination-based transformers的变体已用于NAF,Block-NAF和Flow ++等模型中。
(3)Integration-based transformers
定义non-affine变换器的另一种方法是使用积分变换器,其灵感来自于正函数的积分是单调递增的函数。例如,Wehenkel and Louppe (2019) 将变换器定义为:
τ
(
z
i
;
h
i
)
=
∫
0
z
i
g
(
z
;
α
i
)
d
z
+
β
i
w
h
e
r
e
h
i
=
{
α
i
,
β
i
}
,
(36)
\tau(z_i;\textbf h_i)=\int^{z_i}_0g(z;\textbf α_i)dz+\beta_i\quad where\quad \textbf h_i=\{\textbf α_i,\beta_i\},\tag{36}
τ(zi;hi)=∫0zig(z;αi)dz+βiwherehi={αi,βi},(36)
其中
g
(
⋅
;
α
i
)
g(·;\textbf α_i)
g(⋅;αi)可以是由
α
i
\textbf α_i
αi参数化的任何正值神经网络。通常,除
α
i
\textbf α_i
αi外,
g
(
⋅
;
α
i
)
g(·;\textbf α_i)
g(⋅;αi)还将具有其自身的参数。计算雅可比行列式中所需变换器的导数等于
g
(
z
i
;
α
i
)
g(z_i;\textbf α_i)
g(zi;αi)。这种方法能产生非常灵活的变换器,但积分方法难以进行分析。一种可能是采用数值近似。
可以通过将
g
(
⋅
;
α
i
)
g(·;\textbf α_i)
g(⋅;αi)定义为正的
2
L
2L
2L次多项式来获得可分析的积分变换器。积分是
z
i
z_i
zi的
2
L
+
1
2L+1
2L+1次多项式,因此可以通过分析进行计算。由于每个正的
2
L
2L
2L次多项式可以写成
L
L
L次多项式平方和,因此可以利用这一定理来定义sum-of-squares polynomial 变换器:
τ
(
z
i
;
h
i
)
=
∫
0
z
i
∑
k
=
1
K
(
∑
l
=
0
L
α
i
k
l
z
l
)
2
d
z
+
β
i
,
(37)
\tau(z_i;\textbf h_i)=\int^{z_i}_0\sum^K_{k=1}\bigg(\sum^L_{l=0}\alpha_{ikl}z^l\bigg)^2dz+\beta_i,\tag{37}
τ(zi;hi)=∫0zik=1∑K(l=0∑Lαiklzl)2dz+βi,(37)
其中
h
i
\textbf h_i
hi包含
β
i
\beta_i
βi和所有多项式系数
α
i
k
l
α_{ikl}
αikl,并且
K
≥
2
K≥2
K≥2。此外,affine变换器可以作为
L
=
0
L=0
L=0的特殊情况得到:
∫
0
z
i
∑
k
=
1
K
(
α
i
k
0
z
0
)
2
d
z
+
β
i
=
(
∑
k
=
1
K
α
i
k
0
2
)
z
∣
0
z
i
+
β
i
=
α
i
z
i
+
β
i
,
(38)
\int^{z_i}_0\sum^K_{k=1}(\alpha_{ik0}z^0)^2dz+\beta_i=\bigg(\sum^K_{k=1}\alpha^2_{ik0}\bigg)z|^{z_i}_0+\beta_i=\alpha_iz_i+\beta_i,\tag{38}
∫0zik=1∑K(αik0z0)2dz+βi=(k=1∑Kαik02)z∣0zi+βi=αizi+βi,(38)
其中
α
i
=
∑
k
=
1
K
α
i
k
0
2
α_i=\sum^K_{k=1}α^2_{ik0}
αi=∑k=1Kαik02。可以证明的是,对于足够大的L,平方和多项式变换器可以近似任何单调递增的函数。尽管如此,由于只能通过分析求解次数最多为4的多项式,因此平方和多项式在
L
≥
2
L\ge 2
L≥2的情况下,是不可逆的,并且只能使用例如bisection搜索的方法,迭代进行求逆。
(4)Spline-based transformers
到目前为止,我们已经讨论了各种灵活的non-affine变换器,但是这些变换器无法进行可逆分析。克服此限制的一种方法是将变换器作为单调spline来实现,即由
K
K
K个段组成的分段函数,其中每个段都是一个可逆的简单函数。具体而言,给定
K
+
1
K+1
K+1个输入位置
z
i
0
,
.
.
.
,
z
i
K
z_{i0},...,z_{iK}
zi0,...,ziK且每个段在点
z
i
1
,
.
.
.
,
z
i
(
K
−
1
)
z_{i1},...,z_{i(K-1)}
zi1,...,zi(K−1)处相接,则在每个区间
[
z
i
(
k
−
1
)
,
z
i
k
]
[z_{i(k-1)},z_{ik}]
[zi(k−1),zik]中,变换器
τ
(
z
i
;
h
i
)
τ(z_i;\textbf h_i)
τ(zi;hi)可被视为一个简单的单调函数(例如,低次多项式)。在区间
[
z
i
0
,
z
i
k
]
[z_{i0},z_{ik}]
[zi0,zik]之外,变换器默认作为一个简单函数,例如identity函数。通常,变换器的参数
h
i
\textbf h_i
hi是输入位置
z
i
0
,
.
.
.
,
z
i
K
z_{i0},...,z_{iK}
zi0,...,ziK,及其对应的输出位置
z
i
0
′
,
.
.
.
,
z
i
K
′
z'_{i0},...,z'_{iK}
zi0′,...,ziK′,还有点
z
i
0
,
.
.
.
,
z
i
K
z_{i_0},...,z_{iK}
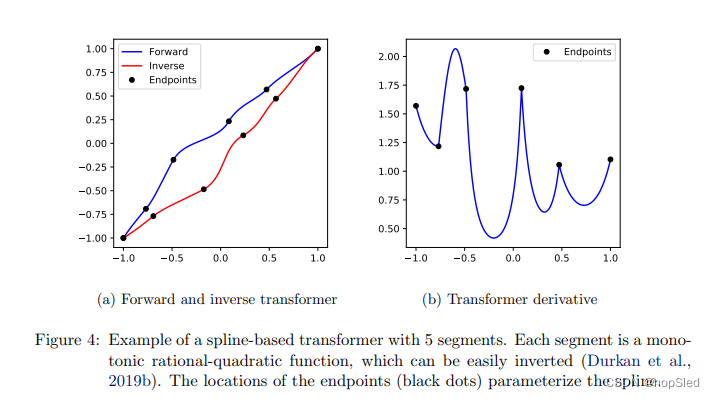
zi0,...,ziK处的导数(即斜率,取决于spline的类型)。有关描述,请参见图4。
基于spline的变换器由使用的spline类型(即段的函数形式)来区分。 到目前为止,已经探索了以下选择,按照灵活性的增加依次为:线性和二次spline,立方spline,线性有理spline和二次有理spline。基于spline的变换器的逆与评估一样快,同时保持精确的可逆分析。对基于spline的变换器进行评估或求逆首先定位正确的段,这可以使用binary search在
O
(
l
o
g
K
)
\mathcal O(log~K)
O(log K)时间内完成,然后对该段进行评估或求逆,这是容易分析的。通过增加片段
K
K
K的数量,可以增加变换器的灵活性。
3.1.2 Implementing the Conditioner
调节器
c
i
(
z
<
i
)
c_i(\textbf z_{<i})
ci(z<i)可以是
z
<
i
\textbf z_{<i}
z<i的任何函数,这意味着每个调节器在原则上都可以实现为以
z
<
i
\textbf z_{<i}
z<i作为输入,并输出
h
i
\textbf h_i
hi的任意模型。但是,调节器的简单实现是为
D
D
D个维度单独构建独立的模型,这要求进行
D
D
D次模型评估,每个模型都具有平均大小
D
/
2
D/2
D/2的向量。这需要额外存储和评估
D
D
D个独立模型的参数。实际上,早期的flow工作认为自回归方法非常昂贵。
但是,可以通过在调节器
c
i
(
z
<
i
)
c_i(\textbf z_{<i})
ci(z<i)上共享参数,甚至通过将调节器组合到单个模型中来有效解决此问题。在以下段落中,我们将讨论调节器的一些实际实现,以使其扩展到高维度。
(1)Recurrent conditioners
调节器共享参数的一种方法是使用循环神经网络(RNN)共同实现它们。第
i
i
i个调节器的实现为:
h
i
=
c
(
s
i
)
w
h
e
r
e
s
1
=
i
n
i
t
i
a
l
s
t
a
t
e
s
i
=
R
N
N
(
z
i
−
1
,
s
i
−
1
)
f
o
r
i
>
1.
(39)
\textbf h_i=c(\textbf s_i)\quad where\quad \begin{array}{cc} \textbf s_1=initial~state\\ \textbf s_i=RNN(z_{i-1},\textbf s_{i-1})~for~i>1. \end{array}\tag{39}
hi=c(si)wheres1=initial statesi=RNN(zi−1,si−1) for i>1.(39)
RNN一次处理
z
<
D
=
(
z
1
,
.
.
.
,
z
D
−
1
)
\textbf z_{<D}=(z_1,...,z_{D-1})
z<D=(z1,...,zD−1)中的一个元素,在每个步骤中,它都会更新一个具有固定维度的内部状态
s
i
s_i
si,该状态对子序列
z
<
i
=
(
z
1
,
.
.
.
,
z
i
−
1
)
\textbf z_{<i}=(z_1,...,z_{i-1})
z<i=(z1,...,zi−1)进行了总结。基于
s
i
\textbf s_i
si计算
h
i
\textbf h_i
hi的网络
c
c
c对于每一步都是相同的。初始状态
s
1
\textbf s_1
s1可以是固定的,也可以是RNN的可学习参数。这里可以使用任何RNN架构,例如LSTM或GRU。
RNN在自回归模型的条件分布被广泛使用。基于RNN的自回归模型的示例包括分布估计器,序列模型和图像/视频模型。第3.1.3节讨论了自回归模型与自回归flow之间的关系。
在自回归flow的文献中,基于RNN的调节器由Oliva et al. (2018)和Kingma et al. (2016)提出,但与替代方案相比并不常见。基于RNN的调节器的主要缺点是它们将固有的并行计算转换为一个顺序计算:即使可以独立并行计算每个
h
i
\textbf h_i
hi,也必须基于状态
s
1
,
.
.
.
,
s
D
s_1,...,s_D
s1,...,sD顺序计算。由于此循环计算涉及
O
(
D
)
\mathcal O(D)
O(D)个步骤,因此对于图像或视频等高维数据可能会很慢。
(2)Masked conditioners
另一种在调节器之间共享参数但能避免RNN顺序计算的方法是masking调节器。该方法使用单个前馈神经网络,该神经网络接收
z
\textbf z
z并同时输出整个序列
(
h
1
,
.
.
.
,
h
D
)
(\textbf h_1,...,\textbf h_D)
(h1,...,hD)。唯一的要求是,该网络必须遵守调节器的自回归结构,即输出
h
i
\textbf h_i
hi不能取决于输入
z
≥
i
z_{≥i}
z≥i。
为了构建这样的网络,一种方法是采用任意神经网络并删除相关连接,直到没有输入
z
i
z_i
zi到输出
(
h
1
,
…
,
h
i
)
(\textbf h_1,…,\textbf h_i)
(h1,…,hi)的路径。删除连接的一种简单方法是将每个权重矩阵元素乘以相同大小的二进制矩阵。这具有删除与零权重相对应连接的效果,同时使所有其他连接都没有修改。这个二进制矩阵可以被认为是“屏蔽”了连接。被屏蔽的网络将具有与原始网络相同的架构和大小。反过来,它保留了原始网络的计算属性,例如并行性或在GPU上有效评估的能力。
Germain et al. (2015) 提出了一种用于在具有任意隐藏层或隐藏单元的多层感知器上进行mask的通用方法。其关键想法是为每个输入,隐藏和输出单元分配一个
1
1
1和
D
D
D之间的度,并屏蔽层之间的权重,以便没有单元馈入具有较低或相等度的单元。在卷积网络中,可以通过用相同大小的二进制矩阵乘以滤波器来完成屏蔽,从而得到一种通常称为自回归或因果卷积的卷积类型。在使用自注意力的体系结构中,可以通过归零softmax概率来完成屏蔽。
屏蔽自回归flow具有两个主要优势。首先,它们能进行高效评估。给定
z
\textbf z
z,可以对神经网络进行一次forward来获得参数
(
h
1
,
.
.
.
,
h
D
)
(\textbf h_1,...,\textbf h_D)
(h1,...,hD),然后可以通过
z
i
′
=
τ
(
z
i
;
h
i
)
z'_i=\tau(z_i;\textbf h_i)
zi′=τ(zi;hi)并行计算
z
′
z'
z′的每个维度。其次,屏蔽自回归flow是一个通用近似器。给定足够大的调节器和足够灵活的变换器,它们可以用单调变换器表示任何自回归变换,从而在任意两个分布之间进行转换(如第2.2节所述)。
另一方面,屏蔽自回归flow的主要缺点是它们的逆不像评估那样高效。这是因为计算
z
i
=
τ
−
1
(
z
i
′
;
h
i
)
z_i=τ^{-1}(z'_i;\textbf h_i)
zi=τ−1(zi′;hi)所需的参数
h
i
\textbf h_i
hi,在获得所有
(
z
i
,
…
,
z
i
−
1
)
(z_i,…,z_{i -1})
(zi,…,zi−1)之前都无法计算。遵循此逻辑,我们必须首先计算
h
1
\textbf h_1
h1并得到
z
1
z_1
z1,然后计算
h
2
\textbf h_2
h2来得到
z
2
z_2
z2,依此类推,直到获得
z
D
z_D
zD为止。使用屏蔽调节器
c
c
c,可以在伪代码中实现上述过程,如下所示:
I
n
i
t
i
a
l
i
z
e
z
t
o
a
n
a
r
b
i
t
r
a
r
y
v
a
l
u
e
f
o
r
i
=
1
,
.
.
.
D
(
h
1
,
.
.
.
,
h
D
)
=
c
(
z
)
z
i
=
τ
−
1
(
z
i
′
;
h
i
)
.
(40)
\begin{aligned} &Initialize~\textbf z~to~an~arbitrary~value\\ &for~i=1,...D\\ &\quad (\textbf h_1,...,\textbf h_D)=c(\textbf z)\\ &\quad z_i=\tau^{-1}(z'_i;\textbf h_i). \end{aligned}\tag{40}
Initialize z to an arbitrary valuefor i=1,...D(h1,...,hD)=c(z)zi=τ−1(zi′;hi).(40)
为了明白为什么此过程是正确的,观察到如果
z
≤
i
−
1
\textbf z_{≤i-1}
z≤i−1在第
i
i
i次迭代之前是正确的,那么
h
i
\textbf h_i
hi将被正确计算(由于
c
c
c的自回归结构),因此在第
(
i
+
1
)
(i+1)
(i+1)次迭代之前,
z
≤
i
\textbf z_{≤i}
z≤i将是正确的。由于
z
≤
0
=
∅
\textbf z_{≤0}=∅
z≤0=∅在第一次迭代之前是正确的(在退化的意义上),因此,通过归纳,
z
≤
D
=
z
\textbf z_{≤D}=\textbf z
z≤D=z在循环结束时将是正确的。即使上述过程可以准确地求逆flow(前提是变换器易逆),它仍需要调用调节器
D
D
D次。这意味着,使用上述方法对屏蔽自回归flow求逆要比评估正向变换耗时。对于高维数据,例如图像或视频,这可能非常昂贵。
Song et al. (2019) 提出的一种对flow求逆的替代方法,其通过迭代下式 Newton-style 固定点更新来求解方程
z
′
=
f
ϕ
(
z
)
\textbf z'=f_{\phi}(\textbf z)
z′=fϕ(z):
z
k
+
1
=
z
k
−
α
d
i
a
g
(
J
f
ϕ
(
z
k
)
)
−
1
(
f
ϕ
(
z
k
)
−
z
′
)
,
(41)
\textbf z_{k+1}=\textbf z_{k}-\alpha~diag(J_{f_{\phi}}(\textbf z_k))^{-1}(f_{\phi}(\textbf z_{k})-\textbf z'),\tag{41}
zk+1=zk−α diag(Jfϕ(zk))−1(fϕ(zk)−z′),(41)
其中
α
α
α是一个步长超参数,
d
i
a
g
(
⋅
)
diag(·)
diag(⋅)返回一个对角矩阵,其对角线元素与其输入相同,且初始化
z
0
=
z
′
\textbf z_0=\textbf z'
z0=z′。Song et al. (2019)表明,上述过程在
0
<
α
<
2
0<α<2
0<α<2时局部收敛,并且由于
f
ϕ
−
1
(
z
′
)
f^{-1}_{\phi}(\textbf z')
fϕ−1(z′)是唯一的固定点,因此该过程必须收敛或多样化。通过屏蔽自回归flow,可以通过调用调节器一次来高效地计算
f
ϕ
(
z
k
)
f_{\phi}(\textbf z_k)
fϕ(zk)和
d
i
a
g
(
J
f
ϕ
(
z
k
)
)
diag(J_{f_{\phi}}(\textbf z_k))
diag(Jfϕ(zk))。因此,上述Newton-like过程在实践中的迭代次数明显小于
D
D
D。另一方面,上述Newton-like过程是近似的,并且保证仅在局部收敛。
尽管与逆相关的计算很困难,masking仍然是实现自回归flow的最受欢迎的技术之一。它非常适合不需要求逆或数据维度不太大的情况。使用屏蔽flow的模型包括IAF,MAF,NAF,Block-NAF,MintNet和MaCow。masking同样在非flow的自回归模型中很受欢迎(例如MADE,PixelCNN和WaveNet)。
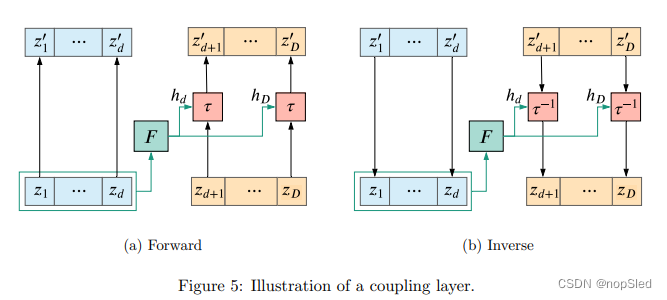
(3)Coupling layers
正如我们已经看到的,屏蔽自回归flow会面临影响其应用和可用性的计算不对称性。采样或密度评估要比另一个慢
D
D
D倍。如果这两个操作都需要快速进行,则需要对调节器进行不同的实现。一种计算对称性(即评估和求逆一样快)的实现是 coupling layer。这个想法是选择一个索引
d
d
d(常见的选择是使用
D
/
2
D/2
D/2并近似到整数)并设计如下的调节器:
- 参数 ( h 1 , . . . , h d ) (\textbf h_1,...,\textbf h_d) (h1,...,hd)是常数,即不是 z \textbf z z的函数。
- 参数 ( h d + 1 , . . . , h D ) (\textbf h_{d+1},...,\textbf h_D) (hd+1,...,hD)是 z ≤ d \textbf z_{\le d} z≤d的函数,即它们不依赖于 z > d \textbf z_{\gt d} z>d。
这可以使用任意函数近似器
F
F
F(例如神经网络)轻松实现这一点,例如:
(
h
1
,
.
.
.
,
h
d
)
=
c
o
n
s
t
a
n
t
s
,
e
i
t
h
e
r
f
i
x
e
d
o
r
e
s
t
i
m
a
t
e
d
(
h
d
+
1
,
.
.
.
,
h
D
)
=
F
(
z
≤
d
)
.
(42)
\begin{array}{cc} (\textbf h_1,...,\textbf h_d)=constants,~either~fixed~or~estimated\\ (\textbf h_{d+1},...,\textbf h_D)=F(\textbf z_{\le d}). \end{array}\tag{42}
(h1,...,hd)=constants, either fixed or estimated(hd+1,...,hD)=F(z≤d).(42)
换句话说,耦合层将
z
\textbf z
z分为两个部分,例如
z
=
[
z
≤
d
,
z
>
d
]
\textbf z=[\textbf z_{≤d},\textbf z_{>d}]
z=[z≤d,z>d]。第一部分是独立于其他维度进行逐元素变换。第二部分以取决于第一部分的方式进行逐元素变换。我们还可以将耦合层视为一种激进屏蔽策略的实现,该策略仅允许
(
h
d
+
1
,
.
.
.
,
h
D
)
(\textbf h_{d+1},...,\textbf h_D)
(hd+1,...,hD)仅取决于
z
≤
d
\textbf z_{\le d}
z≤d。
耦合层的常见实现固定变换器
τ
(
⋅
;
h
1
)
,
.
.
.
,
τ
(
⋅
;
h
d
)
τ(·;\textbf h_1),...,τ(·;\textbf h_d)
τ(⋅;h1),...,τ(⋅;hd)为恒等函数。在这种情况下,转换可以写成下式:
z
≤
d
′
=
z
≤
d
(
h
d
+
1
,
.
.
.
,
h
D
)
=
F
(
z
≤
d
)
.
z
i
′
=
τ
(
z
i
;
h
i
)
f
o
r
i
>
d
.
(43)
\begin{array}{cc} \textbf z'_{\le d}=\textbf z_{\le d}\\ (\textbf h_{d+1},...,\textbf h_D)=F(\textbf z_{\le d}).\\ z'_i=\tau(\textbf z_i;\textbf h_i)~for~i>d. \end{array}\tag{43}
z≤d′=z≤d(hd+1,...,hD)=F(z≤d).zi′=τ(zi;hi) for i>d.(43)
反过来,逆变换很简单,由以下方式给出:
z
≤
d
=
z
≤
d
′
(
h
d
+
1
,
.
.
.
,
h
D
)
=
F
(
z
≤
d
)
.
z
i
′
=
τ
−
1
(
z
i
;
h
i
)
f
o
r
i
>
d
.
.
(44)
\begin{array}{cc} \textbf z_{\le d}=\textbf z'_{\le d}\\ (\textbf h_{d+1},...,\textbf h_D)=F(\textbf z_{\le d}).\\ z'_i=\tau^{-1}(\textbf z_i;\textbf h_i)~for~i>d. \end{array}.\tag{44}
z≤d=z≤d′(hd+1,...,hD)=F(z≤d).zi′=τ−1(zi;hi) for i>d..(44)
上述过程如图5所示。与所有自回归flow一样,变换的雅可比矩阵是下三角矩阵,此外,它还具有以下特殊结构:
J
f
ϕ
=
[
I
0
A
D
]
,
(45)
J_{f_{\phi}}= \left[\begin{matrix} \textbf I & \textbf 0\\ \textbf A & \textbf D \end{matrix}\right],\tag{45}
Jfϕ=[IA0D],(45)
其中,
I
\textbf I
I是一个
d
×
d
d\times d
d×d的恒等矩阵,
0
\textbf 0
0是
d
×
(
D
−
d
)
d\times(D-d)
d×(D−d)的零矩阵,
A
\textbf A
A是
(
D
−
d
)
×
d
(D-d)\times d
(D−d)×d的全矩阵,
D
\textbf D
D是一个
(
D
−
d
)
×
(
D
−
d
)
(D-d)\times(D-d)
(D−d)×(D−d)的对角矩阵。此时,雅可比行列式仅仅是
D
\textbf D
D对角元素的乘积,对角元素为变换
τ
(
⋅
;
h
d
+
1
)
,
.
.
.
,
τ
(
⋅
;
h
D
)
\tau(·; \textbf h_{d+1}),...,\tau(·;\textbf h_D)
τ(⋅;hd+1),...,τ(⋅;hD)的导数。
耦合层和完全自动回归flow是两种实现的极端。耦合层将
z
\textbf z
z分为两个部分,并将第二部分逐元素的变换作为第一部分的函数,而完全自动回归flow将输入分为
D
D
D个部分(每个部分一个元素),并将每个部分的转换作为先前所有部分的函数。显然,存在一个中间选择:即可以将输入分为
K
K
K部分,并将第
k
k
k部分逐元素的变换作为
1
1
1至
k
−
1
k -1
k−1部分的函数,
k
=
2
k=2
k=2对应于耦合层,
k
=
D
k=D
k=D对应于完全自回旋flow。使用屏蔽调节器,逆变换将比评估慢
O
(
K
)
\mathcal O(K)
O(K)倍,因此可以根据任务的计算要求选择
K
K
K。
耦合层的高效是以降低表达能力为代价的。与循环或屏蔽自回归flow不同,无论函数
F
F
F的表现力如何,单个耦合层都不可能再代表任何自回归变换。因此,具有单个耦合层的自回归flow不再是通用近似器。但是,可以通过组合多个耦合层来提高flow的表达能力。在组合耦合层时,需要在层之间排列
z
\textbf z
z的元素,以便所有维度都有机会进行变换以及交互。先前工作表明,组合耦合层确实可以创建灵活的flow。
从理论上讲,只要第
i
i
i个耦合层的索引
d
d
d等于
l
−
1
l-1
l−1,就可以很容易地表明
D
D
D个耦合层的组合确实是通用近似器。观察到第
i
i
i个耦合层可以表达
z
i
′
=
τ
(
z
i
;
c
i
(
z
<
i
)
)
z'_i=τ(z_i;c_i(\textbf z<i))
zi′=τ(zi;ci(z<i))的任何变换,因此
D
D
D个这样的层的组合能够变换每个维度。但是,该结构无论向前还是反向都涉及
D
D
D个序列计算(每一层),因此不会对循环或屏蔽自回归flow带来改进。是否可以通过少于
O
(
D
)
\mathcal O(D)
O(D)个耦合层来获得通用近似器,这是一个开放的问题。
耦合层是实现基于flow的模型的最流行方法之一,因为它们允许密度评估和采样同样快速。基于耦合层的flow容易与最大似然结合,然后从有效地进行采样。因此,在高维数据的生成模型(例如图像,音频和视频)中经常发现耦合层。带有耦合层的基于flow的模型包括NICE,Real NVP,Glow,WaveGlow,FloWaveNet和Flow++。
3.1.3 Relationship with Autoregressive Models
除了标准化flow外,另一类用于高维分布的模型是自回归模型。自回归模型历史悠久,从贝叶斯网络的通用框架到最新的基于神经网络的实现。
为了构建
p
x
(
x
)
p_x(\textbf x)
px(x)的自回归模型,我们首先使用链式法则将
p
x
(
x
)
p_x(\textbf x)
px(x)分解为1维条件概率的乘积:
p
x
(
x
)
=
∏
i
=
1
D
p
x
(
x
i
∣
x
<
i
)
.
(46)
p_x(\textbf x)=\prod^D_{i=1}p_x(x_i|\textbf x_{\lt i}).\tag{46}
px(x)=i=1∏Dpx(xi∣x<i).(46)
然后,我们通过使用具有参数
h
i
\textbf h_i
hi的参数化分布对每个条件分布进行建模:
p
x
(
x
i
∣
x
<
i
)
=
p
x
(
x
i
;
h
i
)
,
w
h
e
r
e
h
i
=
c
i
(
x
<
i
)
.
(47)
p_x(x_i|\textbf x_{\lt i})=p_x(x_i;\textbf h_i),\quad where\quad \textbf h_i=c_i(\textbf x_{\lt i}).\tag{47}
px(xi∣x<i)=px(xi;hi),wherehi=ci(x<i).(47)
例如,
p
x
(
x
i
;
h
i
)
p_x(x_i;\textbf h_i)
px(xi;hi)可以是由均值和方差进行参数化的高斯函数,也可以是通过每个组件的均值,方差和混合系数参数化的混合高斯。函数
c
i
c_i
ci类似于自回归flow的调节剂,并且通常使用RNN或掩屏蔽神经网络实现,如先前部分所述。除了连续数据外,自回归模型可以轻松用于离散甚至混合数据。如果
x
i
x_i
xi对于某些
i
i
i是离散的,则
p
x
(
x
i
;
h
i
)
p_x(x_i;\textbf h_i)
px(xi;hi)可能是参数概率质量函数。
现在,我们表明,所有连续变量的自回归模型实际上都是带有单个自回归层的自回归flow。令
τ
(
x
i
;
h
i
)
τ(x_i;\textbf h_i)
τ(xi;hi)为
p
x
(
x
i
;
h
i
)
p_x(x_i;\textbf h_i)
px(xi;hi)的累积分布函数,定义如下:
τ
(
x
i
;
h
i
)
=
∫
−
∞
x
i
p
x
(
x
i
′
;
h
i
)
d
x
i
′
.
(48)
\tau(x_i;\textbf h_i)=\int^{x_i}_{-\infty}p_x(x'_i;\textbf h_i)dx'_i.\tag{48}
τ(xi;hi)=∫−∞xipx(xi′;hi)dxi′.(48)

















 741
741

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









