







需要学的是神经网络
f
f
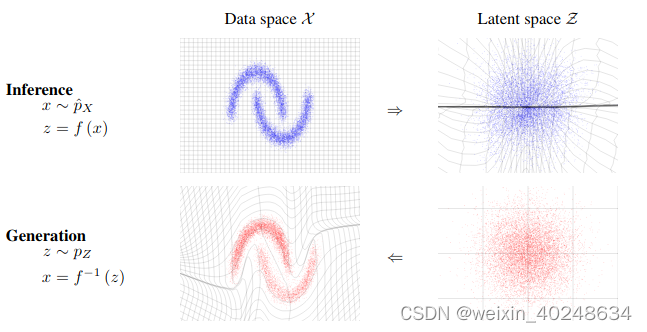
f, 用于完成从source distribution (Pz)(latent space,一般为高斯分布)到 target distribution (Px) 的映射。
Normalizing Flows 是一种强大的生成模型,它通过学习一个可逆且易于计算的转换来将复杂的概率分布转换为简单的分布(如标准正态分布)。这种转换允许我们进行高效的采样和概率密度估计。
以下是 Normalizing Flows 的训练和采样过程的基本步骤:
训练过程:
- 定义模型:需要定义一个 Normalizing Flow 模型。这通常涉及到堆叠多个可逆的转换层,例如仿射变换(Affine transformations)或耦合层(Coupling layers)。
- 设置损失函数:对于生成模型,常用的损失函数是最大似然损失(Maximum Likelihood Loss)或其变种。在 Normalizing Flows 的上下文中,这通常涉及到计算转换后的分布与目标分布之间的负对数似然。

-
优化过程:使用梯度下降或其变种(如 Adam)来优化模型参数。在每次迭代中,你需要:
- 从目标分布中采样一批数据。
- 将这些数据通过模型进行转换, 即使用 the change of variables 公式。
- 计算损失函数。
- 使用自动微分计算梯度。
- 更新模型参数。
-
监控训练过程:监控损失函数在验证集上的表现,以确保模型没有过拟合。同时,也可以可视化生成样本以检查模型的学习进度。
采样过程:
- 从基础分布采样:从简单的基础分布(如标准正态分布)中采样一批数据。
- 通过模型进行转换:将这批数据通过训练好的 Normalizing Flow 模型进行转换。
- 得到生成样本:转换后的数据即为生成的样本,它们应该与目标分布Px相似。
注意事项:
- 可逆性:确保模型中的每个转换层都是可逆的,以便能够计算概率密度和进行采样。
- 计算效率:Normalizing Flows 涉及到多次转换和概率密度的计算,因此需要确保这些操作是高效的。使用高效的实现和并行计算可以加速训练和采样过程。
- 模型复杂性:Normalizing Flows 的性能通常与模型的复杂性成正比。通过增加转换层的数量和复杂性,你可以提高模型的表达能力,但也可能增加过拟合的风险和计算成本。因此,需要在模型复杂性和性能之间进行权衡。
https://wiki.ubc.ca/Course:CPSC522/NormalizingFlows
https://deepgenerativemodels.github.io/notes/flow/
https://mbrubake.github.io/cvpr2021-nf_in_cv-tutorial/Introduction%20-%20CVPR2021.pdf















 365
365











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









