






摘要
除了当前引起越来越多关注的对话聊天机器人或面向任务的对话系统外,我们进一步开发一种自动医学诊断的对话系统,该系统通过与患者对话,以收集超出其自我描述以外的其他症状,并自动诊断。除了对话对话系统自身的挑战(例如主题转移的连贯性和问题理解)外,自动医学诊断在医学知识和症状 - 疾病关系的背景下进一步提出了对对话合理性的更关键要求。现有的对话系统主要依赖于数据驱动学习,并且无法编码外部专家知识图谱。在这项工作中,我们提出了一个End-to-End Knowledge-routed Relational Dialogue System(KR-DS),该系统将丰富的医学知识图谱无缝地纳入对话管理的主题转移中,并与自然语言的理解和自然语言生成合作。我们引入了一个新的知识路由深度Q-network(KR-DQN)来管理主题转移,KR-DQN整合了一个关系修正分支,用于编码不同症状和症状对之间的关系,以及用于主题决策的知识路由图分支。在公共医学对话数据集的广泛实验表明,我们的KR-DS可以击败现有方法(诊断准确性超过8%)。我们进一步展示了KR-DS在新收集的医学对话系统数据集上的优势,该数据集在保留原始的自我描述和患者和医生之间的对话数据方面更具挑战性。
1.介绍
面向任务的对话旨在通过使用自然语言在系统与用户之间进行交互来完成特定的任务,这在不同的应用领域中获得了研究兴趣,包括电影预订,餐厅预订,在线购物和技术支持。在医疗领域,对患者进行医学诊断的对话系统旨在获得其他症状并自动进行诊断,该系统在简化诊断流程并降低从患者收集信息的成本方面具有巨大潜力。此外,对话系统生成的患者状况报告和初步诊断报告可能会帮助医生更有效地进行诊断。
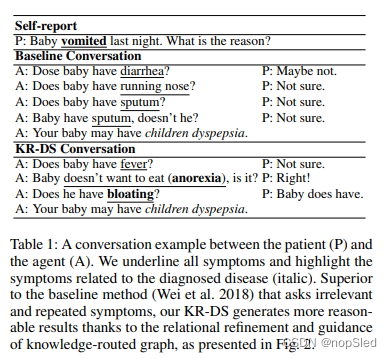
但是,医学诊断的对话系统不仅在具有医学知识的背景下对对话合理性提出了严格的要求,还对症状 - 疾病关系的理解具有较高的要求。对话系统查询到的症状应与潜在疾病相关,并且与医学知识保持一致。当前的任务对话系统极大地依赖于复杂的信念跟踪器和纯数据驱动的学习,这种学习由于缺乏医学知识无法直接用于自动诊断。最近的一项工作构建了一个用于医疗诊断的对话系统,该系统将对话系统作为马尔可夫决策过程,并通过强化学习训练了对话策略。然而,这项工作仅通过数据驱动学习来管理主题转移(即确定应询问哪些症状),其结果是复杂和重复的,如表1所示。而且,这项工作的目标是使用对话状态跟踪和策略学习的对话管理,自然语言处理仅使用基于模版的模型,这无法和真实的自动诊断场景相匹配。
为了应对上述挑战,我们提出了一个用于自动诊断的完全端到端的知识路由关系对话系统(KR-DS),该系统将丰富的医学知识图谱和症状 - 疾病关系无缝地纳入对话管理的主题转移中( DM),并与自然语言理解(NLU)和自然语言产生(NLG)联合,如图1所示。
通常,医生根据医学知识和诊断经验确定诊断结果。受到此启发,我们为对话管理设计了一个新的Knowledge-routed Relational Deep Q-network(KR-DQN),该对话管理集成了知识路由的图分支和一个关系修正分支,充分利用了医学知识和历史诊断案例(医生经验)。关系修正分支从历史诊断数据中自动学习不同症状和症状 - 疾病对之间的关系,以完善从基本DQN产生的粗糙结果。知识路由的图分支通过基于条件概率的精心设计的医学知识图路由来帮助策略决策。因此,如表1所示,这两个分支可以从知识指导和关系编码产生更合理的决策结果。
此外,现有的数据集无法支持我们的端到端对话系统的训练,因为它仅包含用户目标,而不是完整的对话数据。因此,我们通过从在线医疗论坛中的患者和医生之间的自我描述和对话中提取症状和疾病来构建收集新数据集。我们的数据集保留了医生和患者之间的原始自我描述和对话,以使用真实的对话数据来训练NLU组件,这与现实的诊断场景相匹配。
我们的贡献总结为以下几个方面:
1)我们提出了一个端到端的知识路由关系对话系统(KR-DS),该系统将医学知识图谱无缝地纳入对话管理主题转移中,并与自然语言理解和自然语言生成相联合。
2)引入了一个新的知识-路由深度Q网络(KRDQN)来管理主题转移,且通过整合关系修正分支,用于编码不同症状和症状 - 疾病对之间的关系,以及用于主题决策的知识路由的图分支。
3)我们构建了一个新的针对端到端医疗对话系统的数据集,该数据集保留了原始的自我描述和患者和医生之间的对话数据。
4)在两个医学对话系统数据集的广泛实验显示了我们的KR-DS的优势,该数据的诊断准确性大大超过了基线8%以上。
2.相关工作
RNN架构的成功驱动了对对话系统的研究,因为它能够构建状态的潜在表示,从而避免了人为构建状态标签的需求。序列到序列模型也已成功用于任务对话系统。 (Zhao et al. 2017) 提出的框架使编码器-解码器模型能够完成独立的决策并与外部数据库进行交互。 (Chen et al. 2018) 通过将层次结构和变分记忆网络添加到神经Encoder-Decoder网络中,提出了一个层次记忆网络。尽管这些体系结构具有更好的语言建模能力,但它们在知识检索或知识推理中效果不佳,而且这些模型都倾向于生成简短且通用的响应。
另一个研究路线来自知识库的利用。(Young et al. 2017) 研究了常识知识对对话中概念覆盖的影响。(Liu et al. 2018) 提出了一个神经知识扩散模型,将知识引入对话生成中。(Eric et al. 2017) 注意到,面向任务的对话系统通常很难与知识库平滑链接,他们通过使用key-value检索机制来增强端到端结构以解决该问题。
此外,还有两种与我们研究有关的工作,其将深度强化学习应用于自动诊断。但是,他们仅针对对话管理进行对话状态跟踪和策略学习。此外,他们所使用的数据是模拟或简化的,无法反映出真实诊断的情况。在我们的工作中,我们不仅执行关系建模来引入相关症状和疾病,还可以按照以前的医学知识来指导策略学习。我们进一步介绍了一种用于自动诊断的面向任务的对话系统,并且提供了一个新的医疗对话数据集,该数据集能更好地匹配现实情况。
3.Proposed Method
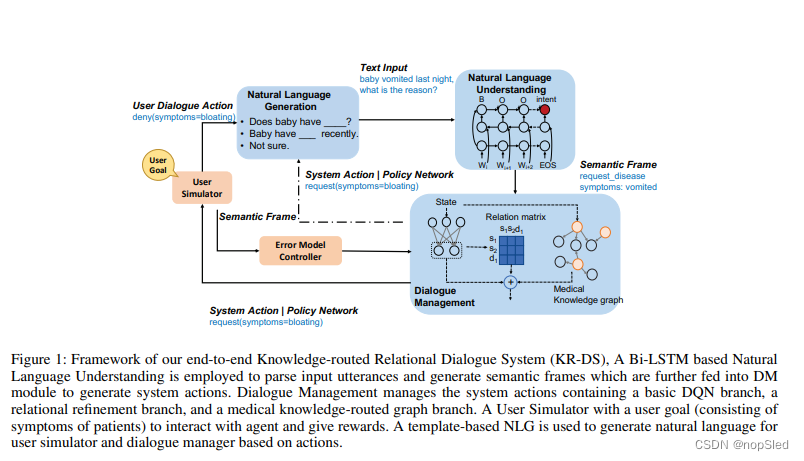
我们的端到端知识路由关系对话系统(KR-DS)在图1中进行了说明。作为面向任务的对话系统,它包含自然语言理解(NLU),对话管理(DM)和自然语言生成(NLG)。NLU识别用户的意图和槽值对。然后DM根据当前的对话状态执行主题转移。DM中的agent将学会去请求症状来执行诊断任务并通知疾病以进行诊断。给定预测的系统动作,自然语言句子由基于模版的NLG生成。此外,为了通过强化学习以端到端的方式训练整个系统,添加了用户模拟器来生成以用户目标为条件的对话交互。
3.1 Natural Language Understanding
在我们的任务中,NLU主要用于对中文的意图进行分类和填写,因为我们的数据集是从中国网站收集的。我们使用开源的中文分词工具,并将医学术语添加到自定义词典中以提高准确性。给定一个单词序列,NLU分类意图并填充一组槽值对以形成语义框架。 如图1所示,语义框架是包含用户意图和槽值对的结构化数据。特别地,在我们自动诊断对话系统中考虑了六种类型的意图。对于用户,有四种类型的意图,包括request+disease,confirm+symptom,deny+symptom和not-sure+symptom。我们应用流行的BIO格式来标注句子中的每个单词。
随后,给定一个单词序列,我们应用BI-LSTM来识别每个单词的BIO标签,并同时对该句子的意图进行分类。完成标签标注后,我们根据对话上下文信息和规整后的医学术语来填充槽。症状和疾病需要规整为标注者定义的医学术语。关于上下文理解,我们维护基于规则的对话状态跟踪器,该跟踪器存储症状的状态。我们将当前语义框架的槽值对表示为固定长度的症状向量(每个位-1、1、 -2、0),然后再加上最后症状向量以获得新的症状矢量。如果agent请求了一个症状并恰好没在用户回答中出现,则此方法还可以通过参考记录的请求槽来填充槽。
由于我们的数据集中标注了症状和意图,因此我们使用有监督的学习来训练双向LSTM模型。此外,经过预训练后,可以通过强化学习与我们的KR-DS中的其他部件共同训练NLU。
3.2 Policy Learning with KR-DQN

(1)Overview
我们在强化学习框架中设计了DM。对话管理器是agent通过对话策略与环境(用户模拟器)进行交互。优化后的对话策略会选择具有最大未来奖赏的动作,这种方式适合用来解决诊断对话系统的问题。如下所示,我们首先描述了该任务中强化学习的基本元素。假设我们具有
M
M
M个疾病,
N
N
N症状。那么agent包含四种类型的动作:inform+disease,request+disease,thanks和closing。因此,agent动作空间大小
D
D
D表示为
D
=
n
u
m
_
g
r
e
e
t
i
n
g
+
M
+
N
D=num\_greeting+M+N
D=num_greeting+M+N。用户动作包含:request+disease,confirm/deny/not-sure+symptom和closing。在症状矢量中,也有四种类型的症状状态,即positive,negative,not-sure和not mentioned,分别表示为1,-1,-2,0。在每个回合中,对话状态
s
t
s_t
st都包含用户和agent的上一个动作,已知症状表示和当前轮次信息。
奖赏对于策略学习非常重要。在我们的任务中,我们鼓励agent做出正确的诊断并惩罚错误的诊断。此外,同样鼓励简短的对话和精确的症状要求。因此,我们设计的奖赏如下,如果诊断成功则为
+
44
+44
+44,如果失败则为
−
22
-22
−22。对于每个对话轮次,我们仅对无法命中现有的症状请求应用
−
1
-1
−1的惩罚。至于不同奖赏的比较,我们在消融部分中展示了几个实验结果。最后,对话策略
π
π
π描述了agent的动作。它将状态
s
t
s_t
st作为输入,并输出所有可能的动作
π
(
a
t
∣
s
t
)
π(a_t|s_t)
π(at∣st)上的概率分布。
DQN在许多问题中是一个通用的策略网络,包括玩游戏,视频字幕生成。除了具有简单多层感知器(MLP)的DQN之外,我们还通过考虑对医学知识和先前动作之间的关系来建模以产生合理的动作,因此提出了一种新的Knowledge-routed Relational DQN(KR-DQN)。
(2)Basic DQN Branch
我们首先利用基本的DQN分支来生成粗糙的动作结果,如等式(1)中的MLP是以状态
s
t
s_t
st为输入,并输出粗糙的动作结果
a
t
r
∈
R
D
a^r_t∈R^D
atr∈RD。MLP的结构是一个简单的具有隐藏层的神经网络,其中隐藏层的激活函数是修正线性单元。
a
t
r
=
M
L
P
(
s
t
)
.
(1)
a^r_t=MLP(s_t).\tag{1}
atr=MLP(st).(1)
(3)Relational Refinement Branch
关系模块可以通过从其他元素(例如其他的症状和疾病)集合中汇总信息来影响单个元素(例如症状或疾病)。由于关系权重通过任务目标自动学习,因此关系模块可以在元素之间建模依赖性。因此,我们通过引入一个关系矩阵
R
∈
R
D
×
D
R∈R^{D×D}
R∈RD×D来设计一个关系修正模块,用于表示所有动作之间的依赖性。最初被预测的动作
a
t
r
a^r_t
atr乘以此可学习的关系矩阵
R
R
R以获得修正后的动作
a
t
f
∈
R
D
a^f_t∈R^D
atf∈RD,如等式(2)所示。关系矩阵是不对称的,代表了有向加权图。关系矩阵的每一列的和为1,并且修正动作向量
a
t
f
a^f_t
atf中的每一个元素是初始预测动作向量的加权,其中权重用于表示元素之间的依赖关系。
a
t
f
=
a
t
r
⋅
R
.
(2)
a^f_t=a^r_t\cdot R.\tag{2}
atf=atr⋅R.(2)
关系矩阵
R
R
R由数据集统计的条件概率初始化。每一项
R
i
j
R_{ij}
Rij表示以单元
x
i
x_i
xi为条件的单元
x
j
x_j
xj的概率。关系矩阵学会通过反向传播来捕获动作之间的依赖性。我们的实验表明,这种初始化方法比随机初始化更好,因为先验知识可以指导关系矩阵学习。
(4)Knowledge-routed Graph Branch
在接受患者的自我描述时,医生首先理解患者可能有多种候选疾病。随后,通过请求这些候选疾病的症状,医生依次排除了其他候选疾病,直到确认诊断为止。受此启发,我们设计了一个知识路由的图模块,以模拟医生的思维过程。
如图2所示,我们首先计算出疾病和症状之间的条件概率,以作为医学知识路由图谱的有向边权重,其中图谱有两种类型的节点(疾病和症状)。每个边都有两个权重,一个是从疾病到症状的条件概率,被表示为
P
(
s
y
m
∣
d
i
s
)
∈
R
M
×
N
P(sym|dis)∈R^{M×N}
P(sym∣dis)∈RM×N,一个是从症状到疾病的条件概率,表示为
P
(
d
i
s
∣
s
y
m
)
∈
R
N
×
M
P(dis|sym)∈R^{N×M}
P(dis∣sym)∈RN×M。
在与患者的沟通过程中,医生可能提出几种候选疾病。我们将候选疾病的概率表示为与观察到的症状相对应的疾病概率。症状先验概率
P
p
r
i
o
r
(
s
y
m
)
∈
R
N
P_{prior}(sym)∈R^N
Pprior(sym)∈RN通过以下规则计算。对于上述症状,确认的症状设置为1,而否定的症状设置为-1,以阻止其相关疾病。至于其他症状(不确定或没提及的症状),其概率设置为从数据集中计算出的先验概率。然后这些症状概率
P
p
r
i
o
r
(
s
y
m
)
P_{prior}(sym)
Pprior(sym)乘以条件概率
P
(
d
i
s
∣
s
y
m
)
P(dis|sym)
P(dis∣sym)获得疾病概率
P
(
d
i
s
)
P(dis)
P(dis),该概率为:
P
(
d
i
s
)
=
P
(
d
i
s
∣
s
y
m
)
⋅
P
p
r
i
o
r
(
s
y
m
)
.
(3)
P(dis)=P(dis|sym)\cdot P_{prior}(sym).\tag{3}
P(dis)=P(dis∣sym)⋅Pprior(sym).(3)
当选择到一些候选疾病,医生经常会询问一些该疾病的明显症状,以根据其医学知识确认诊断。同样,对于疾病概率
P
(
d
i
s
)
P(dis)
P(dis),症状概率
P
(
s
y
m
)
P(sym)
P(sym)是通过疾病概率
P
(
d
i
s
)
P(dis)
P(dis)和条件概率矩阵
P
(
s
y
m
∣
d
i
s
)
P(sym|dis)
P(sym∣dis)之间的矩阵乘获得的:
P
(
s
y
m
)
=
P
(
s
y
m
∣
d
i
s
)
⋅
P
(
d
i
s
)
.
(4)
P(sym)=P(sym|dis)\cdot P(dis).\tag{4}
P(sym)=P(sym∣dis)⋅P(dis).(4)
我们拼接疾病概率
P
(
d
i
s
)
∈
R
M
P(dis)∈R^M
P(dis)∈RM和症状概率
P
(
s
y
m
)
∈
R
N
P(sym)∈R^N
P(sym)∈RN,并用零填充的greeting动作,以获取知识 - 路由的动作概率
a
t
k
∈
D
a^k_t∈D
atk∈D。
对于三个动作矢量
a
t
r
a^r_t
atr,
a
t
f
a^f_t
atf和
a
t
k
a^k_t
atk,我们首先将sigmoid激活函数应用于
a
t
r
a^r_t
atr和
a
t
f
a^f_t
atf,以获得动作概率。随后,我们对这三个动作求和来作为KR-DQN在当前状态
s
t
s_t
st的预测动作分布
a
t
a_t
at。
a
t
=
s
i
g
m
o
i
d
(
a
t
r
)
+
s
i
g
m
o
i
d
(
a
t
f
)
+
a
t
k
(5)
a_t=sigmoid(a^r_t)+sigmoid(a^f_t)+a^k_t\tag{5}
at=sigmoid(atr)+sigmoid(atf)+atk(5)
为了防止重复请求,我们将症状过滤添加到KR-DQN输出中。所有组件均经过精心设计的奖赏(在本节开头描述)来训练,以鼓励KR-DQN学习如何请求有效症状并做出正确的诊断。
3.3 User Simulator

为了训练我们的端到端对话系统,我们使用用户模拟器从实验数据集中采样用户目标,以实现和对话系统的自动交互。与 (Schatzmann and Young 2009)相同,我们的用户模拟器维护一个用户目标
G
G
G。如图3所示,用户目标通常由四个部分组成:用户的疾病标签,对原始患者的自我描述,患者和医生交谈过程中的隐性症状,以及用户需要请求的槽。当agent在对话过程中请求症状时,用户将选择三个动作之一,包括确认症状,否定症状,以及对症状的不确定描述。如果agent告知了正确的疾病,则对话过程将被作为成功而终止。相反,如果ganet进行了错误的诊断或对话转轮次达到最大次数
T
T
T,则对话过程认为失败。
3.4 Natural Language Generation
给定对话管理和用户模拟器生成的动作,我们的系统中应用了基于模板的自然语言生成(Template-NLG)来生成自然语言句子。如NLU部分中所述,请求和通知对相对简单。以前的对话系统具有许多可能的请求/通知模式,但每个对话系统都只有一个模板。与它们不同,我们为每个动作设计了4到5个模板,以使对话多样化。至于对话中使用的医学术语,类似于NLU,我们选择了与我们收集的医学术语清单中特定症状和疾病相对应的日常表达。
3.5 End-to-End Training With Deep Q-Learning
与 (Mnih et al. 2015) 相同,我们采用深度Q学习来训练具有微调NLU和基于模版NLG的DM。我们的系统中应用了两个重要的DQN技巧,即目标网络和经验回放的使用。我们使用
Q
(
s
t
,
a
t
∣
θ
)
Q(s_t,a_t|θ)
Q(st,at∣θ)表示在状态
s
t
s_t
st时选择动作
a
t
a_t
at的期望累积衰减奖赏。然后根据贝尔曼方程,可以写为:
Q
(
s
t
,
a
t
∣
θ
)
=
r
t
+
γ
m
a
x
a
t
+
1
Q
∗
(
s
t
+
1
,
a
t
+
1
∣
θ
′
)
(6)
Q(s_t,a_t|\theta)=r_t+\gamma~max_{a_{t+1}}Q^*(s_{t+1},a_{t+1}|\theta')\tag{6}
Q(st,at∣θ)=rt+γ maxat+1Q∗(st+1,at+1∣θ′)(6)
其中,
θ
′
θ'
θ′是从上一个episode获得的目标网络的参数,
γ
γ
γ是衰减率。我们在训练阶段使用
ϵ
−
g
r
e
e
d
y
\epsilon-greedy
ϵ−greedy方法进行有效的动作空间探索,其中以概率KaTeX parse error: Undefined control sequence: \spsilon at position 1: \̲s̲p̲s̲i̲l̲o̲n̲来选择随机动作。我们将agent每个时刻的经验存储在经验回放缓冲区中,每个元素表示为
e
t
(
s
t
,
a
t
,
r
t
,
s
t
+
1
)
e_t(s_t,a_t,r_t,s_{t+1})
et(st,at,rt,st+1)。如果当前网络的性能优于所有以前的型号,则缓冲区会清空。

















 1616
1616

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









