






摘要
Sparse Mixture-of-Experts (MoE) 是一种神经网络结构设计,可用于在不增加推理成本的情况下为大语言模型(LLM)添加可学习的参数。指令微调是训练LLM遵循质量的一种技术。我们主张将这两种方法结合在一起,因为我们发现MOE模型比密集模型更可以从指令微调中受益。特别是,我们对三个实验设置进行了经验研究:(i)对缺乏指令微调的单个下游任务进行直接微调;(ii)先进行指令微调,然后在下游任务上进行few-shot或zero-shot泛化;(iii)通过对单个下游任务进行进一步指令微调。在第一种情况下,MoE不如具有相同计算能力的密集模型。然而,随着指令微调的引入(第二和第三种情况),这种情况会发生巨大变化,指令微调是独立或与特定于任务的微调一起使用的。我们最强大的模型FLAN-MOE32B在四个基准任务上超过了FLAN-PALM62B的性能,而仅使用了三分之一的FLOPs。FLAN-MOE所体现的进步激发了对任务无关的学习框架中大规模,高性能语言模型的设计原理的重新评估。
1.介绍
近年来,由于越来越大且复杂的深度学习模型的发展,自然语言处理(NLP)领域取得了显着进步。在这些模型中,由于它们在捕获复杂的语言模式并泛化到多样化上下文的无与伦比的能力,因此,基于transformer的语言模型已成为广泛NLP任务的事实上的标准。训练此类模型的一个特别成功的范式是指令微调,它通过调整预训练表示来遵循自然语言指令,以提高其在特定任务上的性能。
尽管大型语言模型(LLM)的好处是无可争议的,但它们迅速增长的规模和计算要求在训练效率,内存占用和部署成本方面构成了重大挑战。因此,迫切需要开发可扩展的技术,该技术可以利用这些模型的力量而不会产生过度的计算开销。
另一方面,具有sparsely activated Mixture of Experts (MoEs) 模型显着降低了LLM的计算成本。MoE模型基于这样一个观察而构建,即语言模型可以解耦为较小的专业子模型或“专家”,这些模型关注输入数据的不同方面,从而实现了更有效的计算和资源分配。但是,我们表明,传统,特定于任务微调的MoE模型会导致次优性能,甚至比具有相同计算成本的微调密集模型还要差。可能的原因之一是通用预训练和特定于任务微调之间的差异。
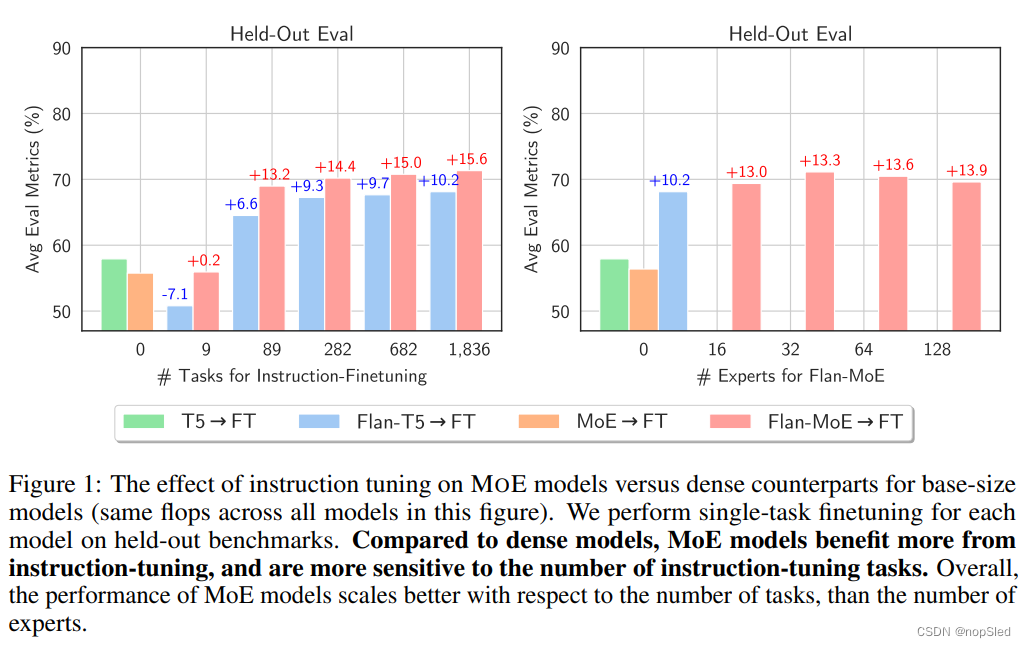
在本文中,我们阐明了在Mixture-ofExperts (MoE) 模型的背景下进行指令微调的关键作用,特别是其在下游任务上的成功可扩展性。我们通过两倍的分析来证明这一点:首先,我们针对特定任务的下游微调,扩展了指令微调的已知好处,这说明了与其密集模型相比,将其应用于MoE模型时,其影响明显更大。其次,我们强调了对MoE模型进行指令微调阶段的必要性,其在下游和扩展任务上超过了密集模型的性能。我们独特的融合FLAN-MOE,是建立在Flan mixture上的指令微调模型,它成功地利用了指令微调和稀疏MOE技术的优势。FLAN-MOE有效地扩大了语言模型,而无需增加计算资源或内存需求。
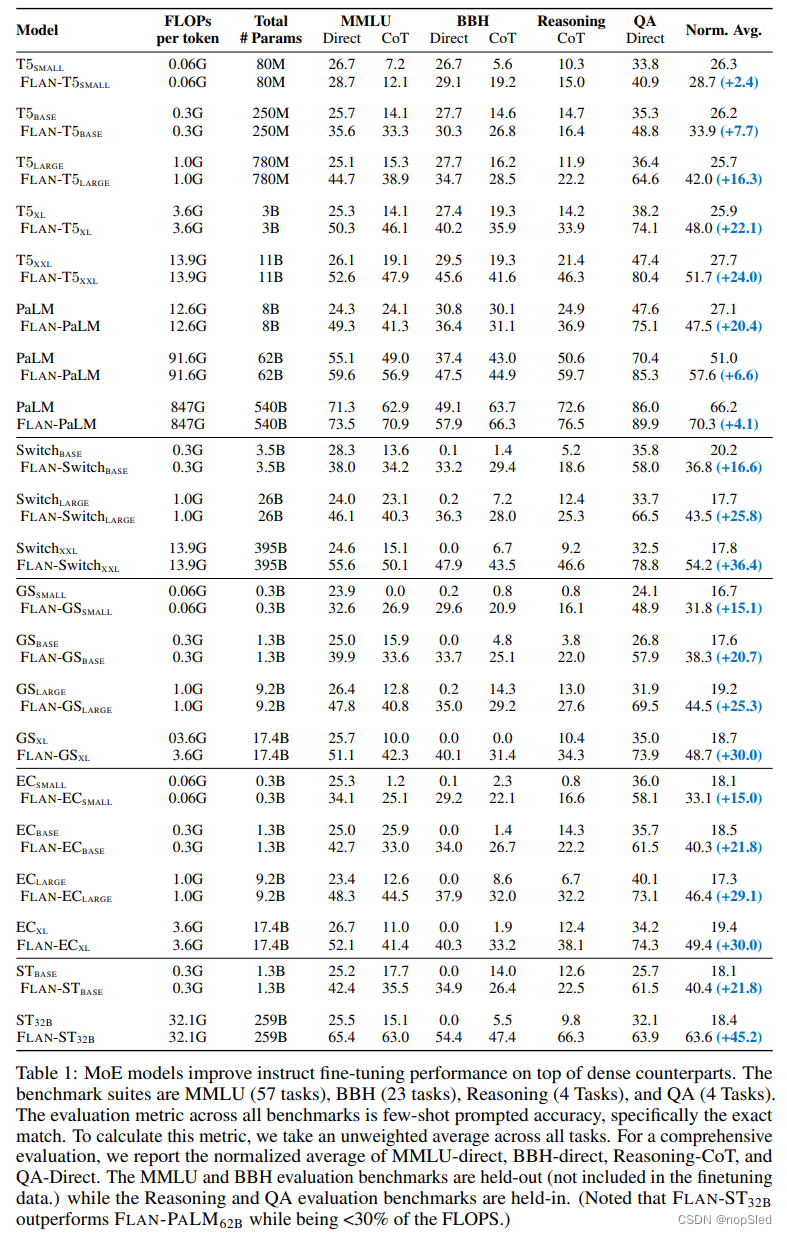
我们将模型FLAN-MOE对一系列任务进行测试,其中包括自然语言理解,推理和问答。我们的评估框架由三个不同的设置组成:(i)直接在单个下游任务上微调模型;(ii)先进行指令微调,然后在下游任务上进行few-shot或zero-shot泛化;(iii)通过对单个下游任务进行进一步指令微调。结果显示了FLAN-MOE在第二和第三个设置中的高度优势。值得注意的是,这些进步在不需要增强计算资源或内存要求的情况下就可实现。实际上,我们的最优模型,在四个单独的基准测试中超越了FLAN-PALM的性能,且仅需每个token计算成本的三分之一。
总而言之,我们的贡献如下:
- 我们确定了指令微调在MoE模型效果中的关键作用:(1)我们证明,与下游任务上的密集模型相比,在没有指令微调的情况下,MoE模型的性能略差。(2)我们强调,当补充指令微调时,MoE模型在下游任务上超过了密集模型的性能,并泛化到zero-shot和few-shot任务。
- 我们提供了一系列的实验,对经过指令微调的不同MoE模型的性能进行了比较分析。
2.Method
2.1 Model Architecture
我们在FLAN-MOE模型中应用了 sparsely activated Mixture-of-Experts (MoE)。 与Switch Transformer类似,我们用MoE层代替了其他每个Transformer层的feed-forward组件。每个MoE层都由一组独立的前馈网络组成,作为“专家”。然后,门控函数使用softmax激活来对这些专家的概率分布进行建模。此分布表示每个专家能够处理传入输入的能力。即使每个MoE层都有更多参数,但专家也被稀疏化激活。这意味着对于给定的一个输入token,仅使用有限的专家子集,这在限制计算资源的同时,给模型具有更多能力。在我们的架构中,子集大小取决于路由策略。每个MoE层的可学习的门控网络都经过训练,以使用其输入来激活输入序列中每个token的最优两个专家。在推理期间,学好的门控网络动态为每个token选择两个最优专家。对于具有 E E E个专家的MoE层,这实质上为前馈层提供了 O ( E 2 ) O(E^2) O(E2)种不同的组合,而不是经典Transformer结构中的一个,从而实现了更大的计算灵活性。token的最终学习表示将是所选专家输出的加权组合。
2.2 Instruction Fine-tuning Recipe
我们使用Flan收集数据集上的前缀语言模型目标微调FLAN-MOE。每个FLAN-MOE将在继承预训练期间的辅助损失设置。所有模型参数将被更新。我们根据相对位置嵌入,将每个FLAN-MOE的输入序列长度调整为2048,输入调整为512。dropout率为0.05,专家dropout率为0.2。学习率为 1 e − 4 1e^{-4} 1e−4。优化器设置遵循[4]。
3.Experiment
4.Discussion
4.1 Finetuing Strategy
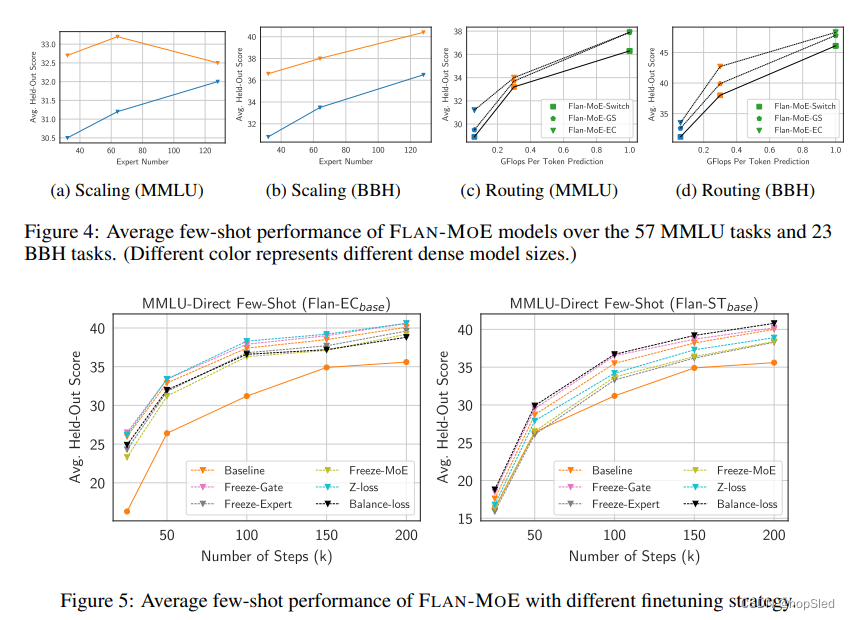
稀疏模型在大型数据集中表现出色,但有时在微调数据受到限制时的性能很差。指令微调也可以视为一个持续的微调阶段,因此我们介绍了一项详细的研究,以了解不同因素如何影响FLAN-MOE的指令微调性能并提供实用配方。这里的所有讨论均基于对
F
L
A
N
−
E
C
B
A
S
E
/
F
L
A
N
−
S
T
B
A
S
E
FLAN-EC_{BASE}/FLAN-ST_{BASE}
FLAN−ECBASE/FLAN−STBASE进行100K步的指令微调。
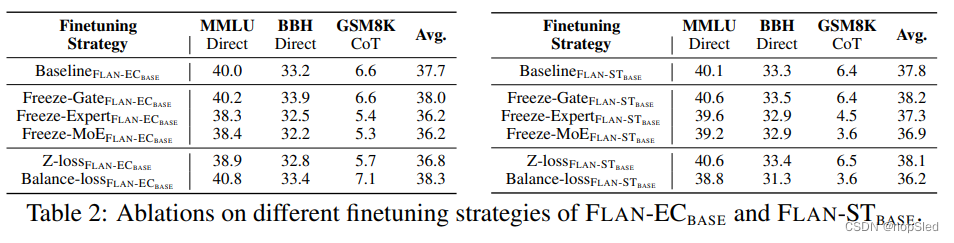
Auxiliary Loss。辅助损失的融合有助于通过促进专家知识的多元化并提高sparsely gated mixture-of-expert模型的泛化能力来减轻过拟合的风险。此外,可以采用辅助损失来解决特定问题,例如专家之间的负载平衡或防止专家崩溃,这可以进一步提高模型的整体性能。我们尝试使用[23]中的平衡损失和表2中[56]使用的路由器Z-loss。平衡损失的实现有助于提高
F
L
A
N
−
E
C
B
A
S
E
FLAN-EC_{BASE}
FLAN−ECBASE在MMLU,BBH和GSM8K的性能,而Z-loss导致性能恶化。相反,对于
F
L
A
N
−
S
T
B
A
S
E
FLAN-ST_{BASE}
FLAN−STBASE,我们观察到了一种相反趋势。我们猜想,预训练期间的辅助损失与指令微调之间的不一致可能会破坏优化过程,从而导致次优优化的FLAN-MOE模型。
Expert/Gating Freeze。为了增强稀疏模型的泛化能力和防止过拟合,研究人员发现,微调模型参数的一部分会导致ST-MoE模型的泛化性能提高,如ST-MoE在研究中所指出的那样。有趣的是,观察到更新非MoE参数会产生与更新所有参数的相似结果,同时仅更新专家参数的性能会稍好一些。
如表2所示,我们通过分别冻结给定模型的门控函数,专家模块和MoE参数进行了实验。结果表明,冻结专家或MoE组件会对性能产生负面影响。相反,冻结门控会稍微改善性能,尽管不是特别显着。我们假设该观察结果与图5所示的FLAN-MOE的拟合不足有关,该图描绘了微调数据效率的消融研究。
Hyperparameter Sensitivity。遵循ST-MoE,我们进一步尝试了专家dropout(
0.0
,
0.1
,
0.5
0.0,0.1,0.5
0.0,0.1,0.5),改变了学习率(
1
e
−
4
,
5
e
−
4
,
1
e
−
3
1e^{-4},5^{e-4},1e^{-3}
1e−4,5e−4,1e−3)和batch大小(16、32、64) ,来检查FLAN-MOE对超参数的灵敏度。我们发现,性能在不同的任务上有所不同,但在所有超参数方面并不显着,但是较低的学习率和较小的batch大小会导致模型在大规模上具有更稳定的指令微调过程。
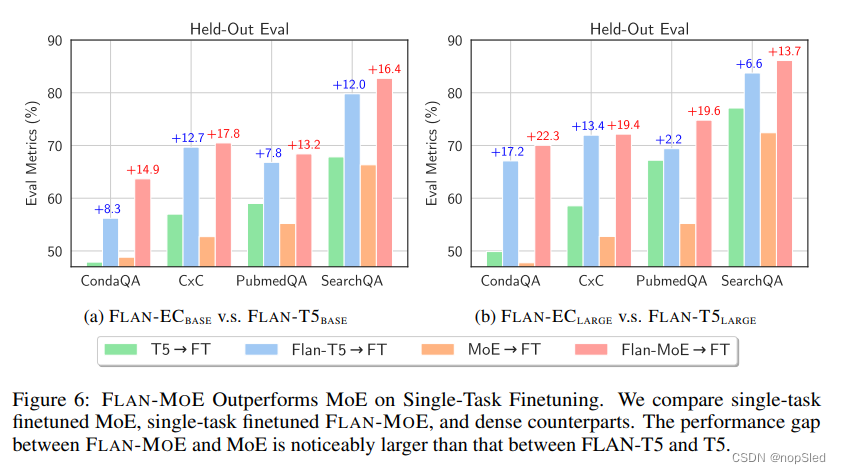
Finetuning v.s. Instruction Finetuning。为了比较直接微调FLAN和FLAN-MOE之间的差距,我们在图6中尝试了单任务微调MOE,单任务微调FLAN-MOE和密集模型。
4.2 Additional Analysis

















 441
441

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









