






 本文提出了一种名为 SoRA 的新方法,用于以参数高效的方式微调预训练大语言模型。它扩展了 LoRA 方法,能在适应过程中动态调整内部秩。通过结合近端梯度方法优化的门控单元控制秩的基数,推理阶段消除归零秩对应参数块。实验表明,SoRA 用更少参数和时间可优于其他基线。
本文提出了一种名为 SoRA 的新方法,用于以参数高效的方式微调预训练大语言模型。它扩展了 LoRA 方法,能在适应过程中动态调整内部秩。通过结合近端梯度方法优化的门控单元控制秩的基数,推理阶段消除归零秩对应参数块。实验表明,SoRA 用更少参数和时间可优于其他基线。
摘要
以参数高效的方式微调预训练的大语言模型因其有效性和高效性而被广泛研究。流行的低秩适应方法(LoRA)提供了一种合理的方法,假设适应过程本质上是低秩的。尽管 LoRA 表现出了值得称赞的性能,但它是通过固定且不可更改的内部秩来实现的,这可能并不总是理想的选择。认识到需要更灵活的适应,我们将 LoRA 的方法扩展到一种称为sparse low-rank adaptation (SoRA) 的新方法,该方法能够在适应过程中动态调整内部秩。我们通过在训练阶段结合了使用近端梯度方法来优化的门控单元来实现这一点,这是一种在门的稀疏性下控制秩的基数。在随后的推理阶段,我们消除了与归零秩对应的参数块,以将每个 SoRA 模块还原为简洁但秩最优的 LoRA。我们的方法通过用更高的秩来初始化 LoRA 以增强 LoRA 的表示能力,同时通过稀疏方式更新有效地控制暂时增加的参数数量。我们进一步引入了 SoRA 的稀疏调度器,旨在检查非零参数数量对模型记忆和泛化的影响。我们的实验结果表明,使用 70% 的参数和 70% 的训练时间,SoRA 也可以优于其他基线。
1.介绍
以参数高效的方式适应大规模预训练语言模型在研究界越来越受到关注。这种范式的方法通常保持底层模型的大部分参数不变,要么在模型中插入额外的可训练参数,要么指定少量可训练参数,要么将适应过程重新参数化为更有效的形式。它们已被验证在各种模型和任务中都是有效的,通常会产生与全参数微调相当甚至更好的结果。
经过对参数高效微调性能的广泛验证后,其发展潜力变得显而易见。这些方法提供了调整base模型以适应任何数据的机会,从而允许针对特定任务和个性化用户特征来定制语言模型以进行增强和自定义。由于被优化参数的轻量级特性,它们可以无缝插入模型中,从而可以进行有针对性的增强。在这些方法中,低秩适应(LORA)被认为是目前最有效的方法之一。它假设自适应后模型参数的变化是“本质上低秩的”,并通过优化低秩分解得到的矩阵来进行自适应。LoRA 避免了因插入额外的神经模块而导致的前向传播延迟,同时表现出稳定的性能。尽管有效,但内部秩的设置上仍然不清楚(通常作为超参数)。直观上,更大的秩带来更大的优化空间,并能处理更具挑战性任务。然而,在实践中,最佳内部秩会根据骨干模型和任务等多种因素而变化。
考虑到在大规模模型(例如具有 1750 亿参数的 GPT-3 和具有 7 亿到 650 亿参数的 LLaMA)上搜索超参数的巨大计算成本,开发基于自适应秩的方法是一种自然的方法。一些现有的工作试图探索这个方向,但它们很大程度上是启发式的或引入了额外的成本。在本文中,我们提出了 SoRA,一种简单、有效、自动化的自适应参数高效微调方法。我们引入了一个在 L1 正则化下具有近端梯度下降更新的门控模块来控制更新矩阵的稀疏性。训练后,门控向量中记录为零的下投影矩阵的列和上投影矩阵的行,可以简单地删除并以更参数有效的方式存储。与其他自适应方法相比,近端梯度方法具有明确的数学含义,并且不必涉及其他计算和启发式方法。例如,AdaLoRA 引入了一个额外的正则化器,以确保下投影矩阵和上投影矩阵严格遵守奇异值分解(SVD)的定义,并且每个矩阵都是正交的。然而,由于梯度计算,该正则化项会产生大量的计算开销。相反,我们消除了这一要求,而是通过控制中间对角矩阵来选择性地过滤低秩项。我们在第 3 节中详细比较了 SoRA 和相关方法。
SoRA 的机制还允许我们暂时控制稀疏性并研究非零可训练参数的数量与记忆和泛化能力之间的关系。我们提出了一种稀疏调度器,发现模型自适应过程表现出很强的“压缩能力”,即使是一小部分参数(低于 LoRA 等级为 1)也能保持相当大的性能。我们进行了大量的实验来证明我们方法的有效性。特别是,我们的模型可以在各种下游任务上以更少的参数和缩短 30% 的训练时间始终优于参数高效的基线。这项工作的代码将在 https://github.com/TsinghuaC3I/SoRA 公开发布。
2.A Closer Look to Adaptive Rank
Related Work。在介绍我们的方法之前,我们首先简要回顾一下参数高效微调和我们的骨干低秩自适应(LoRA)。参数高效微调是一组仅优化一小部分参数并保持主模型不受影响的方法。一些参数高效的方法会向主干模型插入额外的神经模块或参数,例如适配器、前缀和提示微调。此类方法的另一类尝试指定可训练或可修剪的特定参数。研究人员推导出一系列参数有效方法的变体,以提高有效性或效率。最近,参数高效微调的应用扩展到多模态和指令调优场景。在本文中,我们更多地关注 LoRA,它使用低秩矩阵来近似权重的变化。
在LoRA中,预训练的权重(表示为
W
0
∈
R
p
×
q
\textbf W_0 ∈\mathbb R^{p×q}
W0∈Rp×q)被冻结,可训练的LoRA模块是每个权重矩阵
Δ
=
W
u
W
d
∈
R
p
×
q
Δ =\textbf W_u\textbf W_d ∈\mathbb R^{p×q}
Δ=WuWd∈Rp×q变化的低秩分解矩阵
W
d
∈
R
r
×
q
\textbf W_d ∈\mathbb R^{r×q}
Wd∈Rr×q和
W
u
∈
R
p
×
r
\textbf W_u∈\mathbb R^{p×r}
Wu∈Rp×r。这样,当前层
h
h
h的输出可以表示为
y
←
W
0
x
+
W
u
W
d
x
,
(1)
\textbf y\leftarrow \textbf W_0\textbf x+\textbf W_u\textbf W_d\textbf x,\tag{1}
y←W0x+WuWdx,(1)
其中
r
≪
m
i
n
{
p
,
q
}
r ≪ min\{p,q\}
r≪min{p,q} 是“内部维度”的一个超参数,控制低秩矩阵的大小和可训练参数的数量。在本节中,我们主要关注最后一项,表示为
z
←
W
u
W
d
x
\textbf z←\textbf W_u\textbf W_d\textbf x
z←WuWdx。
Adaptive Rank on LoRA。尽管在易处理性和效率方面取得了很大的进步,LoRA 仍然受到其在选择最佳秩
r
r
r 方面的不灵活性的限制。与可以在训练过程中自适应在线调整的连续超参数(例如学习率和权重衰减)不同,LoRA 秩
r
r
r 采用离散值,因此其变化将直接改变模型结构。秩的最佳选择可能因不同的骨干模型和下游任务而异。保守地选择较大的秩
r
r
r 可能会浪费训练时间和计算资源,而逐渐将
r
r
r 设置得较小可能会降低模型性能并导致从头开始重新训练。这些限制凸显了使用自适应秩选择插件升级 LoRA 的重要性。
近年来,人们提出了多种补救措施来实现 LoRA 秩的灵活调整。例如,Valipour et al. (Valipour et al., 2022) 没有设置固定的秩,而是引入了 DyLoRA,其中预定义的离散分布
p
B
(
⋅
)
p_B(·)
pB(⋅) 被投射到一系列秩选择上。这种方法与nested dropout相关但又不同,可以被视为优化具有不同秩的LoRA模块的混合模型。
尽管如此,直接且确定性地调整 LoRA 秩似乎是一种更有吸引力的方法。为了设计这种方法,我们首先从矩阵的秩与奇异值分解(SVD)之间的联系获得关键提示。让我们用
Δ
:
=
W
u
W
d
Δ :=\textbf W_u\textbf W_d
Δ:=WuWd 表示 LoRA 中的可调增量权重矩阵。然后我们可以将其 SVD 表示为
Δ
p
×
q
=
U
p
×
p
Σ
p
×
q
V
q
×
q
T
,
(2)
Δ_{p\times q}=\textbf U_{p\times p}Σ_{p\times q}\textbf V^T_{q\times q},\tag{2}
Δp×q=Up×pΣp×qVq×qT,(2)
其中
U
\textbf U
U和
V
\textbf V
V分别是正交的,
Σ
Σ
Σ是一个(矩形)对角矩阵,对角元素为
Δ
Δ
Δ的奇异值:
σ
(
Δ
)
=
{
σ
1
≥
σ
2
≥
⋅
⋅
⋅
≥
σ
m
i
n
p
,
q
≥
0
}
σ(Δ) =\{σ_1≥ σ_2 ≥···≥σ_{min{p,q}} ≥ 0\}
σ(Δ)={σ1≥σ2≥⋅⋅⋅≥σminp,q≥0}。为了表示方便,我们将
Σ
Σ
Σ 的对角重塑为列向量:
g
:
=
(
σ
1
,
σ
2
,
.
.
.
,
σ
m
i
n
{
p
,
q
}
)
T
.
(3)
\textbf g:=(σ_1,σ_2,...,σ_{min\{p,q\}})^T.\tag{3}
g:=(σ1,σ2,...,σmin{p,q})T.(3)
然后,令
d
=
m
i
n
{
p
,
q
}
d=min\{p,q\}
d=min{p,q},我们能够将LoRA的前向过程重新形式化为:
z
←
Δ
x
=
U
⋅
,
1
:
d
(
g
⊙
V
⋅
,
1
:
d
T
x
)
,
(4)
\textbf z\leftarrow Δ\textbf x=\textbf U_{\cdot,1:d}(\textbf g\odot\textbf V^T_{\cdot,1:d}\textbf x),\tag{4}
z←Δx=U⋅,1:d(g⊙V⋅,1:dTx),(4)
其中
⊙
\odot
⊙表示逐元素点积(Hadamard积)。请注意,
r
a
n
k
(
Δ
)
=
∣
∣
g
∣
∣
0
rank(Δ)=||\textbf g||_0
rank(Δ)=∣∣g∣∣0,这是
g
\textbf g
g的
ℓ
0
ℓ_0
ℓ0 范数。因此,调整LoRA的秩相当于控制向量
g
\textbf g
g的稀疏性。Zhang et al. 使用名为 AdaLoRA 的方法沿着这条基于 SVD 的轨道前进。在 AdaLoRA 中,向量
g
\textbf g
g 中的元素经过校准,使得非零元素的数量小于预定义的
b
b
b。具体来说,他们只保留重要性得分最高的 top-b 个元素——这是他们新提出的从权重梯度乘积启发式构建的“敏感度”指标。
g
\textbf g
g的非负性被合理地丢弃,因为一个负
g
i
\textbf g_i
gi 可以通过翻转
u
i
\textbf u_i
ui 或
v
i
\textbf v_i
vi 的符号简单地减少为正项。此外,他们通过用正则化项替换正交条件
U
⊤
U
=
I
p
\textbf U^⊤\textbf U = \textbf I_p
U⊤U=Ip 和
V
⊤
V
=
I
q
\textbf V^⊤\textbf V =\textbf I_q
V⊤V=Iq,从而将带约束的优化问题转换为无约束版本:
R
(
U
,
V
)
=
∣
∣
U
T
U
−
I
p
∣
∣
F
2
+
∣
∣
V
T
V
−
I
q
∣
∣
F
2
.
(5)
R(\textbf U,\textbf V)=||\textbf U^T\textbf U-\textbf I_p||^2_F+||\textbf V^T\textbf V-\textbf I_q||^2_F.\tag{5}
R(U,V)=∣∣UTU−Ip∣∣F2+∣∣VTV−Iq∣∣F2.(5)
尽管通过实验证明了其有效性,但 AdaLoRA 仍然存在两个问题,需要重新思考方法并等待进一步改进。首先,AdaLoRA 中的稀疏性选择标准基于他们新提出的重要性分数,该评分依赖于权重梯度乘积的移动平均值。尽管它在实证研究中有效,但该标准很大程度上是启发式的,缺乏理论动机。其次,重要性分数的移动平均运算和等式(5)的正交正则化的梯度都会增加额外的计算成本。与具有上述局限性的 AdaLoRA 相比,我们的方法 SoRA 是一种高度简化的更新规则的改进,并得到稀疏正则化和近端梯度方法理论的支持。SoRA 的详细方法将在下一节中详细阐述。
3. Our Approach
我们的方法稀疏低秩适应(SoRA)的关键思想是通过近端梯度方法训练的稀疏门控单元动态调整训练过程中的内部秩。SoRA 采用了之前介绍的低秩分解框架,因为它的有效性和参数效率得到了广泛验证。
3.1 Sparse Low-rank Adaptation
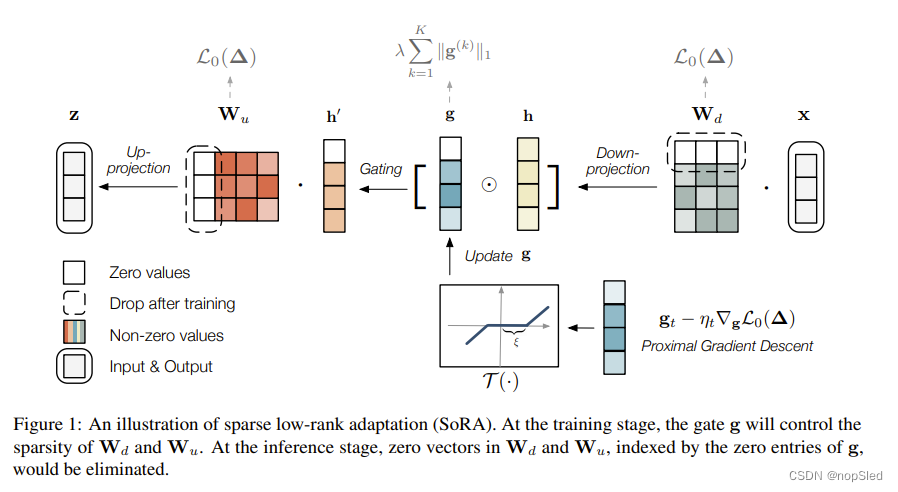
Module Structure。在构建 SoRA 模块之初,我们根据实际或研究问题预先定义了最大可接受的秩
r
m
a
x
r_{max}
rmax。然后,每个SoRA模块将从LoRA继承两个矩阵
W
d
∈
R
r
m
a
x
×
q
\textbf W_d ∈\mathbb R^{r_{max}×q}
Wd∈Rrmax×q和
W
u
∈
R
p
×
r
m
a
x
\textbf W_u ∈ \mathbb R^{p×r_{max}}
Wu∈Rp×rmax,用于下投影和上投影。最大秩
r
m
a
x
r_{max}
rmax设置得相对较大,但我们将在后续段落中展示如何在稀疏意义上有效地训练它。事实上,这是通过在投影矩阵之间注入门控单元
g
∈
R
r
m
a
x
\textbf g ∈ \mathbb R^{r_{max}}
g∈Rrmax 来实现的,它模仿了 SVD 的公式。SoRA模块的前向传播过程如下:
h
⟵
d
o
w
n
p
r
o
j
e
c
t
i
o
n
W
d
x
;
(6)
\textbf h\stackrel{down~projection}{\longleftarrow}\textbf W_d\textbf x;\tag{6}
h⟵down projectionWdx;(6)
h
′
⟵
g
a
t
i
n
g
g
⊙
h
;
(7)
\textbf h'\stackrel{gating}{\longleftarrow}\textbf g\odot \textbf h;\tag{7}
h′⟵gatingg⊙h;(7)
z
⟵
u
p
p
r
o
j
e
c
t
i
o
n
W
u
h
′
;
(8)
\textbf z\stackrel{up~projection}{\longleftarrow}\textbf W_u\textbf h';\tag{8}
z⟵up projectionWuh′;(8)
或者更紧凑表示为:
z
←
W
u
(
g
⊙
(
W
d
x
)
)
.
(9)
\textbf z\leftarrow\textbf W_u(\textbf g\odot(\textbf W_d\textbf x)).\tag{9}
z←Wu(g⊙(Wdx)).(9)
Optimization。我们使用 LoRA 中的随机梯度方法来优化下投影和上投影矩阵,而每个门
g
\textbf g
g 以不同的稀疏性促进方式更新:
g
t
+
1
←
T
η
t
⋅
λ
(
g
t
−
η
t
∇
g
L
0
(
∆
t
)
)
,
(10)
\textbf g_{t+1}\leftarrow \mathcal T_{\eta_t\cdot\lambda}(\textbf g_t-\eta_t∇_g\mathcal L_0(∆_t)),\tag{10}
gt+1←Tηt⋅λ(gt−ηt∇gL0(∆t)),(10)
其中
L
0
(
⋅
)
\mathcal L_0(·)
L0(⋅)是语言模型的原始损失函数,Δ表示完整的可训练参数(包括门),
η
t
>
0
η_t > 0
ηt>0代表第
t
t
t次迭代的步长,
λ
>
0
λ>0
λ>0为 促进稀疏性的正则化强度超参数。此外,上式中的
T
η
t
⋅
λ
(
⋅
)
\mathcal T_{η_t·λ}(·)
Tηt⋅λ(⋅) 代表以下软阈值函数的逐元素广播:
T
ξ
(
x
)
:
=
{
x
−
ξ
,
x
>
ξ
0
,
−
ξ
<
x
<
=
ξ
x
+
ξ
,
x
<
=
−
ξ
(11)
\mathcal T_{\xi}(x):=\begin{cases} x-\xi,& x>\xi\\ 0, & -\xi<x<=\xi\\ x+\xi,& x<=-\xi \end{cases}\tag{11}
Tξ(x):=⎩
⎨
⎧x−ξ,0,x+ξ,x>ξ−ξ<x<=ξx<=−ξ(11)
其中
ξ
=
η
t
⋅
λ
\xi = \eta_t·λ
ξ=ηt⋅λ 为阈值。实际上,等式(10) 中的真实梯度
∇
g
L
0
∇_{\textbf g}\mathcal L_0
∇gL0 由其mini-batch随机对应物近似。
Post-pruning。训练完成后,我们进一步修剪 SoRA 权重以删除归零秩并将模块还原回 LoRA 形式。具体来说,对于第
k
k
k 个 SoRA 模块,令
I
(
k
)
=
{
i
∈
[
1
:
r
m
a
x
]
∣
g
i
(
k
)
=
0
}
(12)
\mathcal I^{(k)}=\{i\in[1:r_{max}]|\textbf g^{(k)}_i=0\}\tag{12}
I(k)={i∈[1:rmax]∣gi(k)=0}(12)
为第
k
k
k 个门控向量
g
(
k
)
\textbf g^{(k)}
g(k) 中零元素的索引。我们删除下投影
W
d
(
k
)
\textbf W^{(k)}_d
Wd(k) 的第
I
(
k
)
\mathcal I^{(k)}
I(k) 行以获得
W
~
d
(
k
)
\widetilde {\textbf W}^{(k)}_d
W
d(k),删除上投影
W
u
(
k
)
\textbf W^{(k)}_u
Wu(k) 的第
I
(
k
)
\mathcal I^{(k)}
I(k) 列以获得
W
~
u
(
k
)
\widetilde {\textbf W}^{(k)}_u
W
u(k), 以及门向量
g
(
k
)
g^{(k)}
g(k)的第
I
(
k
)
\mathcal I^{(k)}
I(k)个元素以获得
g
~
(
k
)
\tilde {\textbf g}^{(k)}
g~(k)。这样,在推理时间内,第
k
k
k 个 SoRA 模块将作为秩为
r
m
a
x
−
∣
I
(
k
)
∣
r_{max} − |\mathcal I^{(k)}|
rmax−∣I(k)∣ 的普通 LoRA 模块进行处理,其中具有下投影矩阵
W
~
d
(
k
)
\widetilde {\textbf W}^{(k)}_d
W
d(k) 和上投影矩阵
W
~
u
(
k
)
⋅
d
i
a
g
(
g
~
(
k
)
)
\widetilde{\textbf W}^{(k)}_u · diag(\tilde g^{(k)})
W
u(k)⋅diag(g~(k))。
3.2 Interpretation and Comparison
Theoretical interpretation。更新规则(10)实际上是近端梯度法对于
ℓ
1
ℓ_1
ℓ1损失的应用。我们能够将(10)重新等价表述为:
g
t
+
1
←
a
r
g
m
i
n
g
η
t
⋅
λ
∣
∣
g
∣
∣
1
+
1
2
∣
∣
g
−
(
g
t
−
η
∇
L
0
(
g
t
)
)
∣
∣
2
2
.
(13)
\textbf g_{t+1}\leftarrow \mathop{argmin}\limits_{\textbf g}\eta_t\cdot\lambda ||\textbf g||_1+\frac{1}{2}||\textbf g-(\textbf g_t-\eta∇\mathcal L_0(\textbf g_t))||^2_2.\tag{13}
gt+1←gargminηt⋅λ∣∣g∣∣1+21∣∣g−(gt−η∇L0(gt))∣∣22.(13)
上式(13)正是
ℓ
1
ℓ_1
ℓ1正则化损失函数的近端梯度更新:
L
(
Δ
)
:
=
L
0
(
Δ
)
+
λ
∑
k
=
1
K
∣
∣
g
(
k
)
∣
∣
1
,
(14)
\mathcal L(\Delta):=\mathcal L_0(\Delta)+\lambda\sum^K_{k=1}||\textbf g^{(k)}||_1,\tag{14}
L(Δ):=L0(Δ)+λk=1∑K∣∣g(k)∣∣1,(14)
其中
g
(
k
)
\textbf g^{(k)}
g(k) 表示第
k
k
k 个 SoRA 模块的门。这种稀疏性促进策略可以追溯到 LASSO 估计器和压缩感知,并且也被深度学习领域的许多工作所采用。
Comparision with AdaLoRA。受到 SVD 分解的启发,我们的方法 SoRA 与之前的工作 AdaLoRA 在以下方面有所不同。首先,我们不应用 AdaLoRA 中使用的正交正则化 (5)。 原因是出于秩选择的目的,稀疏化门
g
\textbf g
g 就足够了。坚持 SVD 的原始要求可能会导致额外的计算支出。其次,AdaLoRA 中的移动平均重要性得分作为相应项清零时损失变化的近似值,这被视为参数“灵敏度”的启发式测量。然而,模型对某个参数的时间敏感性并不意味着应该保留该参数,因为没有严格的理论来这样做。相比之下,我们基于软阈值操作(10)的秩选择以更清晰的形式进行,并且通过近端梯度迭代理论得到充分证明。正如本节前面所解释的,SoRA 模块的更新规则通过最小化正则化损失目标完全遵循插值复杂性权衡的第一原则 (14)。
除了形式上的简单性和理论的清晰性之外,SoRA 还通过更少的参数和更少的时间实现了卓越的实验性能,这将在第 4 节中介绍。
3.3 Scheduling ξ to Explore Memorization and Generalization


















 929
929

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









