






摘要
本博客将展示在数据有限的小型模型上对 DeepSeek-R1-Zero 和 DeepSeek-R1 训练的复制,许多实验都是在 DeepSeek-R1 发布之前由我们独立开发和执行的。我们表明,在仅使用 8K MATH 样例训练的 7B 模型上,长思维链 (CoT) 和自我反思就可以出现,并且我们在复杂的数学推理上取得了令人惊讶的强劲效果。重要的是,我们向社区完全开源了我们的训练代码和细节,以激发更多推理工作。
从 Qwen2.5-Math-7B(基础模型)开始,我们直接使用来自 MATH 数据集的 8K 个样例对其进行强化学习。 没有奖赏模型,没有 SFT,只有 8K MATH 示例用于验证,结果模型在 AIME 上实现(pass@1 准确率)33.3%、在 AMC 上实现 62.5%、在 MATH 上实现 77.2%,优于 Qwen2.5-math-7B-instruct,可与使用 >50 倍数据和更复杂组件的 PRIME 和 rStar-MATH 相媲美。 我们还尝试在 RL 阶段之前使用相同的 8K 示例执行长时间的 CoT SFT,并获得更好的性能。
我们的许多实验都是在 DeepSeek-R1 发布之前完成的。有趣的是,我们独立地采用了与 DeepSeek-R1 类似且直接的 RL 方法,发现它非常有效。主要区别在于我们使用 PPO 而不是 GRPO。虽然这项研究仍在进行中,但我们认为与社区分享我们的中期发现很有价值。我们希望我们的工作可以成为 DeepSeek-R1 Zero 和 DeepSeek-R1 的简单而有效的复制品,适合较小的模型和有限的数据集。
1.介绍
许多研究人员正在探索学习 o-style 模型的可能途径,例如蒸馏、MCTS、基于过程的奖赏模型和强化学习。最近,DeepSeek-R1 和 Kimi-k1.5 都展示了这条路径上极其简单的配方,使用简单的 RL 算法来学习新的长 CoT 和自我反思模式,并取得强劲成果,其中没有使用 MCTS 和奖赏模型。然而,他们的实验是基于大规模 RL 设置中的大型模型。小型模型是否可以展示类似的行为、需要多少数据以及定量结果与其他方法相比如何仍不清楚。本博客重现了 DeepSeek-R1-Zero 和 DeepSeek-R1 的复杂数学推理训练,从 Qwen-2.5-Math-7B(base模型)开始,仅使用原始 MATH 数据集中的 8K(query、最终答案)示例进行 RL 中的基于规则的奖赏建模。我们惊讶地发现,在没有任何其他外部信号的情况下,8K MATH 示例将这个 7B 基础模型进行了性能提升(All results are in pass@1 accuracy):
| Model | AIME 2024 | MATH 500 | AMC | Minerva Math | Olympia dBench | Avg. |
|---|---|---|---|---|---|---|
| Qwen2.5-Math-7B-Base | 16.7 | 52.4 | 52.5 | 12.9 | 16.4 | 30.2 |
| Qwen2.5-Math-7B-Base + 8K MATH SFT | 3.3 | 54.6 | 22.5 | 32.7 | 19.6 | 26.5 |
| Qwen-2.5-Math-7B-Instruct | 13.3 | 79.8 | 50.6 | 34.6 | 40.7 | 43.8 |
| Llama-3.1-70B-Instruct | 16.7 | 64.6 | 30.1 | 35.3 | 31.9 | 35.7 |
| rStar-Math-7B | 26.7 | 78.4 | 47.5 | - | 47.1 | - |
| Eurus-2-7B-PRIME | 26.7 | 79.2 | 57.8 | 38.6 | 42.1 | 48.9 |
| Qwen2.5-7B-SimpleRL-Zero | 33.3 | 77.2 | 62.5 | 33.5 | 37.6 | 48.8 |
| Qwen2.5-7B-SimpleRL | 26.7 | 82.4 | 62.5 | 39.7 | 43.3 | 50.9 |
Qwen2.5-7B-SimpleRL-Zero 是直接从base模型进行的简单 RL 训练,仅使用 8K MATH 示例。与base模型相比,它平均获得了近 20 个绝对点的增益。与具有相同 8K 数据 SFT 的 Qwen2.5-Math-7B-Base 相比,RL 的泛化能力要好得多,绝对值高出 22%。此外,Qwen2.5-7B-SimpleRL-Zero 的平均表现优于 Qwen-2.5-Math-7B-Instruct,与最近发布的 Eurus-2-7B-PRIME 和 rStar-Math-7B 大致相当,后者也基于 Qwen-2.5-Math-7B。这些基线包含更复杂的组件(例如奖赏模型),并使用至少 50 倍以上的高级数据:
| Qwen2.5-Math-7B-Instruct | rStar-Math-7B | Eurus-2-7B-PRIME | Qwen2.5-7B-SimpleRL-Zero | |
|---|---|---|---|---|
| Base Model | Qwen2.5-Math-7B | Qwen2.5-Math-7B | Qwen2.5-Math-7B | Qwen2.5-Math-7B |
| SFT Data | 2.5M (open-source and in-house) | ~7.3M (MATH, NuminaMath, etc.) | 230K | 0 |
| RM Data | 618K (in-house) | ~7k (in-house) | 0 | 0 |
| RM | Qwen2.5-Math-RM (72B) | None | Eurus-2-7B-SFT | None |
| RL Data | 66K queries × 32 samples | ~3.647M × 16 | 150K queries × 4 samples | 8K queries × 8 samples |
我们对仅使用 8K MATH 示例就取得的显著进步感到兴奋和惊讶。值得注意的是,虽然 MATH 问题比许多具有挑战性的基准(例如 AIME 和 AMC)要容易得多,但这个简单的 RL 配方表现出了非凡的泛化能力,与基础模型相比,性能至少提高了 10 个绝对点。与使用同一数据集上的标准 SFT 训练的模型相比,这种由易到难的泛化效果是我们无法想象的。我们完全开源我们的训练代码和细节,希望作为社区进一步探索 RL 在推理方面的潜力的强大基线设置。
接下来,我们将深入研究我们的设置细节,以及在这次 RL 训练期间发生的事情,例如长 CoT 和自我反思模式的出现。
2.The Simple RL Recipe
与 DeepSeek R1 类似,我们的 RL 配方非常简单,没有使用奖赏模型或类似 MCTS 的技术。我们使用 PPO 算法,并采用基于规则的奖赏函数,该函数根据生成的响应的格式和正确性分配奖赏:
- 如果响应提供了指定格式的最终答案并且正确,则会获得 +1 的奖励。
- 如果响应提供了最终答案但不正确,则奖励设置为 -0.5。
- 如果响应未能提供最终答案,则奖励设置为 -1。
该实现基于 OpenRLHF。我们的初步试验表明,该奖赏函数可帮助策略模型快速收敛并生成所需格式的响应。
3.Experimental Setup
在我们的实验中,我们从 Qwen2.5-Math-7B-Base 模型开始,并在具有挑战性的数学推理基准上评估性能,包括 AIME2024、AMC23、GSM8K、MATH-500、Minerva Math 和 OlympiadBench。训练使用了 MATH 训练数据集中难度级别 3-5 的约 8,000 个 query。我们采用类似 DeepSeek-R1-Zero 和 DeepSeek-R1 的方法在以下两种设置下进行实验:
- SimpleRL-Zero:我们直接从基础模型执行 RL,而无需先进行 SFT。我们仅使用 8K MATH(问题、答案)对。
- SimpleRL:我们首先执行 long-cot SFT 作为冷启动。SFT 数据是 8K MATH query,其响应来自 QwQ-32B-Preview。然后我们使用相同的 8K MATH 示例执行我们的 RL 配方。
4.Part 1: SimpleRL-Zero — Reinforcement Learning From Scratch
我们在引言部分报告了 SimpleRL-Zero 的主要结果,它的表现优于 Qwen2.5-Math-7B-Instruct,并且尽管仅使用 8K MATH 示例,但取得了与 PRIME 和 rStar-Math 相当的结果。下面我们分享训练动态和一些有趣的新兴模式。
4.1 The Training Dynamics
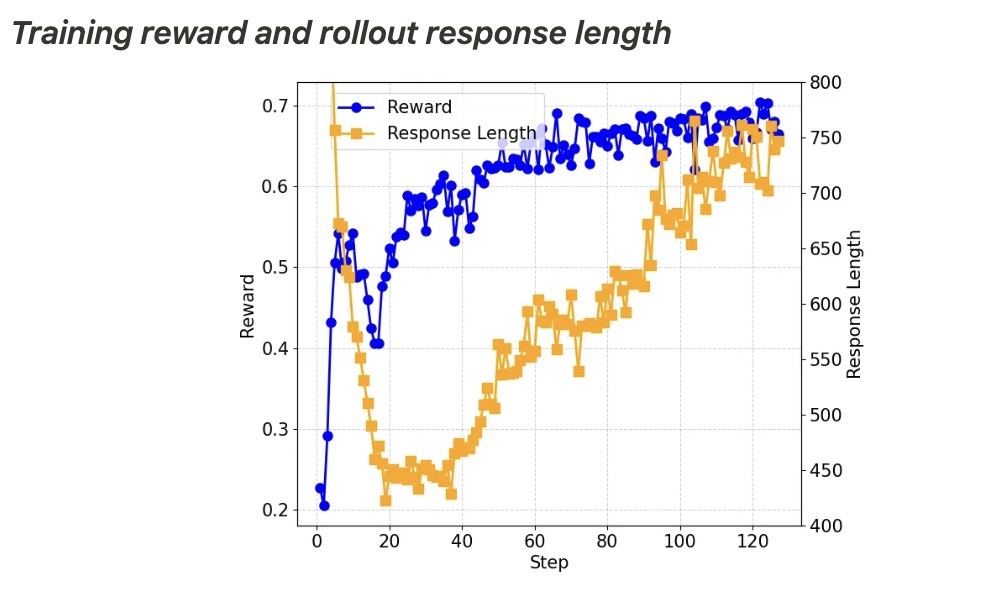
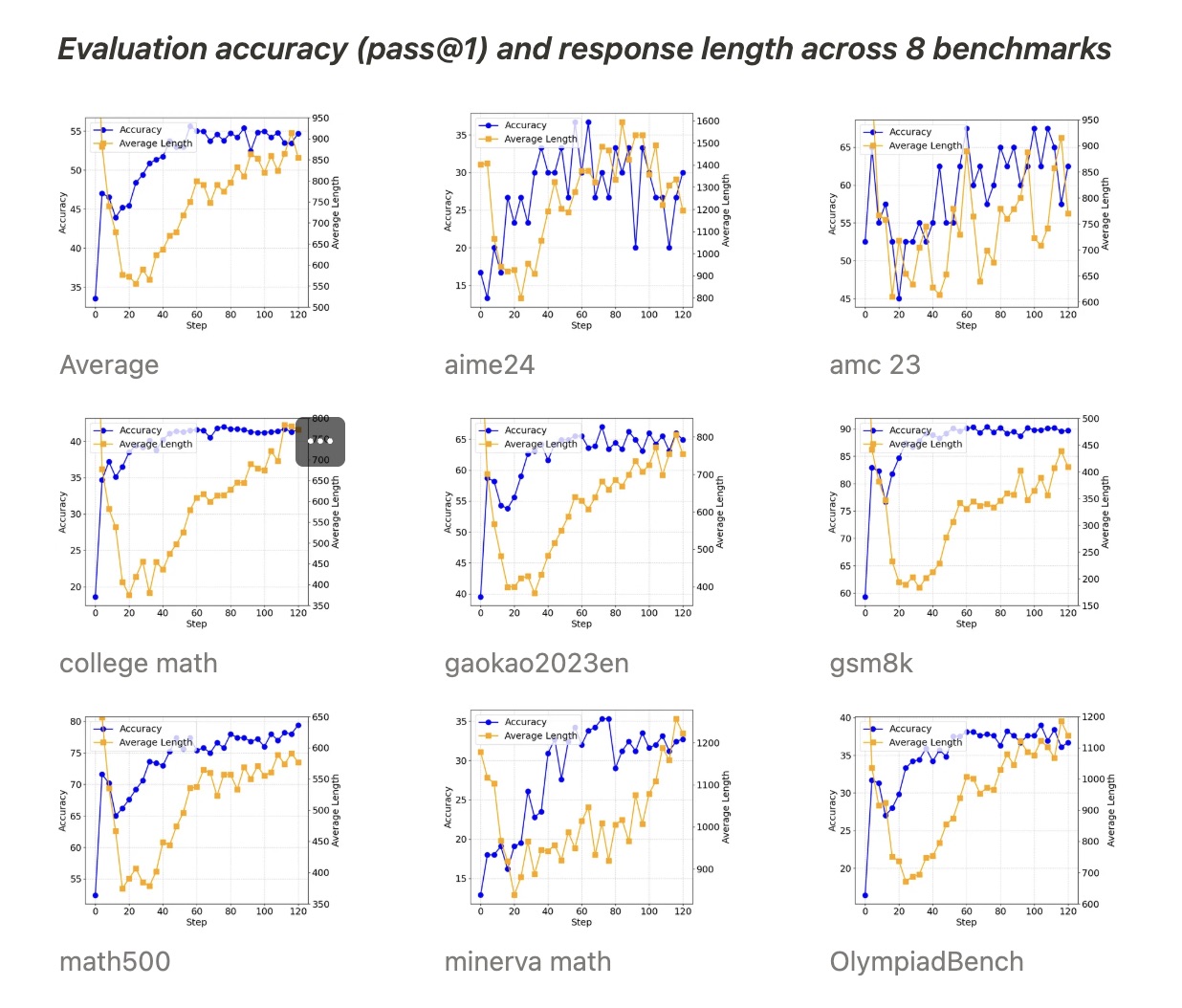
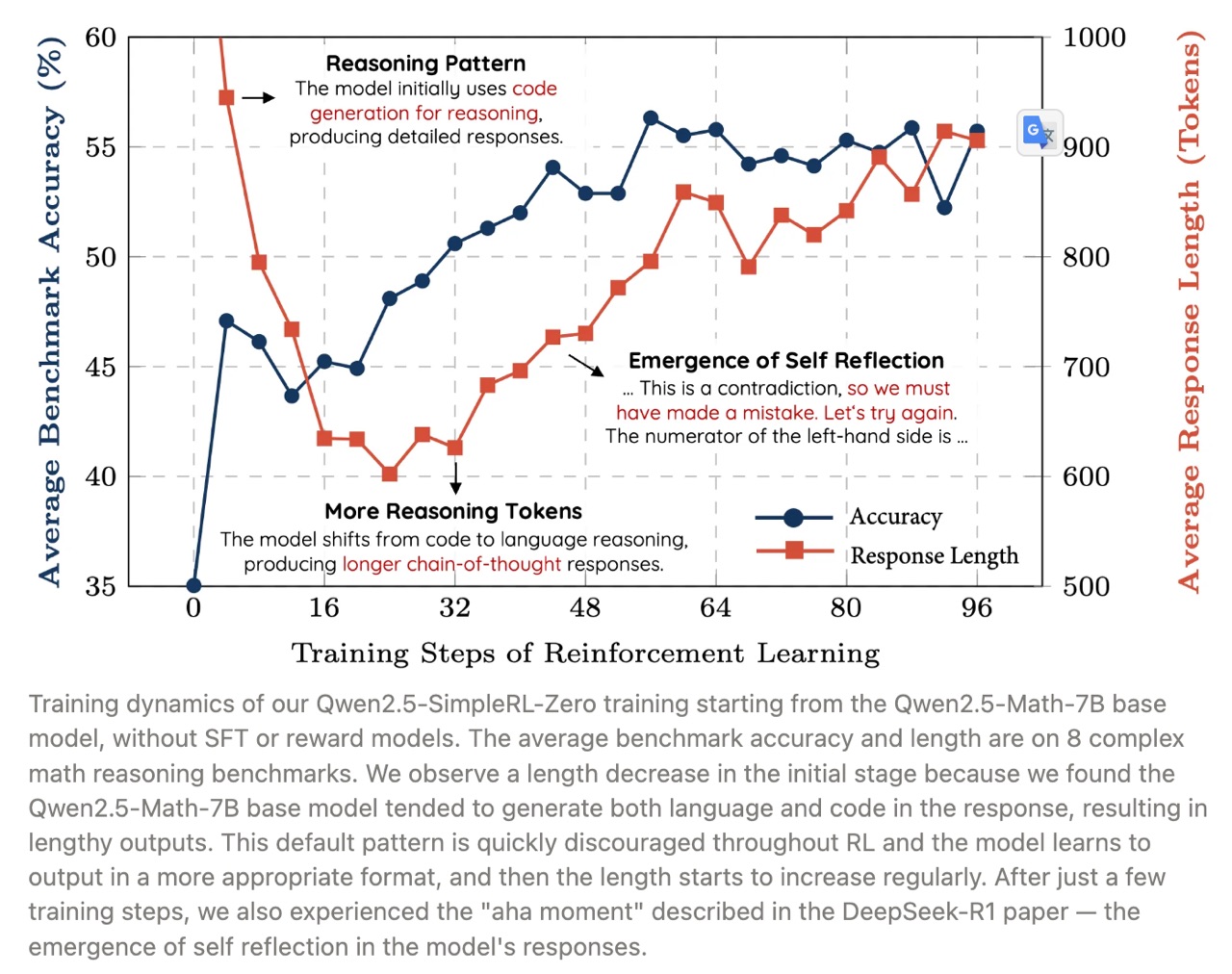
如上图所示,在所有基准测试中,准确率都在随着训练的进行稳步提升,而长度则先减小然后逐渐增加。经过进一步调查,我们发现 Qwen2.5-Math-7B 基础模型在开始时往往会生成大量代码,这可能是由于模型原始的训练数据分布所致。我们发现长度首先减小是因为 RL 训练逐渐消除了这种模式,学会了用正常语言进行推理。然后,生成长度又开始增加,其中自我反思模式出现,如下所示。
4.2 Emergence of Self-Reflection
在第 40 步左右,我们发现模型开始产生自我反思模式,也就是 DeepSeek-R1 论文中的“顿悟时刻”。下面我们展示一个例子。

5.Part 2: SimpleRL — Reinforcement Learning With Imitation Warmup
如前所述,我们在执行 RL 之前会进行长时间 CoT SFT 热身,SFT 数据集是 8K 数学示例,其响应来自 QwQ-32B-Preview。这种冷启动的潜在好处是,模型从已经具备自我反思能力的长时间 CoT 模式开始 RL,然后在 RL 阶段,它可能会学得更快更好。
| Model | AIME 2024 | MATH 500 | AMC | Minerva Math | Olympia dBench | Avg. |
|---|---|---|---|---|---|---|
| Qwen2.5-Math-7B-Base | 16.7 | 52.4 | 52.5 | 12.9 | 16.4 | 30.2 |
| Qwen2.5-Math-7B-Base + 8K QwQ distillation | 16.7 | 76.6 | 55.0 | 34.9 | 36.9 | 44.0 |
| Eurus-2-7B-PRIME | 26.7 | 79.2 | 57.8 | 38.6 | 42.1 | 48.9 |
| Qwen2.5-7B-SimpleRL-Zero | 36.7 | 77.4 | 62.5 | 34.2 | 37.5 | 49.7 |
| Qwen2.5-7B-SimpleRL | 26.7 | 82.4 | 62.5 | 39.7 | 43.3 | 50.9 |
与 RL 训练之前的模型 Qwen2.5-Math-7B-Base + 8K QwQ 蒸馏相比,Qwen2.5-7B-SimpleRL 绝对提升了 6.9%,平均提升幅度显著。此外,Qwen2.5-7B-SimpleRL 的表现始终优于 Eurus-2-7B-PRIME,并且在 5 个基准测试中的 3 个上超越了 Qwen2.5-7B-SimpleRL-Zero。尽管结果不错,但考虑到 QwQ 是一个 32B 的强长 CoT 教师模型,我们有点惊讶 QwQ 蒸馏阶段与 Zero 设置相比没有产生更大的收益。
5.1 The Training Dynamics
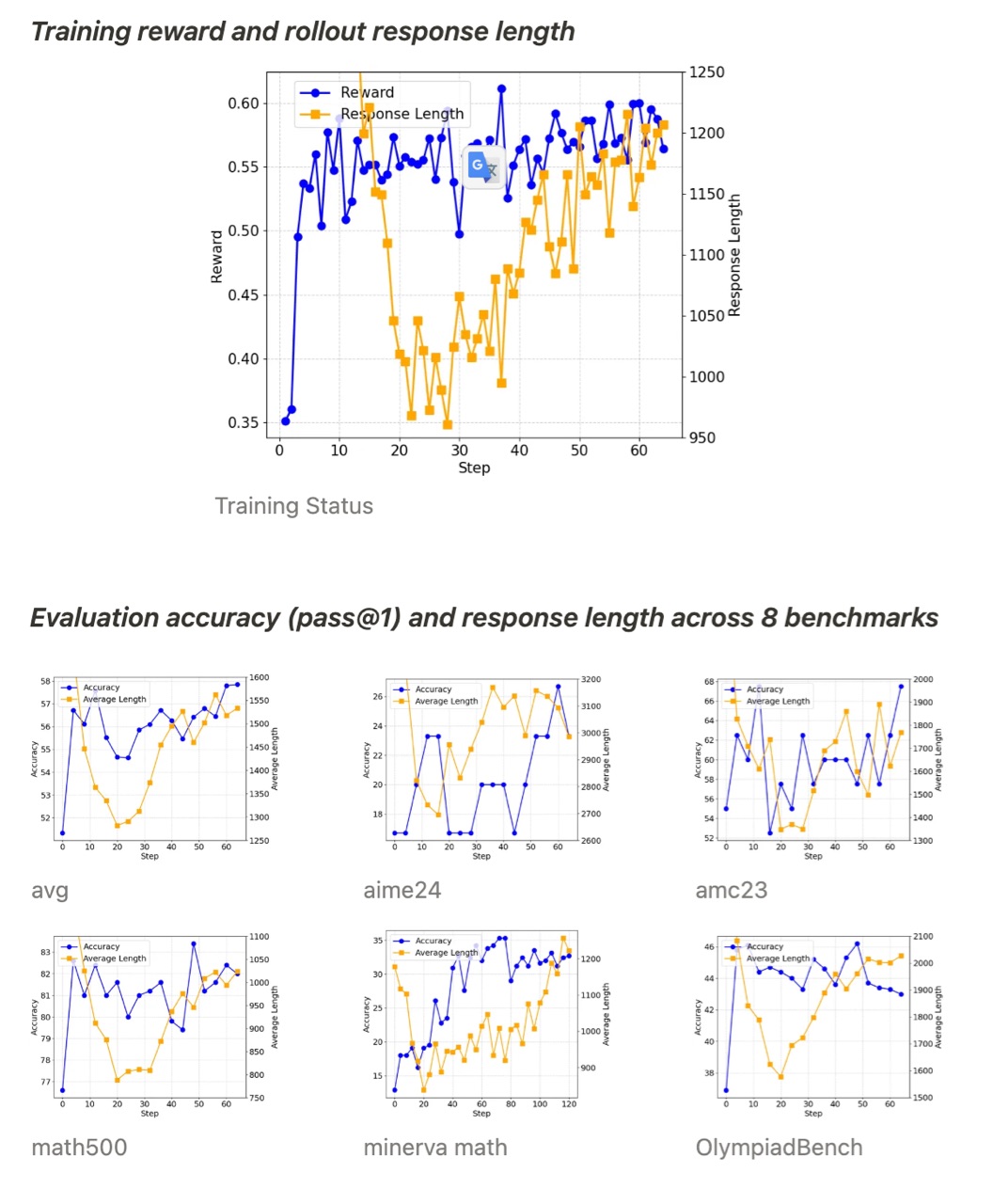
Qwen2.5-SimpleRL 的训练动态与 Qwen2.5-SimpleRL-Zero 的训练动态相似。有趣的是,即使我们首先执行长 CoT SFT,我们仍然在 RL 开始时观察到长度减少的现象。我们怀疑这是因为精炼的 QwQ 推理模式不受小型策略模型的青睐,或者超出了小型模型的能力。因此,它学会放弃它并自行开发新的长推理。

















 677
677

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









