




摘要
大语言模型 (LLM) 应用(例如 Agent 和领域特定推理)越来越依赖于上下文自适应——使用指令、策略或证据修改输入,而不是更新权重。先前的方法虽然提高了可用性,但常常受到简洁性偏差的影响,这会为了简洁的摘要而牺牲领域洞察力;此外,上下文崩溃也会导致迭代重写随着时间的推移而侵蚀细节。基于 Dynamic Cheatsheet 引入的自适应记忆,我们引入了 ACE(Agent 上下文工程),该框架将上下文视为不断发展的剧本,通过模块化的生成、反思和整理流程来积累、完善和组织策略。ACE 通过结构化的增量更新来防止上下文崩溃,这些更新可以保留详细知识,并通过长上下文模型进行扩展。在 Agent 和领域特定基准测试中,ACE 优化了离线(例如系统提示)和在线(例如 Agent记忆)上下文,其性能始终优于强大的基准:Agent 方面提升了 10.6%,金融方面提升了 8.6%,同时显著降低了自适应延迟和部署成本。值得注意的是,ACE 无需标记监督,而是利用自然执行反馈即可有效适应。在 AppWorld 排行榜上,尽管使用了规模较小的开源模型,ACE 的整体平均水平与排名第一的生产级 Agent 相当,并在更难的测试挑战赛中超越了后者。这些结果表明,全面且不断发展的环境能够以较低的开销实现可扩展、高效且自我改进的 LLM 系统。
1.Introduction
基于大语言模型 (LLM) 的现代人工智能应用,例如 LLM Agent 和复合人工智能系统,越来越依赖于上下文自适应。上下文自适应并非修改模型权重,而是通过将清晰的指令、结构化的推理步骤或特定领域的输入格式直接融入模型输入,从而提升模型训练后的性能。上下文是许多人工智能系统组件的基础,包括指导下游任务的 system prompt、承载过去事实和经验的 memory,以及减少幻觉和补充知识的事实 evidence。
通过上下文而非权重进行自适应有几个关键优势。上下文对于用户和开发者来说具有可解释性,允许在运行时快速集成新知识,并且可以在复合系统中的模型或模块之间共享。同时,长上下文 LLM 和上下文高效推理(例如 key-value 缓存重用)的进展,使得基于上下文的方法在部署方面越来越实用。因此,上下文自适应正在成为构建强大、可扩展且可自我改进的人工智能系统的核心范式。
尽管取得了这些进展,现有的上下文自适应方法仍面临两个关键限制。首先,简洁性 bias:许多 prompt 优化器优先考虑简洁、广泛适用的指令,而非全面的积累。例如,GEPA 强调简洁性是一种优势,但这种抽象可能会忽略特定领域的启发式方法、工具使用指南或实践中重要的常见故障模式。该目标在某些情况下与验证指标相符,但往往无法捕捉到 Agent 和知识密集型应用所需的详细策略。其次,上下文崩溃:依赖于 LLM 进行整体重写的方法通常会随着时间的推移而退化为更短、信息量更少的摘要,从而导致性能急剧下降(图 2)。在交互式智能体、领域特定编程以及金融或法律分析等领域,强大的性能取决于保留详细的、特定于任务的知识,而不是将其压缩掉。
随着 Agent 和知识密集型推理等应用对可靠性的要求越来越高,近期的研究已转向利用丰富的潜在有用信息来充实上下文,这得益于长上下文 LLM 的进步。我们认为,上下文不应仅仅作为简洁的摘要,而应作为全面、不断发展的策略手册——详细、包容,并富含领域洞察。与通常受益于简洁泛化的人类不同,LLM 在提供长而详细的上下文时效率更高,并且可以自主提取相关性。因此,上下文不应压缩特定领域的启发式方法和策略,而应保留它们,让模型在推理时决定哪些内容重要。
为了突破这些限制,我们引入了 ACE(Agentic Context Engineering),这是一个用于在离线环境(例如 system prompt 优化)和在线环境(例如测试时 memory 调整)中进行全面上下文自适应的框架。ACE 并非将上下文压缩成精炼的摘要,而是将其视为不断演变的剧本,随着时间的推移,这些剧本会积累并组织策略。ACE 基于 Dynamic Cheatsheet 的 Agent 架构,融合了生成、反思和整理的模块化工作流程,同时添加了遵循“增长-细化”原则的结构化增量更新。这种设计保留了详细的领域特定知识,防止上下文崩溃,并生成在整个自适应过程中保持全面性和可扩展性的上下文。
我们评估了两类 LLM 应用的 ACE 性能,这些应用最能从全面且不断发展的环境中获益:(1)Agent,这类应用需要多轮推理、工具使用和环境交互,其中累积的策略可以在不同场景中重复使用;(2)特定领域的基准测试,这类应用需要专门的策略和知识,我们专注于金融分析。我们的主要发现如下:
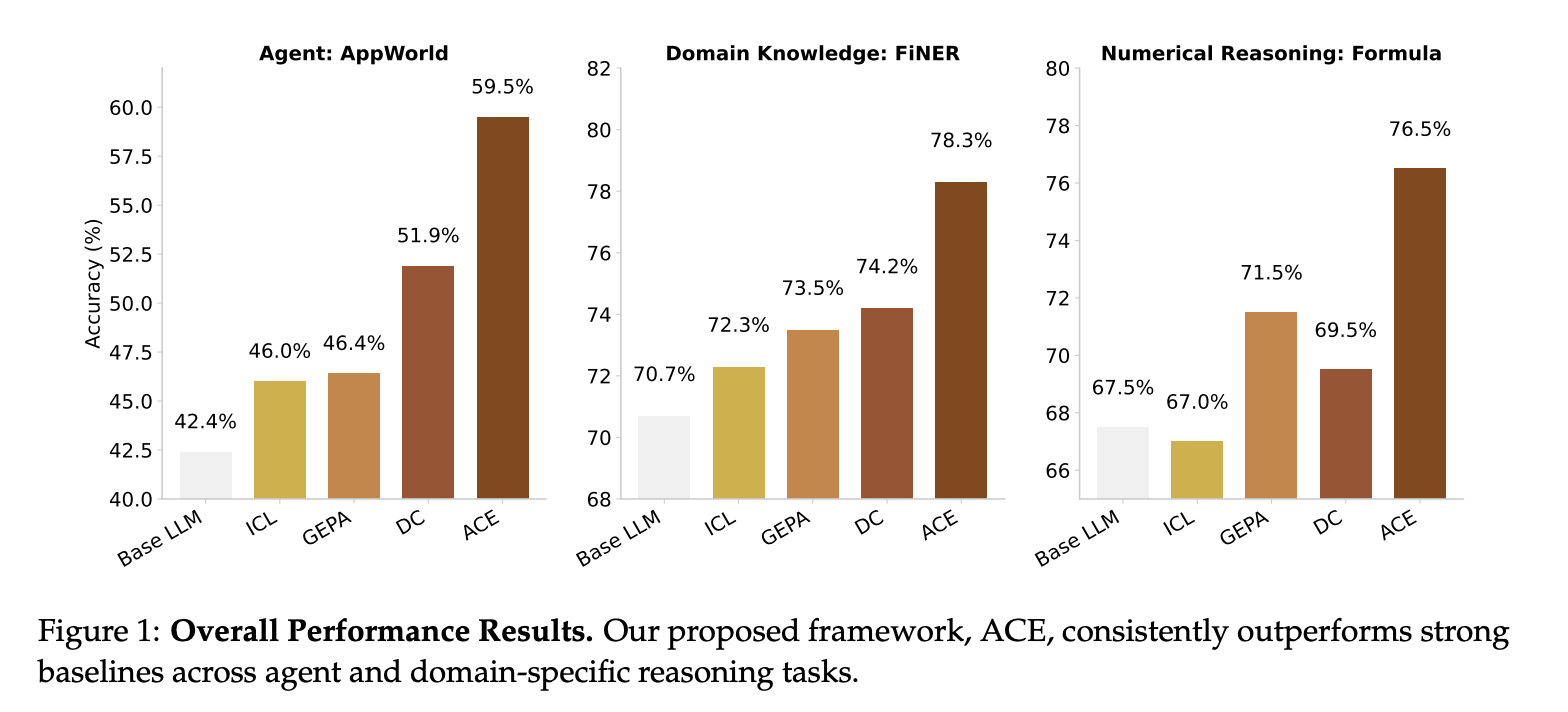
- ACE 的表现始终优于强大的基线,在离线和在线自适应设置中,Agent 的平均增益为 10.6%,特定领域基准的平均增益为 8.6%。
- 通过利用运行反馈和环境信号,ACE 能够在没有标记监督的情况下构建有效的上下文,这是自我改进的 LLM 和 Agent的关键要素。
- 在 AppWorld 基准排行榜上,ACE 的平均成绩与排名第一的生产级Agent IBMCUGA(由 GPT-4.1 提供支持)相当,并且在更难的测试挑战分割中超越了它,同时使用了较小的开源模型(DeepSeek-V3.1)。
- ACE 所需的部署次数和美元成本显著减少,并且与现有的自适应方法相比,自适应延迟平均降低了 86.9%,这表明可以实现可扩展的自我改进,同时具有更高的准确性和更低的开销。
2.Background and Motivation
2.1 Context Adaptation
上下文自适应(或上下文工程)是指通过构建或修改 LLM 的输入(而不是改变其权重)来改进模型行为的方法。目前最先进的方法是利用自然语言反馈。在这种范式中,语言模型会检查当前上下文以及执行轨迹、推理步骤或验证结果等信号,并生成关于如何修改上下文的自然语言反馈。然后将此反馈融入到上下文中,从而实现迭代自适应。代表性方法包括:Reflexion,它反思失败之处以改进智能体规划;TextGrad,它通过类似梯度的文本反馈优化提示;GEPA,它基于执行轨迹迭代地优化提示,并实现了强大的性能,甚至在某些情况下超越了强化学习方法;以及 Dynamic Cheatsheet,它构建了一个外部记忆,用于在推理过程中积累过去成功和失败的策略和经验教训。这些自然语言反馈方法代表了一项重大进步,为改进 LLM 系统提供了灵活且可解释的信号,而不仅仅是权重更新。
2.2 Limitations of Existing Context Adaptation Methods
The Brevity Bias。上下文自适应方法的一个反复出现的局限性是简洁性bias:优化过程倾向于倾向于简短、通用的提示。Gao et al. 在测试生成的提示优化中记录了这种效应,其中迭代方法反复生成几乎相同的指令(例如,“创建单元测试以确保方法按预期运行”),从而牺牲了多样性并忽略了特定领域的细节。这种收敛不仅缩小了搜索空间,还会在迭代过程中传播重复的错误,因为优化后的提示通常会继承与其种子相同的错误。更广泛地说,这种偏差会损害需要详细、上下文丰富指导的领域的性能——例如多步骤 Agent、程序合成或知识密集型推理——在这些领域中,成功取决于积累而非压缩特定任务的洞察力。
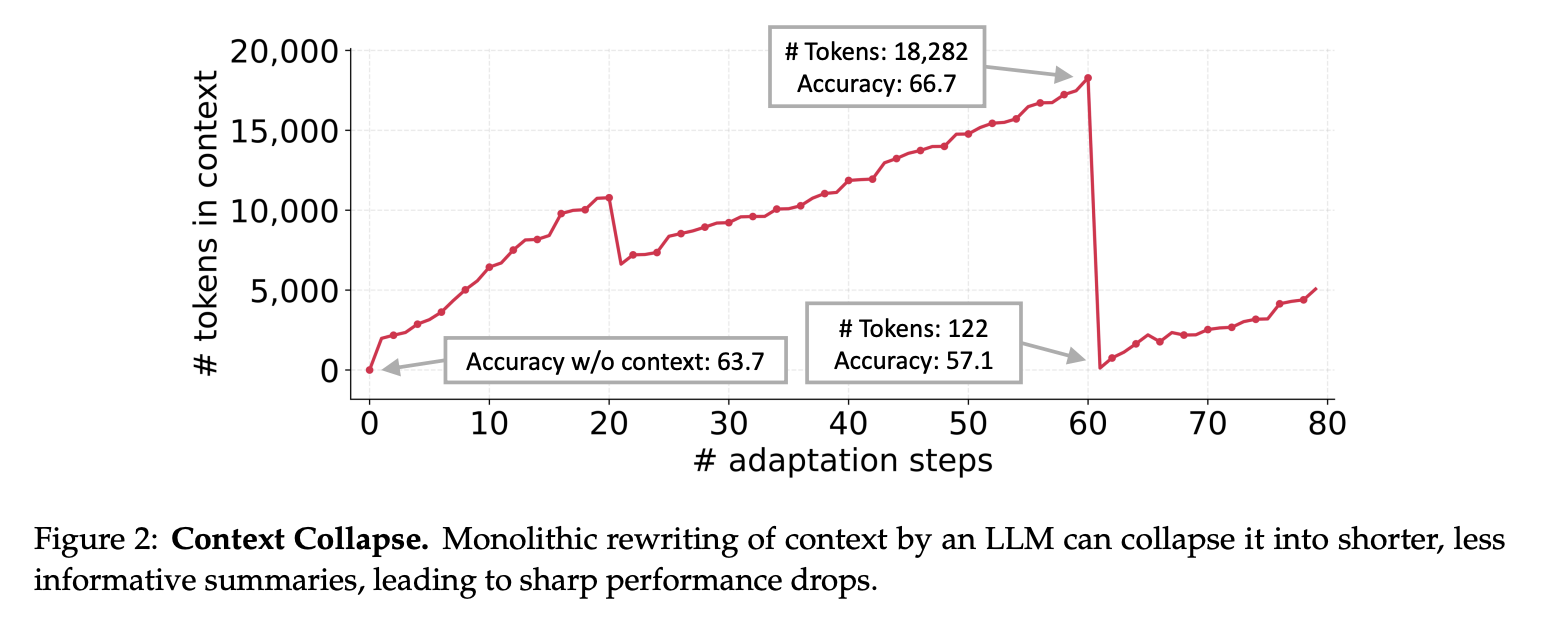
Context Collapse。在 AppWorld 基准测试的案例研究中,我们观察到一种称为“上下文崩溃”的现象。当 LLM 在每个自适应步骤中被要求完全重写累积的上下文时,就会出现这种现象。随着上下文变得越来越大,模型往往会将其压缩成更短、信息量更少的摘要,从而导致信息大量丢失。例如,在第 60 步,上下文包含 18,282 个 token,准确率达到 66.7,但紧接着的一步,上下文就崩溃到只有 122 个 token,准确率下降到 57.1,比没有自适应的基线准确率 63.7 还要差。虽然我们通过动态备忘单强调了这一点,但这个问题并非该方法所特有;相反,它反映了使用 LLM 进行端到端上下文重写的一个根本风险,在这种情况下,累积的知识可能会被突然擦除而不是保留。
3.Agentic Context Engineering (ACE)
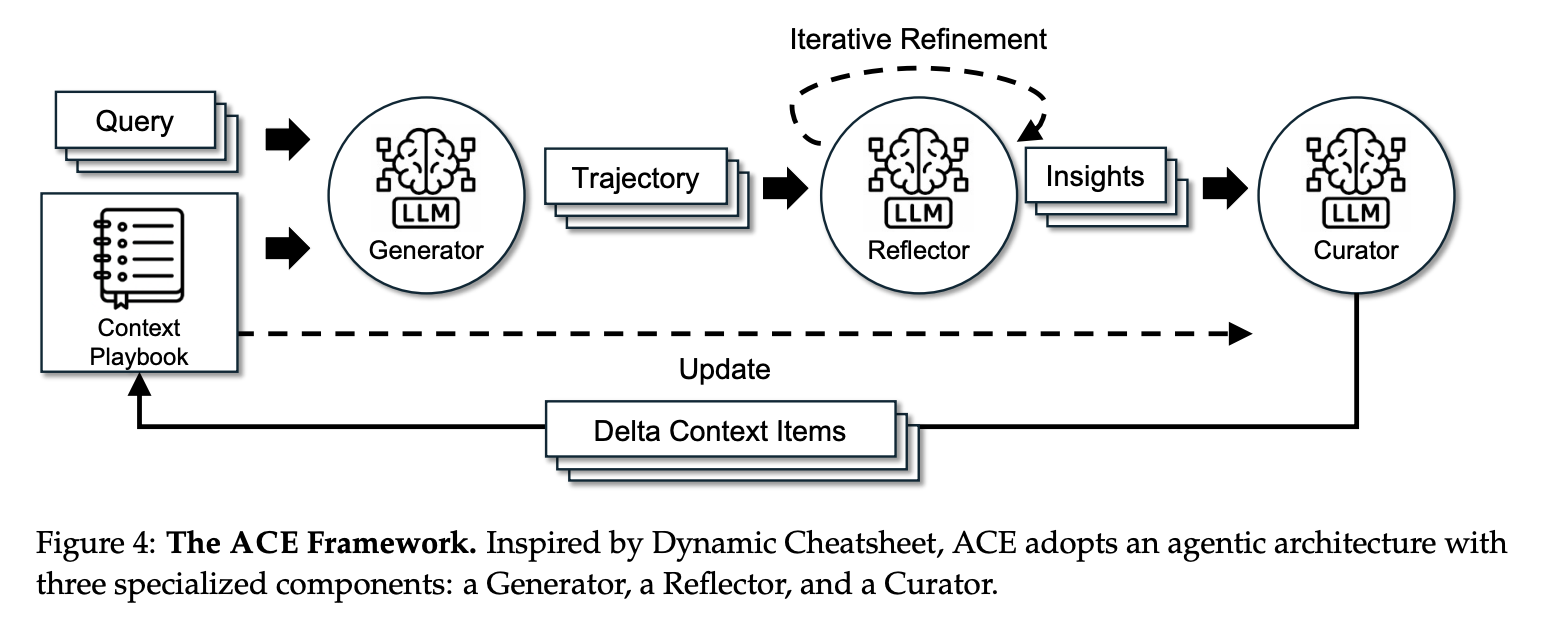
我们提出了 ACE(Agentic Context Engineering)框架,用于在离线(例如 system prompt 优化)和在线(例如测试时记忆调整)场景中实现可扩展且高效的上下文自适应。ACE 并非将知识浓缩为简洁的摘要或静态指令,而是将上下文视为不断演进的剧本,随着时间的推移,这些剧本会不断积累、完善和组织策略。基于 Dynamic Cheatsheet 的 Agent 设计,ACE 引入了三个角色的结构化分工(图 4):生成器(Generator),生成推理轨迹;反思器(Reflector),从成功和错误中提炼具体的洞察;以及策略设计器(Curator),将这些洞察整合到结构化的上下文更新中。这反映了人类的学习方式——实验、反思和巩固——同时避免了单个模型承担所有职责所带来的瓶颈。
为了解决 §2.2 中讨论的先前方法的局限性(特别是简洁性bias和上下文崩溃),ACE 引入了三个关键创新:(1)专用反思器,将评估和洞察的提取与策略生成分开,提高上下文质量和下游性能(§4.5);(2)增量 delta 更新(§3.1),用局部编辑取代昂贵的整体重写,减少延迟和计算成本(§4.6);(3)增长和细化机制(§3.2),平衡稳定的上下文扩展和冗余控制。
如图 4 所示,工作流程始于生成器 (Generator) 为新 query 生成推理轨迹,这些轨迹既能揭示有效的策略,也能揭示反复出现的陷阱。反思器 (Reflector) 对这些轨迹进行评估,以提取经验教训,并可选择通过多次迭代对其进行改进。之后,策略设计器 (Curator) 将这些经验教训合成紧凑的增量条目 (delta entry),并通过轻量级的非 LLM 逻辑将其确定性地合并到现有上下文中。由于更新是逐项且局部化的,因此可以并行合并多个增量条目,从而实现大规模批量自适应。ACE 进一步支持多阶段自适应,即重复访问相同的查询以逐步强化上下文。
3.1 Incremental Delta Updates
ACE 的核心设计原则是将上下文表示为一系列结构化、逐项列出的项目符号,而不是单个整体式提示。项目符号的概念类似于 LLM 记忆框架(例如 Dynamic Cheatsheet 和 A-MEM)中的记忆条目概念,但建立在此之上,包含 (1) 元数据,包括唯一标识符和计数器,用于跟踪其被标记为有用或有害的频率;以及 (2) 内容,用于捕获小单元,例如可重用策略、领域概念或常见故障模式。在解决新问题时,生成器会突出显示哪些项目符号有用或具有误导性,并提供反馈,指导反思器提出纠正性更新。
这种分项设计实现了三个关键特性:(1) 局部化,即仅更新相关的项目符号;(2) 细粒度检索,使生成器能够专注于最相关的知识;(3) 增量自适应,允许在推理过程中高效地合并、修剪和去重。
ACE 并非完全重新生成上下文,而是增量地生成紧凑的增量上下文:由反思器 (Reflector) 提炼并由策略生成器 (Curator) 集成的小型候选项目符号集。这避免了完全重写的计算成本和延迟,同时确保保留过去的知识并稳步添加新的见解。随着上下文的增长,这种方法能够提供长期或领域密集型应用程序所需的可扩展性。
3.2 Grow-and-Refine
除了增量增长之外,ACE 还通过定期或惰性优化来确保上下文保持紧凑和相关性。在 grow-and-refine 中,带有新标识符的项目符号会被添加,而现有项目符号则会就地更新(例如,增加计数器)。然后,去重步骤会通过语义嵌入比较项目符号来修剪冗余。此优化可以主动执行(每次增量之后)或惰性执行(仅在超出上下文窗口时),具体取决于应用程序对延迟和准确性的要求。
增量更新和增长与细化共同维护了自适应扩展的上下文,保持了可解释性,并避免了由单片上下文重写引入的潜在差异。

















 929
929

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









