







换个思路,再训练一次。
1 基本框架
试想,如果有一个语句需要从预料库中匹配,每一次匹配都会伴随着大量的耗时:
一次匹配20ms, 1 000 000次呢,1 000 000 *20/ 1000 = 20 000S ~5.56H。效率极其的低:
使用如下策略解决:候选文本与匹配文本分别进入模型(并行)然后输出两个向量,通过cos相似度得到是否匹配结果;
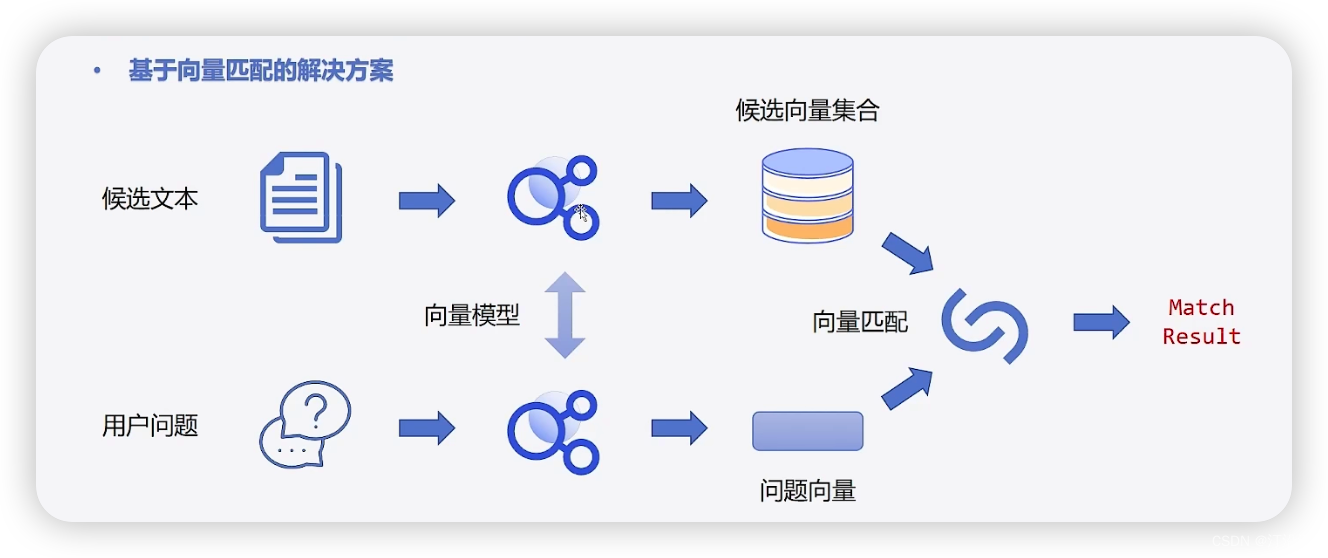
2 使用方法介绍
2.1 CosineSimilarity
pytorch.nn.CosineSimilarity(余弦相似度)是一种常用的相似度度量方法,用于衡量两个向量之间的相似程度。在自然语言处理和信息检索等领域,余弦相似度常用于比较文本、向量表示或特征之间的相似性。
2.2 CosineEmbeddingLoss

3 代码
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset,load_from_disk
import traceback
import torch
from sklearn.model_selection import train_test_split
#dataset = load_dataset("json", data_files="../data/train_pair_1w.json", split="train")
dataset = load_dataset("csv", data_files="/Users/user/studyFile/2024/nlp/text_similar/data/Chinese_Text_Similarity.csv", split="train")
datasets = dataset.train_test_split(test_size=0.2,shuffle=True)
tokenizer = AutoTokenizer.from_pretrained("../chinese_macbert_base")
def process_function(examples):
sentences = []
labels = []
for sen1, sen2, label in zip(examples["sentence1"], examples["sentence2"], examples["label"]):
sentences.append(sen1)
sentences.append(sen2)
labels.append(1 if int(label) == 1 else -1)
# input_ids, attention_mask, token_type_ids
tokenized_examples = tokenizer(sentences, max_length=128, truncation=True, padding="max_length")
# tokenized_examples format likes {'input_ids':[[],[],[]], 'token_type_ids':[[],[],[]],'attention_mask':[[],[],[]]}
# k : input_ids, v: [[],[],[],[]]
tokenized_examples = {k: [v[i: i + 2] for i in range(0, len(v), 2)] for k, v in tokenized_examples.items()}
tokenized_examples["labels"] = labels
return tokenized_examples
tokenized_datasets = datasets.map(process_function, batched=True, remove_columns=datasets["train"].column_names)
tokenized_datasets
#搭建模型
from transformers import BertForSequenceClassification, BertPreTrainedModel, BertModel
from typing import Optional
from transformers.configuration_utils import PretrainedConfig
from torch.nn import CosineSimilarity, CosineEmbeddingLoss
import torch
class DualModel(BertPreTrainedModel):
def __init__(self, config: PretrainedConfig, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
self.bert = BertModel(config)
self.post_init()
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
token_type_ids: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
inputs_embeds: Optional[torch.Tensor] = None,
labels: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
):
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
# Step1 分别获取sentenceA 和 sentenceB的输入
senA_input_ids, senB_input_ids = input_ids[:, 0], input_ids[:, 1]
senA_attention_mask, senB_attention_mask = attention_mask[:, 0], attention_mask[:, 1]
senA_token_type_ids, senB_token_type_ids = token_type_ids[:, 0], token_type_ids[:, 1]
# Step2 分别获取sentenceA 和 sentenceB的向量表示
senA_outputs = self.bert(
senA_input_ids,
attention_mask=senA_attention_mask,
token_type_ids=senA_token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
senA_pooled_output = senA_outputs[1] # [batch, hidden]
senB_outputs = self.bert(
senB_input_ids,
attention_mask=senB_attention_mask,
token_type_ids=senB_token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
senB_pooled_output = senB_outputs[1] # [batch, hidden]
# step3 计算相似度
cos = CosineSimilarity()(senA_pooled_output, senB_pooled_output) # [batch, ]
# step4 计算loss
loss = None
if labels is not None:
loss_fct = CosineEmbeddingLoss(0.3)
loss = loss_fct(senA_pooled_output, senB_pooled_output, labels)
output = (cos,)
return ((loss,) + output) if loss is not None else output
model = DualModel.from_pretrained("../chinese_macbert_base")
import evaluate
acc_metric = evaluate.load("./metric_accuracy.py")
f1_metirc = evaluate.load("./metric_f1.py")
def eval_metric(eval_predict):
predictions, labels = eval_predict
predictions = [int(p > 0.7) for p in predictions]
labels = [int(l > 0) for l in labels]
# predictions = predictions.argmax(axis=-1)
acc = acc_metric.compute(predictions=predictions, references=labels)
f1 = f1_metirc.compute(predictions=predictions, references=labels)
acc.update(f1)
return acc
# 模型参数
train_args = TrainingArguments(output_dir="./dual_model", # 输出文件夹
per_device_train_batch_size=32, # 训练时的batch_size
per_device_eval_batch_size=32, # 验证时的batch_size
logging_steps=10, # log 打印的频率
evaluation_strategy="epoch", # 评估策略
save_strategy="epoch", # 保存策略
save_total_limit=3, # 最大保存数
learning_rate=2e-5, # 学习率
weight_decay=0.01, # weight_decay
metric_for_best_model="f1", # 设定评估指标
load_best_model_at_end=True) # 训练完成后加载最优模型
trainer = Trainer(model=model,
args=train_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
compute_metrics=eval_metric)
trainer.train()
# 预测样本
class SentenceSimilarityPipeline:
def __init__(self, model, tokenizer) -> None:
self.model = model.bert
self.tokenizer = tokenizer
self.device = model.device
def preprocess(self, senA, senB):
return self.tokenizer([senA, senB], max_length=128, truncation=True, return_tensors="pt", padding=True)
def predict(self, inputs):
inputs = {k: v.to(self.device) for k, v in inputs.items()}
#print(inputs)
return self.model(**inputs)[1] # [2, 768]
def postprocess(self, logits):
cos = CosineSimilarity()(logits[None, 0, :], logits[None,1, :]).squeeze().cpu().item()
return cos
def __call__(self, senA, senB, return_vector=False):
inputs = self.preprocess(senA, senB)
logits = self.predict(inputs)
result = self.postprocess(logits)
if return_vector:
return result, logits
else:
return result
pipe = SentenceSimilarityPipeline(model, tokenizer)
pipe("我喜欢北京", "北京是个真奇怪的地方,但是我喜欢", return_vector=True)
太耗时了,没有GPU.....
















 56
56











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









