







1 .简介
目前LLM是基于Transformer结构,其核心是self-attention,随着输入序列的不断增大,时间与空间复杂度都呈二次方增长。为了解决扩大Transformer模型上下文长度时面临的挑战,斯坦福大学和纽约州立大学布法罗分校的研究者共同提出了FlashAttention,通过提供一种快速且内存高效的注意力算法,无需任何近似即可加速注意力计算并减少内存占用。 FlashAttention的核心原理是将输入QKV分块,并保证每个块能够在SRAM(一级缓存)上完成注意力操作,并将结果更新回HBM,从而降低对高带宽内存(HBM)的读写操作。总之,FlashAttention从GPU的内存读写入手,减少了内存读写量,从而实现了2~4倍的速度提升。
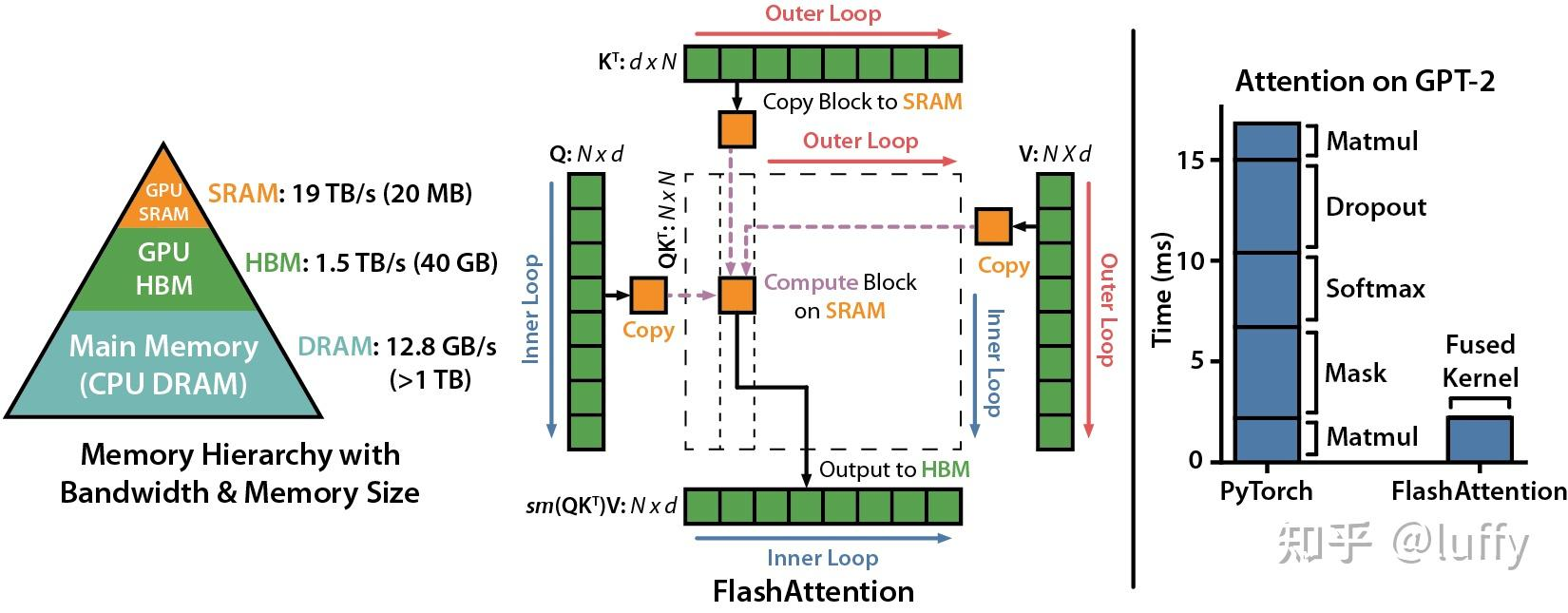
1.1 GPU 内存层次结构
在 GPU 中,数据访问速度由快到慢的层次:
- 寄存器(Registers):最快,但容量极小(每个线程私有)。
- 共享内存(Shared Memory):
- 片上缓存,速度接近寄存器,容量有限(每 Streaming Multiprocessor 约 48KB~128KB)。
- 关键作用:用于线程块(Block)内的线程协作,适合存储频繁访问的临时数据(如分块的 Q, K, V )。
- L1/L2 缓存:硬件自动管理,速度中等。
- 显存(HBM, High-Bandwidth Memory):
- 容量大(如 40GB),但延迟高、带宽有限。
- 瓶颈:频繁读写显存会大幅降低计算速度。
1.2 传统 Self-Attention 的显存瓶颈
标准 Self-Attention 的计算流程:
- 从显存加载完整的 Q, K, V 到 GPU 计算核心。
- 计算 S = QK^T (显存占用 O(N^2) )。
- 将 S 写回显存,再加载回来计算 Softmax。
- 计算 O = \text{Softmax}(S)V ,结果写回显存。
问题:
- 显存频繁读写: S 和中间结果需要多次显存访问,成为性能瓶颈(“Memory-bound”)。
- 缓存未充分利用:大矩阵无法完全放入共享内存,导致重复从显存加载数据。
2 Flash Attention 优化缓存
1. GPU内存优化:减少显存访问(降低计算时间);
2. Safe Softmax:避免数值溢出(保证稳定性);
Flash Attention 通过以下策略最大化共享内存利用率,减少显存访问:
(1) 分块计算(Tiling)
- 将 Q, K, V 分成小块(如 B_q \times d 和 B_k \times d ),确保每块能放入共享内存。
- 外循环:遍历 K 、 V 的块(每次加载一部分 K 和 V 到显存)。
- 内循环:遍历 Q 的块(每次计算 Q 的一个子块与当前 K 块的 Attention)。
- 结果:每个 Q_i 和 K_j 的组合都会被计算一次局部 Attention Score,总计计算次数为 \frac{N}{B_q} \times \frac{N}{B_k} 次( B_q, B_k 是块大小)。
# 显存占用低:分块计算,无完整中间矩阵
O = zeros_like(Q)
m_global, l_global = -inf, 0
for K_j, V_j in blocks(K, V): # 外循环:K/V分块
for Q_i in blocks(Q): # 内循环:Q分块
S_local = Q_i @ K_j.T # 局部计算
m_local = max(S_local)
S_stable = S_local - m_local
P_local = exp(S_stable) / sum(exp(S_stable))
# 更新全局最大值并重新缩放
m_new = max(m_global, m_local)
scale_old = exp(m_global - m_new)
scale_local = exp(m_local - m_new)
l_new = l_global * scale_old + sum(exp(S_stable)) * scale_local
O_i = (O_i * l_global * scale_old + P_local @ V_j * scale_local) / l_new
m_global, l_global = m_new, l_new- 每个块的 Q_i, K_j, V_j 从显存加载到共享内存后,所有计算(矩阵乘、Softmax)均在共享内存中完成。
(2) 避免中间矩阵存储
- 不存储完整的 S = QK^T :直接分块计算并累加到最终输出 O 。
- 动态更新统计量:通过维护全局最大值 m 和指数和 l ,避免显存访问。
(3) 计算与IO重叠
- 使用异步操作(如 CUDA Streams)在计算当前块时,预加载下一个块的数据到共享内存。
数学原理:利用Softmax的平移不变性.

















 1805
1805

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









