







转载请注明作者和出处:https://blog.csdn.net/qq_28810395

一、目标检测简介
在现在的计算机视觉(computer vision,CV)中,图像分类、目标检测、图像分割是计算机视觉领域额三个主要任务。从图像中解析出可供计算机理解的信息,是计算机视觉邻域重点要解决的问题,深度学习模型的出现,其强大的表示能力为机器视觉提供了巨大的助力。下图就是机器理解图像的三个层次。

- 目标检测(Detection):
分类任务关心整体,给出的是整张图片的内容描述,而检测则关注特定的物体目标,要求同时获得这一目标的类别信息和位置信息(classification + localization)。相比分类,检测给出的是对图片前景和背景的理解,我们需要从背景中分离出感兴趣的目标,并确定这一目标的描述(类别和位置),因此检测模型的输出是一个列表,列表的每一项使用一个数组给出检出目标的类别和位置(常用矩形检测框的坐标表示)。简单来说就是知道这个物体是什么,同时知道目标在什么地方。
二、认知物体流程
生活中的认知物体流程无非就两种方法先看这个东西,再看这个在哪、先看位置,再看哪个东西。 机器视觉同样仿生人类认知物体过程,现在可以思考一下你自己是怎么个认知物体过程。
没错,在大多数人的认知过程,是先定位后认知物体。同样的现有的机器视觉也就采用了这种认知物体流程。先定位–进行裁剪划分–判断类别
三、目标检测难点
目标检测目前主要存在的主要问题,也是目标检测未来的发展方向:
- 图像质量(光线亮暗、高对比度)不同的检测
- 小目标物体检测;
- 遮挡面积较大的目标检测;
- 区分图像中与目标物体外形相似的非目标物体;
- 实时性检测;
- 小数据量迁移训练效果的提升;
- 目标检测范围应用越来越广,缺乏各种各样的训练样本数据。

四、评判标准

Accuracy(准确率) 是分类指标中最初级的指标,是代表了预测正确结果的样本占总样本的百分比,给出定义如下:
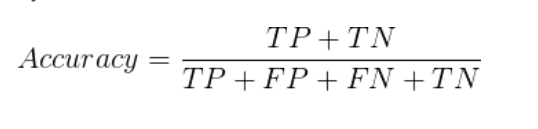
利用其可以判断模型的正确率,但由于受样本不平衡,导致所计算的准确率拥有很大水分,导致结果不正确,所以下述两个指标正是弥补其的不足之处。
Precision(精准率) 又称为查准率,代表了预测为正样本中实际是正样本的百分比,简单来说就说识别出的物体正确的占比,给出定义如下:
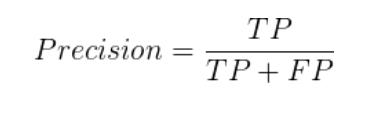
*相比于准确率,精准率代表的是正样本中预测正确的概率,而准确率整个模型在全部样本中的准确概率。
Recall(召回率) 又称为查全率,代表实际为正样本中被预测为正样本的百分比,简单来说,就是在实际图像物体中,我们找出并正确的是占多大比例,给出定义如下:
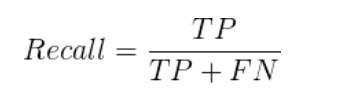
对比下面图片进行详细理解。

五、RCNN算法
R-CNN是一种基于区域的卷积神经网络算法,它在卷积神经网络上应用区域推荐的策略,形成自底向上的目标定位模型,摒弃了传统的多尺度滑动窗口确定所有可能的目标区域和人工选取特征的方法,将候选区域算法和卷积神经网络(feature)相结合,使得检测速度和精度明显提升。
- Faster-rcnn算法网络:

- Preprocessing 首先将输入的不规则大小image进行裁剪处理(统一尺寸)。
- Conv layers.作为一种cnn网络目标检测的方法,faster_rcnn首先使用一组基础 conv+relu+pooling层提取image的feture map。该feature map被共享用于后续的RPN层和全连接层。
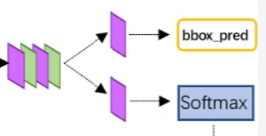
- Region Proposal Networks.RPN 层是faster-rcnn最大的亮点,RPN网络用于生成region proposcals.该层通过softmax判断anchors属于foreground或者background,再利用box regression修正anchors获得精确的propocals.
- Roi Pooling.该层收集输入的feature map 和 proposcal,综合这些信息提取proposal feature
map,送入后续的全连接层判定目标类别。 - Classification。利用proposal feature map计算proposcal类别,同时再次bounding box
regression获得检验框的最终精确地位置。
总体分为四个部分:特征提取——粗分类+定位(RPN)——NMS去重——精分类+定位。
- RPN网络:
遍历特征图上的每个像素点,然后根据不同位置和宽高的anchor框从原图上生成候选框(人为定义)。

特征图的每个像素点生成三种不同尺度大小的anchor 框,每种框的宽高比分别为:1:1,2:1,1:2, 即特征图上的每个像素点共生成9个不同大小的anchor框。

边框回归

NMS算法
第一阶段结束后会生成大量的候选框,巨大的数量会大大影响模型运算的速度,同时大量的候选框存在重合的情况,因此需要通过一定的手段在不降低候选框质量的情况下减少框的数量。NMS (非极大值抑制) 是为了去除重复的无效框,保留得分最高的目标框。

如上图,对所有候选框按得分进行排序,所有候选框与当前框进行交并集运算,大于阈值的进行删除,然后逐框进行上述过程。
第二阶段首先把经过RPN输出的ROIs映射到ROlpooling的特征图上,然后再进行目标分类和边框回归的精修,这时softmax分类器的类别不再是前景和背景两类,而是实际的类别数量,这样就完成了一次完整的目标检测。
六、参考文献
https://blog.csdn.net/Lin_xiaoyi/article/details/78214874
https://blog.csdn.net/xiaohu2022/article/details/79211732
http://edu.cstor.cn/#/
















 1173
1173











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









