







话术:将整个项目的各种业务、技术亮点,进行抽取,编写成大白话,涵盖所有的核心业务、各种技术解决方案。
真正做到,就算你照着念,都可以给面试官讲明白。
解决面试问题:
- 你介绍一下你最近/最熟悉的一个项目经验吧
- xxx技术在这个项目中用到过是吧?
- xxx 业务遇到xxx问题,你们是怎么解决的?
针对自己的项目经验,最起码自己做的部分业务,整理的特别熟悉。
本套课程特色:以问答形式,梳理话术,编写成大白话,讲解出来,并且分析其中的部分核心业务技术难点
1.请你介绍一下你最近这个项目吧
注意:
一定要追求真实,一定要给一个真实背景。千万别完全照着头条课件上的东西去说,很容易撞车。
项目介绍三要素:项目介绍、岗位职责、业绩、技术亮点
下面的话术中,项目名称自己适当修改一下,依据所在城市进行包装。
话术1:
好的面试官,我最近做的这个项目是融媒体项目,准确来讲是一个融媒体平台,项目是我们公司自研的,核心业务就是基于我们公司自有的媒体资源、社群、自媒体资源进行整合。基于我们研发的融媒体平台,构建了多款App,分别针对不同的客户群体。公司业务规划走的就是融媒体矩阵,每个App项目分别针对不同的类目进行打造,各自做专业垂直类目的App。说白了就是前端换了个皮肤,垂直类目有母婴、健康、旅游、以及各省市区域进行打造,只要运营需要,随时可以生产出很多App.
项目的核心就是通过矩阵玩法,聚集不同类目下的用户,每一个项目都是一个垂直类目,吸引不同兴趣爱好的用户,说白了就是养一波铁粉,然后为后期打造私域营销、垂直类目精准客群推荐打好基础,后期公司计划就是走这个广告和垂直类目电商进行营利。
还有就是项目架构,我们首先是将整体系统拆分成多个分布式子系统,比如大数据计算和推荐、平台运营管理系统、还有就是我参与的
这个融媒体平台项目。
我主要是负责融媒体平台端的一些功能开发,后台架构是用的微服务,便于业务的扩展和将来部署时动态的管理服务资源。
主要服务的话就是个人中心、文章服务、行为数据服务、任务调度微服务、评论服务、检索服务、自媒体管理服务、平台管理服务、图片管理服务、统一认证服务这些基本业务服务,大概有十几个,大部分服务模块相关的核心业务开发我都参与过,我们公司开发模式的话没有严格的划分具体负责哪些模块,都是根据月度下发的任务进行分配的。
我们项目选择的技术还是比较ok的,比如:基于SpringCloud Alibaba系列微服务组件,进行搭建,用到Nacos、Sentinel、OpenFeign、Gateway、SkyWalking等微服务组件。
然后业务层,就是每一个微服务的话,我们是用的SpringBoot、MybatisPlus、Redis、MySQL、RabbitMQ、Elasticsearch这些技术还是比较主流的;
我在项目中的话,主要是负责java 后端开发,算是我们小组的主力吧,项目也是做了有一年了,目前已经上线几个APP了。
主要独立负责的一些核心业务的话就是有用户推荐服务java端、个人中心、文章服务、任务调度微服务、评论服务、检索服务、统一认证服务这几个核心模块业务的设计与编码。
这个项目我从项目立项那会就参与了,我刚进公司的时候这个项目刚开始做,所以这类型业务也是非常熟悉,当然我主要是做后端开发。大概就是这个情况,面试官。
2.你们项目的开发环境是怎么搭建的
我们公司的项目环境有开发环境、测试环境和线上生产环境,测试环境和生产环境是运维搭建的。
然后开发环境是我(如果你包装3年以下就说你组长搭建)搭建的,我们公司内部有专门的开发机,就是一台高性能的服务器,然后我在上面使用Docker部署了一些项目开发环境用的东西,比如:Redis、MySQL、Nacos Server端、Sentinel Server端、SkyWalking Server端,还包括一些其他中间件,Elasticsearch、RabbitMQ、XXL-JOB这些中间件,还有ELK日志平台,这些都是我部署的。
因为开发环境的这个服务器性能足够满足我们日常开发使用,所以就部署在一台服务器上。主要是能够快速的重置、重启就可以了。
至于公司内部项目管理工具、GitLab、公司内部知识库这些不是我搭建的,因为这些都是公司平台自有的。
开发的时候,我们就是连接公司内网的开发机,所有的连接方式、账号信息,我都是写好文档,在公司内部的wk平台上发布了,用的时候,其他同事去参考就行了。
如果回家后需要加班的话,我们就配上VPN连接公司内部服务器就行了。
3.登录你们是怎么做的?
平台方、媒体端、用户端登录方式是不一样的,平台端和媒体端是支持账号密码、手机验证码登录。
用户端是支持账号密码、手机验证码、微信登录、微博登录多种登录方式。
平台端和媒体端是必须登录后才能使用。
用户端的话,可以匿名访问,但如果要点赞、评论、收藏或者查看个人中心等行为的话,还是需要登录的,App页面会自动跳出来登录界面。关于登录这块都是我做的,我给您挨个说一下吧。
3.1账号密码登录
我们首先设计了用户表,用户表中包含了用户的账号、密码、手机号、头像、注册时间、是否身份认证这些字段。
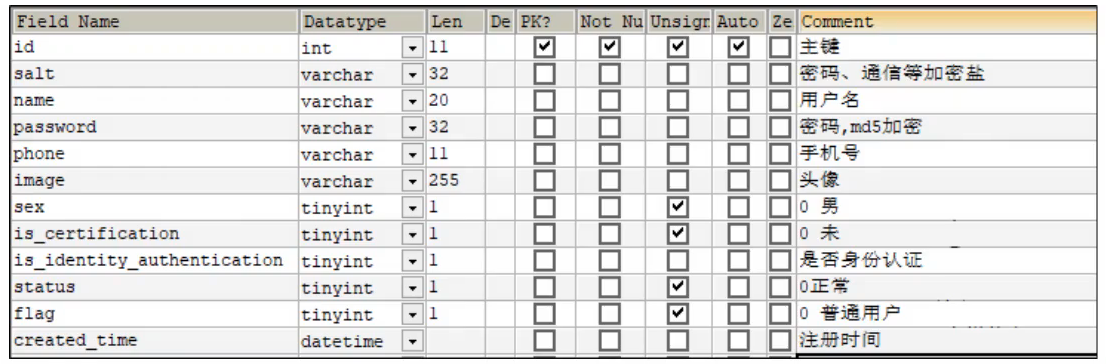
当前端提交请求时,请求体中以JSON形式提交账号、密码、验证码这几个参数。
请求先到后端gateway网关,网关处判断登录请求时不需要校验Token的,所以直接放行。
请求被转发到user用户服务这里,流程也很简单,先针对参数进行校验,非空、是否合法,如果参数有问题,则直接返回登录失败信息。
如果参数有问题,则直接返回登录失败信息。
如果参数没问题,就判断一下账号密码是否频繁登录,这里我是借助redis的zset数据结构设计了一个时间窗口限流算法实现的。
如果没有限流,就查询用户数据,用户是否存在,如果不存在就返回登录失败。如果存在,就校验密码,我们是使用加随机盐的一个工具类BCrypt实现的,它的安全度更高。
如果密码校验通过,就封装用户数据,比如用户名、用户头像,封装到JWT Token的载荷中,返回给前端就可以了。
以后前端就带着这个Token访问其他资源。当然了,我在网关处,针对Token进行校验,比如访问受限资源,需要判断是否有Token,判断Token是否有效,如果Token没问题,就将请求放给后面的微服务。
3.2手机验证码登录
这个流程主要涉及到3个接口,分别是:
- 手机验证码发送接口,在common通用服务中
- 滑块验证码接口,在common通用服务中
- 手机验证码登录流程,在user通用服务中
3.2.1手机验证码发送
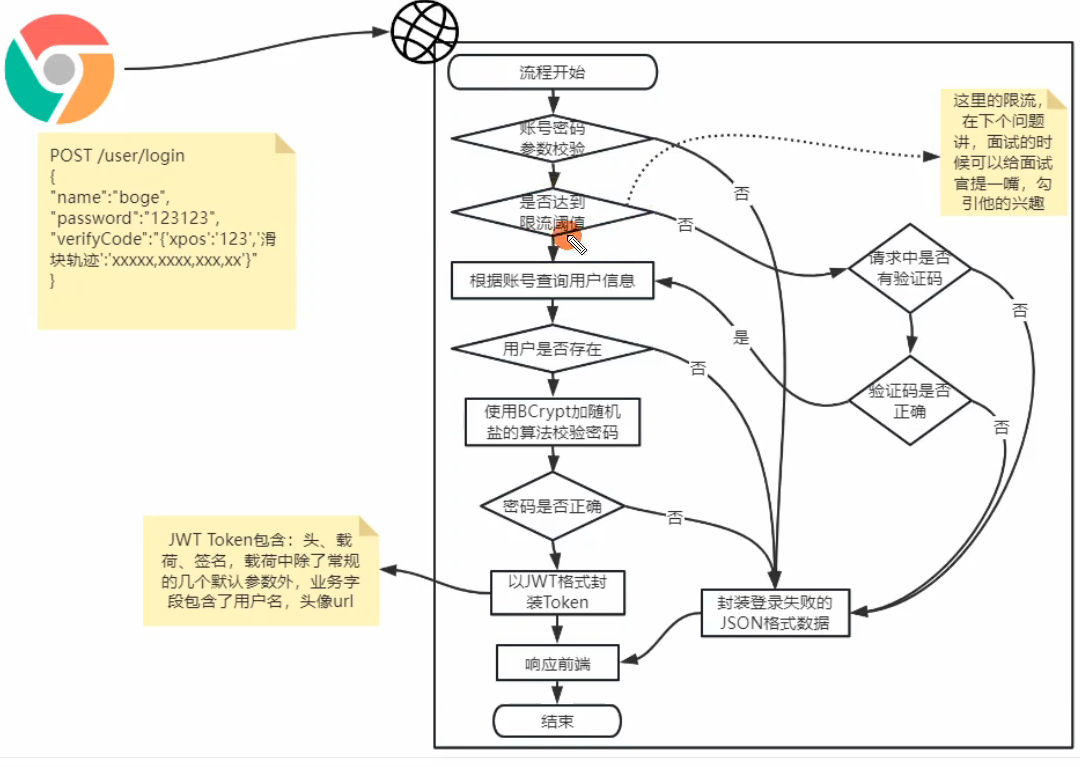
首先用户在页面填写手机号码,前端校验手机号没有问题,就会自动向后端【发送登录短信】接口发起请求。
我们是设计了一个common服务,就是封装了一些通用功能的服务,将发短信、OSS对象存储这些通用功能都放到这个通用服务中实现。
common服务的短信发送接口,接收到了用户请求后,先针对手机号进行校验,校验的细节是这样的,先校验手机号是否合法,然后校验手机号是否被拉黑,这个拉黑主要是防止用户疯狂的刷我们的发短信接口。判断用户是否拉黑的依据就是在Redis中存了一个TTL过期时间为10分钟的拉黑key, 如果这样用户一旦被拉黑,只能10分钟后才能访问我们这个接口。
然后校验手机号是否达到限流阈值,这里我是基于redis的zset,设计了时间窗口限流算法实现的。
限流的条件是满足5分钟内发生3次发短信行为,就判定进行限流。
如果没有达到限流阈值,我们直接调用三方的短信服务,发送短信。
短信发送成功后,我就把短信验证码,缓存到Rdis中,过期时间TTL设置为默认5分钟,当然这些时间配置什么的,我们都使用统一的配置文件管理了,可以动态修改的。
缓存在Redis中的key的格式为:USER:LOGIN:手机号,值就是验证码的随机值。
最后响应前端短信发送成功。
另外还有一个点就是限流的细节,我给您讲下,我们分两级验证码限流的:
- 第一级:用户5分钟内连续发3次短信,达到阈值后,使用滑块验证码限流,查询请求参数中是否携带滑块验证码参数,如果有,就查询redis中的验证码,比对前端提交的这个参数是否正确,如果正确,就直接放过去。
- 第二级:用户10分钟内,连续发8次短信,达到阈值后,直接限流用户10分钟后重试,实现方式就是将用户拉黑,把用户的手机号设计为key,比如: BLACK:LOGIN:手机号,TTL过期时间设置为10分钟,这样用户下次请求时,直接判断这个手机号是否在黑名单,如果在的话直接就拒绝了。10分钟后自然会过期,就又恢复正常发送短信了。
3.2.2手机验证码登录
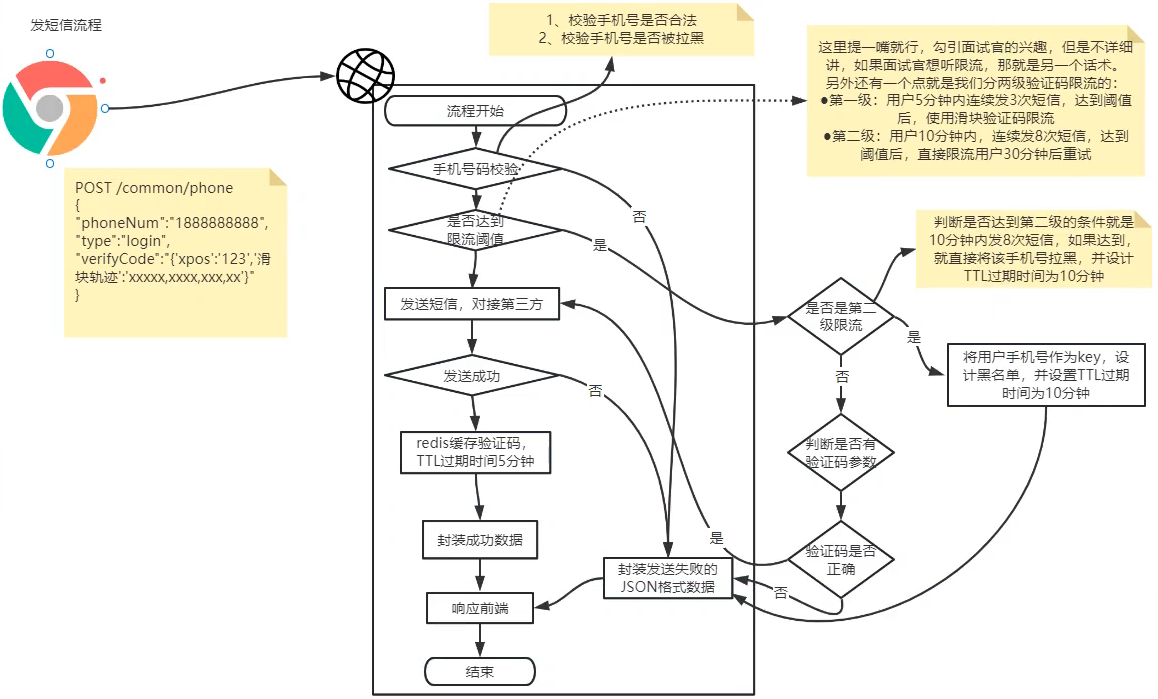
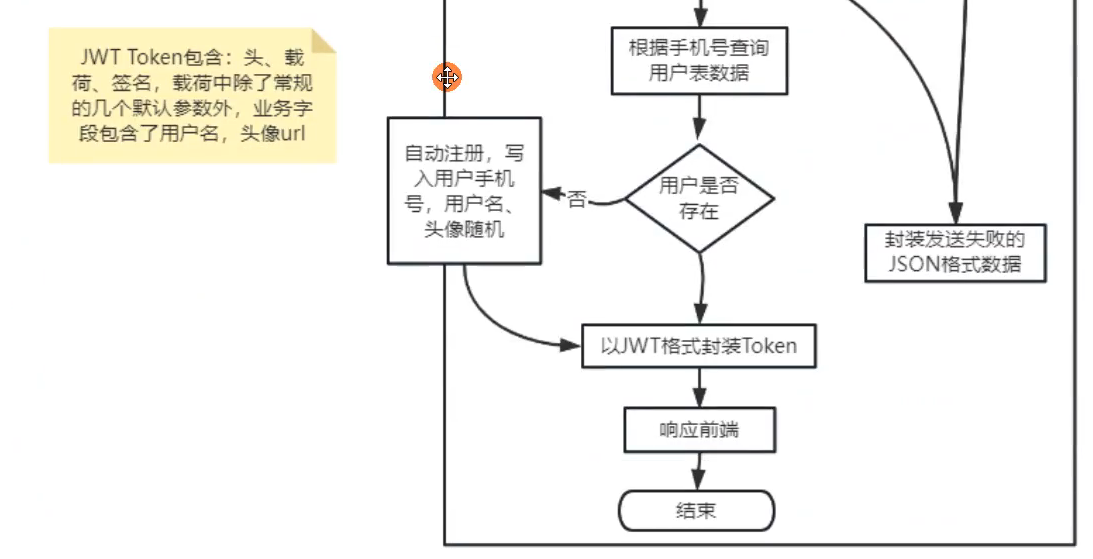
首先是前端提交登录登录表单,包含手机号、验证码。
后端接收到请求后,先校验一下手机号是否合法。
然后根据手机号,查询Redis中缓存的真实验证码,查询完毕后销毁掉redis中的验证码。比对验证码是否正确,如果验证码不存在,或者验证码错误,那就直接返回前端失败信息。如果验证码正确,就根据手机号查询用户表中用户数据,如果用户存在,就以JWT格式封装
用户Token,返回给前端。
如果用户不存在,也没关系,直接默认自动注册,写入用户的手机号,关于用户名和头像用默认值代替。
用户自己可以在个人中心中,修改用户名、头像、密码等数据。
4.登录时手机验证码有做过限流吗?(同样适用于其他限流场景)
有的,这个必须做限流,我是利用redis的zset结合时间窗口限流算法进行实现的。
我们是这样考虑的,用户可能有很多行为,是无意义,或者非法的,比如:频繁发送短信、频繁修改个人信息、频繁的点赞、评论等等行为,都应该进行限流。
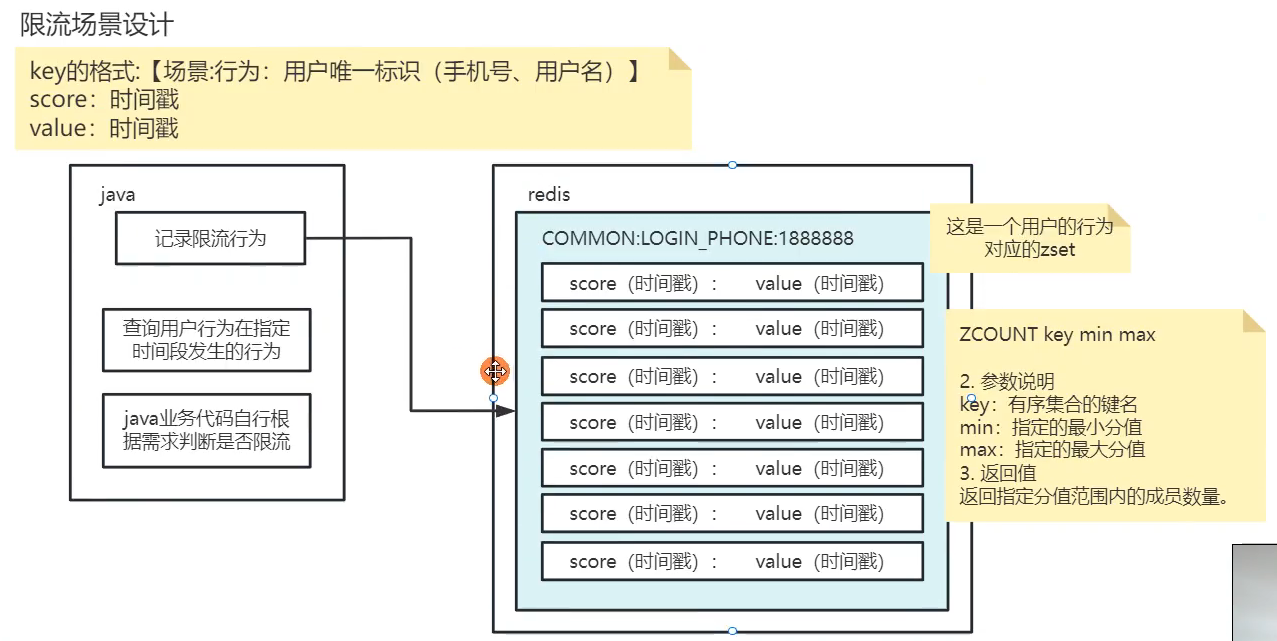
所以我就针对这些频繁的行为进行限流,设计了一个通用的限流接口。思路上是使用时间窗口限流算法,具体实现我利用redis的Zset进行实现。
比如说,用户5分钟内只能发送3个验证码,或者10分钟内只能发送8个验证码,于是我就将用户发短信的行为设计为ky,格式为【场景:行为:用户唯一标识(可以是手机号、用户名)】,score分数值是时间戳,value值也是时间戳。
具体流程:
当用户每次发生限流行为,都会记录这个行为,以Redis zset的方式进行记录。
在业务处理流程中,使用java api进行查询判断,其实本质就是调用redis的zcount命令,这个命令可以传入起始分值和结束分值。我就把当前时间戳作为结束分值,然后当前时间戳减去限流时间,比如说5分钟的毫秒值,求出来5分钟前的时间戳。于是根据这两个时间戳作为分值,范围查询zst中出现的次数,就得到用户在5分钟内,这个行为一共触发了几次。
后续的业务,就是不同场景中,根据不同的需求,进行校验就行了,比如说5分钟限流3次,10分钟限流8次,这就是后面的业务代码考虑的事情了。
限流算法思路:

5.续约Token怎么设计的?
这个续约token在我们的项目中有设计过,恰好也是我做的。
当时产品经理给到的需求是,要求用户可以保持一个长期登录或者自动登录的效果。避免用户状态频繁过期,频繁登录给用户带来不便。
我当时就使用双Token的方式进行设计的,这种方案提出来后是经过组长评估的,他也认为没问题,于是我就这么做了。
我给您说下我的大概实现思路吧。
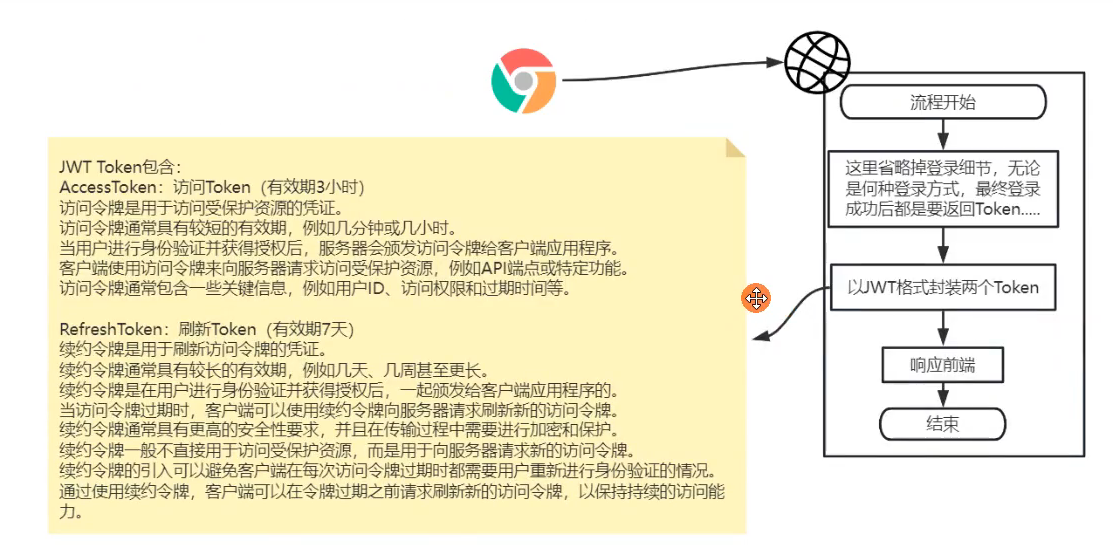
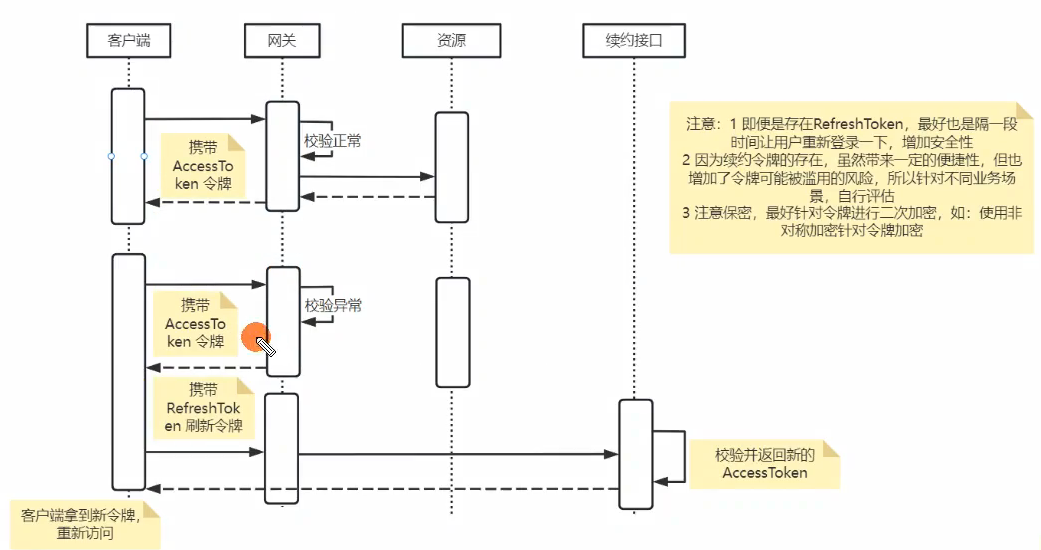
首先是登录,在登录的时候,无论何种方式认证,最后都是返回Token给到前端。
在返回Token的时候,是生成两个Token:
- 一个是AccessToken,我管他叫访问令牌,我处于安全考虑,比如防止令牌被恶意使用,设置他的有效期为3个小时,每次请求资源时携带这个令牌;
- 另一个是RefreshToken,我管他叫刷新令牌,这个令牌不能用来访问资源,只能用来刷新访问令牌,就是每当访问令牌过期,前端携带这个RefreshToken获取新的AccessToken,这个刷新Token的有效期我设置为7天,当然这个可以改,这是写在配置文件中的;
当Token返回给前端后,浏览器端用的是localStorage保存的,App端的话有他们自己的本地保存方式,将这两个Token保存下来。
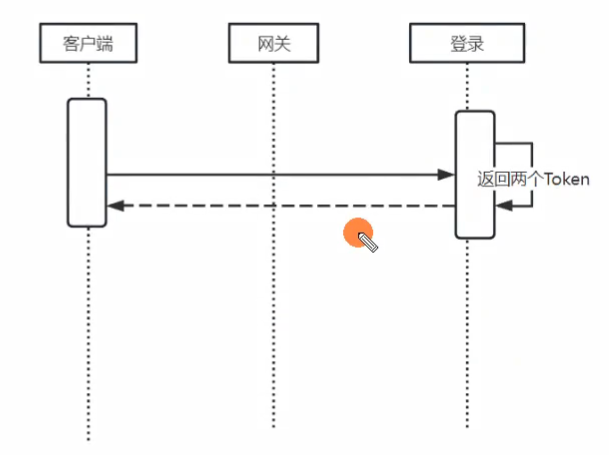
然后就是访问资源的时候,我们在网关处会进行校验,如果访问的是受限资源,那么网关写了
一个全局过滤器,
校验是否携带AccessToken,以及这个Token是否过期,如果正常,则直接放行。
如果校验异常,可能是Token过期,也可能是Token数据被篡改或损坏,于是返回拒绝。
前端判断拒绝的状态码为AccessToken无效后,会重新发起一次请求,携带RefreshToken重新请求续约接口,这个续约接口是不需要网关拦截的,然后续约接口针对RefreshToken进行解密后,校验签名没有问题,没有被篡改,于是重新颁发新的AccessToken,返回给前端。
前端重新携带AccessToken发起请求就行了。
这里面有个重要的地方就是,我针对令牌使用RSA非对称加密进行加密,目的就是防止被篡改数据。
这就是我设计的实现方案。
6.前后端交互是怎么配合的?
我们是使用Swagger、Knife4j快速生成后端的接口文档,然后给到前端,和前端进行配合的。
这个Knife4j就是一个整合了Swagger和OpenApi的工具。
开发接口的时候,我们是使用Swagger提供了一波注解,标注在不同的类、方法、属性上面快速的生成在线文档。
然后Knife4j进行了增强,不仅页面美化了,而且还可以在线调试,还支持导出离线的接口文档。
我当初就是在开发环境启用了Knife4j,只有在开发环境中,前端能够访问到我们的接口,然后也可以直接导出离线版,发给前进行对接。
另外我自己本地测试的时候,包括和前端进行面对面沟通的时候,我是习惯使用postman进行测试,Knife4j 提供的那个测试页面功能太少,没有Postman专业。
包括我们项目的每一个接口,都是在PostMan中创建了团队,进行维护的。
无论是前端还是后端,都可以直接在它的接口列表中直接调出来以前写好的接口,进行接口测试的。
7.你们项目前端是怎么部署的?
我们前端的话分为App端和PC端。
App端是查接打包成应用的。
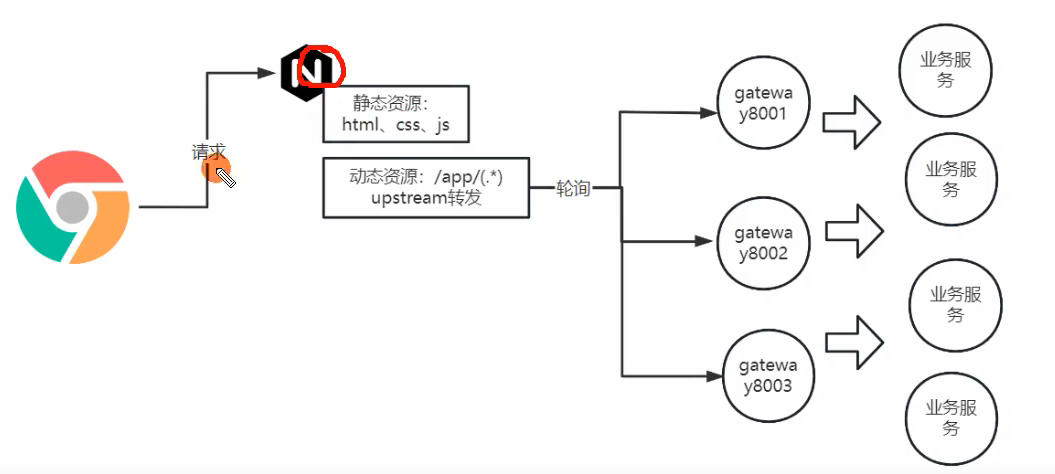
PC端是需要将前端资源部署在服务器中的,我们是采用nginx作为前端项目的部署服务器。
前端我们架构是使用vue写的,前端写完后会使用webpack进行编译构建,把vue文件转为编译后的js、css、html之类的静态资源。
然后把这些静态资源打包发布到nginx服务器。
部署方式也很简单,将静态资源更新到nginx的html目录下,然后修改nginx配置文件,将root目录指定到项目路径,这样前端请求域名根路径下的静态资源时,直接在nginx端进行响应了。
另外我们还配置了关于后端的api访问路由,凡是以app路径开头的资源,全都转发到后端的网关微服务上,转发的策略用的是轮询。
8.文章查询流程讲一下
文章查询我们是支持首页查询、频道栏目查询,另外还提供了关键字检索功能。
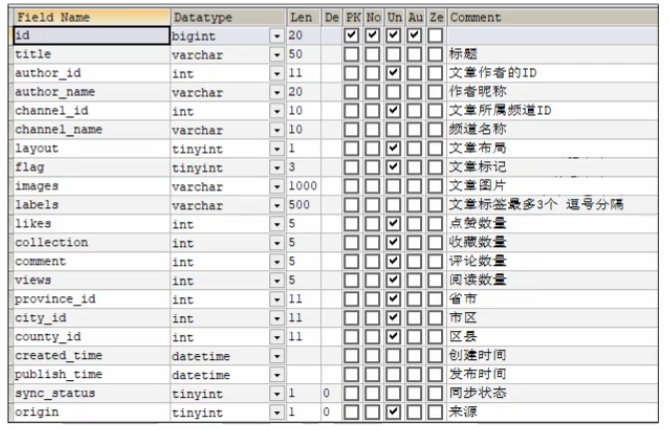
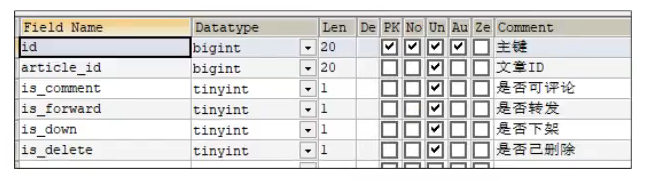
先说一下这个表结构吧有3张表存储文章信息:文章基本信息表、文章配置表、文章内容表,他们之间都是一对一的映射关系。然后还有一个大数据推荐接口被我们调用。
ap_article文章基本信息表
ap_article_config文章配置表
ap_article_content文章内容表
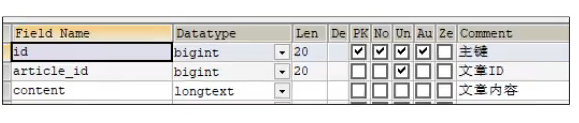
当初我在设计这三张表的时候,本质他们都是文章相关的字段,本应该在一张表里面,但是考虑到后续随着数据量的增多,可能会单表带来很大的压力,所以进行了垂直分割。我按照查询的业务维度进行拆分的,比如:基本信息一张表,配置信息一张表,文章内容一张表进行分离。
先说首页查询吧,首页查询其实是推荐查询,推荐的依据主要是:
- 用户自己在个人中心配置过的感兴趣标签:
- 大数据系统根据用户行为数据分析得到的用户画像,这个是不断更新的;
- 系统本身的推荐,如:管理员设
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5068
5068

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









