







DW集训营数据库基础算法梳理[一]
一. 损失函数的极大似然推导
要知道如何用极大似然推导,首先先要明白什么是损失函数,以及为什么要定义损失函数?
在多元回归中,需要求的目标值可以描述为:
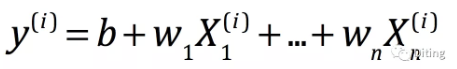
为了描述其表示的误差,在最小二乘法的描述中,我们通过目标值和预测值的差来度量回归模型,最后我们选用了均方误差MSE来作为回归效果的度量:

之所以用均方误差MSE来描述,是因为一是这样其连续可导,另一方面是它将限制最大的误差尽可能的小,于是我们就将这个式子表述为误差函数,以损失函数达到最小值的目的,找到回归模型的最优解w和b。
搞清了损失函数的概念后,我们来理解下极大似然是什么鬼?以及为什么要用极大似然?
虽然我们使用最小二乘法得到了损失函数,但是如果从统计理论的角度出发来推导损失函数,我认为更有说服力,也能更好地理解线性回归模型,以及为什么开始要提出一些假设条件。
最大似然估计是一种确定模型参数值的方法。确定参数值的过程,是找到能最大化模型产生真实观察数据可能性的那一组参数。

二. 一元线性回归的参数求解公式推导
对于一元线性回归来说,其实质就是当样本特征只有一个时,来寻找一条直线,最大程度的来拟合样本特征和样本输出标记之间的关系。
那么如何来判定这个直线拟合程度的好坏,有一种方法时,让每个点求其到直线的距离,使得这些点到直线的距离之和为最小。
但是点到直线的距离中每个都有开方,最后开方相加会让求解的复杂度增加。故在这里可以对每一个点拉一根平行于y轴的直线,以到y轴的距离值来衡量拟合程度的好坏。
因为有的点在直线上,有的点在直线下,会出现负数,故在这里需要加上绝对值,但是绝对值因为表现的形式是坐标轴为对角线的正方形,而正方形的四个顶点不满足可导的条件,在后面求梯度中要求求导时会比较繁琐。故在这里采用距离的平方来表示。
即:

在x和y已知的情况下,找到目标a和b,使得尽可能的小,一般使用J(a,b)或者loss来表示损失函数。
损失函数的最小值就是求函数的极值,接下来对函数进行求导,当存在两个变量时,我们就对函数的各个未知分量进行求偏导,使得其偏导数为0,导数为0的地方,就是函数极值的地方。

其实就相当于对复合函数的链式求导法则,因为对a求偏导时需要用到对b求偏导的量,所以我们先对b求偏导,手推如下:

三. 多元线性回归的参数求解公式推导
为了使得y的表达式中的每一项都是一致的,我们b后也乘以一个X0,这样可以让式子结合在一起,计算时也更加方便,此时X0恒为1,此时对于系数w和截距b而言,我们就可以将其统一表示为列向量的形式,即为:
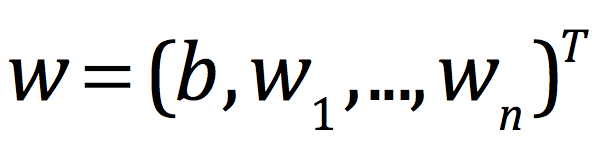
此时对于X而言,X已经是一个矩阵了,每一行表示一个样本,每一列代表一个特征,在这里Xi表示从X这个矩阵中抽出一行,所以它本身就是一个行向量了,对于目标函数而言,就变成了:
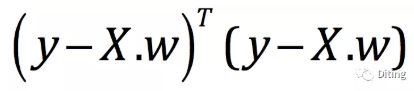
我们对其进行求导,得:

四. 线性回归损失函数的最优化算法
梯度下降是一种优化算法,能够为大范围的问题找到最优解。梯度下降的中心思想就是迭代地调整参数从而使得成本函数最小化。
批量梯度下降:对每一个样本进行计算,迭代的调整theta参数使得损失函数最小化;
特点:比较慢,且容易陷入局部值
随机梯度下降:每一步在训练集中随机选择一个样本,并且仅仅基于这单个样本来计算梯度,确定下一步搜索的方向;
特点:可以取到全局解,但容易取不到最优值
小批量梯度下降:每一步在训练集中选择的样本基于1和全部之间,并以选择的这些样本来确定下一步搜索的方向;
特点:基于’中庸’的思想,一定程度避免了陷入局部值,又在时间上得以保证;
在其中具体实现可以参考:
回归分析-手写代码实现梯度下降(一)
回归分析-手写代码实现梯度下降(二)
回归分析-手写代码实现梯度下降(三)
回归分析-手写代码实现梯度下降(四)
















 623
623











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











