







【学习任务】
前言
在引出信息论基础的这些概念前,我们先来说清楚为什么会用到它们,又是在什么情况下需要用到它们的?
决策树是一个非常人性化的模型,它的建模思路是尽量模拟人做决策的过程,其完全通过生成决策规则来解决分类和回归问题。这里拿招聘爬虫的例子来简单说明:
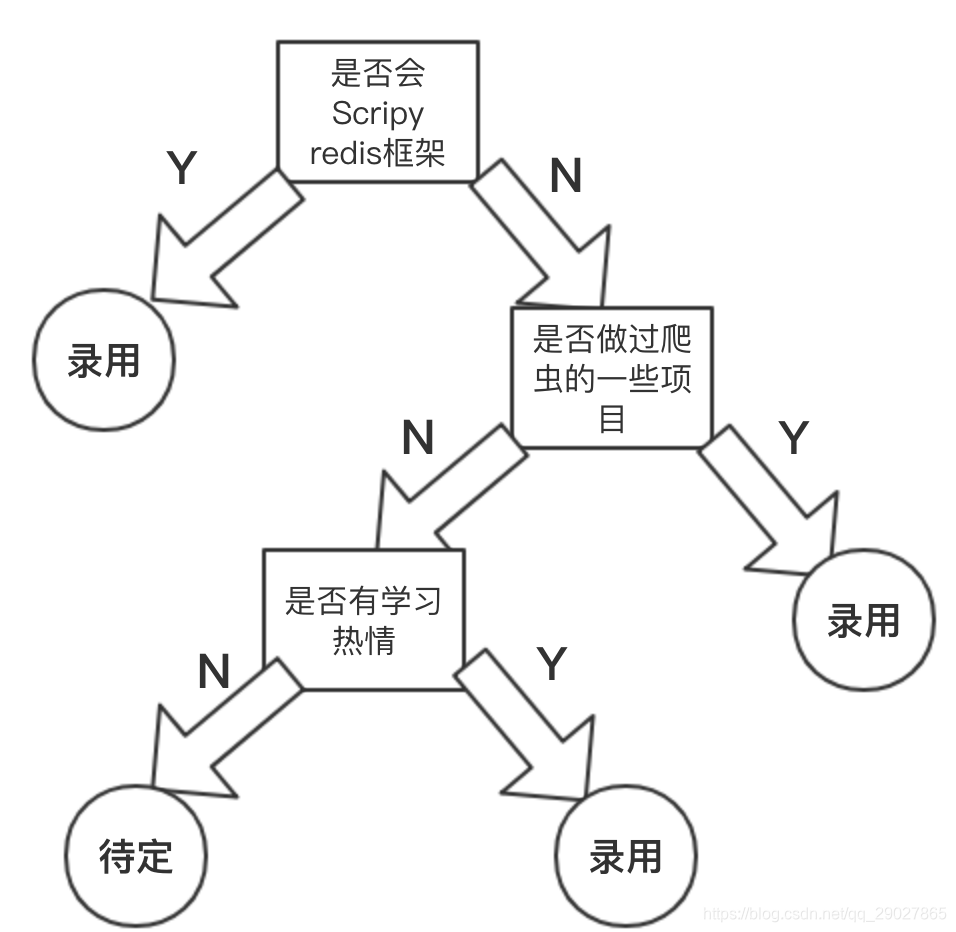
可以看到,这样的一个决策的过程,最终形成了一个树的结构,在这棵树所有的叶子节点的位置,其实就是我们最终作出的决策,这个决策在这里也可以认为是对输入信息(这里指应聘者的个人情况)的一个输出(这里指的是分类)。而这棵树的每个子树的根结点,就可以被认为决策规则。
但是,这种情况是我们的语言描述,不具有问题的解释性。如果具体到数值情况的话,决策树又是怎么表示的呢?我们以鸢尾花数据集的后两个特征,使用sklearn先看下决策树得到的分类效果:
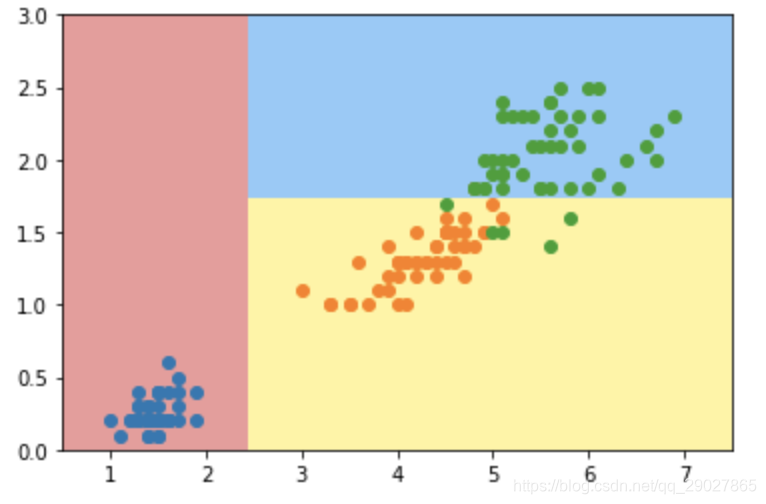
我们可以用树的方式来描绘该分类,如下:
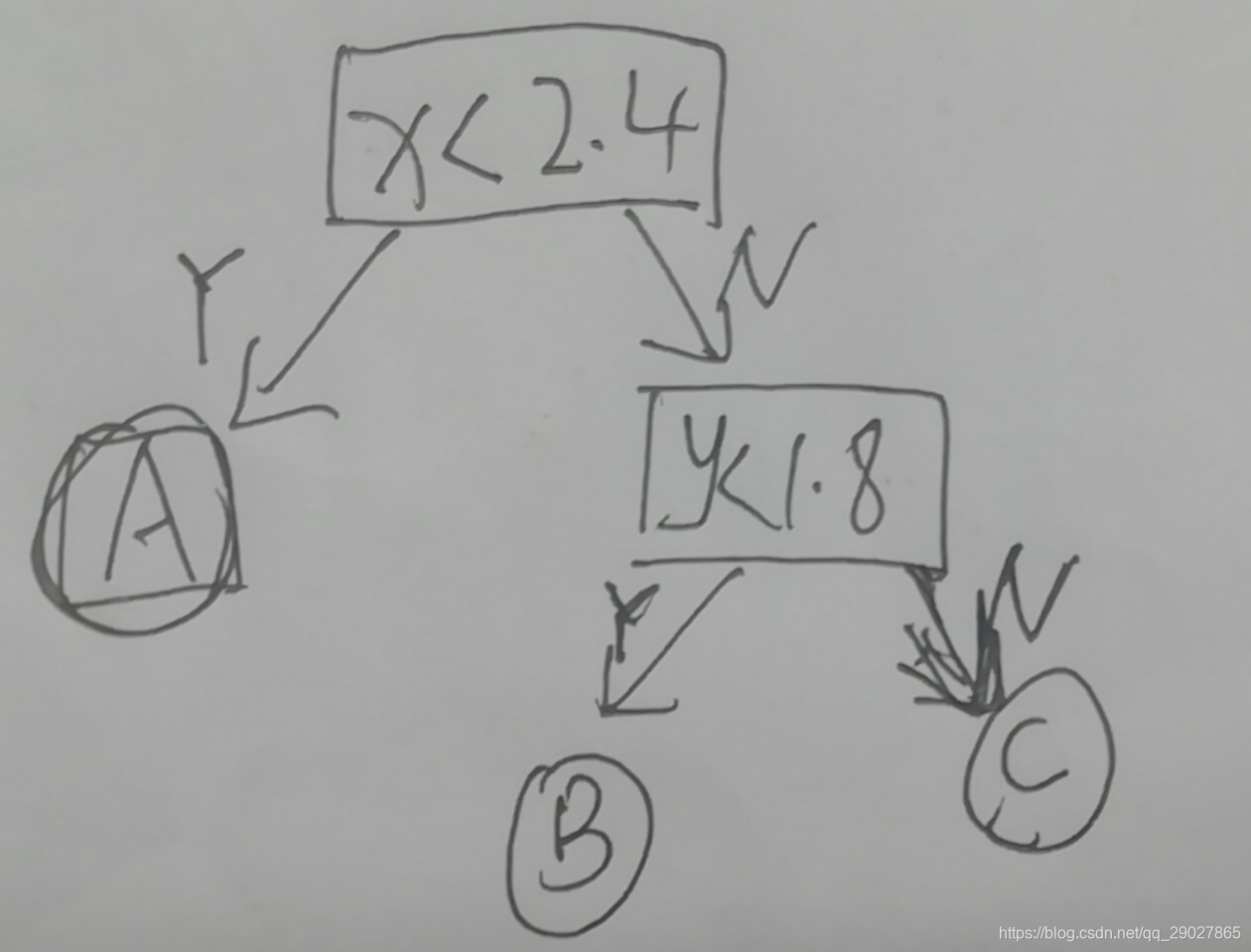
由此,我们知道决策树在数值上的表现就是,在每个节点上,它选择某一个维度以及和这个维度相应的阈值,然后根据此阈值来进行决策分类。
现在我们对决策树有了初步的印象,接下来我们的问题是,我们应该在每个节点的哪个维度做划分?我们又该在某个维度下的哪个值(阈值)上做划分?由此,我们需要引出信息论基础中的概念来进行解释。
1. 信息论基础(熵 联合熵 条件熵 信息增益 基尼不纯度)
信息熵:
熵原本是一个热力学的用词,在信息论中熵代表对随机变量不确定性的度量。对一组数据来说,熵越大,数据的不确定性越高,熵越小,数据的不确定性越低。
信息熵的公式如下:
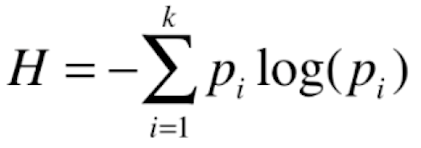
Pi: 在这里Pi指的是,在一个系统中,可能会有k类信息,每类信息所占的比例(注意这里是比例,不是概率,因为这个训练集中类别信息是确定的),就叫做Pi;
负号的解释:因为Pi本身都是小于1的,那么log(Pi)就是小于1的,为了抵消负号的影响,因此需要在其前面加上负号。
我们拿一个特例来解释信息熵,假如有5个类别,若干个数值,数值的分类比例可以表示为:{1,0,0,0,0},这种情况下的信息熵就为:H=-1.log(1)=0,熵达到最小值,即其不确定性最低,确定性最高,因为它每个样本都属于第一类。
那么现在我们就可以知道,决策树中如何划分的基本方向,就是经过划分之后使得信息熵降低,即数据的确定性变高,划分出来的信息熵,是所有其他划分方法中得到的信息熵的最小值,得到的这个划分的维度及维度下的阈值,即构建了决策树。
(由信息熵来定划分的维度和值的具体过程,以及构建决策树的过程代码,预计在2月4号补充完毕)
联合熵,条件熵,信息增益:
了解了信息熵后,其联合熵,条件熵,我认为其可以认为是在具体数据分布形式上的不同所引起的不同的计算方式,比如如果第一类和第二类相关,就可以用条件熵来表示。信息增益,我认为其是为了补全熵的精确度的一种更精确的方式。具体计算方式可以先参照:信息熵的描述
基尼系数:
和信息熵一样,相当于是另一种指标来指导决策树的划分,其式子表示为:
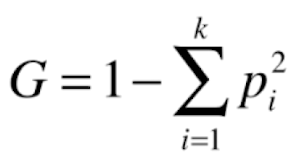
其表示的意义和信息熵相同,基尼系数越大,数据的不确定性越高,基尼系数越小,数据的不确定性越低。
对于基尼系数和信息熵,其实它们都可以认为是划分依据中的超参数,通过式子的对比,信息熵的计算比基尼系数稍慢,而scikit-learn中默认划分的参数为基尼系数,但大多数情况下,这个超参数的选择没有太大的区别,得到的结果非常相似,对模型的影响非常小,而对模型影响大的,就是接下来介绍的分类算法超参数。
2. 决策树的不同分类算法(ID3算法、C4.5、CART分类树)的原理及应用场景
CART:
sklearn内核写法:
CART全称为Classification and Regression Tree,其既可以解决分类问题,也可以解决回归问题。其特点就是在每一个节点上根据某一个维度d和某一个阈值v进行二分,这样得到的决策树就是一颗二叉树。
ID3算法,C4.5也均由特征选择,决策树生成和决策树剪枝这三个步骤完成,具体的差异在于特征选择时使用的标准不一样,其中ID3使用信息增益,但存在偏向选取值较多的特征的问题;针对ID3的问题,C4.5改用信息增益比来解决;CART分类树则使用基尼系数来进行特征选择。
3. 回归树原理
依然是创建一颗树,分类树是根据树上节点的判断原则,会落入到叶子节点表示的分类中,而回归问题是预测一个具体的数值,那么可以把最终落入到分类中所有数据的值的平均数,作为回归的预测值。
4. 决策树防止过拟合手段
- 决策树深度max_depth参数;
- min_samples_split参数:表示对于一个节点来说,至少要有多少个样本数据,才可以对这个节点继续拆分,其越高越不容易过拟合;
- min_samples_leaf参数:表示对于叶子节点来说,至少应该有几个样本;
- 剪枝
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











