







一、准备工作
1. 准备工作: 安装CUDA
首先确定电脑显卡匹配的cuda版本
win+r打开命令,cmd进入命令窗口,输入
nvidia-smi
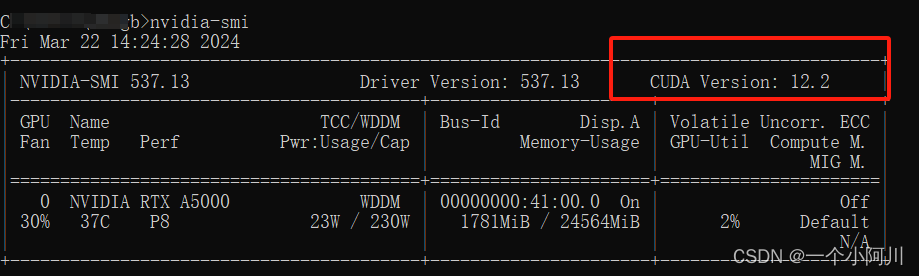
在nvidia官网(链接: nvidia官网.)下载对应的cuda版本,我用的是离线下载,防止中途网络问题导致安装不成功。我选择的是12.2.2版本

下载好之后,一路默认安装。
安装完成后,还是在命令窗口,输入
nvcc --version
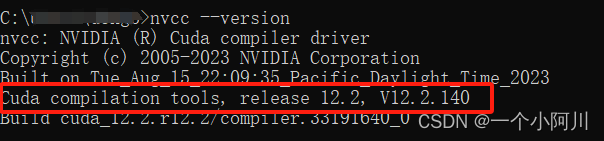
我安装了两个版本的cuda,可以查到两个cuda版本号。
在系统环境变量中查看一下是否有环境变量
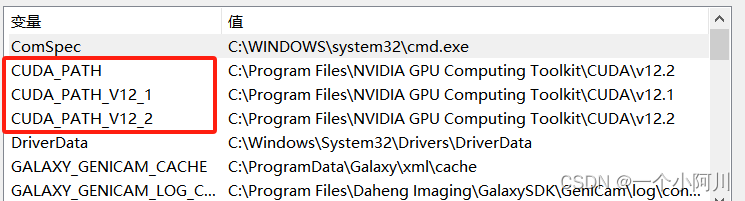

2. 准备工作:在GitHub上下载最新的项目文件
GitHub项目链接: github项目地址.
二、配置环境
1. 解压项目文件,右键在pycharm中打开(我安装的是最新的pycharm)

以下两条指令用来安装环境
pip install ultralytics # 安装
pip install -U ultralytics # 也可以用这个,安装并更新
#按照官方文档的说法这行语句会安装所有需要的环境,但是我输入这个语句之后,还是需要安装其他安装包,直接pip install 就可以了
2. 构建数据集
2.1 划分数据集
我是将10000张自己的数据集抽出一些,分60%作为训练集,20%作为验证集,%20作为测试集。
labelme打标签,但是yolo的标签格式不同,所以需要将标签格式转换,脚本代码如下:
标签文件-格式转换脚本文件.
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import copy
from lxml.etree import Element, SubElement, tostring, ElementTree
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
classes = ["AT1", "AF1","AT2", "AF2","AT3", "AF3", "CT", "CF", "BT", "BF"] # 类别 // 需要先设定好所有分选的类别
CURRENT_DIR = os.path.dirname(os.path.abspath(__file__))
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('./label_xml\%s.xml' % (image_id), encoding='UTF-8')
out_file = open('./label_txt\%s.txt' % (image_id), 'w') # 生成txt格式文件
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
# print(cls)
if cls not in classes:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " +
" ".join([str(a) for a in bb]) + '\n')
xml_path = os.path.join(CURRENT_DIR, './label_xml/')# 输出路径
# xml list
img_xmls = os.listdir(xml_path)
for img_xml in img_xmls:
# print(img_xml)
label_name = img_xml.split('.')[0]
print(label_name)
convert_annotation(label_name)
3. 新建训练配置文件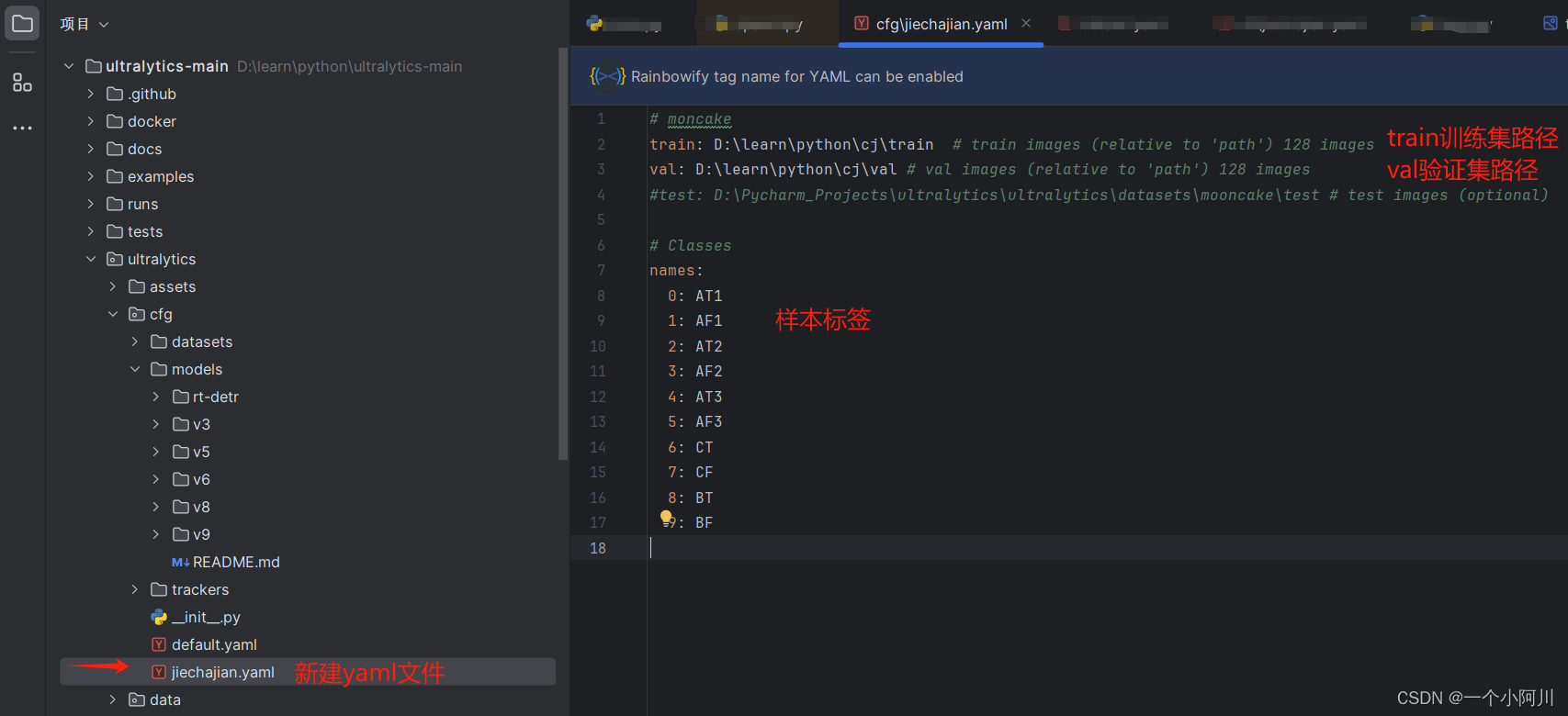
三、开始训练
1. 先新建一个训练脚本
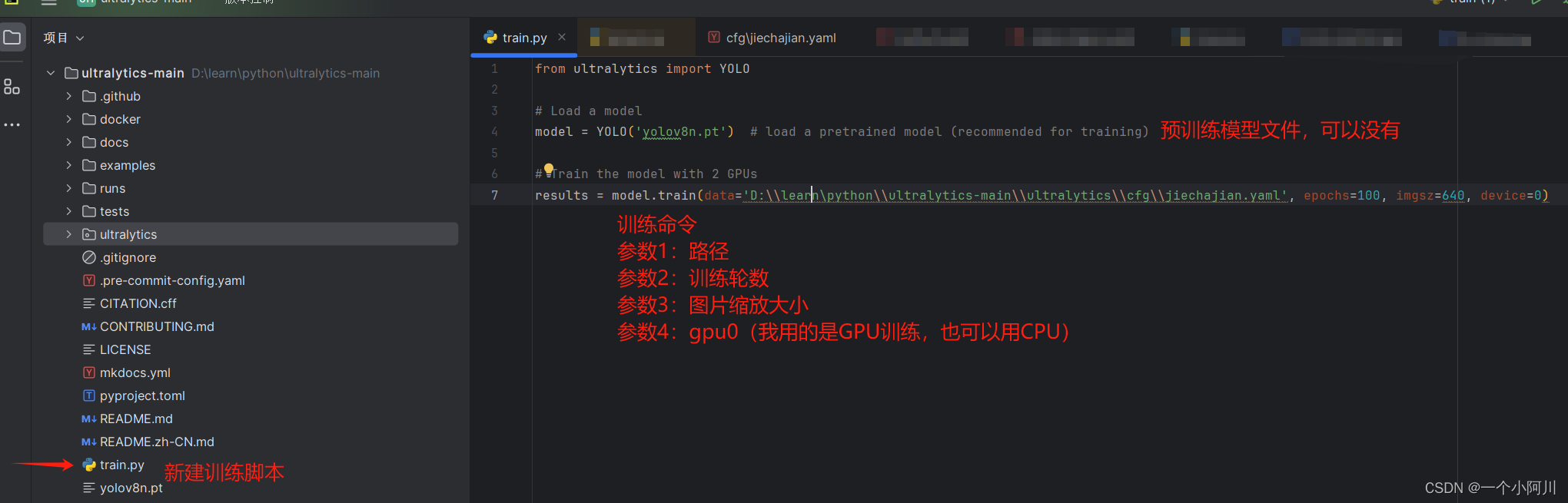
训练脚本文件.
// train codes
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
# Train the model with 2 GPUs
results = model.train(data='D:\\learn\python\\ultralytics-main\\ultralytics\\cfg\\jiechajian.yaml', epochs=100, imgsz=640, device=0)# 如果用CPU训练修改最后一个参数为:device='cpu'
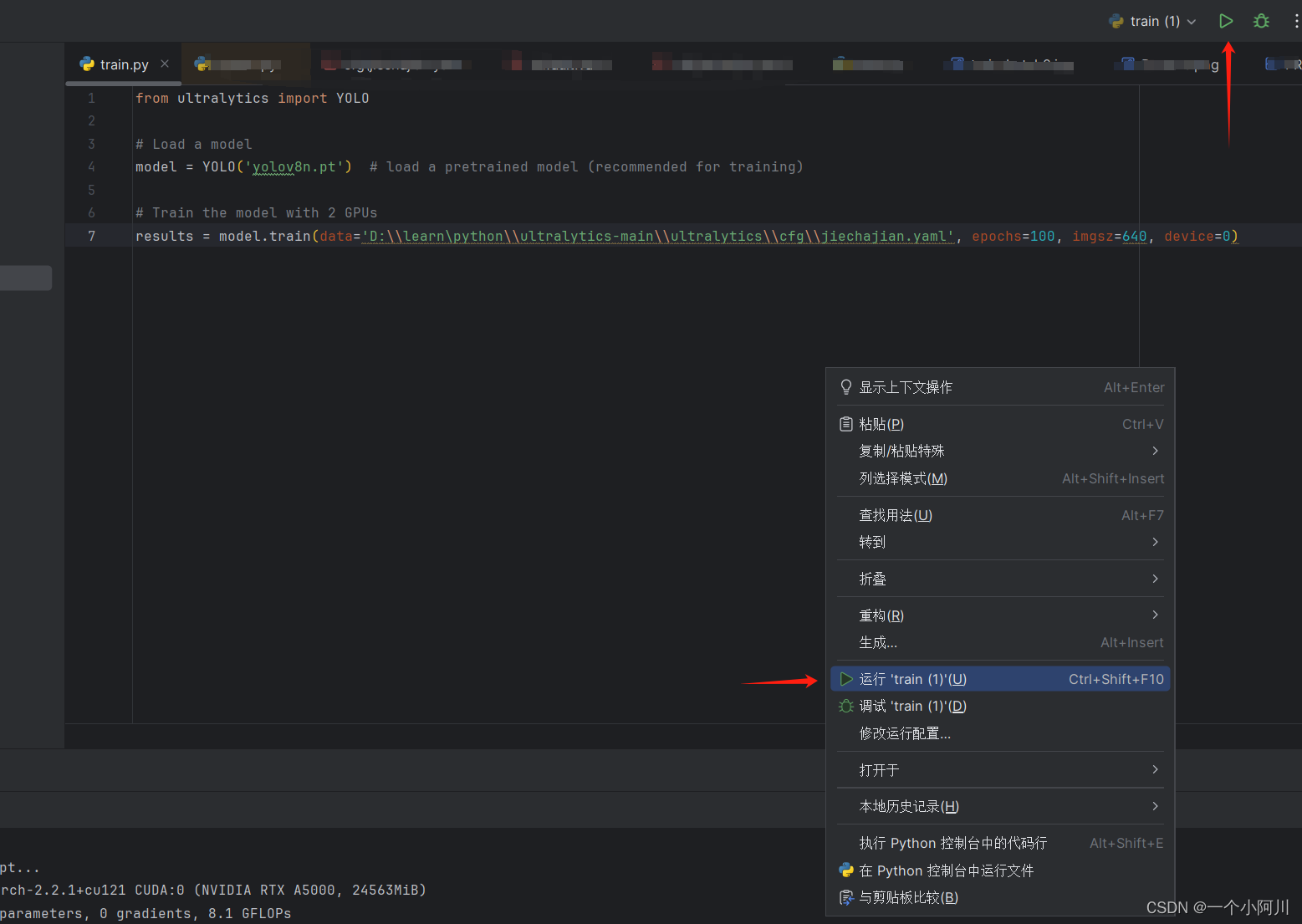
2. 开始训练,右键运行或者右上角的运行,都可以
3. 训练结果
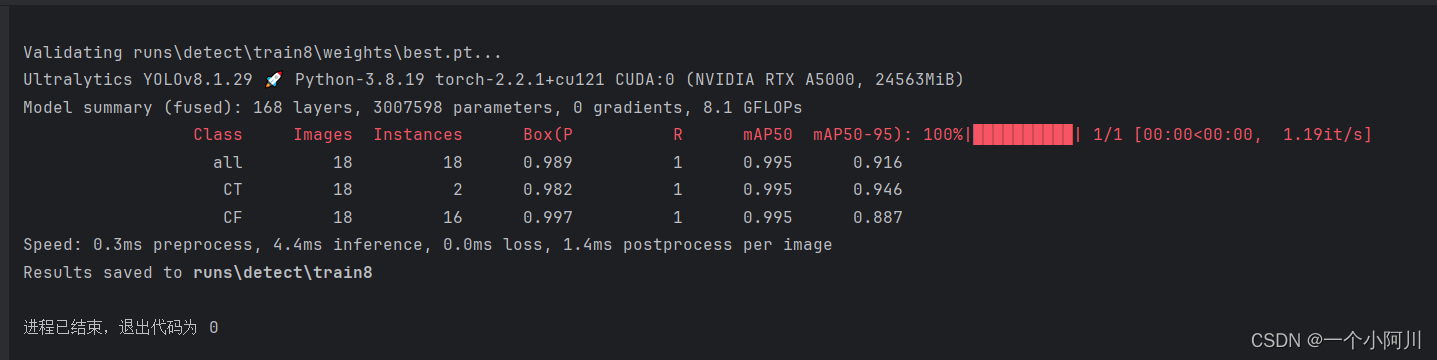
ok,训练完成!















 1962
1962











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









