









Lecture 16主要讲解了什么是对抗样本,为何会发生,它们是如何破坏机器学习系统的,如何防御它们,如何利用它们来提高机器学习性能,即使没有对抗样本。
文章目录
What are adversarial examples?

对抗样本是那种用心构造出来会被误分类的样本,大部分情况下我们会构造一个对人类观察者来说看起来和原始图片不可区分的新图片。
上图中左侧为未经处理的原图片,在ImageNet上训练的CNN能识别出这是一只熊猫。如果我们确切地计算如何对图片做一个修正,使得CNN在识别修正后的图片犯错误,我们找到一个由中间的图像给出的移动所有像素的最优方向,在人看来这很像是随机噪声,但它其实是被用心构造出来的一个网络参数的函数。如果我们把构造出来的攻击图像乘上一个非常小的系数,然后加到原始图片上得到右图,CNN错误地将右图识别为长臂猿。
有趣的是这种操作不仅仅改变了分类,CNN甚至对其错误的分类预测有了比之前左图识别为熊猫更高的置信度。

输入一张图片,利用梯度上升方法,一点点地改变图片直到CNN认为这是一架飞机。我们由上图可以看出,除了左下角猫脸的颜色可以明显地看出变化外,其他的三幅图我们都无法分辨出其与原始图像的区别。

实验证明线性模型完全没有抵御对抗样本攻击的能力。

对抗样本不止能欺骗神经网络模型。
Why do they happen?

一开始认为是过拟合的原因。如果是过拟合的话那么这张图片被误分类或多或少是运气不好的结果,并且是独一无二的,如果我们拟合一个有点不同的模型我们期待会在训练集上随机地犯别的错误。但事实并非如此,我们发现不同的模型容易在同一个对抗样本上犯错,并且会指定同样的类给他们。另外,如果我们对原始样本和对抗样本研究其区别,我们在输入空间有一个方向,我们可以对其他任何的没有噪声的样本上加一个相同的偏移向量,这种方法总能得到一个对抗样本。于是我们意识到这是一种系统性效应,而不是随机效应。
那么我们思考这会不会更像是欠拟合,他们可能是因为模型太线性了。

上图他我们可以看出误分类点由于距离分类边界较远,因此会有较高的置信度被错误分类。

但DNN真的类似于线性模型吗?DNN其实是分段线性函数。
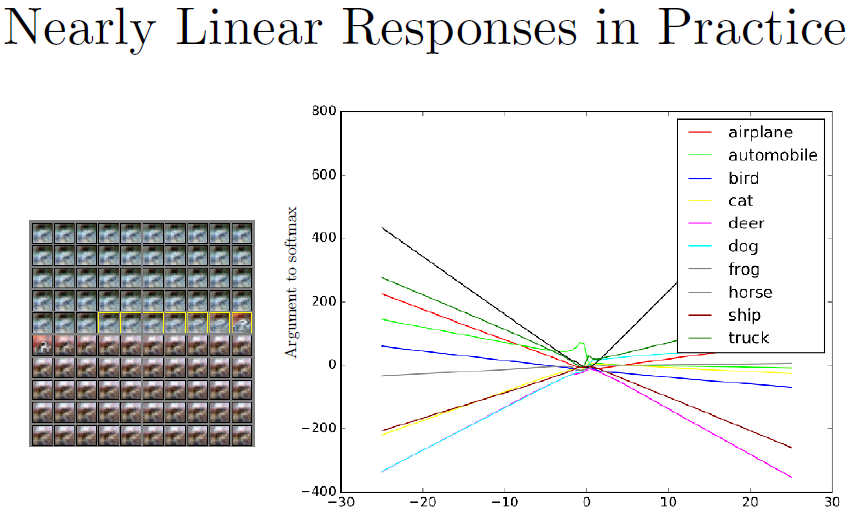
我们用一个CNN跟踪一个一维的输入空间的路径。我们选择一个没有噪声的例子(一张白色汽车在红色背景上的图片),然后选择一个方向将用于穿越空间。我们会有一个系数
ϵ
\epsilon
ϵ乘以这个方向的特征向量。当epsilon是-30时(上图右侧的最左边),我们减掉了数倍的单位方向向量。当
ϵ
=
0
\epsilon=0
ϵ=0时,如中间部分,我们可以看到数据集的原始图片。当
ϵ
=
30
\epsilon=30
ϵ=30时,我们对输出加上这个方向。上图左侧为
ϵ
\epsilon
ϵ从-30变化至30的图片,黄框部分为输入被识别为汽车的地方。
How can they be used to compromise machine learning systems?

当我们构造对抗样本时,我们要保证我们在衡量真实的误差(而不是如上图所示将3真的改成了7)。

在构造对抗样本时,我们用最大范数来限制扰动。这意味着不能像上上幅图那样抹去3的顶部。
一种快速构造对抗样本的方法是利用NN损失函数的梯度,取这个梯度的符号,这个符号其实是加强了最大范数的限制(只能加或者减)。利用这个符号,建立NN损失函数的一阶Taylor近似展开,根据Taylor展开我们想要在最大范数限制下最大化损失函数,有一个技巧叫快速梯度符号法(FGSM)。
利用FGSM来攻击没有什么特殊防御的NN时,会得到99%的攻击成功率,这意味着模型线性程度过高的假设是成立的。
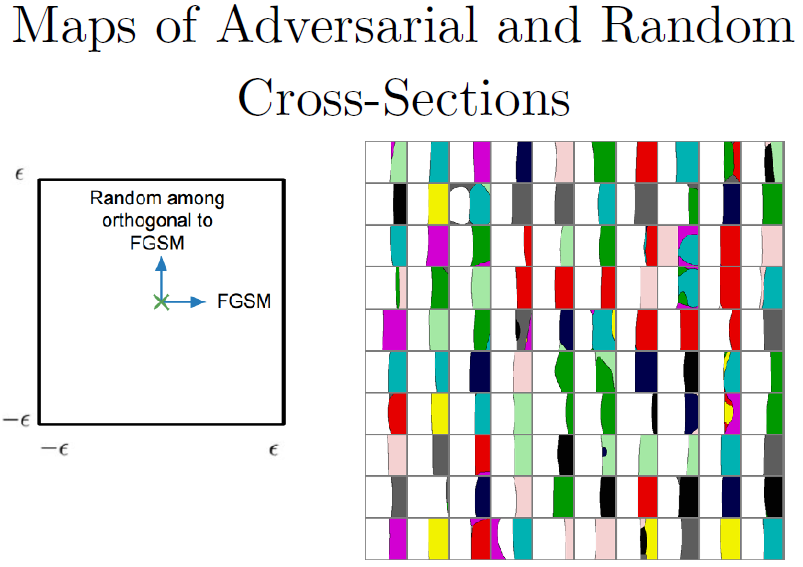
上图为神经网络决策边界的映射函数。我们想构建一个二维输入控件的交界的映射,来展示每个数据集中的点到底应该是哪个分类。上图每个小方块是一个CIFAR-10分类器的决策边界的映射,每个单元对应了不同的测试样本。左边展示了一个图例,帮忙理解每个单元格表现的是什么。单元格最中间对应的是没有经过修正的原始样本,左右代表沿FGSM攻击方向游走,上下代表垂直于FGSM的随机方向游走。白色像素表示分类正确,不同颜色表示不同类别。我们可以发现单元格左半边图片基本都分对类了,右半边都是不同的颜色,左右边界分界线近乎是线性的。这也就是说FGSM识别了一个方向,如果我们在这个方向上的内积大,我们就可以得到对抗样本。我们发现每个真实样本都靠近某个线性决策边界,当你穿过边界进入对抗子空间中,所有其他附近的点都是对抗样本。这意味着只要把方向找对,你都不用找到具体的空间坐标,你只要找到一个方向,一个和梯度方向能形成很大内积的方向,然后只要沿这个方向移动一点,就可以欺骗网络模型。

我们还利用左右两边重新给定坐标轴,得到一个交叉口的情况。利用FGSM,我们寻找第二个方向,能够和梯度方向形成较大的内积,我们可以把两个轴都做成对抗的,得到如上图所示的对角线方向的边界。
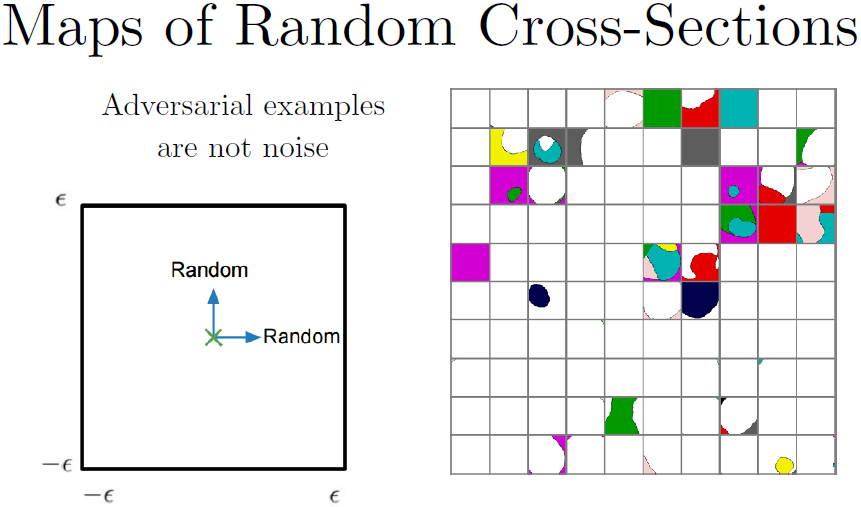
对抗样本不是噪声这一点很重要。你可以对对抗样本加很多噪声,但它依然保持对抗性。这里我们做一些随机的交叉点,两个轴都是随机地挑选方向。可以发现大部分都分类正确。一般来说,一个样本一开始就正确(错误),加噪声并不会改善这种情况。这里有一些意外,我们来看第三行第三列,噪声确实可以让模型分类错误,尤其是很大的噪声。另外最上面一行,可以看到有些单元格一开始分类错误,但噪声却能够使它成为正确分类。
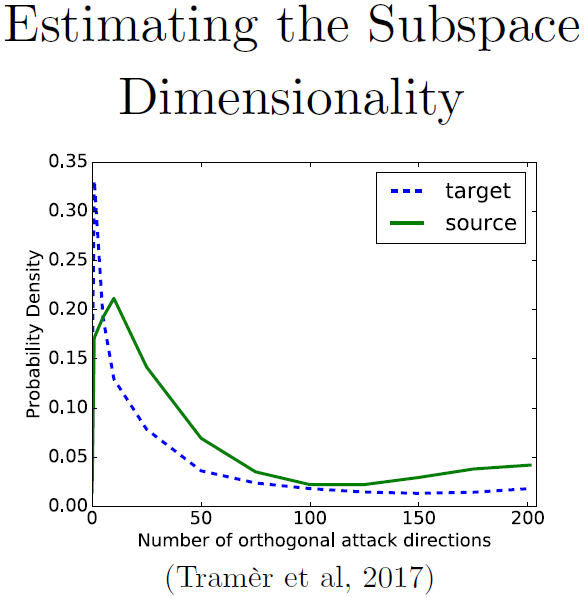
在这张图中,我们来看看二维的情况。我们发现对抗区域平均有25个维度,维数其实是在告诉你由一个随机噪声找到一个对抗样本的容易程度。对抗子空间的维数是和迁移性质息息相关的,子空间维数越大,这两个模型的子空间就越可能重叠。如果你有两个不同的模型,都有一个很大的对抗子空间,很可能把对抗样本迁移到另一个模型中去。如果对抗空间很小,除非是某种系统效应使得两个模型有恰好一样的子空间,否则迁移样本就会更难,因为子空间是随机的。

类似上图的现象,人们发现线性程度高的模式可以适应训练数据,甚至还可以泛化到测试数据上,它们掌握了和训练数据相同分布的那些例子,但如果你换一个分布去测试,如果有一个恶意的对手故意造一个用来欺骗模型的样本,那么模型就很容易被骗。
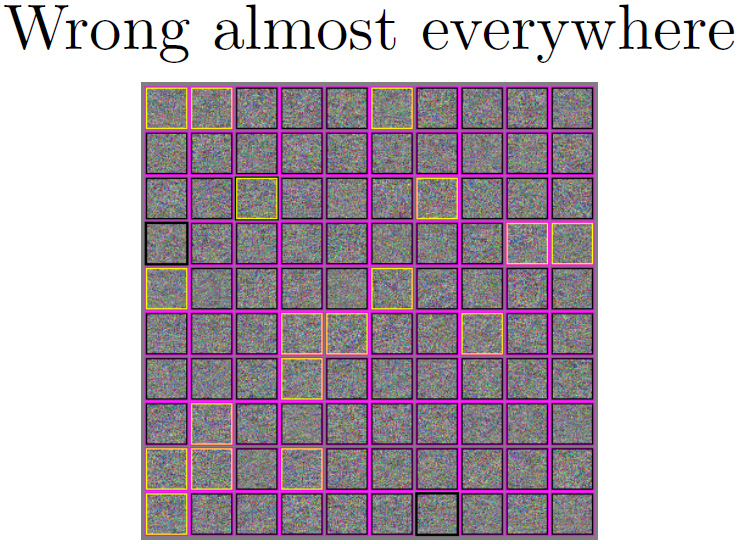
现代机器现象算法几乎处处都是错误的。如果将数据换成来自于IID的测试集样本时,我们会发现几乎所有的样本都分类错了,模型只在一个很窄的流形上表现良好,这个流形分布在我们的训练数据附近。上图中展示了几种不同的高斯噪声并运行到CIFAR-10分类器上,粉色框标出的是分类器觉得那里有点什么东西的地方,黄色框标出的地方是一个FGSM,成功地让模型以为它看上去是一架飞机。
有一些方法可以看出模型是在告诉你他觉得是存在某些东西的。一种是,如果它认为某个分类有90%的可能性,它其实是认为这个类是存在的,我们宁愿它给出了一个类似于均匀分布的噪音,这个噪音看起来一点也不像训练集,但模型却认为它一定是某一类东西(如马)。另一种方式是,我们可以把模型的最后一层换掉,比如换成对每个类的sigmoid输出,这样模型就可以告诉你给定分类的子集的分布,它可以告诉你一个图片既是马又是车。我们希望噪声能不被分成任何类,就是说每个sigmoid得到的值都应该小于0.5,0.5并不是一个很小的阈值,对这种有缺陷的输入,sigmoid阈值改为小于0.01也是合理的。但我们会发现在模型上加上足够大范数的高斯分布的噪声,这些sigmoid总是趋向于分成某个类。
我们还发现可以通过对抗样本来进行强化学习。
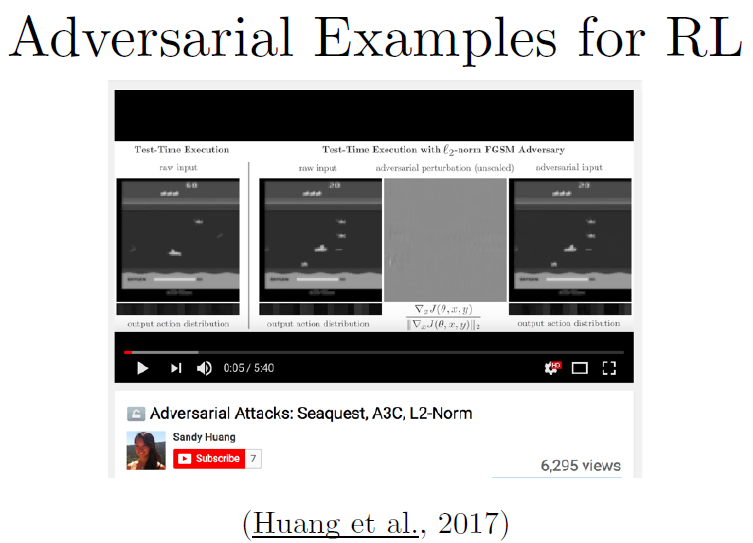
此处是一个Atari上的游戏叫Seaquest,我们拿原始的输入像素利用FGSM或其他范数包括最大范数的攻击来计算扰动,用来改变选择行为的策略。强化学习策略可以看成一个可以接收框架的分类器,但不是把输入分到某个具体的类,它可以给出一个采取行动的softmax分布。如果我们采取它,那么这个行动应该被敌人降低了该行动的可能性,我们会得到输入框架的一些扰动,继续利用这个框架就会导致和原本应该要采取的行动不一致的行动。这样的话,我们的智能体玩这个游戏就会很差很差。
What are the defenses?
我们从上述内容中了解了线性模型是很糟糕的。事实上,某些二次模型效果比较好,特别的,浅层的RBF网络可以很好地抵挡对抗扰动。

目前难题是深层RBF网络很难训练,若能成功训练来解决对抗样本问题是有可能的。因为这个模型非线性程度高,有着宽阔的平坦的区域,这样敌人很难只对模型的输入做小的改动就提升损失函数。

关于对抗样例最需要注意的是它们可以从一个数据集泛化到另一个数据集,从一个模型泛化到另一个。上图在两个不同的训练集上训练了两个不同的模型。两个训练集非常小,只是MNIST上3和7的分类。若用左边一块图的数字训练一个逻辑回归模型,我们就会得到左下角这个权重,用右边的训练得到右下角的权重。于是我们学习了两个看起来很像的权重向量,这是因为机器学习算法具有泛化性。我们希望学习到的目标函数是独立于我们训练的数据的,和我们选择的哪个训练样本是没有关系的。如果我们想把测试集泛化到训练集上,并且希望不同的训练集能得到差不多的结果。这意味着它们学到的是差不多的函数,这样它们就会对类似的对抗样本表现薄弱。

我们可以直接来衡量几种不同的机器学习技术的迁移率,不只是在不同的数据集上的迁移率。Papernot等发现逻辑回归构造的对抗样本有87.4%的概率迁移到决策树。矩阵中深色块表示有很高的迁移数量,这就表示攻击者可以很容易地利用左边的模型构造出对抗样本来攻击右边的模型。
整体流程如下:
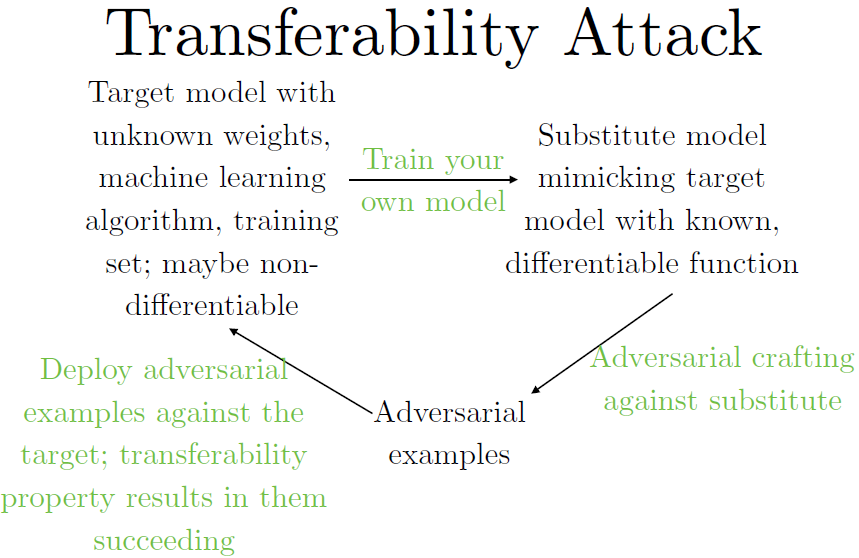
假设一个攻击者想要欺骗一个他们无法接触的模型,他们不知道训练模型的结构,不知道使用的算法,他们也不知道要攻击的模型参数。他们能做的就是训练自己的模型,有两种训练方式:一是在自己的训练集上针对你想要攻击的任务标上标签;另一种方法是你不够条件构建自己的训练集,但你可以限制访问模型,就是说你可以对模型给定输入,观察输出。那么你可以给定输入,观测输出,然后将其作为你的训练集,就算你得到的目标模型给出的输出仅仅是模型选中的类别标签。
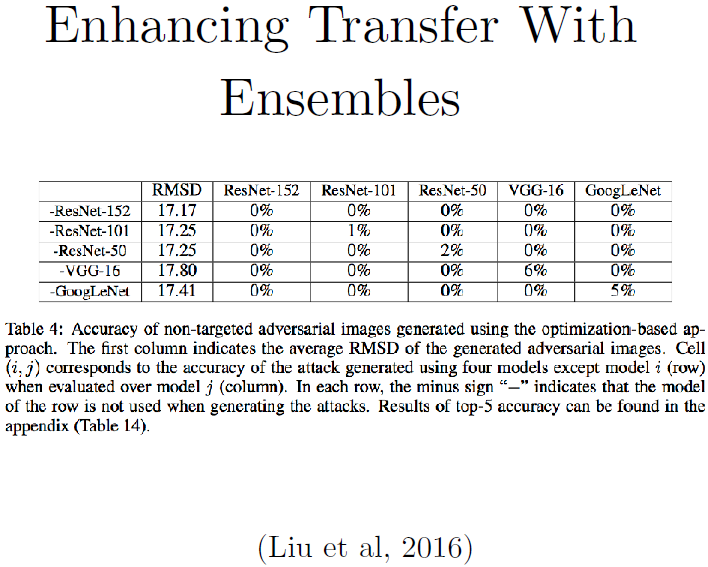
UC Berkeley的Dawn Song等发现若将几个不同的模型集成起来,再用梯度下降搜索一个对抗样本,可以欺骗集成中的每一个模型。上图工作展示出这个攻击的强大,当你故意地去导致迁移现象产生的话,它真的可以构造一个非常厉害的迁移。

Nicolas Papernot展示了他们可以利用迁移现象来欺骗由Amazon和Google搭建的分类器。

用手机识别软件来识别打印出来的对抗样本图片,事实证明目标识别系统确实被欺骗了。这个照相机的系统和生成对抗样本的模型是不一样的,这表明模型发送了迁移现象。这样的话攻击者可以有效地利用对抗样本欺骗利用物理代理系统,即使攻击者没有权限接触到这个模型的代理,没有直接接触它,而只是轻微地调整了个体接收的环境。

对每一种攻击机制,防御几乎都是失败的,不可能仅依靠传统的正则化来搞定这个问题。
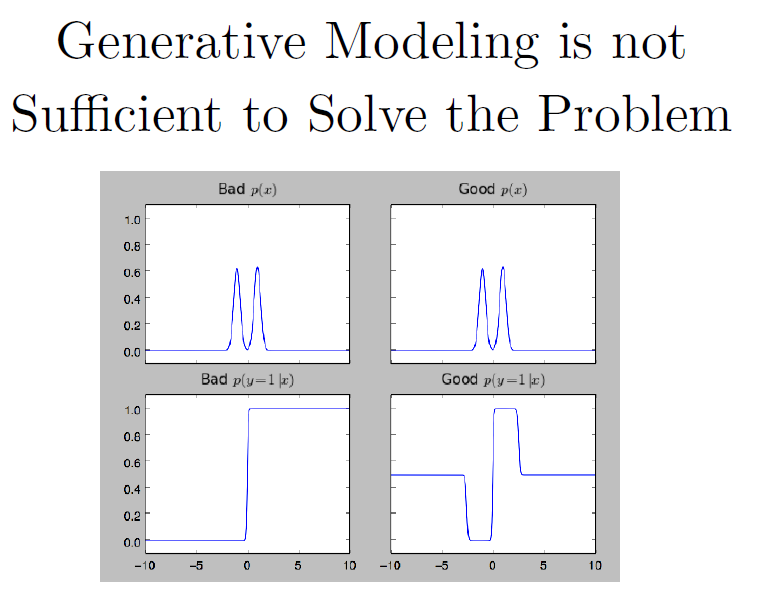
生成模型是不足以解决这个问题的。相较于弄清楚输入x的真实分布,更重要的是弄清楚标签y给定输入x的正确后验分布。上图左侧是一个由两个高斯分布混合得到的双峰分布,右侧是由两个拉普拉斯分布混合得到的。它们在输入x上的分布几乎没有区别,在训练集上的似然区别是可以忽略的,但对类别的后验分布是极其不同的。左边是一个逻辑回归分类器,在分布的尾部产生了很高的置信度,但那里都没有训练数据。
如果我们设计一个非常丰富的深度生成模型可以生成现实的ImageNet图片,还能正确地计算出后验分布,可能这种方法是有效的。但目前计算任何一个概率都是非常困难的,所以我们通常改为做一个近似器导致后验分布的线性程度非常高。

泛逼近定理告诉我们无论我们的分类函数想要有什么形状,一个足够大的神经网络总能表达出来。我们能否训练神经网络得到这个函数还是一个目前大家都无法解决的问题,但我们至少能给出一个对的形状出来。
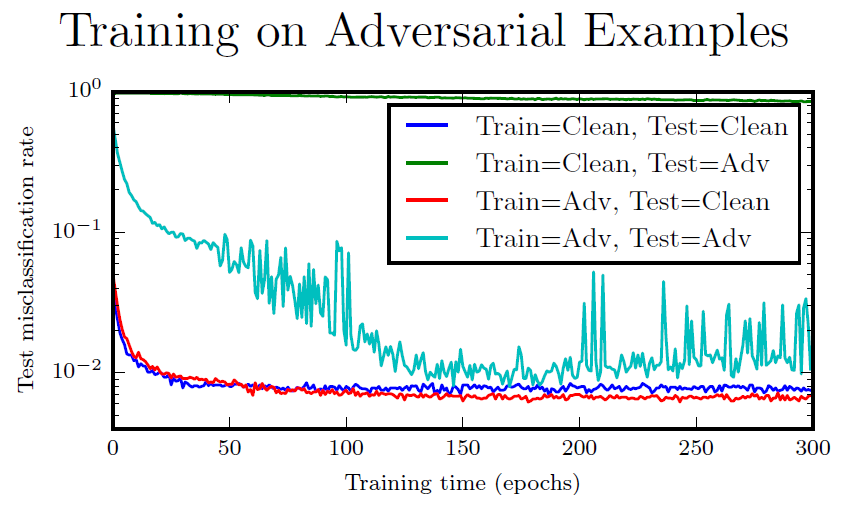
如果我们只是在对抗样本上训练呢?每个训练集上的输入x,我们希望x加上一个攻击仍然可以对应到原本的类别标签去。这有一点效果,我们可以逐渐抵抗我们训练的这种攻击。上图绿色曲线没有下降的很明显,这是测试集在对抗样本上的错误率。观察蓝色和红色曲线,我们可以发现在对抗样本上训练是一种很好的正则化方法。

除了DNN外,其他模型可能不会通过对抗训练受到很好的效果。

但其实就算有了对抗训练,我们还是很难构造模型,如果我们对不同的类别的输入进行优化。如上图所示,我们用一张CIFAR-10中的卡车为例,我们将其变为CIFAR-10类别的其他每个类。我们发现中间部分的卡车已经有一点像鸟了,鸟类是唯一一个比较贴合的类别。这就是说就算有了对抗训练,我们依然离解决问题很遥远。
How to use adversarial examples to improve machine learning, even when there is no adversary?

当我们做对抗训练,我们依靠所有样本上的标签。那万一我们没有标签呢?事实上我们的确可以在没有标签的情况下训练,可以让模型来预测第一个图片的标签,如果你已经训练了一会了,但模型还没有训练地很完美,模型可能会表示,这是一只鸟,也可能是一架飞机(都有蓝天)。

然后我们做一个对抗扰动,旨在改变决策。我们希望让网络觉得这是一辆卡车,或是类似的东西。而不是之前你觉得可能是的东西。接下去可以训练它判断出来的类别分布应该和原来一样,也就是仍然觉得这是一只鸟或一架飞机。这种方法叫做虚拟对抗训练。
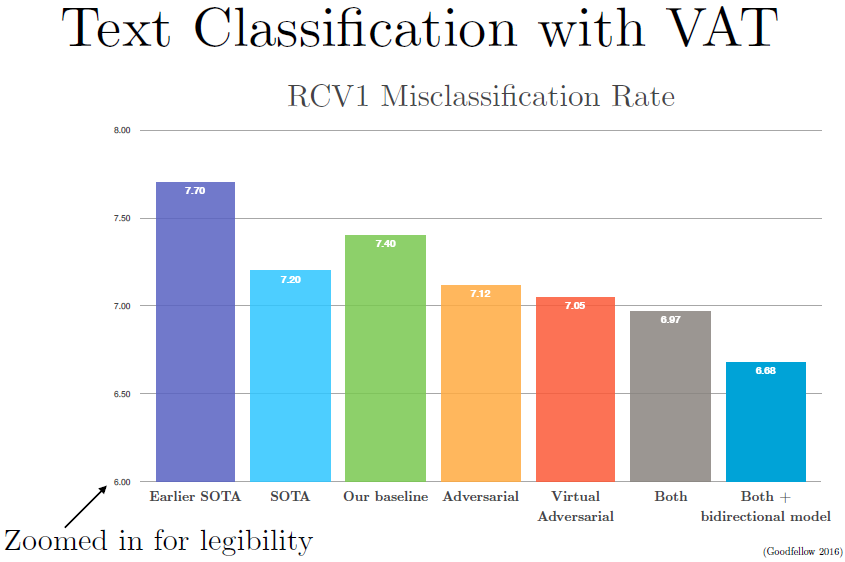
使用虚拟对抗训练我们可以实现半监督学习,即同时使用带标签数据和不带标签数据进行训练,这使得模型准确率有所提升。
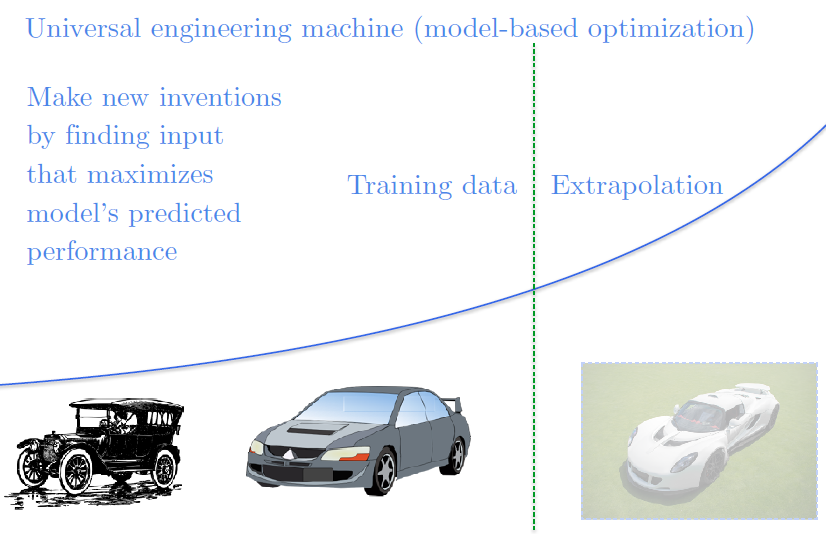
我们在使用神经网络作为优化过程时还存在很多问题,比如我们想造一辆很快很快的车,我们想象一个神经网络接受汽车的蓝图作为输入,预测这辆车能开到多快,我们可以优化神经网络的输入,找到预测出来跑的最快的车的蓝图,这样我们就可以造一辆超级快的车。但不幸的是,我们现在并没有得到一辆开的很快的车的蓝图。我们构造对抗样本使得模型认为这辆车很快,如果我们能够解决对抗样本的问题,我们就能解决基于模型的优化问题。

本博客与https://xuyunkun.com同步更新















 2122
2122











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









