







STL
C标准库
strlen() 字符串长度
strcmp() 字符串比较
strcpy() 字符串拷贝
memset() 暴力清空
memcpy() 暴力拷贝
三角函数、指数函数、浮点取整函数
qsort() C语言快排
rand() 随机数
malloc() free() C语言动态分配内存
time(0) 从1970年到现在的秒数(配合随机数)
clock() 程序启动到目前位置的毫秒数
isdigit(), isalpha(),判断字符是否为数字、大小写字母
生成随机数
//生成随机数
#include<iostream>
#include<cstdlib>
#include<ctime>
using namespace std;
int main(){
srand(time(NULL));//设置随机数种子
rand() % 100;//生成一个[0,100)的随机数
return 0;
}
动态数组(vector)
成员函数
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2LFJaH68-1633739580471)()]
建立
//vector的创建
#include <bits/stdc++.h>
using namespace std;
int main()
{
vector<int>v1;
//创建一个存int类型的动态数组,int可以改成其它类型
vector<double>v2{1,1,2,3,5,8};
//创建一个存double类型的动态数组,长度为6,1 1 2 3 5 8分别存在v[0]~v[5]
vector<long long>v3(20);
//创建一个存long long类型的动态数组,长度为20,v[0]~v[19]默认为0
vector<string>v4(20,"zzuacm");
//创建一个存string类型的动态数组,长度为20,存的都是"zzuacm"
vector<int>v5[3];
//相当于存int的二维数组,一共3行,每行的列可变
vector<vector<int> >v5{{1,2},{1},{1,2,3}};
//存int的二维数组,行和列都可变,初始状态
return 0;
}
操作
int main()
{
vector<int>v;
for(int i=1;i<=5;i++)
v.push_back(i);//向动态数组中插入1~5
cout<<v.size()<<endl;//输出数组的大小,有几个值
for(int i=0;i<5;i++)
cout<<v[i]<<" ";//输出v[0]~v[4],也就是1~5
cout<<endl;
v.clear();//将v清空,此时size为0
v.resize(10);//为v重新开辟大小为10的空间,初始为0
for(int i=0;i<v.size();i++)
cout<<v[i]<<" ";//遍历每一个元素
while(!v.empty())//当v还不空的话,去掉v的最后一个元素,等同于v.clear();
v.pop_back();
return 0;
}
删除 遍历
int main()
{
vector<int>v{0,1,2,3,4};
v.erase(v.begin()+3);//删除v[3],v变为{0,1,2,4}
v.insert(v.begin()+3,666);//在v[3]前加上666,v变成{0,1,2,666,4}
v.front()=10;//将v[0]改成10,等同于v[0]=10;
v.back()=20;//将v[4]改成20等同于v[v.size()-1]=20;
//下标遍历
for(int i=0;i<v.size();i++)
cout<<v[i]<<" ";//使用下标访问的方法遍历v
cout<<endl;
//迭代器遍历
for(vector<int>::iterator it=v.begin();it!=v.end();it++)
cout<<*it<<" ";//使用迭代器,从v.begin()到v.end()-1
for(auto i=v.begin();i!=v.end();i++)
cout<<*i<<" ";//使用迭代器,从v.begin()到v.end()-1
cout<<endl;
for(auto i:v)//使用C++11新特性循环遍历v,如果需要改变i的值,还需要在前面加上&
cout<<i<<" ";
cout<<endl;
return 0;
}
迭代器
vector<int>::iterator it=v.begin(); //很奇怪的数据类型(对应STL的指针)
auto it=v.begin();
在这⾥ it 类似于⼀个指针,指向 v 的第⼀个元素
it 等价于 &v[0]
*it 等价于 v[0]
it 也可以进⾏加减操作,例如 it + 3 指向第四个元素
it++ 后it指向的就是v的第二个元素(v[1])了
字符串
成员函数
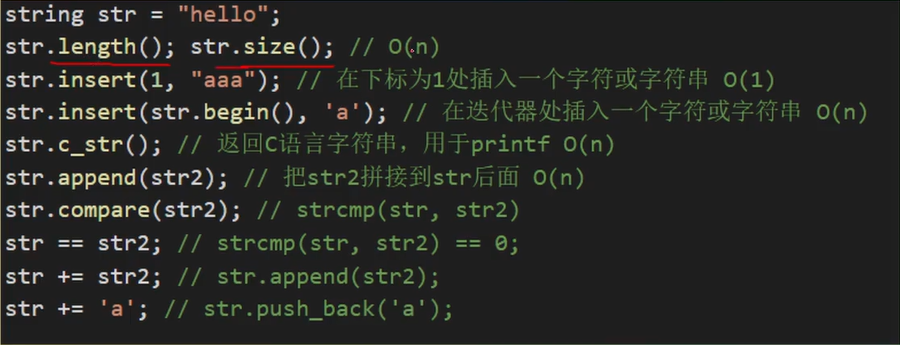
- 所有参数为字符串的地方既可以是string也可以是c字符串
- 字符串操作与vector类似,但size,length复杂度较高
- 可通过下标访问字符串元素
加速读取
#include<iostream>
//#include<string>
using namespace std;
int main()
{
string a;
char ch[100];
scanf("%s",ch);
a = string(ch);
cout<<a<<endl;
return 0;
}
栈
是一种线性结构
成员函数
头文件
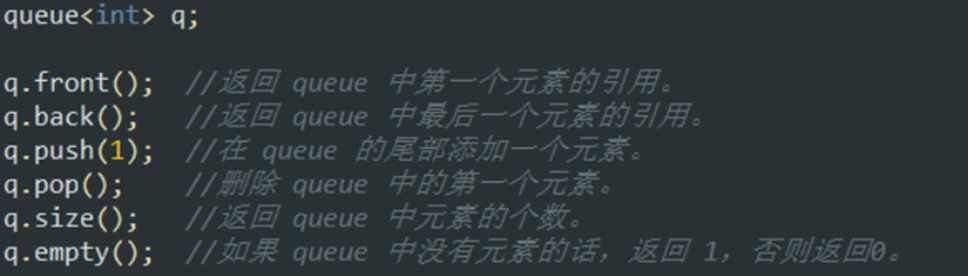
队列
成员函数

优先队列
优先队列是按照优先级出列的。每次的首元素都是优先级最大的。
优先队列的优先级是以定义的**运算符 <**来说,最大的那个元素。
q.top()获取队列首位(最大)的元素
注意运算符的重载
map
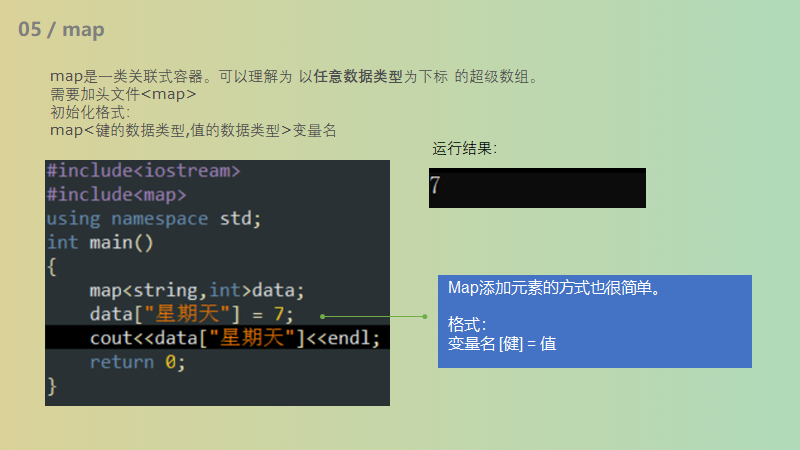
内置pair,见后
成员函数

遍历
#include<iostream>
#include<map>
using namespace std;
int main()
{
map<string,int>data;
data["星期天"] = 7;
data["星期六"] = 6;
data.insert(pair<string,int>("星期五",5));
for(map<string,int>::iterator it = data.begin();it!=data.end();it++){
cout<< it->first <<" "<< it->second <<endl;
}
for(auto i:mp)
cout<<i.first<<' '<<i.second<<endl;
return 0;
}
注意
- 有的题目在使用map时会卡时间,原因是map的访问添加都是O(nlogn)。
- 遇到这种情况,只需要使用unordered_map,unordered_map 的访问添加是O(1) 。
- 除了初始化时写成unordered_map<键类型,值类型>变量名外,其他的操作都是一样的。
- map是有序的,unordered_map是无序的
pair
简易版struct
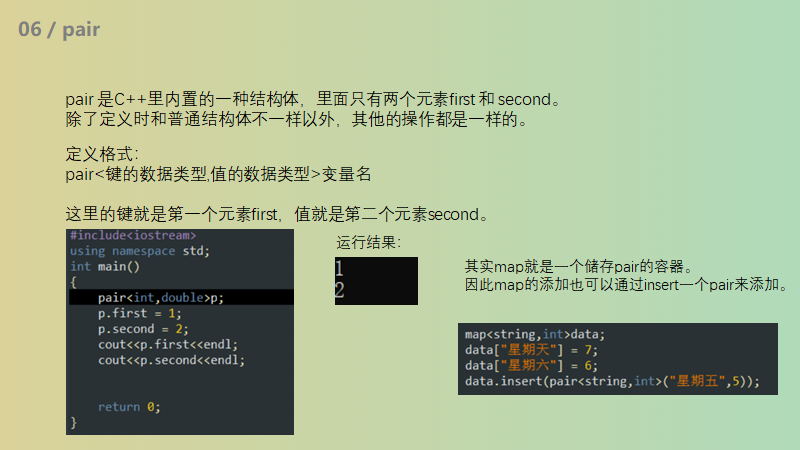
构造
#define pii pair<int, int>
//#define x first
//#define y second
using pii = pair<int, int>;
typdef pair<int, int> pii;
int main(){
pii a (1, 2);
pii b = make_pair(3, 4);
pair<string, pii> c ("name", make_pair(1, 2));
auto d = c;
return 0;
}
set
- 集合(set)是一种包含对象的容器,可以快速地(logn)查询元素是否在已知几集合中。
- set 中所有元素是有序地,且只能出现⼀次,因为 set 中元素是有序的,所以存储的元素必须已经定义 过「<」运算符(因此如果想在 set 中存放 struct 的话必须⼿动重载「<」运算符,和优先队列一样)
- 与set类似的还有
- multiset元素有序可以出现多次
- unordered_set元素无序只能出现一次
- unordered_multiset元素无序可以出现多次
成员函数

建立与遍历
//建立方法:
set<Type>s;
multiset<Type>s;
unorded_set<Type>s;
unorded_multiset<Type>s;
//如果Type无法进行比较,还需要和优先队列一样定义<运算符
//遍历方法:
for(auto i:s)cout<<i<<" ";
//和vector的类似
查找元素
set<int>s;
if(s.find(666) == s.end()){
cout << "666 was not in set";
}
else{
cout << *(s.find(666));
}
注意
int main(){
set<int> s;
auto i = s.begin();
i++, i++, i++, i++;
//i += 4; 错误
cout << *i;
return 0;
}
重载比较
set 容器模版需要3个泛型参数,如下:template<class T, class C, class A> class set;
第一个T 是元素类型,必选;
第二个C 指定元素比较方式,缺省为 Less, 即使用 < 符号比较;
第三个A 指定空间分配对象,一般使用默认类型。
因此:
(1) 如果第2个泛型参数你使用默认值的话,你的自定义元素类型需要重载 < 运算操作;
(2)如果你第2个泛型参数不使用默认值的话,则比较对象必须具有 () 操作,即:
bool operator()(const T &a, const T &b)
#include <cstdio>
#include <algorithm>
#include <set>
using namespace std;
int m,k;
struct cmp{
bool operator() (int a,int b){
if(abs(a-b)<=k){
return false;
}
else{
return a<b;
}
}
};
set<int,cmp> s;
char op[10];
int x;
int main(void){
scanf("%d%d",&m,&k);
while(m--){
scanf("%s%d",op,&x);
if(op[0]=='a'){
if(s.find(x)==s.end()){
s.insert(x);
}
}
else if(op[0]=='d'){
s.erase(x);
}
else{
if(s.find(x)!=s.end()){
puts("Yes");
}
else{
puts("No");
}
}
}
return 0;
}
algorithm
sort()
sort(first, last, compare)
- first:排序起始位置(指针或 iterator)
- last:排序终⽌位置(指针或 iterator)
- compare:⽐较⽅式,可以省略,省略时默认按升序排序,如果排序的元素没有定义比较运算(如结构体),必须有compare
- sort 排序的范围是 [first, last),时间为 O(nlogn)
- 作用:使指定容器范围内的元素有序,默认从小到大排序。
- 可以排序所有已经定义的数据类型
cmp()
对于未定义 < 小于号的 数据类型,可以写一个cmp函数来定义排序的规则。
同样的,基本数据类型也可以通过cmp来自定义排序规则。
可更改升降序
#include<iostream>
#include<cstdlib>
#include<ctime>
#include<algorithm>
using namespace std;
const int n = 10;
struct st{
int A_score;
int B_score;
};
st stu[n+5];
void putt();//输出stu
//降序
bool cmp(st a,st b){//两个关键词的排序
if(a.A_score != b.A_score) return a.A_score > b.A_score;
return a.B_score > b.B_score;
}
//升序
bool cmp(st a,st b){//两个关键词的排序
if(a.A_score != b.A_score) return a.A_score < b.A_score;
return a.B_score < b.B_score;
}
int main()
{
srand(time(NULL));
for(int i = 0;i < n;i++){
stu[i].A_score = rand()%5 + 1;
stu[i].B_score = rand()%5 + 1;
}
cout<<"排序前:"<<endl;
putt();
sort(stu+0,stu+n,cmp);
cout<<endl<<"排序后:"<<endl;
putt();
return 0;
}
void putt(){
for(int i = 0;i<n;i++){
cout<<stu[i].A_score<<" "<< stu[i].B_score<<endl;
}
}
重载<
重载结构体的排序规则
#include<iostream>
#include<cstdlib>
#include<ctime>
#include<algorithm>
using namespace std;
const int n = 10;
struct st{
int A_score;
int B_score;
bool operator < (const st b){
if(this->A_score != b.A_score) return this->A_score < b.A_score;
return this->B_score < b.B_score;
}
};
st stu[n+5];
void putt();//输出stu
int main()
{
srand(time(NULL));
for(int i = 0;i < n;i++){
stu[i].A_score = rand()%5 + 1;
stu[i].B_score = rand()%5 + 1;
}
cout<<"排序前:"<<endl;
putt();
sort(stu+0,stu+n);
cout<<endl<<"排序后:"<<endl;
putt();
return 0;
}
void putt(){
for(int i = 0;i<n;i++){
cout<<stu[i].A_score<<" "<< stu[i].B_score<<endl;
}
}
next_permutation()
作用:用于求序列[first,last)元素全排列中一个排序的下一个排序
#include<bits/stdc++.h>
using namespace std;
int main()
{
int a[3] = {0, 1, 2};
do
{
for (int i = 0; i < 3; i++)
cout<<a[i]<<' ';
cout<<endl;
}
while (next_permutation(a, a + 3));
return 0;
}
//如果有下一个排列 则返回1,否则返回0 .
//即:对于 4 3 2 1,按照字典序来说,它没有下一个排列了,返回0.
返回值:如果有下一个排列 则返回1,否则返回0。
二分函数
lower_bound(first, last, value)
- ▸ first:查找起始位置(指针或 iterator)
- ▸ last:查找终⽌位置(指针或 iterator)
- ▸ value:查找的值
- ▸ lower_bound 查找的范围是 [first, last),返回的是序列中第⼀个大于等于 value 的元素的位置,时间为 O(logn)
- ▸ [first, last)范围内的序列必须是提前排好序的,不然会错
- ▸ 如果序列内所有元素都⽐ value ⼩,则返回last
upper_bound(first, last, value)
- ▸ upper_bound 与 lower_bound 相似,唯⼀不同的地⽅在于upper_bound 查找的是序列中第⼀个⼤于 value 的元素
int main()
{
int arr[]={3,2,5,1,4};
sort(arr,arr+5);//需要先排序
cout << *lower_bound(arr,arr+5,3);//输出数组中第一个大于等于3的值
return 0;
}
unique()
去重函数(unique)
unique(first, last):
- ▸ [first, last)范围内的值必须是一开始就提前排好序的
- ▸ 移除 [first, last) 内连续重复项
- ▸ 返回值:去重之后的返回最后一个元素的下一个地址(迭代器)
#include<bits/stdc++.h>
using namespace std;
int main()
{
int arr[]={3,2,2,1,2},n;
sort(arr,arr+5);//需要先排序
n=unique(arr,arr+5)-arr;//n是去重后的元素个数
return 0;
}
reverse()
可反转容器等
string str="hello world , hi";
reverse(str.begin(),str.end());//str结果为 ih , dlrow olleh
vector<int> v = {5,4,3,2,1};
reverse(v.begin(),v.end());//容器v的值变为1,2,3,4,5
max()
min()
swap()
交换指针,可用于容器
取整函数
使用floor函数。floor(x)返回的是小于或等于x的最大整数。
如: floor(10.5) == 10 floor(-10.5) == -11
使用ceil函数。ceil(x)返回的是大于x的最小整数。
如: ceil(10.5) == 11 ceil(-10.5) ==-10
floor()是向负无穷大舍入,floor(-10.5) == -11;
ceil()是向正无穷大舍入,ceil(-10.5) == -10
nth_element()
当采用默认的升序排序规则(std::less)时,该函数可以从某个序列中找到第 n 小的元素 K,并将 K 移动到序列中第 n 的位置处。不仅如此,整个序列经过 nth_element() 函数处理后,所有位于 K 之前的元素都比 K 小,所有位于 K 之后的元素都比 K 大。
3 4 1 2 5
nth_element(s, s + n, s + len);
2 1 3 4 5
二分查找
在数组中的应用
在从小到大的排序数组中,
lower_bound( begin,end,num):从数组的begin位置到end-1位置二分查找第一个大于或等于num的数字,找到返回该数字的地址,不存在则返回end。通过返回的地址减去起始地址begin,得到找到数字在数组中的下标。
upper_bound( begin,end,num):从数组的begin位置到end-1位置二分查找第一个大于num的数字,找到返回该数字的地址,不存在则返回end。通过返回的地址减去起始地址begin,得到找到数字在数组中的下标。
在从大到小的排序数组中,重载lower_bound()和upper_bound()
lower_bound( begin,end,num,greater() ):从数组的begin位置到end-1位置二分查找第一个小于或等于num的数字,找到返回该数字的地址,不存在则返回end。通过返回的地址减去起始地址begin,得到找到数字在数组中的下标。
upper_bound( begin,end,num,greater() ):从数组的begin位置到end-1位置二分查找第一个小于num的数字,找到返回该数字的地址,不存在则返回end。通过返回的地址减去起始地址begin,得到找到数字在数组中的下标。
在map中的应用
lower_bound(k)寻找 k <= ? 并返回其迭代器
upper_bound(k)寻找 k < ? 并返回其迭代器
(其中 ?为那个最接近的key值)
// map::lower_bound/upper_bound
#include <iostream>
#include <map>
int main (){
std::map<char,int> mymap;
std::map<char,int>::iterator itlow,itup;
mymap['a']=20;
mymap['b']=40; //注释看看
mymap['c']=60;
mymap['d']=80;
mymap['e']=100;
itlow=mymap.lower_bound ('b'); // 寻找 'b' <= ?
itup=mymap.upper_bound ('d'); // 寻找 'c' < ?
mymap.erase(itlow,itup); // erases [itlow,itup)
// print content:
for (std::map<char,int>::iterator it=mymap.begin(); it!=mymap.end(); ++it)
std::cout << it->first << " => " << it->second << '\n';
return 0;
}
















 1248
1248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











