









目的:将一组dict字典数据转为pandas的DataFrame格式,然后用pandas实现类似sql语句中select * from xxx where condition的功能。
一、python中将dict格式数据转为DataFrame格式
转换方法有多种,看需求的DataFrame格式是什么样的。我采用的是将dict中key作为列,值作为行的方法
在我的任务中,需要将多个字典合并到一个DataFrame中,因此采用如下方法:
第一步将多个字典存入list中。
第二步由pd.DataFrame()转格式。
# 一组字典
dict1 = {'name': '张三', 'id': '0', 'value': 'aaa'}
dict11 = {'name': '张三', 'id': '0', 'value': 'aaa2'}
dict12 = {'name': '张三', 'id': '0', 'value': 'aaa3'}
dict13 = {'name': '张三', 'id': '0', 'value': 'aaa3'}
dict2 = {'name': '李四', 'id': '1', 'value': 'bbb'}
dict3 = {'name': '王五', 'id': '2', 'value': 'ccc'}
dict4 = {'name': '马六', 'id': '3', 'value': 'ddd'}
# 存入list
tmp_list = [dict1, dict11, dict12, dict13, dict2, dict3, dict4]
# 转为DataFrame
df = pd.DataFrame(tmp_list)
print(df)
result:
name id value
0 张三 0 aaa
1 张三 0 aaa2
2 张三 0 aaa3
3 张三 0 aaa3
4 李四 1 bbb
5 王五 2 ccc
6 马六 3 ddddict转DataFrame参考:Python 将字典(dict)转换为DataFrame_python字典转dataframe_pumpkin96的博客-CSDN博客
二、使用pandas内置方法实现类似sql的select查询
(1) 使用pandas进行select操作:在SQL中,如果我们要从df中选取前三行的name和value列数据,SQL的语法为:
select name, value from df limit 3使用pandas进行查询语法为:
result = df[['name', 'value']].head(3)
print(result)
result:
name value
0 张三 aaa
1 张三 aaa2
2 张三 aaa3(2) pandas进行where条件查询:在SQL中,查询name为张三的所有行,where操作语法为:
select * from df where name = '张三'pandas语法为:
result = df[df['name'] == '张三']
print(result)
name id value
0 张三 0 aaa
1 张三 0 aaa2
2 张三 0 aaa3
3 张三 0 aaa3(3) 多个条件查询时,sql中语法为and和or。
select * from df where name = '张三' and value =aaa3pandas中使用符号“&”和“|”实现。
result = df[(df['name'] == '张三')&(df['value'] == 'aaa3')]
print(result)
name id value
2 张三 0 aaa3
3 张三 0 aaa3同时使用df.value_counts()或者len()可以统计查询结果的数量。
result = df[(df['name'] == '张三')&(df['value'] == 'aaa3')].value_counts()
print(result)
name id value
张三 0 aaa3 2
dtype: int64(4) pandas中去重操作,sql中语法为distinct。
select distinct * from temp where name = '张三'此时sql搜索结果为:
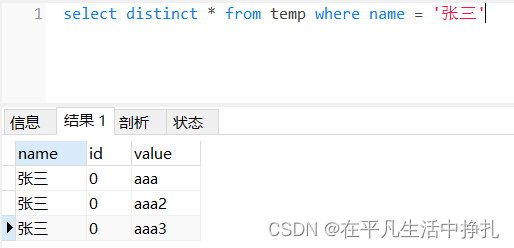
若sql语句为distinct name:
select distinct name from temp where name = '张三'则是对name进行去重,sql的去重结果保留了重复时的第一行数据。
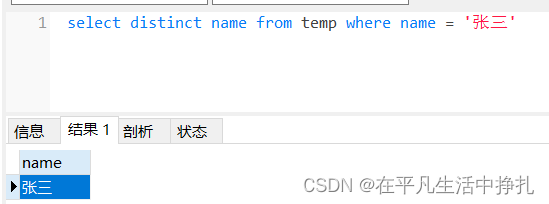
在pandas中使用df.drop_duplicates()进行去重操作。
a = df[df['name'] == '张三'] # select * from temp where name = '张三'操作
# distinct去重操作
result = a.drop_duplicates(subset=None, keep='first', inplace=False, ignore_index=False)
print(result)
name id value
0 张三 0 aaa
1 张三 0 aaa2
2 张三 0 aaa3第二条sql语句pandas可以这样写。
# select name from df where name = '张三'
a = df[['name']][df['name'] == '张三']
# distinct去重操作
result = a.drop_duplicates(subset='name', keep='first', inplace=False, ignore_index=False)
print(result)
result:
name
0 张三其中:
-
subset:设置识别重复项的列名或列名序列,对某些列来识别重复项,默认情况下为None,使用所有列,即识别完全相同的内容,若设置,则仅识别对应的列;
-
keep参数:确定要保留哪些重复项,可选值有first,last,False,默认为first。first:删除除第一次出现的重复项,即保留第一次出现的重复项last:保留最后一次出现的重复项False:删除所有重复项
-
inplace参数:表示是否返回副本,默认为False表示返回副本,设置为True表示在原数据上修改 -
ignore_index参数:指示是否重新生成行索引,默认为False表示不生成,此时会导致index乱序,设置为True表示重新按照0,1 ,2…生成index
pandas实现sql查询参考:
https://www.cnblogs.com/diruodaichang/p/11423742.html














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









