







python处理数据时,经常使用的一个套路是按照某些变量分组,然后每组里做同样的函数处理,生成一些新的数据,最后组合成一些新的数据。
函数内部通常使用dict来保存新数据,最后组合成一个Dataframe。
本文总结以上两个主要的操作。
1. dict update
首先定义一个空的字典:result = {}
然后不断调用result.update({'f' : [value]})
需要注意的是value一定要使用list的格式,否则会报错。
2. 使用append追加dict到frame中
这一步骤里,可以使用append,直接追加到一个空的dataframe中
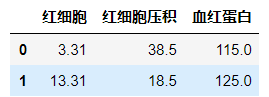
df = pd.DataFrame()
a={'红细胞': 3.31, '血红蛋白': 115, '红细胞压积': 38.5}
df = df.append(a, ignore_index=True)
a1={'血红蛋白': 125, '红细胞': 13.31, '红细胞压积': 18.5}
df = df.append(a1, ignore_index=True)
df
3. 结果















 3349
3349











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









