






目的:在自己的代码中NNI工具,进行超参数自动调优训练自己的项目,得到精度最高的一组超参数。
nni地址:
使用流程
使用nni自动调参训练自己的项目需要以下几步:
1.安装nni
pip install nni2.配置nni需要的文件
第一个文件:search_space.json
记录搜索空间的文件,包括所有需要搜索的超参的名称和分布。
{
"batch_size": {"_type":"choice", "_value": [16, 32, 64, 128]},
"hidden_size":{"_type":"choice","_value":[128, 256, 512, 1024]},
"lr":{"_type":"choice","_value":[0.0001, 0.001, 0.01, 0.1]},
"momentum":{"_type":"uniform","_value":[0, 1]}
}比如搜索空间里batch_size有四个值可供选择,lr有四个值,这几项参数按照一定方法组合成为一组超参数进行训练实验。
自己使用时可以增加自己的超参数进行实验。
那么,超参数组合方法有哪些呢?方法在哪里指定呢?就需要配置nni的第二个文件。
第二个文件:config.yml
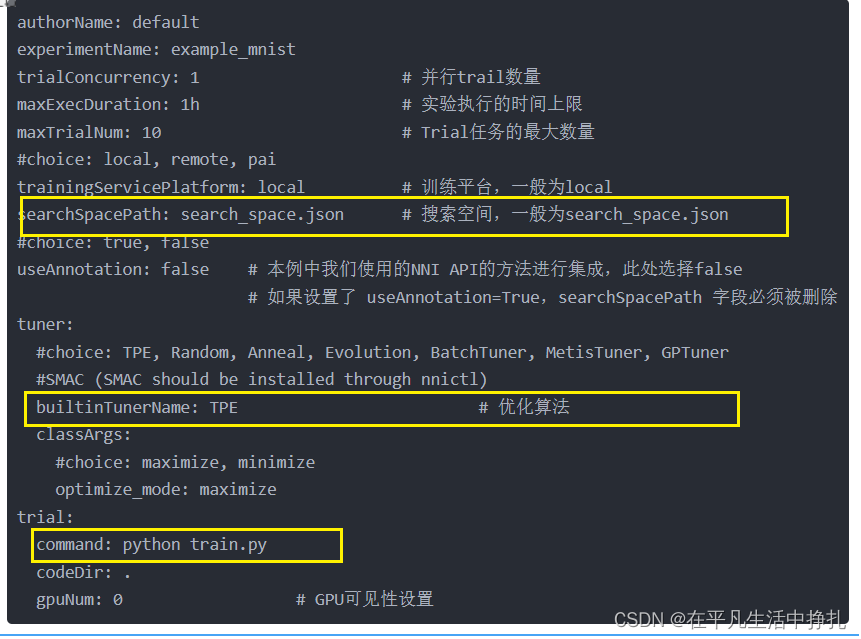
指定搜索空间和Trail文件的路径等作用的文件。除此之外还提供调整算法,最大Trial运行次数和最大持续时间等参数。
authorName: default
experimentName: example_mnist
trialConcurrency: 1 # 并行trail数量
maxExecDuration: 1h # 实验执行的时间上限
maxTrialNum: 10 # Trial任务的最大数量
#choice: local, remote, pai
trainingServicePlatform: local # 训练平台,一般为local
searchSpacePath: search_space.json # 搜索空间,一般为search_space.json
#choice: true, false
useAnnotation: false # 本例中我们使用的NNI API的方法进行集成,此处选择false
# 如果设置了 useAnnotation=True,searchSpacePath 字段必须被删除
tuner:
#choice: TPE, Random, Anneal, Evolution, BatchTuner, MetisTuner, GPTuner
#SMAC (SMAC should be installed through nnictl)
builtinTunerName: TPE # 优化算法
classArgs:
#choice: maximize, minimize
optimize_mode: maximize
trial:
command: python train.py
codeDir: .
gpuNum: 0 # GPU可见性设置可以看到,文件中指定了搜索空间文件search_space.json,组合优化算法为TPE,实验要调用的自己训练的代码train.py。
3.在train.py中编写nni代码
借用另一位博主的代码介绍nni思路:
import nni
def main(args):
# 下载数据
train_loader = torch.utils.data.DataLoader(datasets.MNIST(...), batch_size=args['batch_size'], shuffle=True)
test_loader = torch.tuils.data.DataLoader(datasets.MNIST(...), batch_size=1000, shuffle=True)
# 构造模型
model = Net(hidden_size=args['hidden_size'])
optimizer = optim.SGD(model.parameters(), lr=args['lr'], momentum=args['momentum'])
# 训练
for epoch in range(10):
train(args, model, device, train_loader, optimizer, epoch)
test_acc = test(args, model, device, test_loader)
print(test_acc)
nni.report_intermeidate_result(test_acc)
print('final accuracy:', test_acc)
# 报告评估指标
nni.report_final_result(test_acc)
if __name__ == '__main__':
# 设置超参数默认值
params = {'batch_size': 32, 'hidden_size': 128, 'lr': 0.001, 'momentum': 0.5}
# 获取一次Trail的超参数
params = nni.get_next_parameter()
main(params)1.import nni
2.获取Trail中的超参数,传递给训练代码。
params = nni.get_next_parameter()
3.在训练中每一个epoch报告一次nni。
nni.report_intermeidate_result(test_acc)
4.在训练结束报告nni。
nni.report_final_result(test_acc)
4.启动nni实验
终端输入以下命令启动nni实验。
nnictl create --config config.yml # 默认地址
nnictl create --config config.yml -p 8888 --debug # 指定端口nnictl是一个命令行工具,用来控制NNI Experiment,如启动、停止、继续Experiment,启动、停止 NNIBoard 等等
然后可以通过终端输出的WebUI的地址,在浏览器看到 NNI 的进度。














 557
557











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









