









上一次自己列出了几个关于神经风格迁移的论文链接后,自己也尝试去读懂这些,于是挑选了几个论文来拜读,本文挑选了四篇论文,前两篇是单模型多风格的(Multiple-Style-Per-Model Fast Neural Method),而后两篇是单模型任意风格的(Arbitrary-Style-Per-Model Fast Neural Method)。
====================
一:《Multi-style Generative Network for Real-time Transfer》
论文地址:https://arxiv.org/pdf/1703.06953.pdf
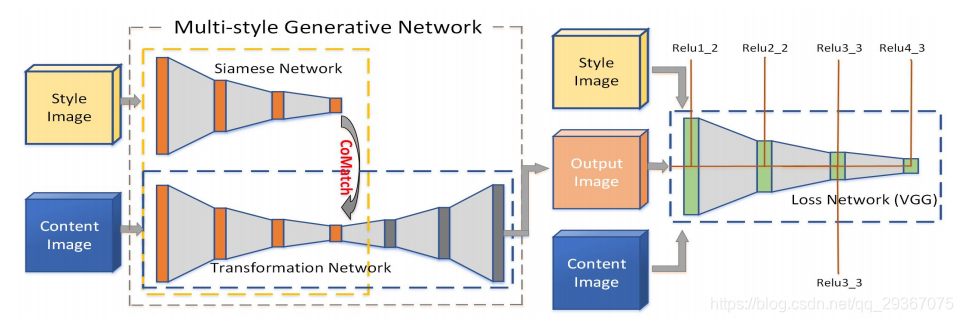
网络结构使用的是AE结构来生成图像,其中AE地E部分有一个孪生网络(参数共享),来接受风格图像地输入提取特征,做后续处理,然后将风格图像,内容图像,和重建后的内容图像预期送到一个预训练的网络比如VGG,提取三者特征后来计算损失。
因此网络需要训练的参数就是整个AE。
那么风格图像和内容图像经过了同样的孪生网络,也就是AE的E部分,风格的特征图的特征是如何迁移到内容的特征图上的呢?注意看图的那个E部分的弯曲箭头,有个CoMatch Layer的操作,就是为了将风格迁移到内容上。
先来看看内容和风格的表征,在网络中我们可以得到不同尺度的特征图,计算Gram矩阵就是表示了风格,这里复习下Gram矩阵的计算方式,注意那个θ函数是reshape操作。

将风格和内容的特征融合成一个特征y的操作叫做. . CoMatch Layer。融合了多层的信息,那么y在每一层都是不一样的。
希望新的特征y希望能具有相似的内容和相似的风格。
在输入到孪生网络中,我们可以得到内容特征图F(x_c)和风格g(F(x_s)),g就是Gram矩阵运算,怎么融合呢?优化如下的式子:
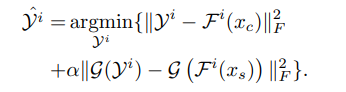
这个不是很好优化,可以通过迭代来优化,但是这样很费时间,因此作者提出了一个近似的解,如下所示

整个式子中有一个参数W,每一层都不一样,是个需要学习的参数矩阵。这样就用这个式子把风格和内容结合在了一起,最后得到新的特征y,y在每一层都不同。整个y输入到decoder得到重建的image。
损失函数:

其中G就是整个AE网络,内容图像,风格图像,重建图像一起输入到预先训练好了的VGG网络中,提取每一层的特征图。
第一项是:只要某一层,重建图像的特征图要和内容图像的特征图一致。
第二项是:一共取VGG的K层,每一层中的重建图像的特征图的Gram矩阵要和风格图像的特征图的Gram矩阵一致。
第三项是:正则化项。
λ参数就是控制风格化程度的。
来优化G,得到G的的参数,包括了前面的CoMatch Layer的W矩阵。
特点:
1:风格图像参与训练过程。
2:需要训练整个AE。
3:风格化程度可控制。
============================
二:《StyleBank: An Explicit Representation for Neural Image Style Transfer》
论文地址:https://arxiv.org/pdf/1703.09210.pdf

特点:
1:风格是需要学习出来的,但是却又将风格和内容的学习独立,风格可以单独分离出来使用,风格可以单独学习训练,学习到一个卷积的filter。换句话说就是风格需要训练,然后就将风格编码在一个卷积的filter,后面可选择性地、插拔式地使用。
2:基于同一个AE,不仅可以同时训练多个不同的风格,还可以在不改变自编码的情况下,增量学习一个新的风格,总之啊一个风格要使用必须得西安训练学习个东西出来先。
3:可以根据某个区域进行风格转换,比如一个内容图片的不同区域可以有不同的转换。
4:可以同时学习多个style,style之间隔离且独立。
5:风格化程度可控制。
网络结构:
有两种不同的数据分支,一个是autoencoder分支(encoder --> decoder),一个是style分支(encoder --> style_K --> decoder),俩分支共享encoder和decoder。
autoencoder分支就是正常的编码器,输入的内容图像需要经过编码器和解码器后还原出原始图像,练自编码使生成的图像尽可能的和输入图像接近相似;
style分支是content图像在经过encoder后的特征图结合了风格(stylebank K)的信息(结合方式就是 StyleBank会分别和输入图像经过Encoder得到的特征maps进行卷积生成风格变换后的特征),再经过Decoder生成带有风格的目标图像,如下论文所描述。

Content图像经过encoder得到的feature map和 style的结合方式就是卷积,一个style就是学习到了一个卷积的filter K_i,这个filter K_i就是代表了一个style。
损失函数:
auto-encoder branch:使用MSE损失函数,关注输出图像和原始图像的相似程度,我们之前学习知道了,这个是低频上的相似,会损失高频信息,这个是用来训练AE的。

stylizing branch:使用了perceptual loss(感知误差),包含了内容损失L_c和风格L_s,
并且包含了正则化项。

F就是某一层的特征图,G就是进行Gram matrix计算,α和β以及γ都是超参数,用于控制style的程度。
训练策略:
每一轮迭代有(T+1)- step,前T步骤是走stylizing branch,更新encoder,stylebank,decoder的参数,其中每一步骤都是选择一个style K_i。最后一步是走auto-encoder branch,更新encoder 和 decoder的参数。

在训练网络后,每个样式都编码在一个卷积滤波器组。
三:《Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization》
论文地址:https://arxiv.org/pdf/1705.06830.pdf
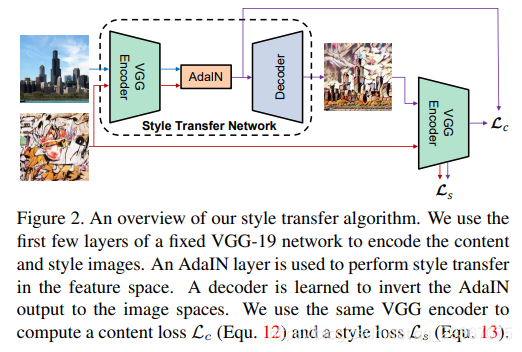
这篇文章核心提出了一个Adaptive instance normalization (AdaIN)的策略,作者认为同的style其实由feature的variance和mean决定,因此通过将Content image的feature 转换,使其与style image的feature有相同的variance和mean即可实现style transfer。然后再通过decoder得到目标图像。
自适应实例归一化,在feature 空间中,将content图的每通道输入的均值和方差归一化后的结果对齐匹配到风格图的每通道输入的均值和方差。这里的content图和style图的每通道输入的值都是feature空间的,这篇论文中采用的是预训练好的vgg网络relu4_1的feature空间结果作为输入的。

上图中的AdaIN层是对内容图进行归一化,这里是通过对齐内容图的每通道的feature map的均值和方差来匹配风格图每通道feature map的均值和方差,这里的x是content image, y是style image,将归一化后的内容图的输入进行缩放和平移。
相类似的还有其他各种归一化(BN,IN,CIN,IIN等)
网络架构算法过程:
在架构图中,两个encoder是一样的,都是预先训练好了的VGG-19的网络的前L卷积层(论文取relu_1_1,relu_2_1,relu_3_1,relu_4_1四层)。AdaIN层是不需要训练的,单纯的是内存计算。我们仅仅只需要训练一个对称的decoder即可。
1:输入是c是content image, s是style image。
2:经过encoder和AdaIN层,我们得到目标特征图t
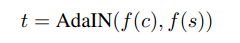
3:随机初始化并训练一个Decoder网络g,将t转换为输出的风格化的图像T。
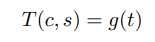
或者使用人为可控的内容风格权衡参数,这样能人为把握生成图像的风格化程度。
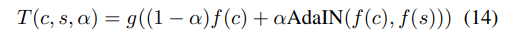
4:一旦网络训练完毕,后期使用中,仅仅保留AE的结构即可得到风格化图像。
损失函数:包含了内容损失函数和风格损失函数。
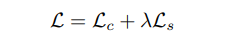
内容损失函数Lc,风格损失函数Ls,λ是权衡系数,能控制风格化的程度。
内容损失函数:
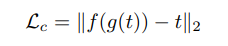
将decoder的输出T经过同样的encoder,重新得到编码,和目标特征t进行比较,期望结果是尽可能接近,这个就是对内容上的评估损失,使用的欧氏距离。
风格损失函数:

风格损失函数解析如下,将decoder的输出T和原始的风格S图像经过同样的encoder,在
每一层每一个通道的特征图,都是希望能和原始的风格图像S在方差和均值上是一致的(方差和均值是一致,那么风格也是一致)。不同的style其实由feature的variance和mean决定!!!
特点:
1:不需要对风格进行训练出一个东西来表示风格,只需要训练AE,但是风格图像会参与AE的训练,能做到对任意风格进行转换。很灵活了。
2:风格迁移到内容图像使用的方法是AdaIN(这个过程没有参数,不需要训练)。
3:网络模块训练少,仅仅剩下一个decoder的结构需要训练。
4:风格化程度可控制。
四:《Universal Style Transfer via Feature Transforms》
论文地址:https://arxiv.org/pdf/1705.08086.pdf
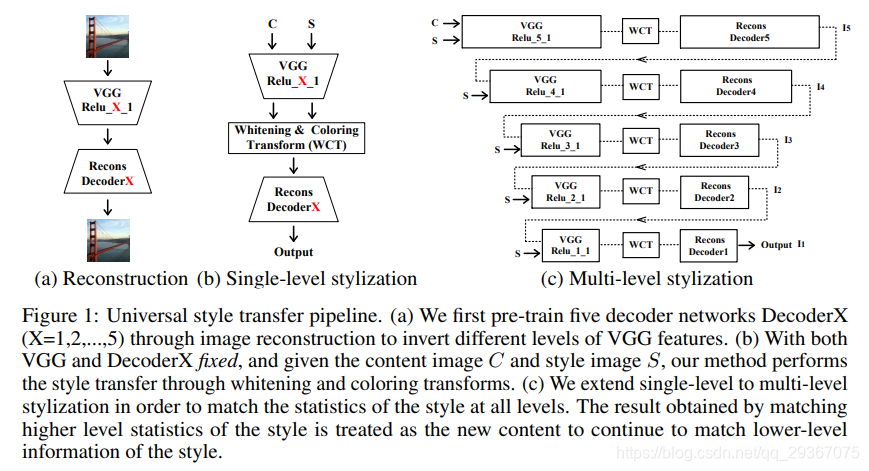
如图所示:
这个模型的基本结构还是AE结构,使用的是还是VGG-19的前L层卷积特征图。
先来看看单层的风格化过程。
首先第一步对于VGG-19前部分中的每一个Relu_x_1都训练出一个对应的decoder X。
第二步,采用WCT的非训练转换,将style迁移到内容图像的特征上得到一个新的特征。
第三部,将新的特征经过decoder可以得到目标图像
除此之外可以训练多个decoder,分别对应于VGG-19的前L层的特征图(每一层一个decoder),然后将其串联起来,组成多层的风格化过程。
损失函数和WCT过程:
文章中使用了一个未在图中画出的VGG-19,固定它,不参与训练,仅仅只是作为提取特征来使用。
1:重建decoder:
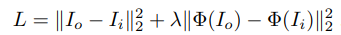
其中I_o是输出图像,I_i是输入图像,第一项是像素级别的重建和损失值。
第二项是说,输入和输出图像经过那个VGG-19,得到了好几层的特征图,看看特征图的损失,其实这里就是希望的是每一层 特征图也是一模一样的才好。
很明显第一项是低频信息,第二项是高频信息。还原度更高。这里仅仅只需要训练AE,对style不参与任何训练的过程。
2:WCT过程(Whitening and coloring transforms)
这个过程就是为了将style的feture maps通过WCT方式迁移到content的feture maps上,组成一个新的feture maps,再经过Decoder即可得到带有风格的图片。
I_c是输入的内容图像,I_s是输入的风格图像,经过VGG-19后得到的特征图进行向量化(feature的高度和宽度reshape成一个维度)后分别得到的是f_c和f_s。
首先进行Whitening transform:
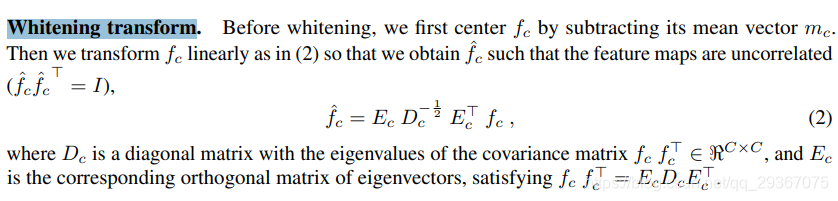
其次进行Coloring transform
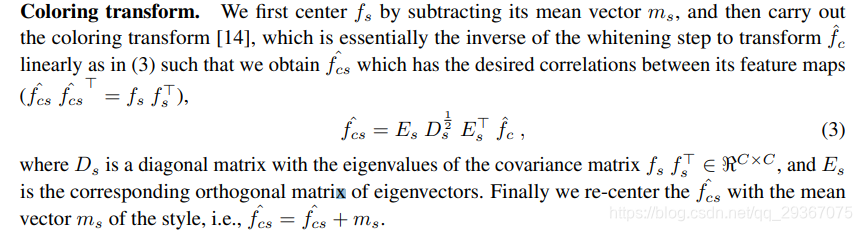
最后进行用户控制,你呢让用户决定风格化的程度。
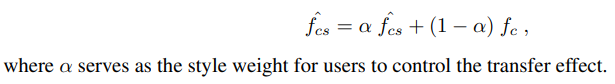
完了后,我们得到了新的带有风格的特征(原始的内容特征被进行了转换),最后decoders全部训练完了后,给任意一张风格图像均可以进行。
特点:
1:不需要训练style,style图像也不参与任何训练,使用WCT的方法转换,可以做到任意的style转换,随意给一张style的图像就可以通过WCT方式迁移。更加灵活了。
2:对AE的损失函数函数更加具有还原度。
3:仅仅只需要训练decoder。
4:风格化程度可控制。
非常感谢如下两篇博文带来的资源和学习,非常推荐如下博文来学习神经风格迁移!
图像风格化算法综述三部曲
https://zhuanlan.zhihu.com/c_185430820
Style Transfer | 风格迁移综述
https://zhuanlan.zhihu.com/p/57564626

















 1402
1402

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









