







今天学习 tesseract-ocr开源库的使用,这是个开源的能够识别多语言文字的库
下面是在Windows上安装的步骤
1:下载软件,选择最新的版本安装
https://github.com/UB-Mannheim/tesseract/wiki
The latest installers can be downloaded here:
tesseract-ocr-w32-setup-v5.0.1.20220118.exe (32 bit) and
tesseract-ocr-w64-setup-v5.0.1.20220118.exe (64 bit) resp.
2:安装时可以将语言包选上(比如不选择的话,默认的只能解析英文)
3:配置环境变量,将安装目录加载PATH环境变量中去,安装目录下面有个 tesseract.exe 。(选择的语言的训练包都在安装目录下的 tessdata 子目录)
4:检查下,打开cmd,
tesseract -v 查看版本
tesseract --list-langs 查看安装的语言
5:安装必要的库
pip install Pillow
pip3 install pytesseract
然后就可以写代码了
代码测试如下:
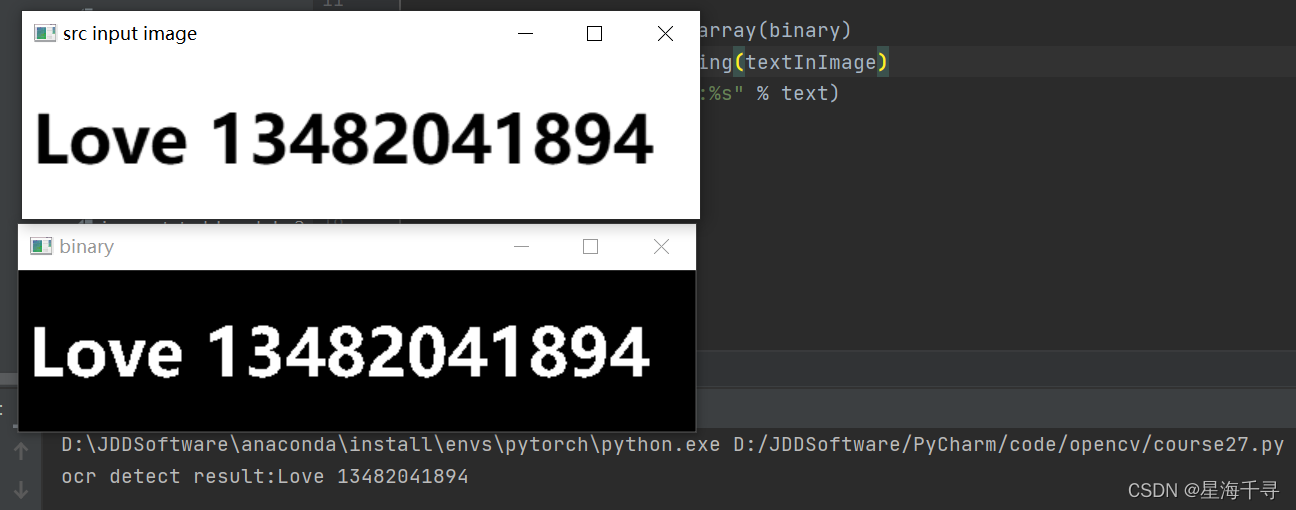
import cv2 as cv
from PIL import Image
import pytesseract as tess
src = cv.imread("images/number2.png") # 读取图片
gray = cv.cvtColor(src, cv.COLOR_BGR2GRAY)
cv.imshow("src input image", gray) # 通过名字将图像和窗口联系
ret, binary = cv.threshold(gray, 0, 255, cv.THRESH_BINARY_INV | cv.THRESH_OTSU)
cv.imshow("binary", binary)
textInImage = Image.fromarray(binary)
text = tess.image_to_string(textInImage)
print("ocr detect result:%s" % text)
cv.waitKey(0)
cv.destroyAllWindows()
效果如下:
学习自:
https://www.cnblogs.com/zhigu/p/10646928.html
https://blog.csdn.net/ytzh88/article/details/106186475/
https://blog.csdn.net/qq_33731081/article/details/103812749















 592
592











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









