







本文介绍了如何通过增大上下文窗口,利用大型语言模型(LLMs)进行多实例上下文学习(Many-Shot In-Context Learning,ICL)的方法。主要描述了现有的几实例上下文学习方法虽然在推理时能够通过少量例子学习,但当例子数量增多时,其性能并没有得到明显提升。此外,文章还解释了现有工作由于依赖人工生成的例子数量有限,无法充分利用多实例上下文学习的潜力。
核心挑战
1️⃣ 挑战1:如何在没有人工例子的情况下进行有效的多实例学习
多实例ICL在例子数量增加时表现出显著的性能提升,但受限于可用的人工生成例子数量。文章通过引入强化上下文学习(Reinforced ICL)使用模型生成的思考过程作为替代,有效解决了这一挑战。
2️⃣ 挑战2:如何克服预训练偏差,提升模型在复杂推理任务上的表现
文章通过实施无监督ICL,完全去除提示中的推理过程,只用特定领域的问题来提示模型。这种方法特别适用于复杂的推理任务,并能有效地克服预训练中的偏见。
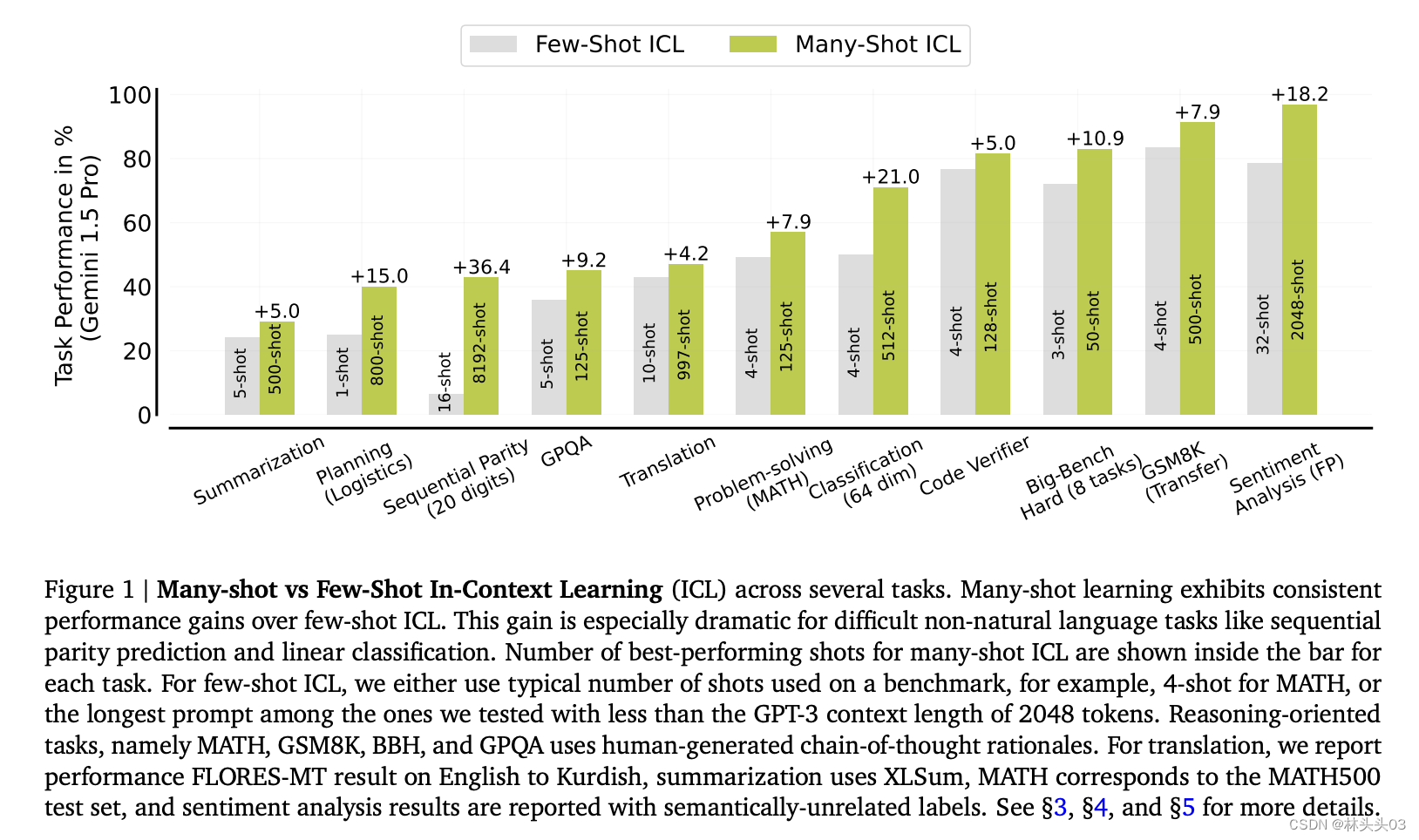
Figure 1: 展示了在多种任务上进行多实例和几实例上下文学习(ICL)的性能比较。图中显示,随着实例(shots)数量的增加,从几实例到多实例学习,性能有显著的提升,尤其是在一些非自然语言任务(如序列奇偶性预测和线性分类)上表现更为突出。图表还标出了在多实例学习中表现最佳的实例数量。
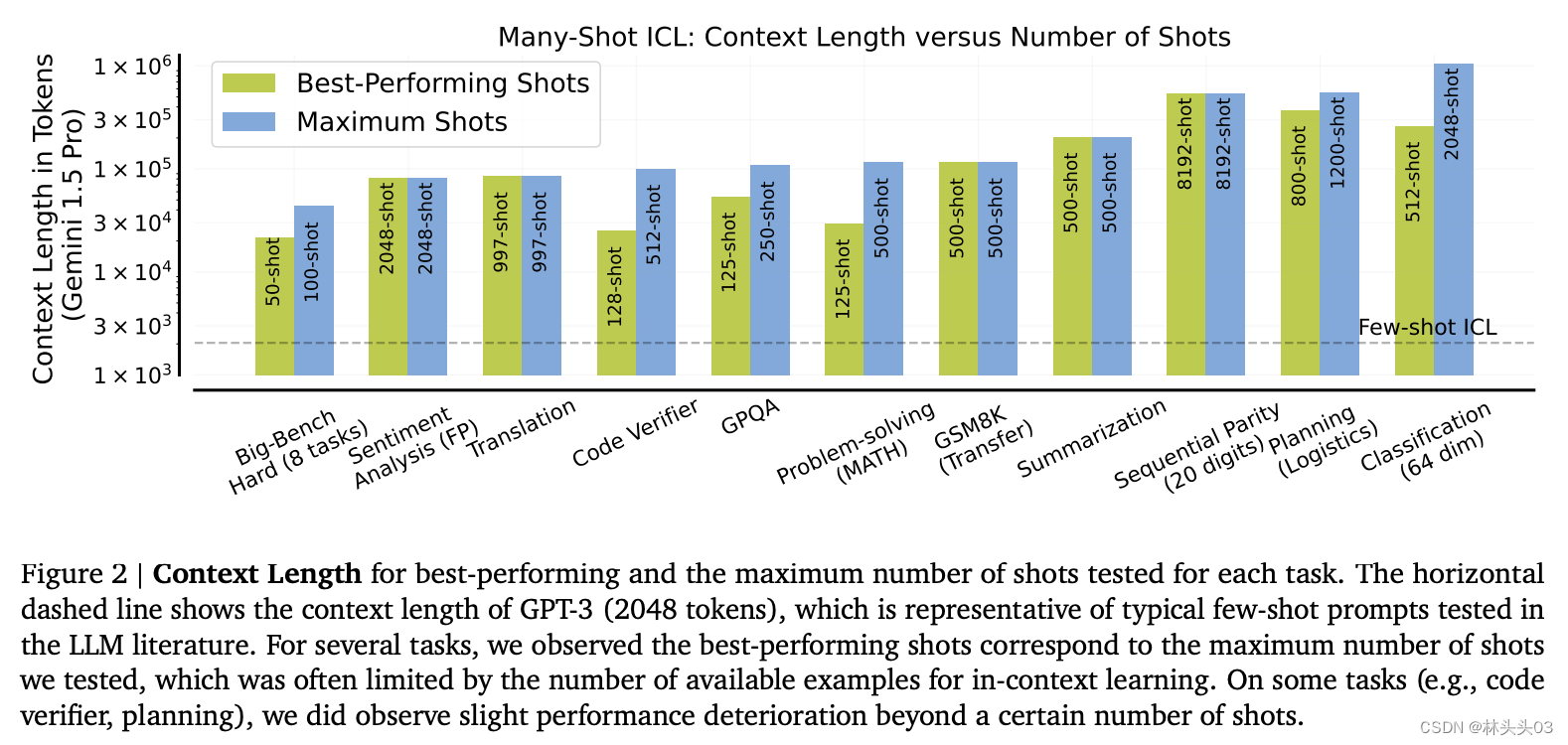
Figure 2: 描述了在多种任务上,最佳性能的实例数量与最大测试实例数量之间的关系,并展示了这些数量与上下文长度的关系。图中的水平虚线表示GPT-3的典型上下文长度(2048个
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









