







 本文介绍了一种利用双人对抗语言游戏对抗性禁忌来增强大型语言模型(LLMs)推理能力的方法。通过攻击者和防守者角色的对弈,模型通过自我对弈和增强学习不断优化策略,显著提高了推理水平和游戏胜率,展示了自我对弈训练在提高LLM性能方面的有效性。
本文介绍了一种利用双人对抗语言游戏对抗性禁忌来增强大型语言模型(LLMs)推理能力的方法。通过攻击者和防守者角色的对弈,模型通过自我对弈和增强学习不断优化策略,显著提高了推理水平和游戏胜率,展示了自我对弈训练在提高LLM性能方面的有效性。
本文介绍了一种名为“对抗性禁忌”(Adversarial Taboo)的双人对抗语言游戏,用于通过自我对弈提升大型语言模型的推理能力。

👉 具体的流程
1️⃣ 游戏设计:在这个游戏中,有两个角色:攻击者和防守者。攻击者知道一个目标词,而防守者不知道。攻击者的任务是通过对话诱使防守者说出这个目标词。与此同时,防守者的任务是从攻击者的话语中推测出目标词。
2️⃣ 角色扮演:LLMs被用作攻击者和防守者,与自己的一个副本进行对弈。通过这种方式,模型不断地从自己的对话中学习和推理。
- 自我对弈训练:通过增强学习,模型根据游戏的结果来优化其策略,以期在接下来的游戏中表现得更好。
👉 挑战与解决方法
1️⃣ 挑战1:提高LLMs的推理能力
问题:LLMs在处理需要高水平推理和复杂对话交互的任务时表现不佳。
解决方法:通过让模型在对抗性语言游戏中自我对弈,模型需要不断推理对方的意图并作出反应。例如,如果目标词是“苹果”,攻击者可能会说“通常在超市里你会买什么水果?”如果防守者回答“苹果”,攻击者就赢了游戏。
2️⃣ 挑战2:迭代提升推理能力
问题:如何确保模型的推理能力不仅能够达到一定水平,而且还能持续提升?
解决方法:通过迭代自我对弈的过程,模型在每一轮游戏后都能根据之前的经验调整其策略。这种方式类似于人类通过不断练习某项技能来逐渐掌握它。比如,如果攻击者发现直接提问使得防守者容易猜出目标词,它可能会改用更加含糊其辞的描述来增加游戏的难度。
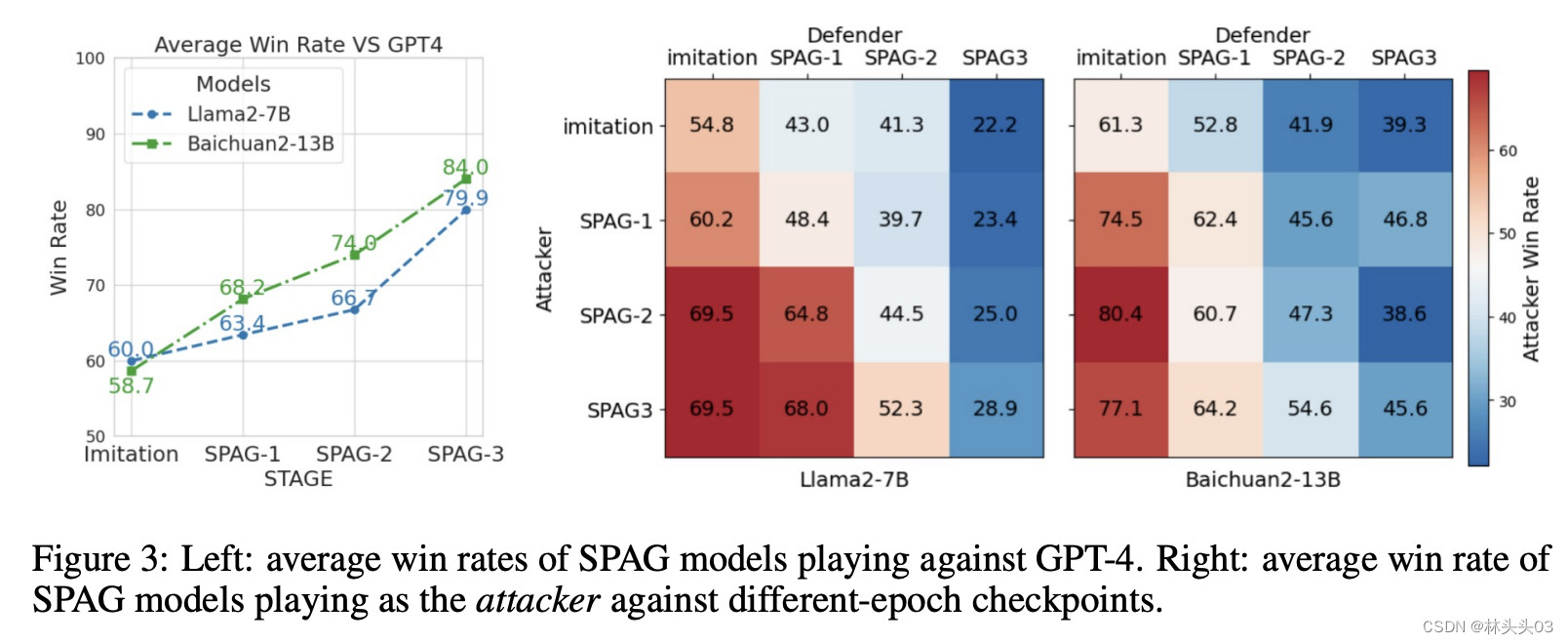
👉 实现与部署
在实验中,模型的推理能力在多轮自我对弈后显著提升。例如,通过不断学习和适应,模型能更准确地推理出对方的策略并有效地使用语言来达到自己的目的。
👉 另外,本文有几个特别有趣的发现和观点:
1️⃣ 自我对弈的持续改善:通过在对抗性语言游戏中进行自我对弈训练,大型语言模型(LLMs)的推理能力可以连续且显著地改善。这表明,通过特定的游戏设计和规则设置,可以有效地引导LLMs进行更深入的思考和推理,这在传统的单向训练方法中往往难以实现。
3️⃣ 增强学习的有效性:通过对比使用自我对弈增强学习训练的模型与仅通过监督学习训练的模型,研究表明自我对弈结合增强学习的方法在提高推理性能方面更为有效。这一点在多个推理基准测试中得到了验证,其中自我对弈训练的模型在所有测试中均表现优异。
3️⃣ 游戏胜率的提升:研究还观察到,通过自我对弈训练的模型在游戏中的胜率有统一和持续的提升。这不仅显示了模型在单次游戏中的表现提升,还反映了其长期学习和适应能力的增强。
今日 git 更新了多篇 arvix 上最新发表的论文,更详细的总结和更多的论文,
请移步 🔗github 搜索 llm-paper-daily 每日更新论文,觉得有帮助的,帮帮点个 🌟 哈。

















 644
644

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









