










主要介绍迁移学习相关任务:
1.Target Data有标签、Source Data有标签可以进行Model Fine-tuning,微调的主要方式是Layer Transfer。还可以进行Multitask Learning。
2.Target Data无标签、Source Data有标签可以进行Domain-adversarial training,希望经过一个Domain classifier和原来数字classifier进行联合,使得domain的特性消除,使得不同domain的image混在一起。也可以进行Zero-shot learning,即在Data的标签都是属性,对于从未见过的类别,我们可以识别有哪些属性
3.Target Data有标签、Source Data无标签,可以进行Self-taught learning,其实目的就是在Source Data做Auto Encoder,提取一个好的feature extractor。应用在Target Data上。
4,Target Data无标签、Source Data无标签可以进行Self-taught Clustering,也是在Source Data做Auto Encoder,提取一个好的feature extractor。应用在Target Data上。任务是做聚类。
pdf 视频
Transfer Learning
迁移学习定义要做的是存在不直接相干数据,期望帮助当前任务。
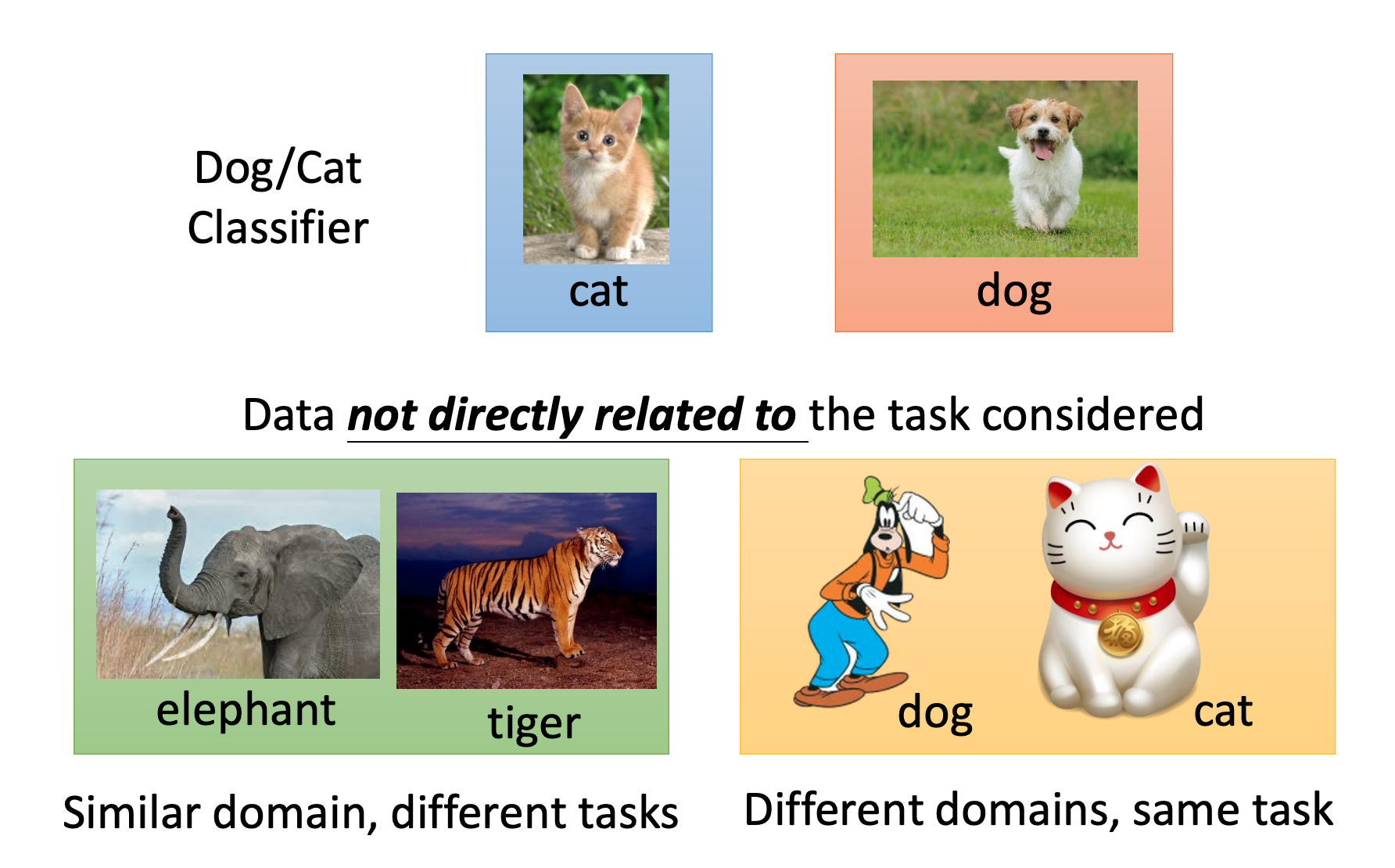
比如当前分类是cat和dog,有以下2中不直接相干数据:
- 同领域,不同任务
- 不同领域,同任务
为什么要进行迁移学习,其目的就是当前任务直接相关的数据太少了,我们期望在其他不直接相关的数据上学习,而不直接相关的数据是大量的。然后在不直接相关的数据上充分学习,在使用当前任务少量数据迁移。
Overview
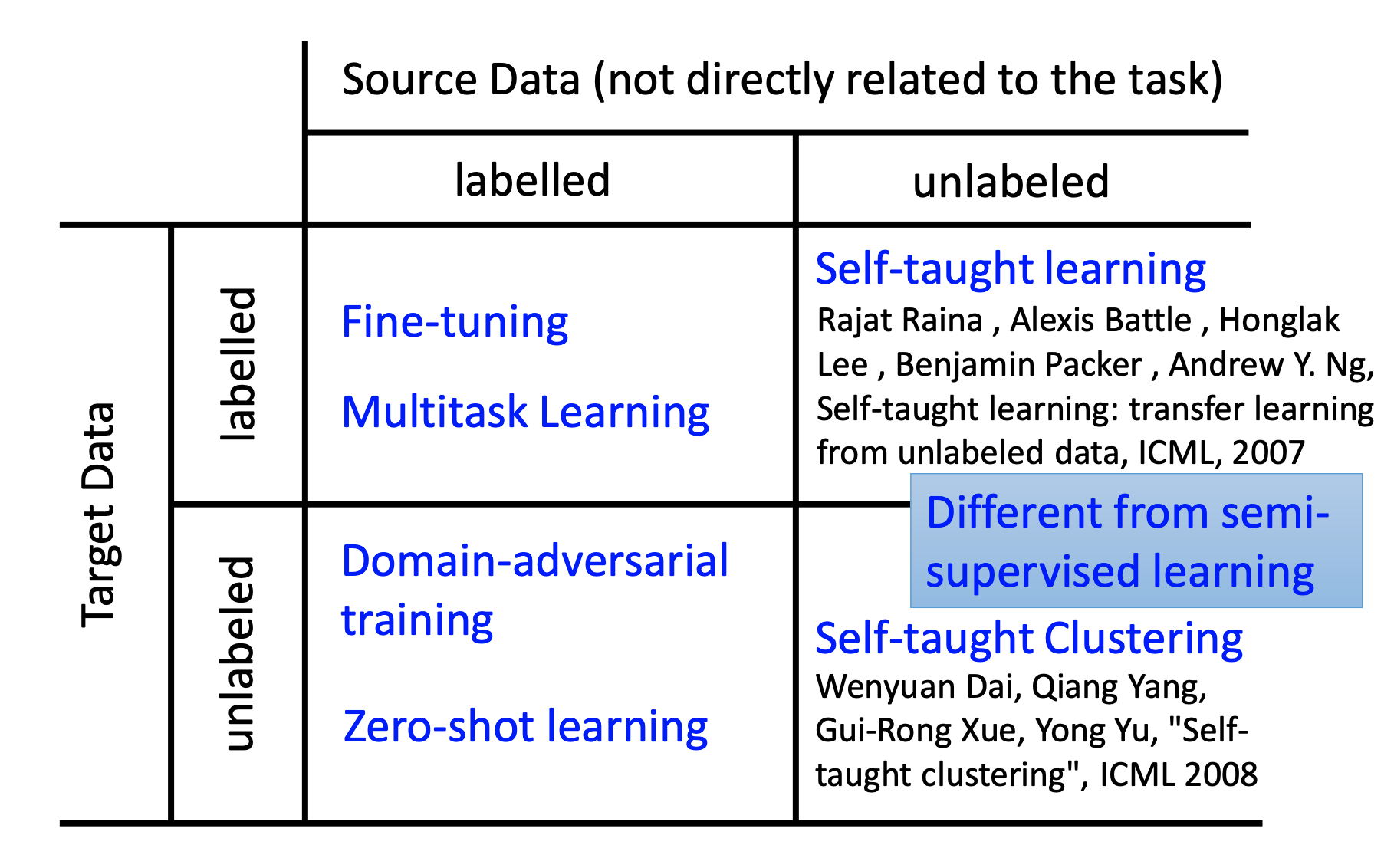
Target Data 是当前任务相关数据
Source Data 是和当前任务不直接相关数据
Model Fine-tuning
概念:Target Data有标签、Source Data有标签。只关心Target Data的performance,Fine-tuning后Source Data坏掉也没关系。

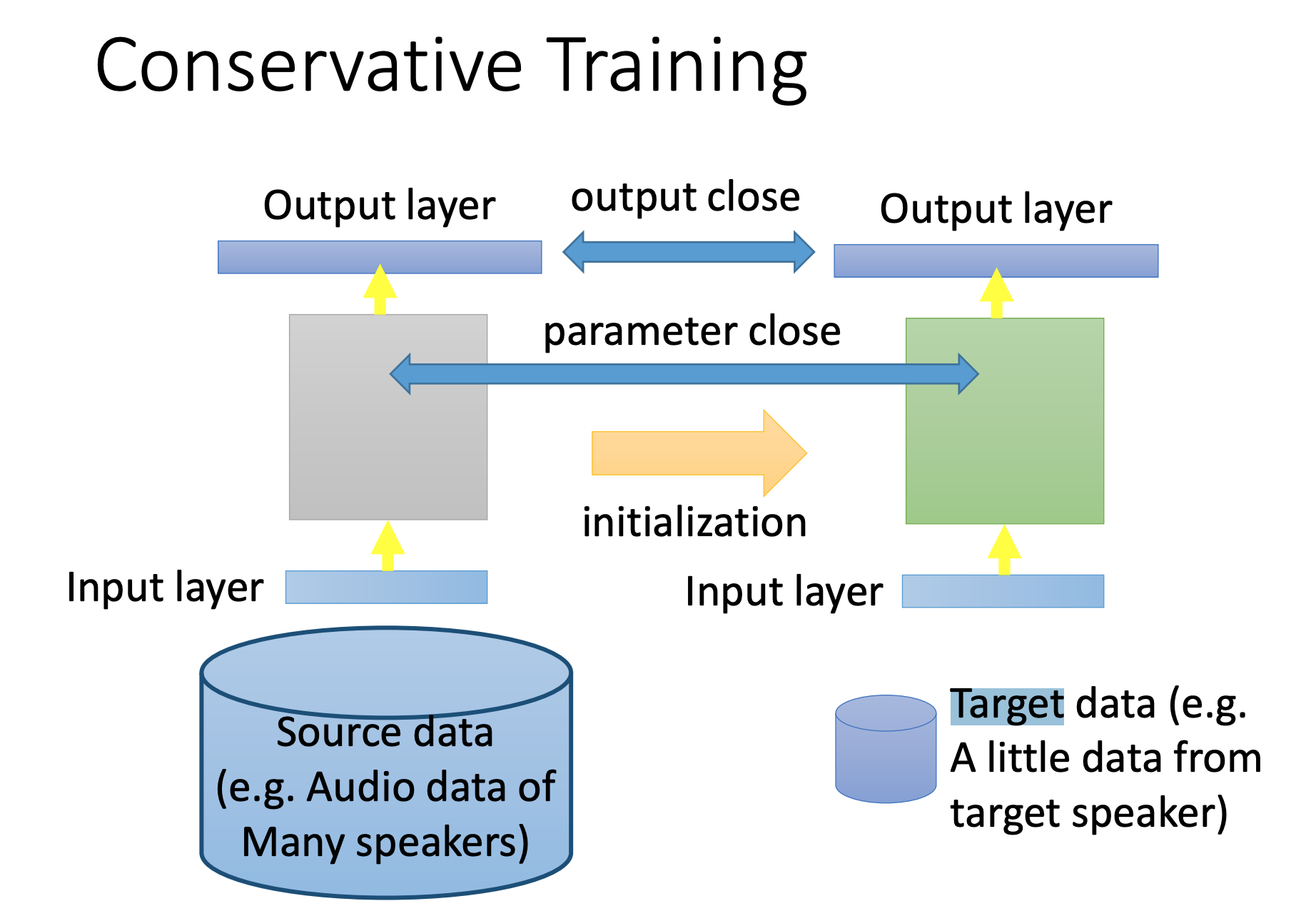
Conservative Training
微调时,由于Target data太少,直接迁移可能会过拟合,添加约束:和原来输出不能差太多。
Layer Transfer
我们fix很多层,在Target data,只调整一层。这样参数比较少,不容易过拟合。
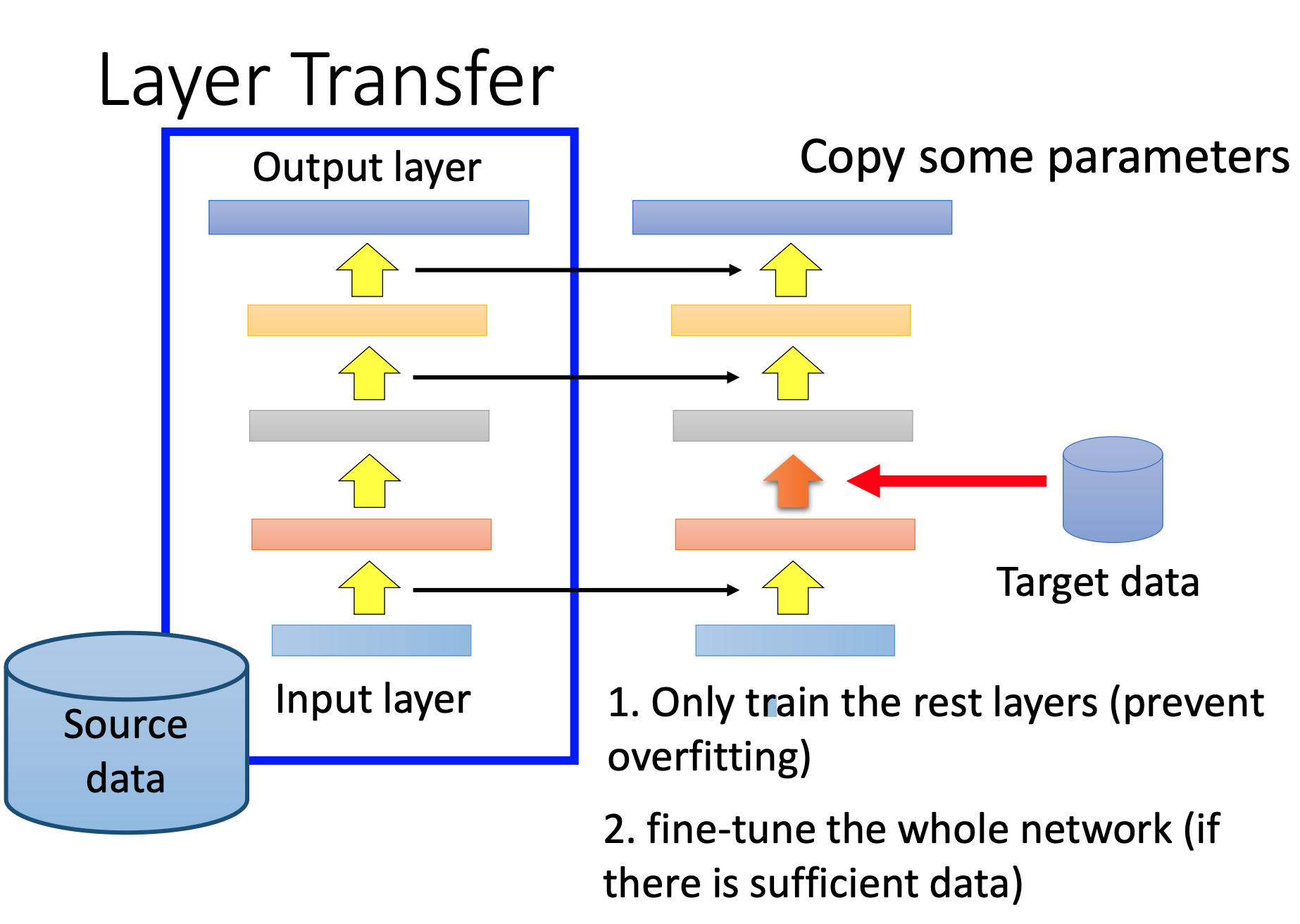
对于语音任务:一般copy后面几层,后面几层主要对语音识别。前面几层在不同的语调上提取方式可能不同,需要在当前任务中学习。不同领域,同任务。
对于图像任务:一般copy前面几层,前面几层主要提取图像特征,比如点、线、轮廓,可以共用。后面几层是图片的语义信息,需要在当前任务中学习。同领域,不同任务。
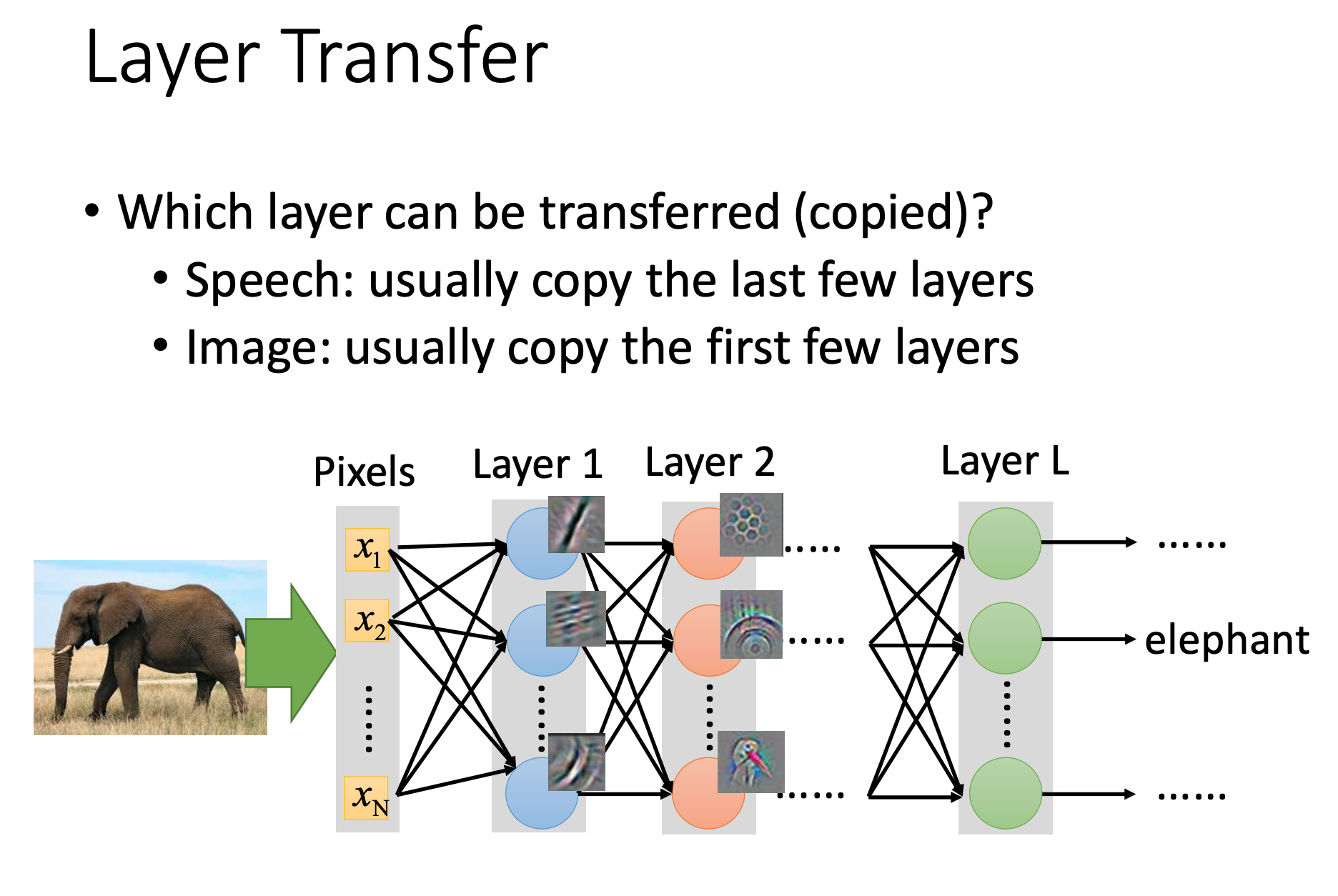
Image
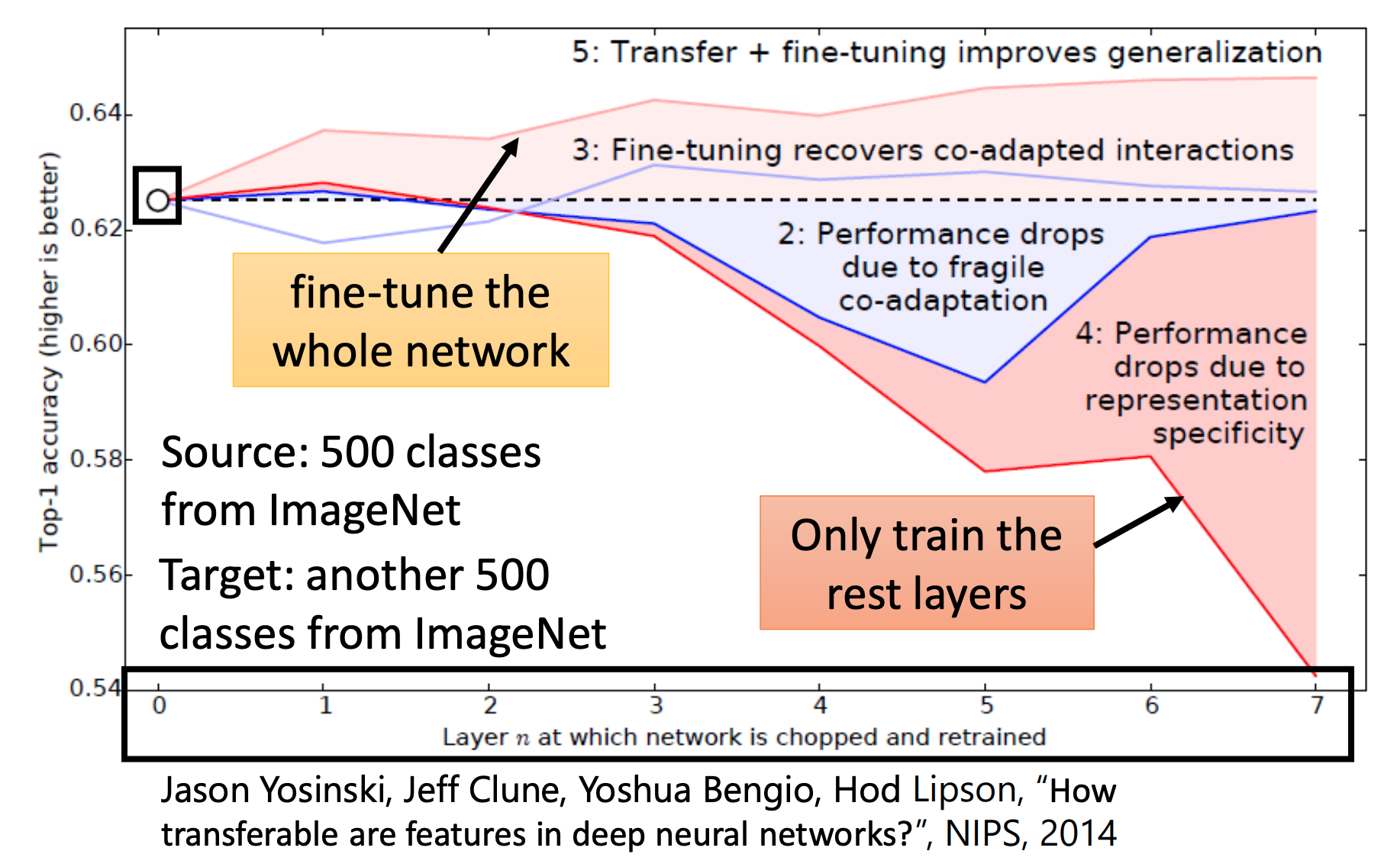
解释上面在ImageNet实验
橙色(最下面)线:copy越多层(用source data训练的),并把copy的层fix住,再用target data训练训练剩下的layer,结果是会越来越差。说明:图像上进行Layer Transfer只有前面几层可以共享。
粉色(最上面)线:copy越多层(用source data训练的),然后用target data训练整个model,结果会越来越好。
对照组
蓝色线:用target data训练一个model,然后copy越多层,并把copy的层fix住,再用target data训练训练剩下的layer,有时候是会坏掉的。说明:在训练时前面的layer和后面的layer要互相匹配。
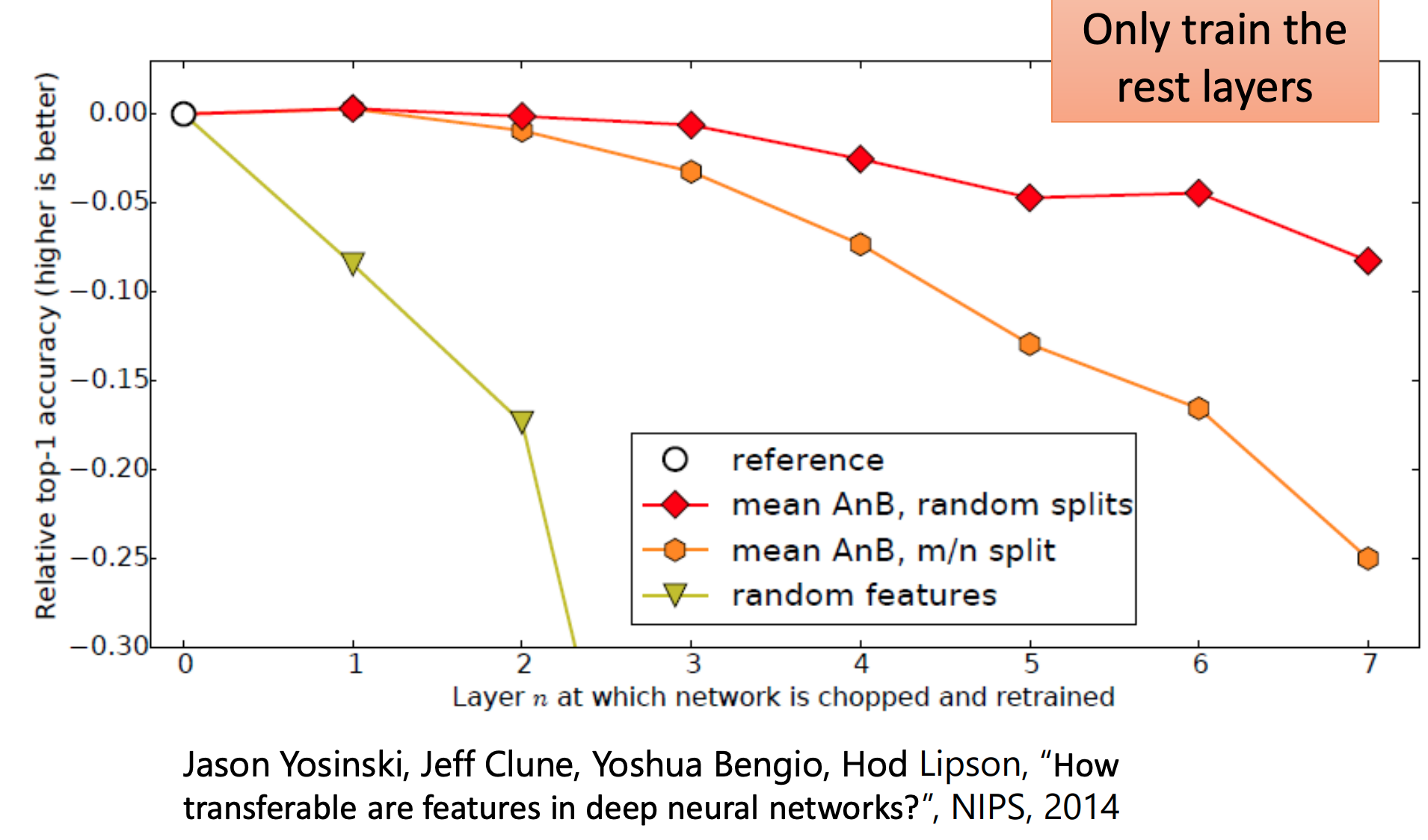
从上到下分别是
- 随机划分source和targe类别
- 认为分类,与1.先比source和targe类别更不一样
- 随机
说明:source data与target data越不一样,进行Layer Transfer效果越差。
Multitask Learning
概念:Target Data有标签、Source Data有标签。即关心Target Data的performance,也关心Source Data的performance。
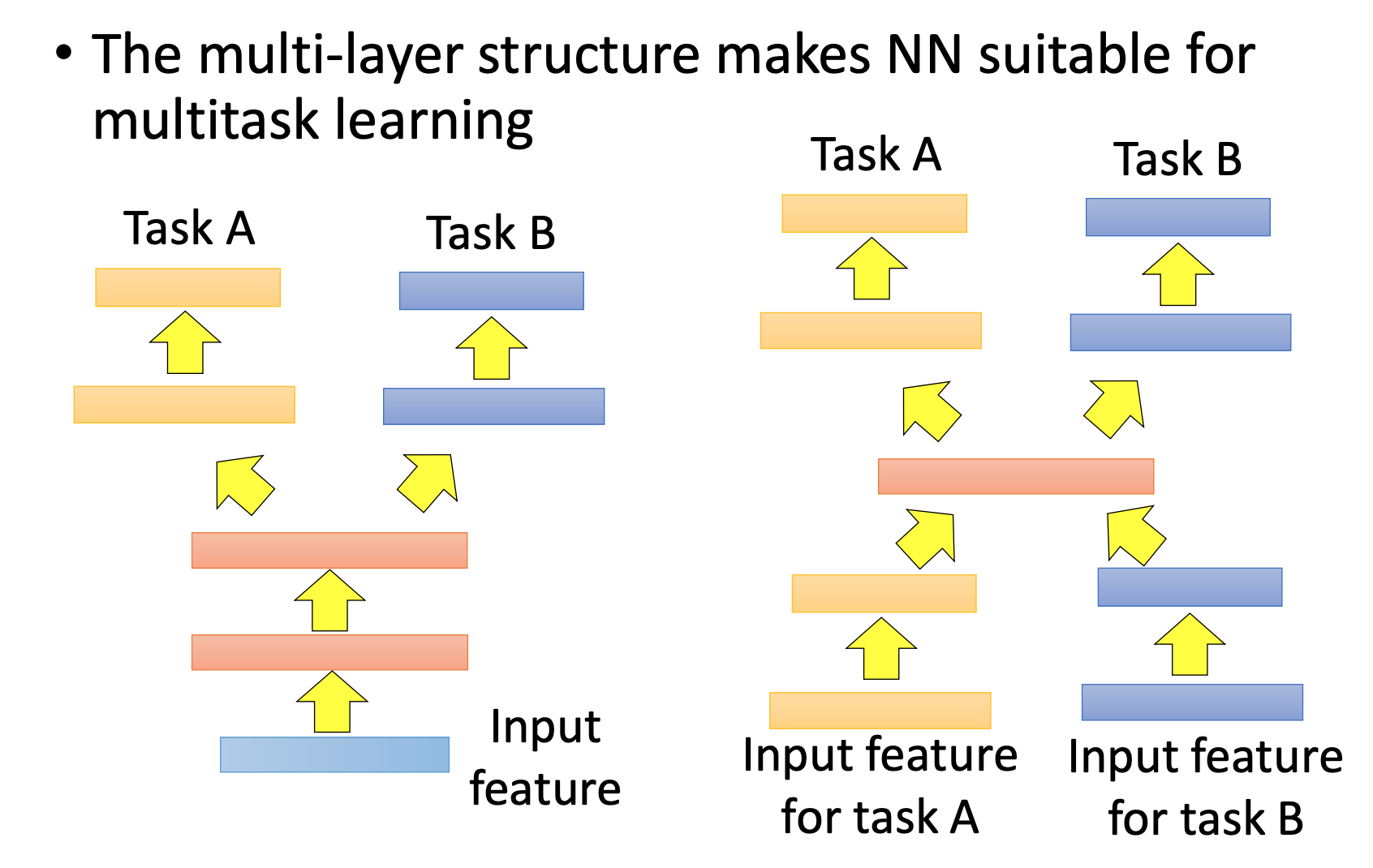
个人认为和Layer Transfer不同的是 Multitask Learning在训练时,Target Data和Source Data是混在一起的,这样才能同时兼顾两边performance。那么也就是说Task A和Task B要是独立的,比如:A区分植物和动物,B区分真实图和卡通同,这时候就需要数据有2个标签,而这也不能称为迁移学习了吧。
Domain-adversarial training
概念:Target Data无标签、Source Data有标签。
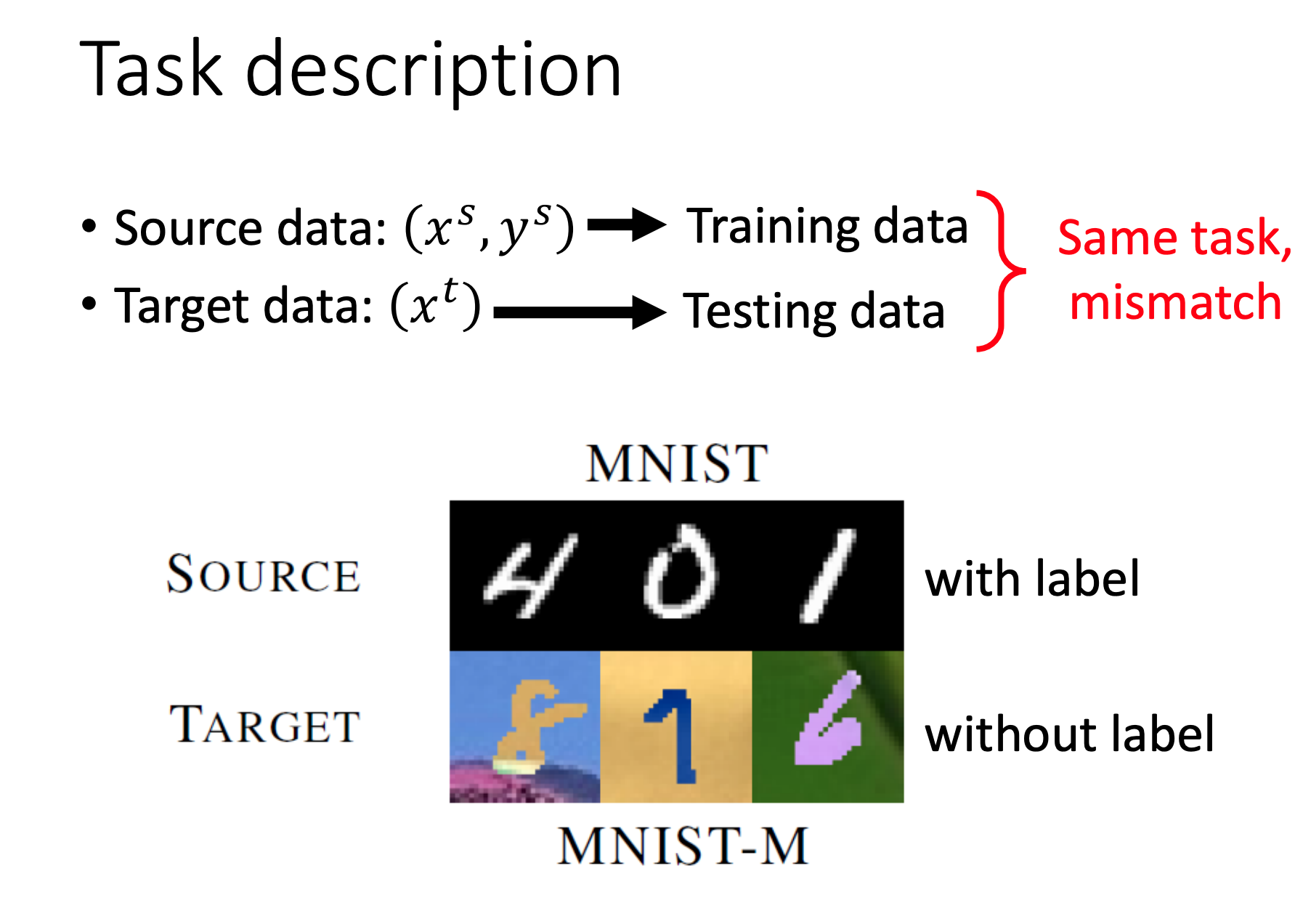
Source data和Target data非常不一样。
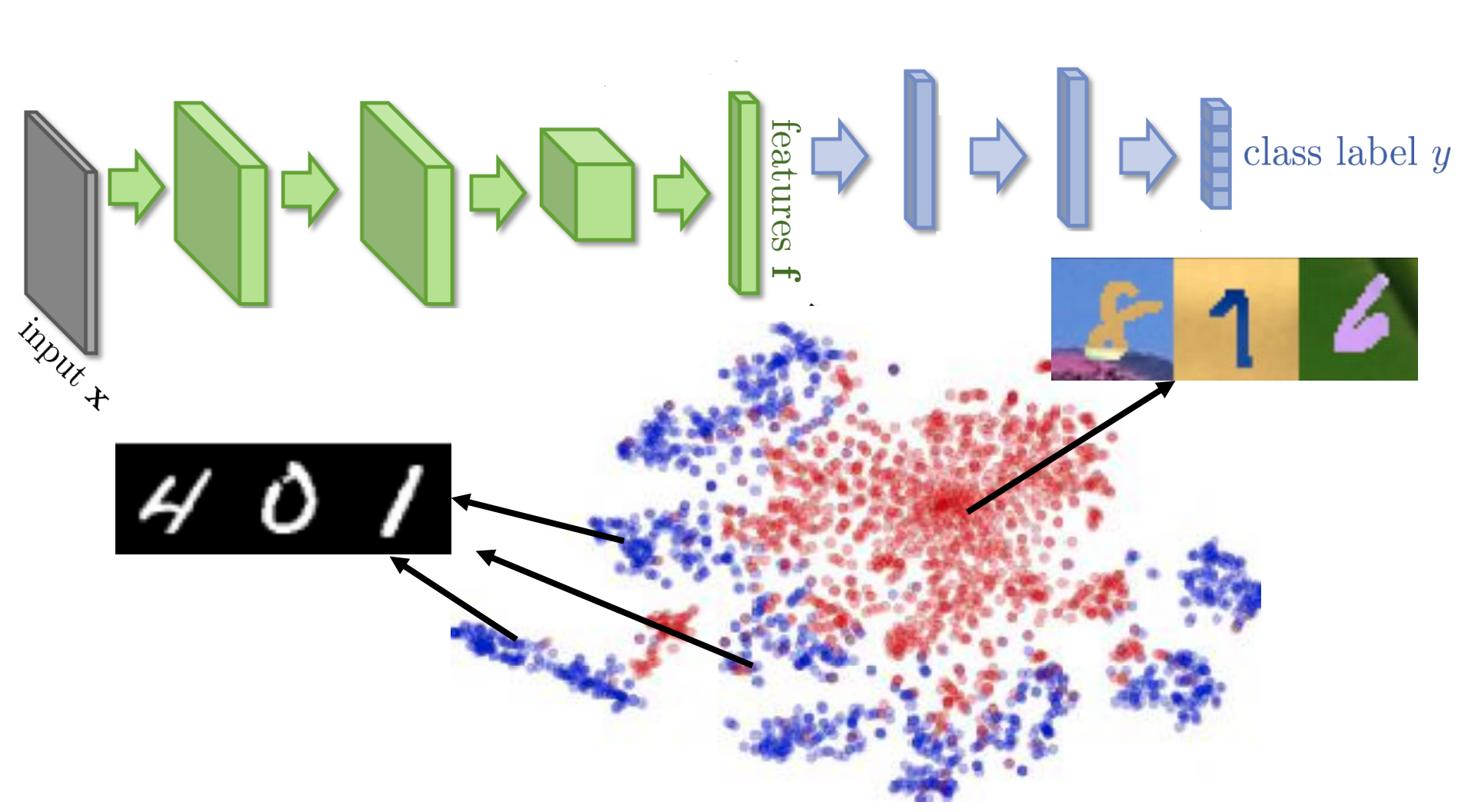
对特征
f
f
f进行
t
−
S
N
E
t-SNE
t−SNE降维的结果,所以发现classifier虽然可以把Source data分开,但是在Target data却分不开。
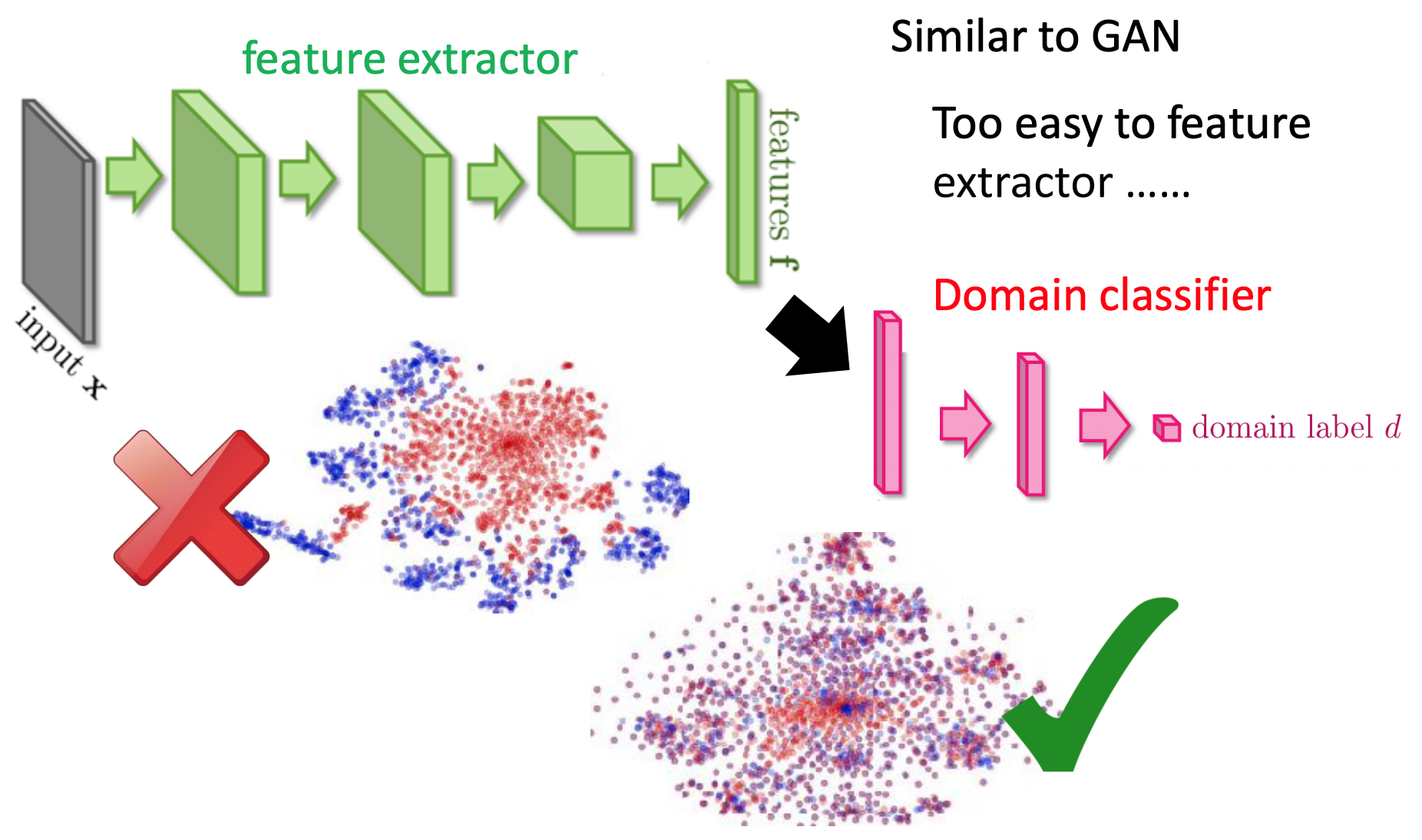
我们希望经过一个Domain classifier和原来数字classifier进行联合,使得domain的特性消除,使得不同domain的image混在一起。
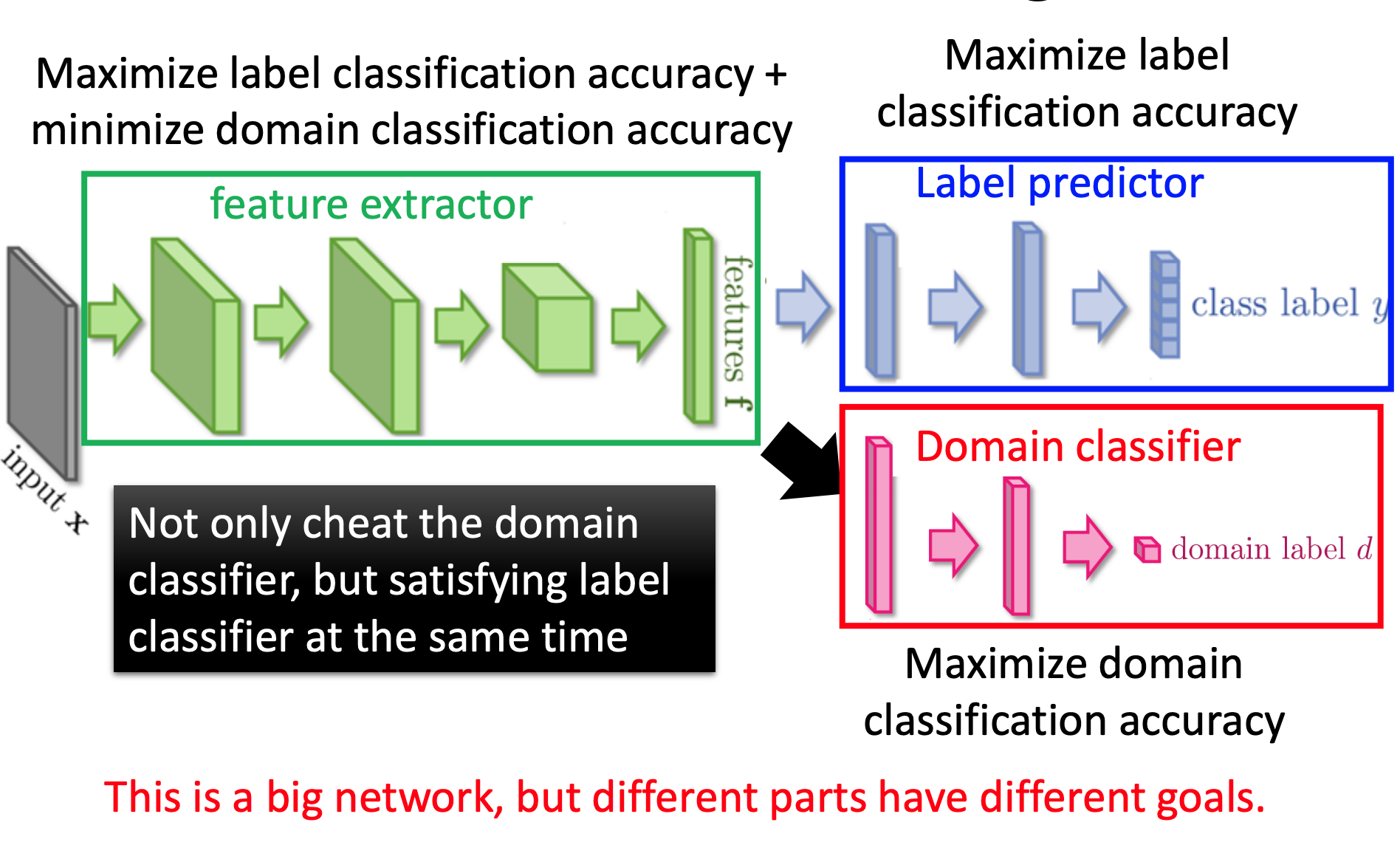
抽出的feature不仅要把domain特性消除掉,还要保持原来数字分类的特性。就是说,feature extractor要提高Label predictor的accuracy,同时也要减低Domain classifier的accuracy。
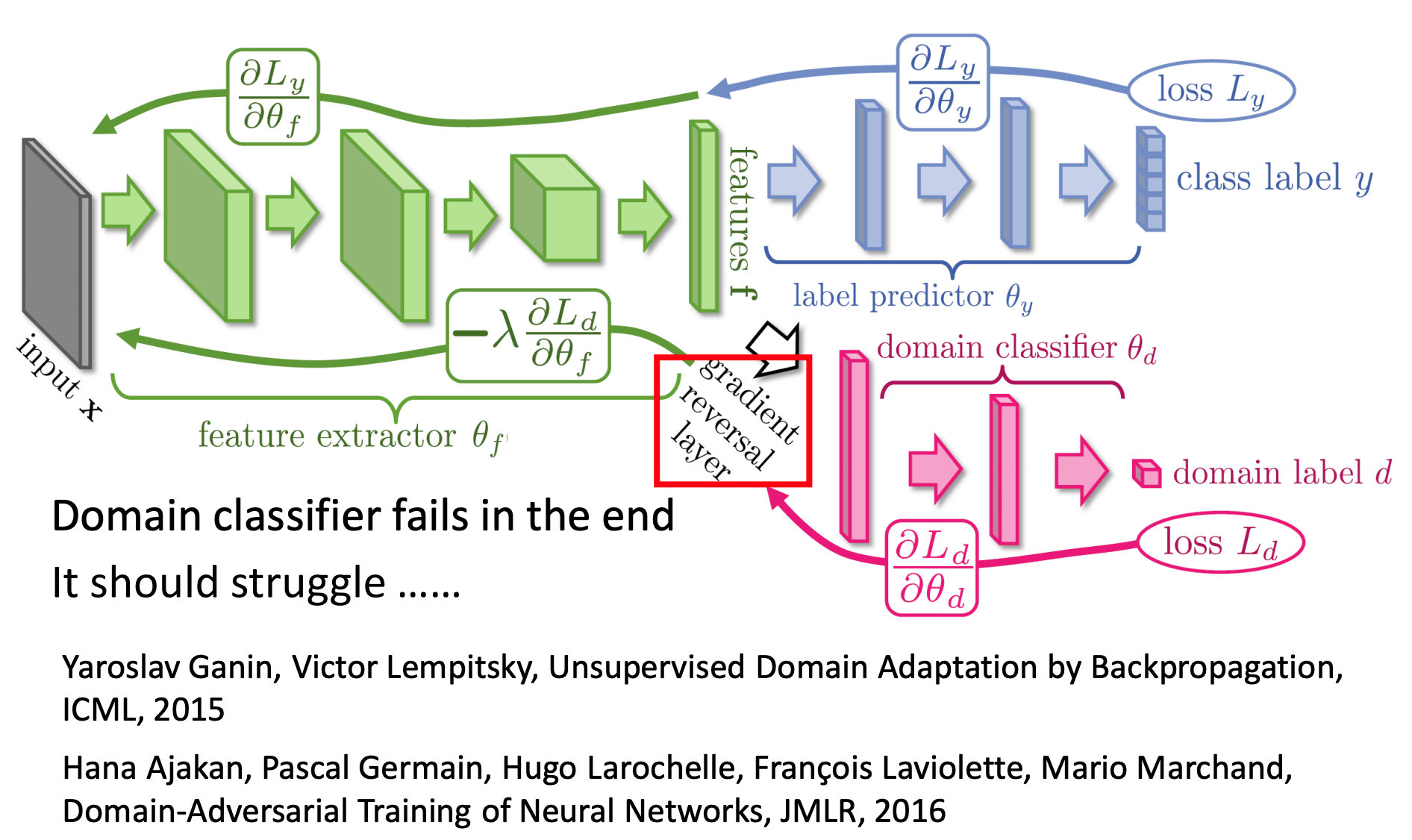
反向传播时,Domain classifier有小的loss,我们添加一个符号使得反向传播的梯度更大,而大的loss,我们添加一个符号使得反向传播的梯度更小。但是也不期望Domain classifier很弱,还没等把domain特性消除掉,Domain classifier的accuracy就很大,坏掉了。所以可能是需要先训练一个比较强的Domain classifier,这样需要越多会把domain特性消除掉。
Zero-shot learning
概念:Target Data无标签、Source Data有标签。
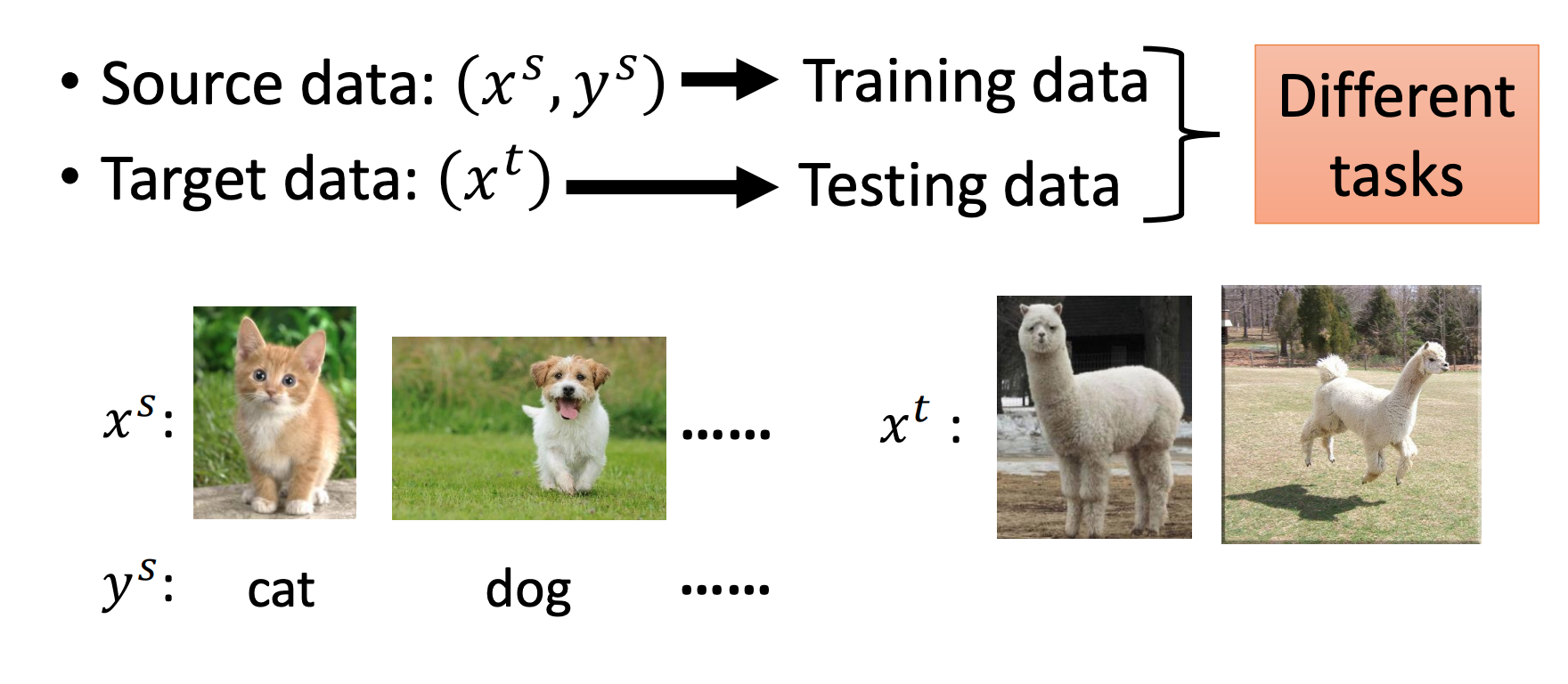
与Domain-adversarial training不同的是,Target data是和Source data属于不同的任务。上图显示,在Source data上,训练了识别猫和狗的任务,但是草泥马和羊驼从未见过。
联想语音识别,word很多,可能训练数据不会包含所有word,所以是识别phoneme,然后一个word是由多个phoneme组成,通过查表就知道对应的词。而phoneme是比较少的,可以训练的比较完整。
• Representing each class by its attr
在图像识别任务上,也可以这么做,一张图有什么属性。
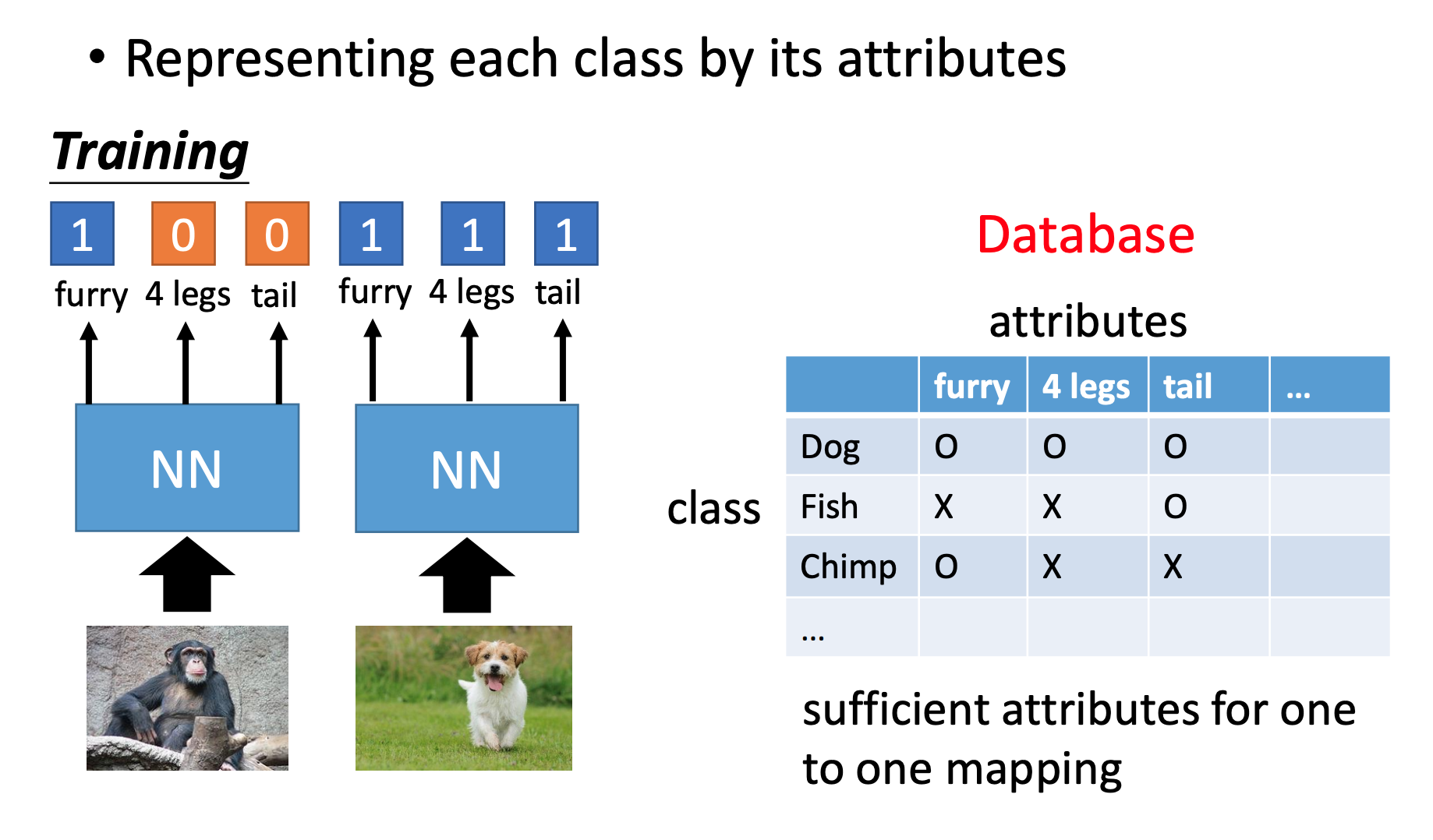
需要注意的是:属性要足够丰富,每一个class都要有独一无二的属性组合。
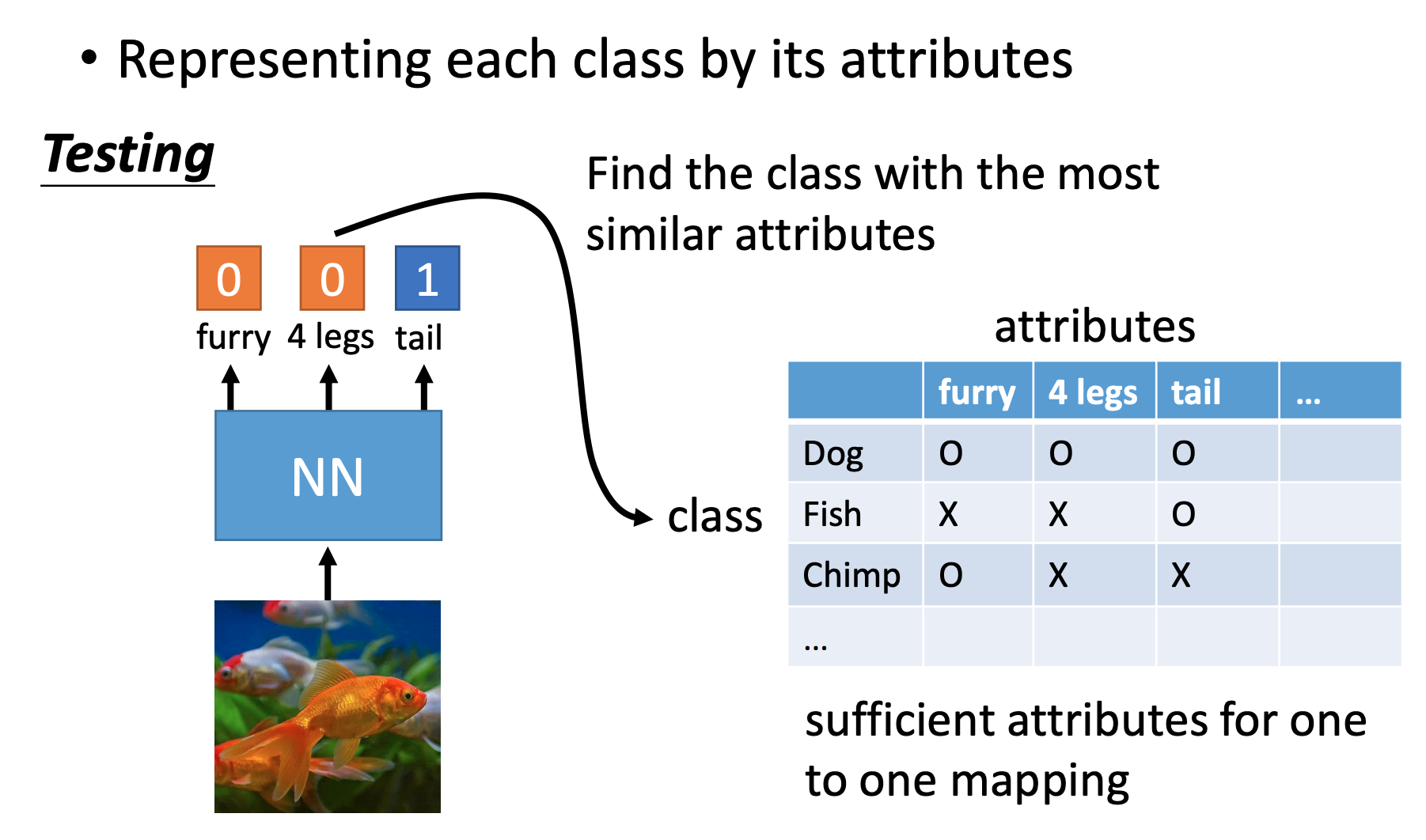
测试时候同理。
•Attribute embedding
也可以对图片做Attribute embedding ,比如利用2个NN,输入分别是图片和Attribute。期望它们的输出要一致,并且是在低维空间上的。
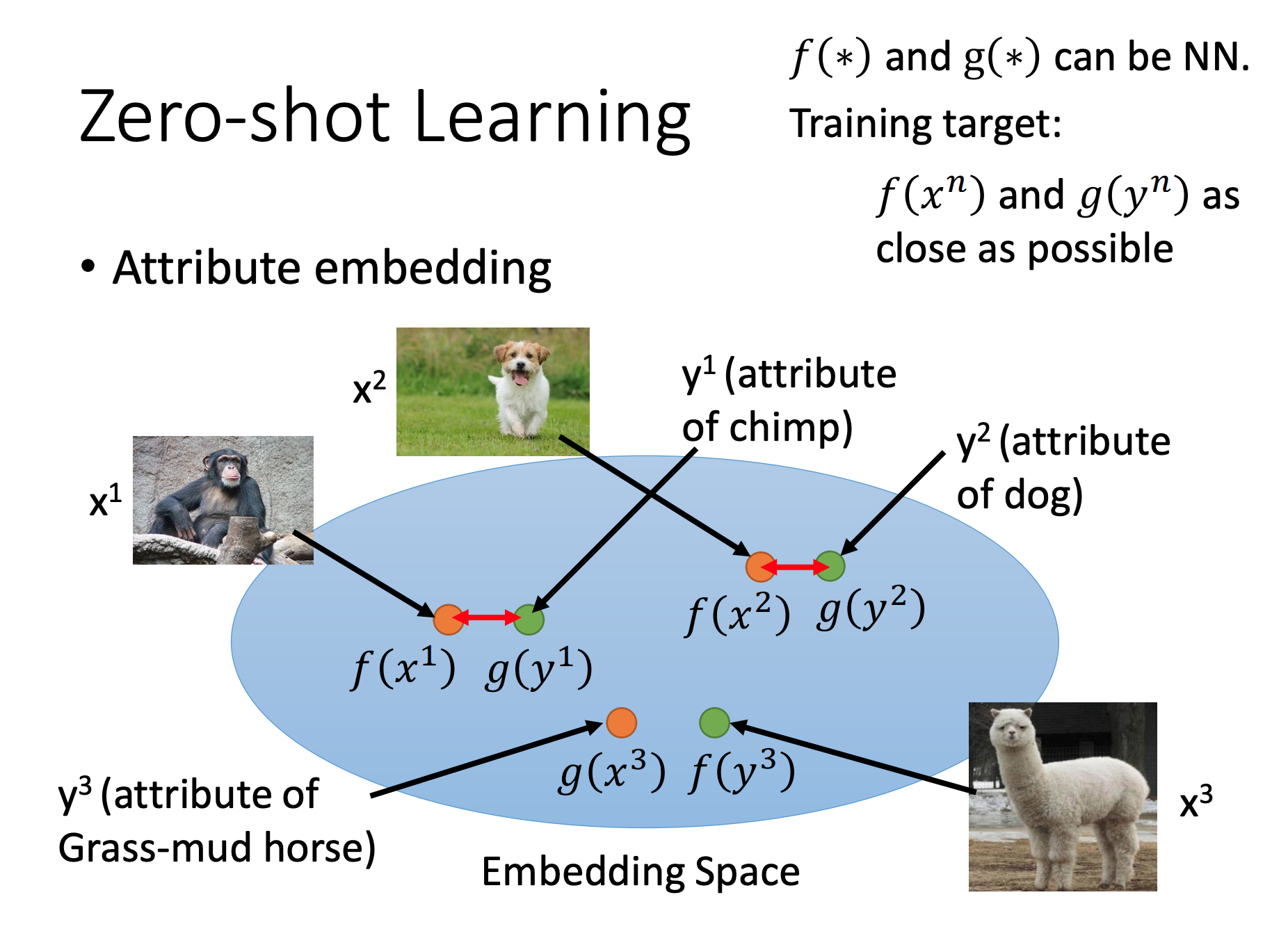
•Attribute embedding + word embedding:
如果不知道Attribute可以使用word的word vector(word embedding)表示。
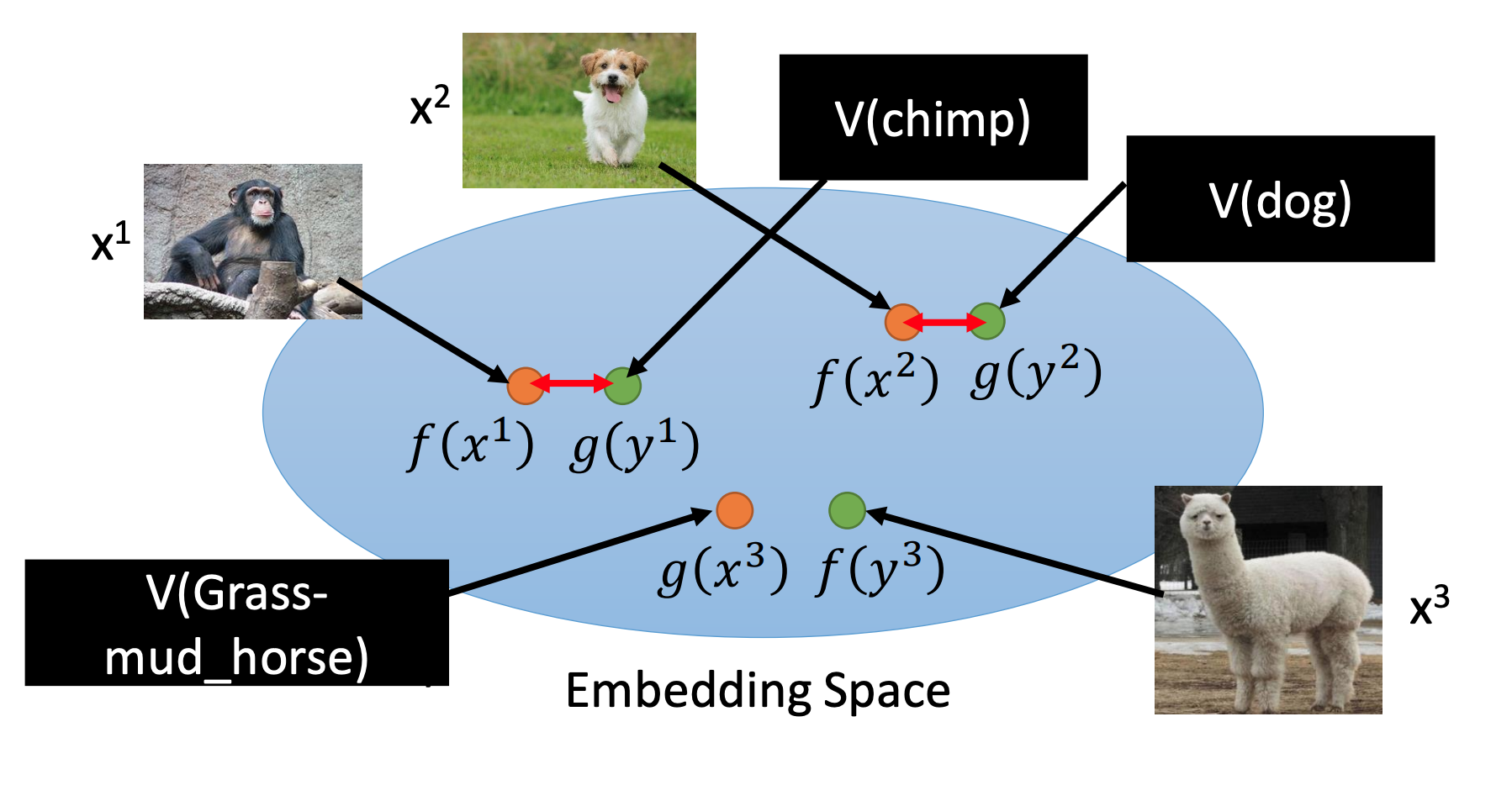
下面解释一下训练过程
直觉上lose可以这么设计:
f
∗
,
g
∗
=
arg
min
f
,
g
∑
n
∥
f
(
x
n
)
−
g
(
y
n
)
∥
2
f^{*}, g^{*}=\arg \min _{f, g} \sum_{n}\left\|f\left(x^{n}\right)-g\left(y^{n}\right)\right\|_{2}
f∗,g∗=argf,gminn∑∥f(xn)−g(yn)∥2
但是可能存在一个问题,model可能会把所有的x和y都投影到同一个点,这时候loss最小。
为了防止这种情况,loss设计成这样:
f
∗
,
g
∗
=
arg
min
f
,
g
∑
n
max
(
0
,
k
−
f
(
x
n
)
⋅
g
(
y
n
)
+
max
m
≠
n
f
(
x
n
)
⋅
g
(
y
m
)
)
f^{*}, g^{*}=\arg \min _{f, g} \sum_{n} \max \left(0, k-f\left(x^{n}\right) \cdot g\left(y^{n}\right)+\max _{m \neq n} f\left(x^{n}\right) \cdot g\left(y^{m}\right)\right)
f∗,g∗=argf,gminn∑max(0,k−f(xn)⋅g(yn)+m=nmaxf(xn)⋅g(ym))
因为当
f
(
x
n
)
f\left(x^{n}\right)
f(xn) 和
g
(
y
n
)
g\left(y^{n}\right)
g(yn)的内积大于
f
(
x
n
)
f\left(x^{n}\right)
f(xn) 和
g
(
y
m
)
g\left(y^{m}\right)
g(ym)内积时loss就为0。所以model只会往反方向发展,也就是
f
(
x
n
)
f\left(x^{n}\right)
f(xn) 和
g
(
y
n
)
g\left(y^{n}\right)
g(yn)的内积小于
f
(
x
n
)
f\left(x^{n}\right)
f(xn) 和
g
(
y
m
)
g\left(y^{m}\right)
g(ym)内积。这就符合同类的x和y相近,不同类的x和y不相近。
在这种情况下loss为0
k
−
f
(
x
n
)
⋅
g
(
y
n
)
+
max
m
≠
n
f
(
x
n
)
⋅
g
(
y
m
)
<
0
k-f\left(x^{n}\right) \cdot g\left(y^{n}\right)+\max _{m \neq n} f\left(x^{n}\right) \cdot g\left(y^{m}\right)<0
k−f(xn)⋅g(yn)+m=nmaxf(xn)⋅g(ym)<0
也就是
f
(
x
n
)
⋅
g
(
y
n
)
−
max
f
(
x
n
)
⋅
g
(
y
m
)
>
k
f\left(x^{n}\right) \cdot g\left(y^{n}\right)-\max f\left(x^{n}\right) \cdot g\left(y^{m}\right)>k
f(xn)⋅g(yn)−maxf(xn)⋅g(ym)>k
其中,k为一个定义的margin。
• Convex Combination of Semantic Embedding
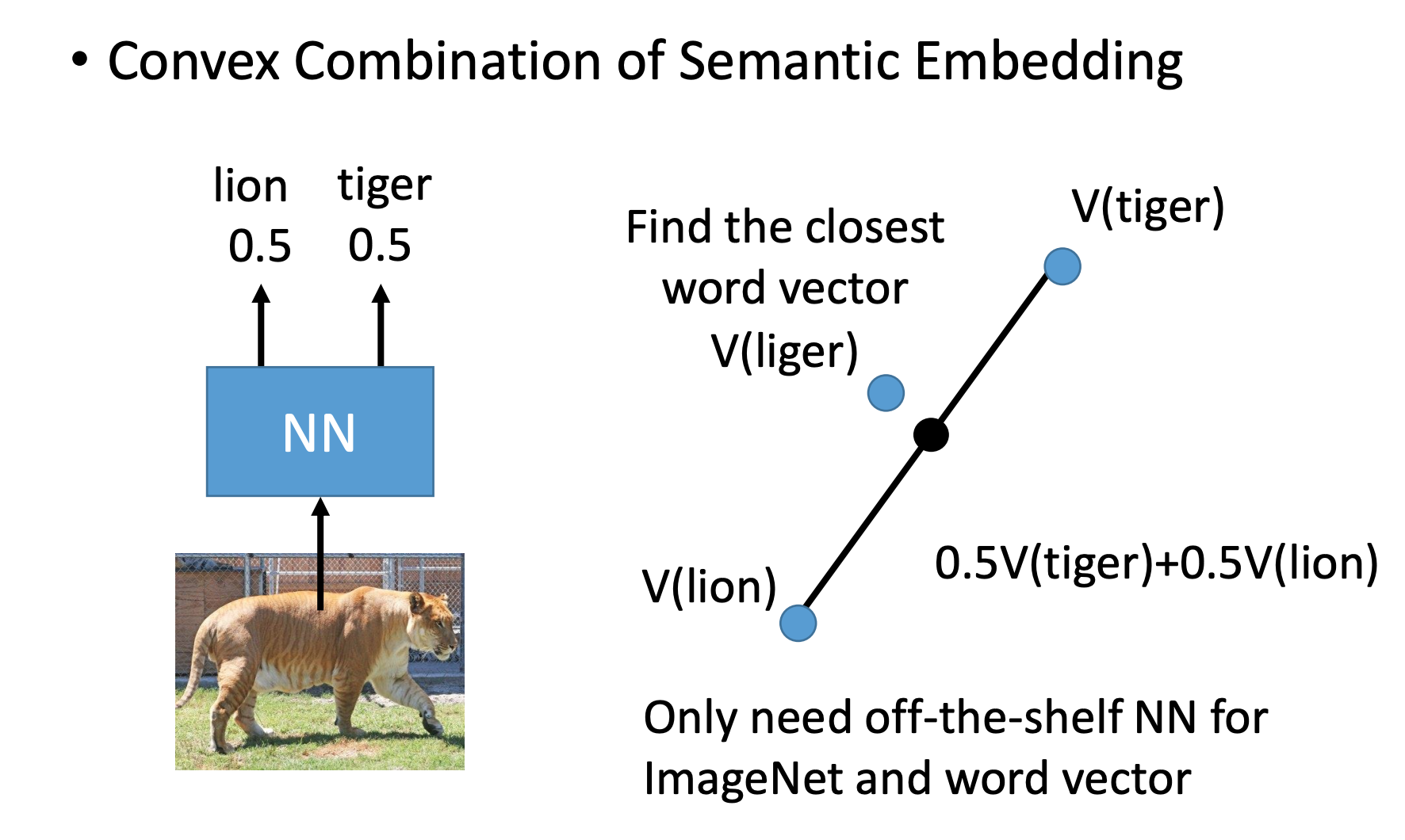
这个就比较简单了,用NN输出各个类的概率组合,然后在word vector找。
在语言翻译上的应用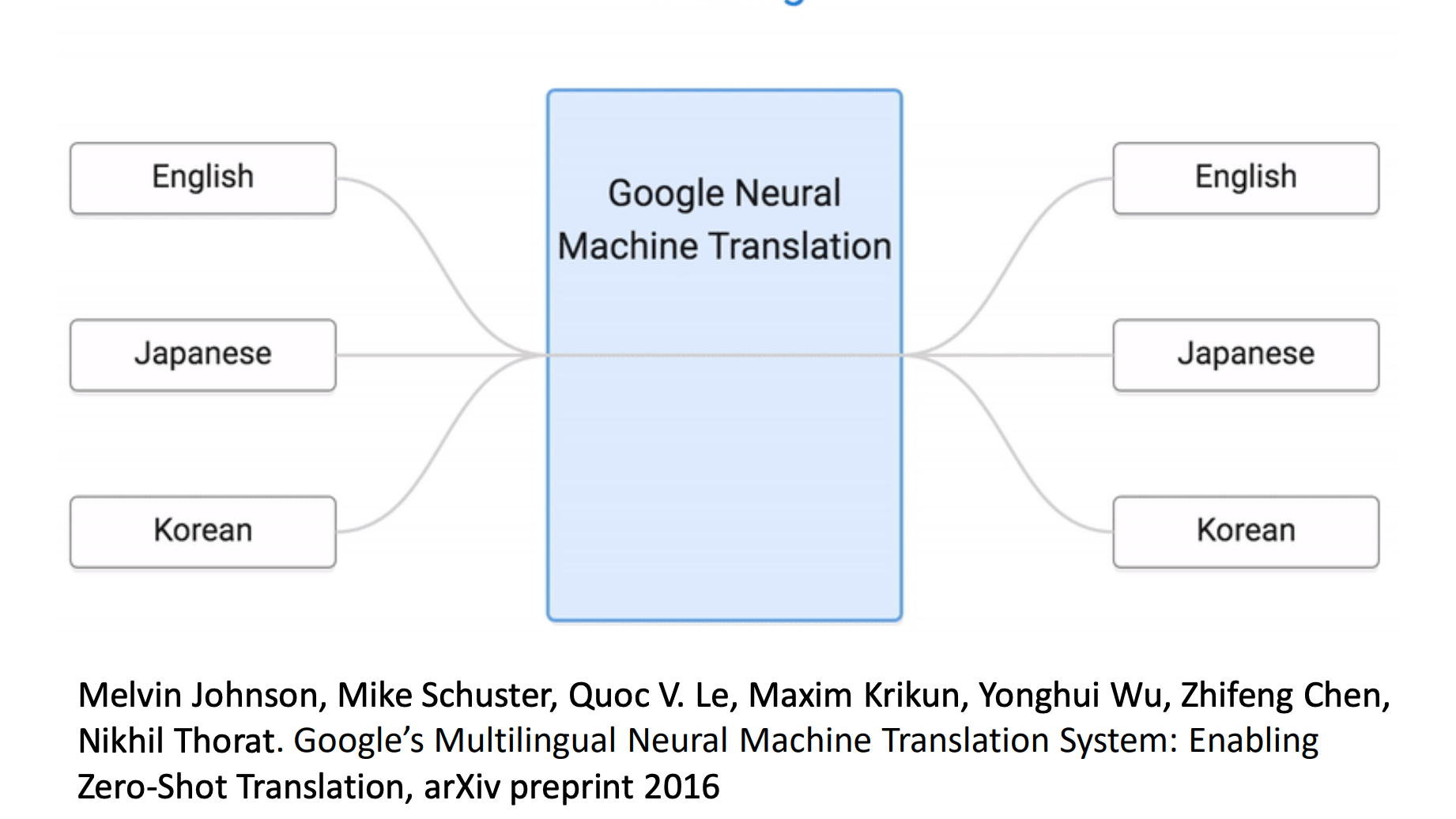
所有语言都转成sequence language。比如上面学习了韩语翻译英语和英语翻译成日语。那么就可以直接进行韩语翻译成日语了。这一过程为韩语->sequence language->日语。其中韩语->sequence language在韩语翻译英语学习到了。sequence language->日语在英语翻译成日语学习到了。
sequence language 空间
Self-taught learning
概念:Target Data有标签、Source Data无标签。
Self-taught learning其实也是Semi-supervised learning。但是和一般的Semi-supervised learning不同的是Unlabel data和 label data非常不一样。
其实目的就是在Source Data做Auto Encoder,提取一个好的feature extractor。应用在Target Data上。
Self-taught Clustering
概念:Target Data无标签、Source Data无标签。
也是在Source Data做Auto Encoder,提取一个好的feature extractor。应用在Target Data上。任务是做聚类。
以上参考李宏毅老师视频和ppt,仅作为学习笔记交流使用















 579
579











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









