






【MATLAB第58期】基于MATLAB的PCA-Kmeans、PCA-LVQ与BP神经网络分类预测模型对比
一、数据介绍
基于UCI葡萄酒数据集进行葡萄酒分类及产地预测
共包含178组样本数据,来源于三个葡萄酒产地,每组数据包含产地标签及13种化学元素含量,即已知类别标签。
把样本集随机分为训练集和测试集(70%训练,30%测试),根据已有数据集训练一个能进行葡萄酒产地预测的模型,以正确区分三个产地所产出的葡萄酒,
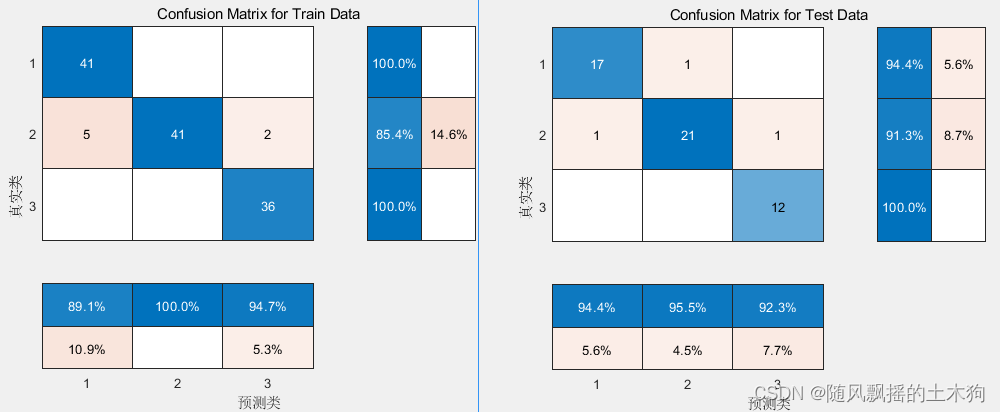
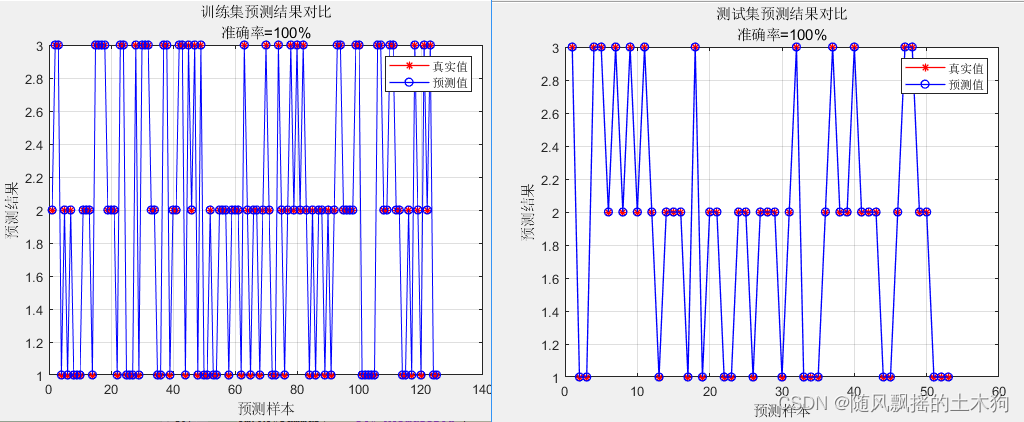
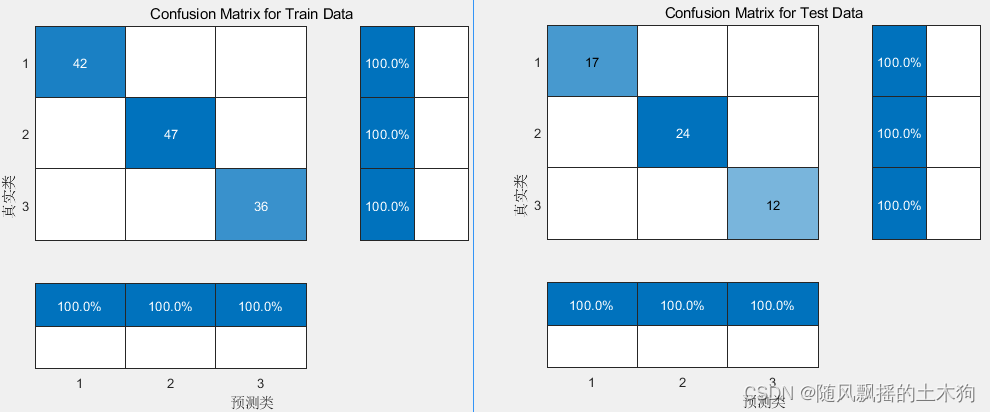
分别采用PCA+Kmeans、PCA+LVQ、BP神经网络等方法进行模型的训练与测试,准确率都能达到95%左右。
二、效果展示
1.PCA-Kmeans
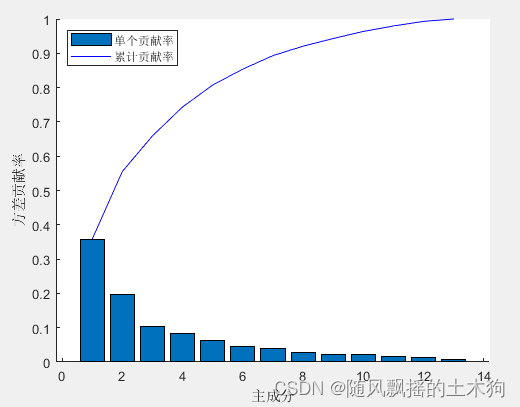
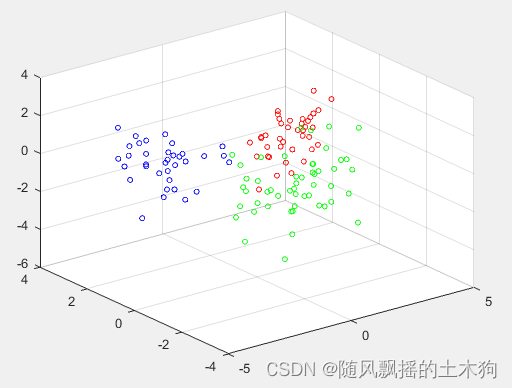
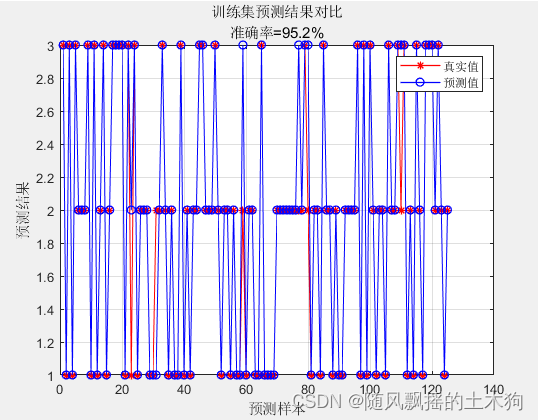
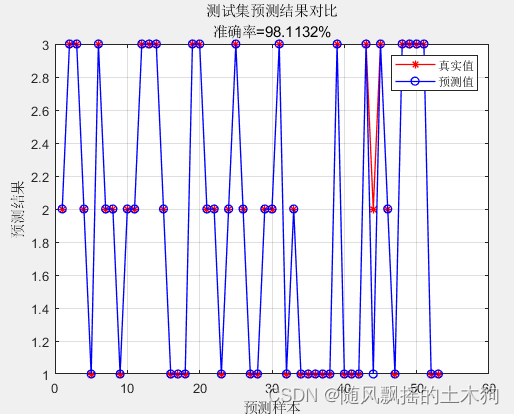
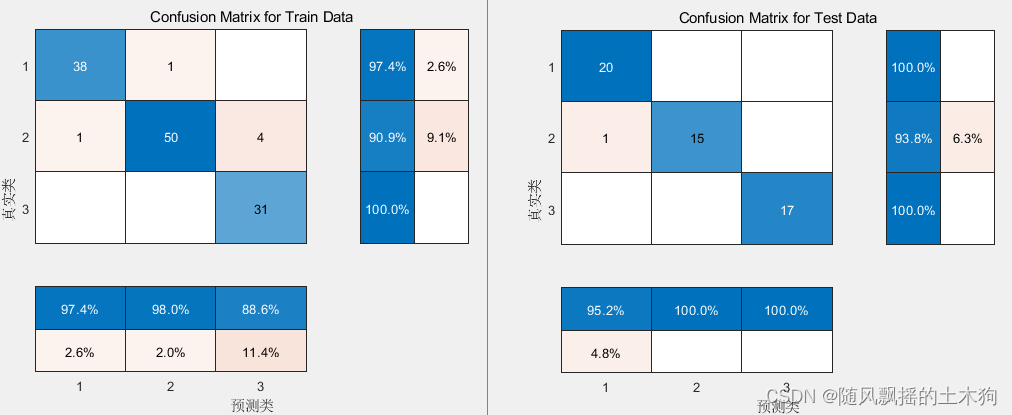
train_accuracy = 0.95
test_accuracy = 0.98
2.PCA-LVQ
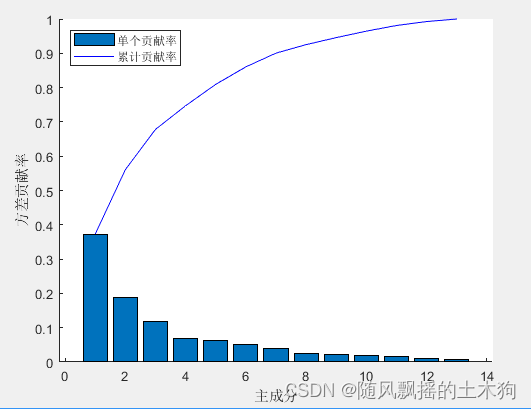
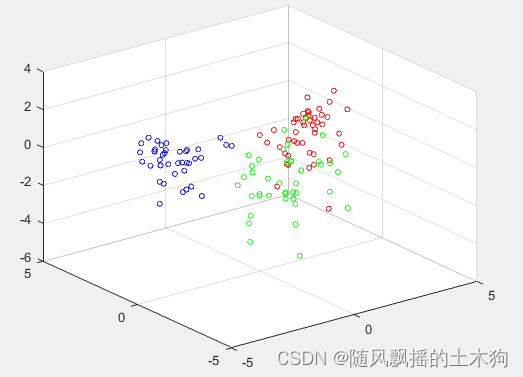
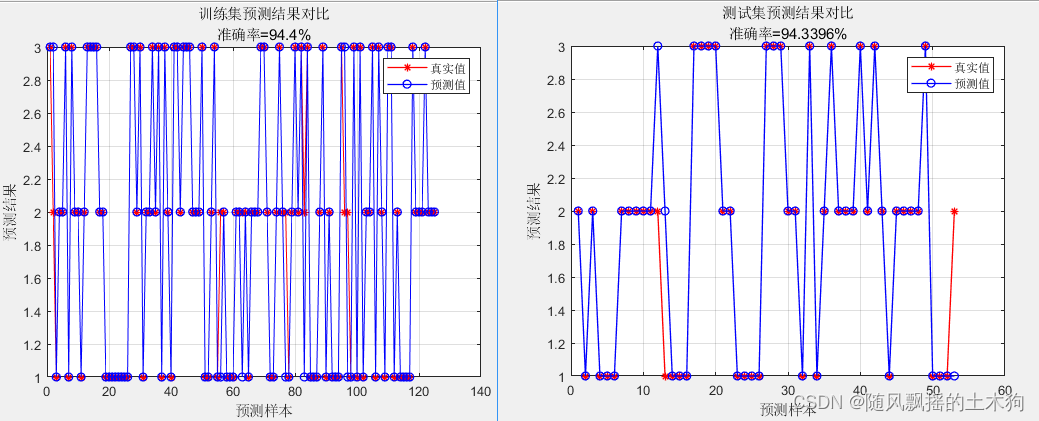
3.BP
三、代码展示(部分代码)
clear all;
wine_data = xlsread('wine.xlsx'); %分类标签默认第一列
method = 'BP';%PK: PCA & Kmeans
%PL: PCA & LVQ
%BP: BP Neural Network'
rate = 0.7;%训练集70%,测试集30%
N = size(unique(wine_data(:,1)),1);;
total_cnt = size(wine_data,1);
train_cnt = round(total_cnt*rate);
test_cnt = total_cnt - train_cnt;
rand_idx = randperm(total_cnt);
train_idx = rand_idx(1:train_cnt);
test_idx = rand_idx(train_cnt+1:total_cnt);
train_data = wine_data(train_idx,2:size(wine_data,2));
train_class = wine_data(train_idx,1);
test_data = wine_data(test_idx,2:size(wine_data,2));
test_class = wine_data(test_idx,1);
dim = size(wine_data,2)-1;
%矩阵z-score标准化
train_SM = zeros(train_cnt,dim);
data_mean = mean(train_data);
data_std = std(train_data);
test_SM = zeros(test_cnt,dim);
for j = 1:dim
train_SM(:,j) = (train_data(:,j) - data_mean(j)) / data_std(j);
test_SM(:,j) = (test_data(:,j) - data_mean(j)) / data_std(j);
end
四、代码获取
私信回复“58期”即可获取下载链接。

















 5548
5548











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











