







 BEIT论文介绍了一种将Transformer应用于图像处理的新方法,通过自监督学习来初始化模型参数。首先训练一个变分自动编码器,然后使用遮挡策略(约40%图像内容)进行预训练,使Transformer学习到图像的抽象特征。预训练后的模型可用于下游任务如图像分类和分割,只需微调头部参数。文章探讨了未使用像素重构的原因以及遮挡比例选择的疑问,并提供了官方代码实现。
BEIT论文介绍了一种将Transformer应用于图像处理的新方法,通过自监督学习来初始化模型参数。首先训练一个变分自动编码器,然后使用遮挡策略(约40%图像内容)进行预训练,使Transformer学习到图像的抽象特征。预训练后的模型可用于下游任务如图像分类和分割,只需微调头部参数。文章探讨了未使用像素重构的原因以及遮挡比例选择的疑问,并提供了官方代码实现。
记录下论文《BEIT: BERT Pre-Training of Image Transformers》,这是一篇将Transformer应用于图像领域,并使用自监督方法进行参数初始化的文章。
整体概要
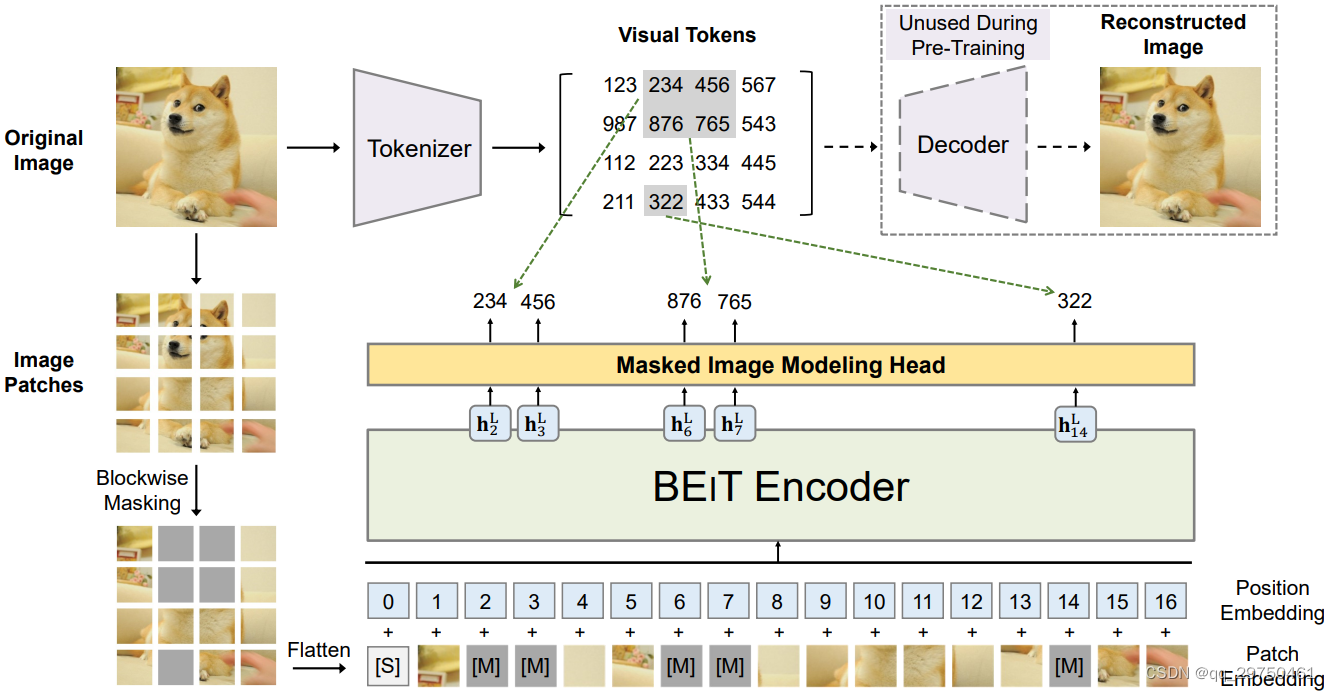
由于网络整体流程图没有标注好模型的运行过程,结合论文的描述:第一阶段为训练一个变分自动编码器,即图中的 Encoder和Decoder部分,然后保留自动编码器的Encoder部分,即图中的Tokenizer,用于生成文中提及的Token;第二个阶段为自监督训练过程,将图像分块,然后进行一定比例的随机mask(文中说遮挡40%的图像内容),然后将经过遮挡处理的图像送入Transformer进行学习,学习的目标就是完整图像送入Tokenizer得到的特征图,即让Transformer拥有一定的特征学习能力(本质上是得到具有一定学习能力的Transformer模型,即相当于对模型参数进行了合理的初始化);第三个阶段会将经过预训练后的Transformer模型进行下游任务的学习(图像分类、图像分割等),在此过程中,仅用添加下游任务相关的网络头部即可,也就是仅微调网络头部参数。
方法产生原因及存在的问题
1 文中没有直接使用Tranformer对masked图像的像素进行重构/恢复,作者认为这将会另Transformer模型更倾向关注短距离相关性(即过度关注局部特征,限制全局特征的学习)或高频去噪能力(因为模型中经过掩码后,与周围的图像形成强烈的反差或明显边缘,类似加了高频信息)。而我们一般使用深度神经网络模型一般是希望模型能够学习到抽象的特征,而不是针对某种特定任务的模型,所以这里使用自动编码器学习到的特征作为目标,训练Transformer,让其在输入有遮挡的情况下,仍然能学习到目标特征,一定程度上可认为经过预训练后的Transformer为更强大的编码器,能够对输入生成抽象的高维特征。
2 个人认为存在的问题在于文中在自监督预训练过程中,使用了随机遮挡的方法,文中提到是大约40%的图像内容被遮挡,作者并未讨论为什么大约40%内容被遮挡?此外作者在预训练模型过程中,输入端使用了一个特殊的Token [S] 并未解释该Token的用途,可能是进一步扩展模型学习的余量?
官方关键代码
官方代码链接,可以使用 git 或 svn 进行下载,比较快。
这个代码里其实看起来有些乱,但是文件命名整体上还相对较规范,可以说明一些问题。下面将结合和整体的模型相关的关键代码来说一下。
1 modeling_pretrain.py
这个文件中基本包含了模型相关的代码,整体上可以辅助我们理解模型的整体运行流程。整体上包含:PatchEmbed -> Relative position encoding -> Transformer Block
import math
import torch
import torch.nn as nn
from functools import partial
from modeling_finetune import Block, _cfg, PatchEmbed, RelativePositionBias
from timm.models.registry import register_model
from timm.models.layers import trunc_normal_ as __call_trunc_normal_
def trunc_normal_(tensor, mean=0., std=1.):
__call_trunc_normal_(tensor, mean=mean, std=std, a=-std, b=std)
__all__ = [
'beit_base_patch16_224_8k_vocab',
'beit_large_patch16_224_8k_vocab',
]
class VisionTransformerForMaskedImageModeling(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_chans=3, vocab_size=8192, embed_dim=768, depth=12,
num_heads=12, mlp_ratio=4., qkv_bias=True, qk_scale=None, drop_rate=0., attn_drop_rate=0.,
drop_path_rate=0., norm_layer=None, init_values=None, attn_head_dim=None,
use_abs_pos_emb=True, use_rel_pos_bias=False, use_shared_rel_pos_bias=False, init_std=0.02, **kwargs):
super().__init__()
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)
num_patches = self.patch_embed.num_patches
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.mask_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
if use_abs_pos_emb:
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
else:
self.pos_embed = None
self.pos_drop = nn.Dropout(p=drop_rate)
if use_shared_rel_pos_bias:
self.rel_pos_bias = RelativePositionBias(window_size=self.patch_embed.patch_shape, num_heads=num_heads)
else:
self.rel_pos_bias = None
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule
self.blocks = nn.ModuleList([
Block(
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer,
init_values=init_values, window_size=self.patch_embed.patch_shape if use_rel_po 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 996
996

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









