







 BEiT采用自监督学习方法预训练图像表示,借鉴BERT的encoder结构,将图片转换为patch序列,然后用mask图像建模进行预训练。在预训练过程中,部分图像patch被随机替换为可学习的编码,通过BEiT的encoder和分类器预测这些被遮盖的patch。主干网络是基于图片transformer,通过blockwise masking策略确保预训练的有效性。
BEiT采用自监督学习方法预训练图像表示,借鉴BERT的encoder结构,将图片转换为patch序列,然后用mask图像建模进行预训练。在预训练过程中,部分图像patch被随机替换为可学习的编码,通过BEiT的encoder和分类器预测这些被遮盖的patch。主干网络是基于图片transformer,通过blockwise masking策略确保预训练的有效性。
1 核心思想
BEiT 提出了一种自监督学习图像表征的方法,核心思想是预训练任务实现 BEiT encoder 分类预测 mask patch 的 token。思路迁移自 BERT 的 encoder 结构,图像输入处理一方面将图像转为 patch 序列(ViT) ,另一方面用固定范围的 token 代替图片像素。
预训练 BERT: masked image modeling + 下游任务: image classification and semantic segmentation
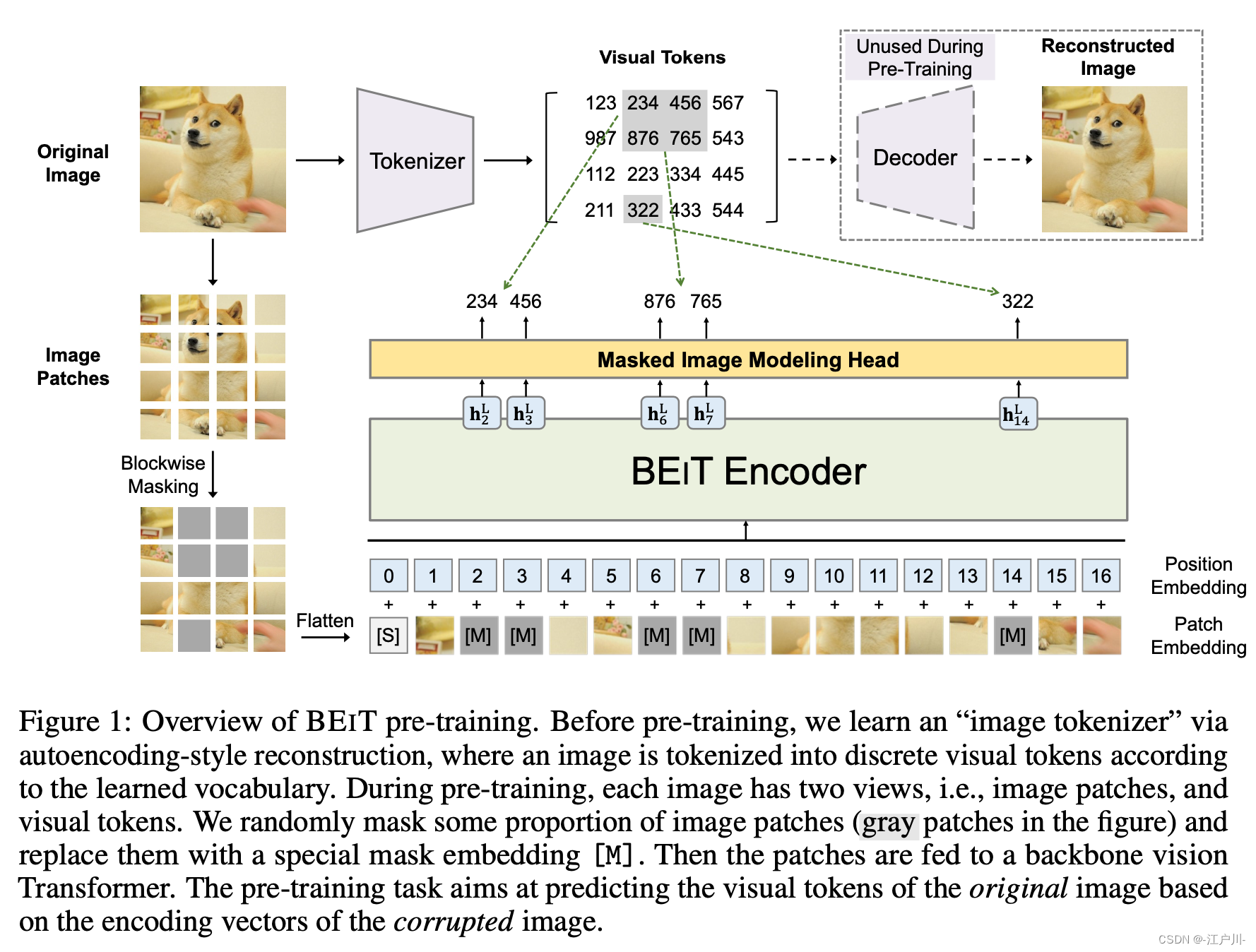
思路:
-
给定图片x
-
变成 N 个image patches
-
变成 N 个visual tokens
-
随机盖住 40%的 img patches, 替换为可学习的编码
-
把盖住替换后的编码 与原始的 visual tokens 通过 BEiT 的 L层 encoder, 得到一个 h L h^L
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1344
1344











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









