







transformer_正余弦位置编码代码笔记
transformer输入的序列中,不同位置的相同词汇可能会表达不同的含义,通过考虑位置信息的不同来区分序列中不同位置的相同词汇。
位置编码有多种方式,此处仅记录正余弦位置编码
正余弦位置编码公式如下:
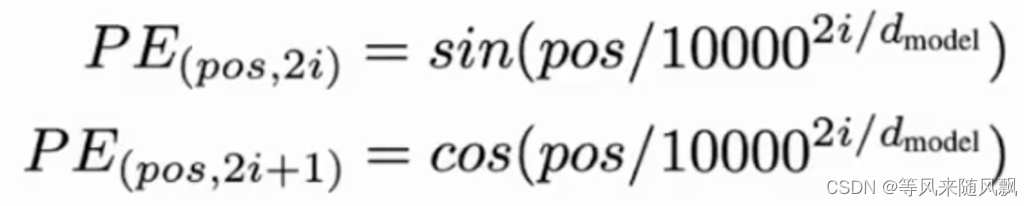
代码如下:
import numpy as np
import torch
def positional_encoding(seq_len, d_model):
# 创建一个形状为(seq_len, 1)的数组,其中的值为[0, 1, 2, ... seq_len-1]
position = np.arange(seq_len)[:, np.newaxis] # 使用np.newaxis增加列上的维度,position矩阵为seq_len×1
# 计算除数,这里的除数将用于计算正弦和余弦的频率,div_term矩阵为1×d_model
div_term = np.exp(np.arange(0, d_model, 2) * -(np.log(10000.0) / d_model))
# 初始化位置编码矩阵为零,后续计算所有位置的位置编码并更新相对位置的初始化位置编码矩阵
pe = np.zeros((seq_len, d_model))
# 以下是针对偶数列使用正弦函数,奇数列使用余弦函数,最终输出的结果矩阵为seq_len×d_model
# 对矩阵的偶数列机型正弦函数编码
pe[:, 0::2] = np.sin(position * div_term)
# 对矩阵的奇数列机型余弦函数编码
pe[:, 1::2] = np.cos(position * div_term)
# 返回位置编码矩阵,转换为PyTorch张量
return torch.tensor(pe, dtype=torch.float32)
if __name__ == '__main__':
# 使用示例
seq_len = 50 # 定义序列长度
d_model = 512 # 定义模型的embedding维度
pe = positional_encoding(seq_len, d_model) # 获得位置编码
print(pe)
实际使用时代码如下:
# forward the GPT model itself
# token的embedding
tok_emb = self.transformer.wte(idx) # token embeddings of shape (b, t, n_embd)
# 位置的embedding
pos_emb = self.transformer.wpe(pos) # position embeddings of shape (1, t, n_embd)
# 将token的embedding与位置得到embedding相加
x = self.transformer.drop(tok_emb + pos_emb)















 1080
1080











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









