







重温第一篇探索 ViT 模型在自监督学习领域的经典代表作
Paper:https://openaccess.thecvf.com/content/ICCV2021/papers/Caron_Emerging_Properties_in_Self-Supervised_Vision_Transformers_ICCV_2021_paper.pdf
https//arxiv.org/pdf/2104.14294.pdf
Code:https://github.com/facebookresearch/dino
DINO 是一种用于自监督视觉学习的深度学习模型,于 2021 年由 Facebook AI 提出。DINO 是最先探讨基于 Transformer 架构的自监督学习代表作之一,其通过在无标签图像上进行自监督训练来学习视觉特征表示。
DINO 是视觉 Transformer 做自监督学习的非常经典的工作。DINO 所要探究的问题是:自监督学习算法是否能够为视觉 Transformer 带来新的特性。本文给出了以下的观察:首先,自监督训练得到的 ViT 包含关于图像语义分割的显式信息,这在以往的有监督训练和卷积网络里面都是不具备的。其次,这些特征也是优秀的 k-NN 分类器,ViT-Small 在 ImageNet 上达到了 78.3% 的 top-1 精度。DINO 还研究了自监督训练中的 momentum encoder,multi-crop training 以及在 ViT 中使用小 Patch 的技巧。
自监督训练得到的 ViT 包含关于图像语义分割的显式信息,这在以往的有监督训练和卷积网络里面都是不具备的。这些特征也是优秀的 k-NN 分类器,ViT-Small 在 ImageNet 上达到了 78.3% 的 top-1 精度。DINO 还研究了自监督训练中的 momentum encoder,multi-crop training 以及在 ViT 中使用小 Patch 的技巧。
相比于监督学习需要人为地提供标签告诉模型这是什么,自监督学习无须任何“显示”标签,只需输入图像通过某种机制便能让网络学会理解图像本身的语义信息。例如,我们可以通过图像旋转、随机裁剪等变换,使模型学习到不同角度、不同尺度下的特征。另外,也可以通过模型自身的预测来构建任务,例如预测图像的局部块、颜色等等。这些任务由于不需要人类标注,因此可以在大规模的无标签数据上进行训练,从侧面上提供了一种从无标签数据中学习特征表示的新方法,它可以帮助我们更好地利用现有数据资源,解决监督学习中的一些瓶颈问题。
回到正题,DINO 的核心思想便是通过在大规模的无标签数据集上进行对比学习,学习出一组具有可传递性的视觉特征表示。在 DINO 中,作者通过引入一个新的对比学习方法,将原始图像的特征与随机裁剪的图像的特征进行对比,从而学习到更好的视觉通用表征,最终也获得了非常出色的效果。

DINO 这个名称可以理解为是由 Distillation 和 NO labels 这两个词组成的缩写,既表达了DINO采用自蒸馏方法的特点,也突出了它是一种基于无监督学习的模型。具体来说,DINO 是使用一种称为“无监督自蒸馏”的方法,该方法通过自监督学习来学习模型的知识表示。在这个方法中,模型使用自身的输出来生成“伪标签”,然后使用这些伪标签来重新训练模型,从而进一步提高模型的性能和泛化能力。
作为开始,我们给出一张动图,其非常生动形象的展示了贯穿 DINO 的整个框架和核心思想:
如上所示,DINO 本质上是一种自监督学习方法,通过无监督的方式学习图像特征表示,可用于计算机视觉的其他下游任务,例如分类和检测等。该方法的核心思想是使用一种叫做自蒸馏的方法,即将一个学生模型的表示与一个动量化的教师模型的表示进行比较,以学习出更好的特征表示。
在正式讲解具体细节前,我们可以先看看 DINO 整个处理流程的伪代码:
 下面我们将分别从网络结构、数据增强、损失函数三大部分进行详细的介绍。
下面我们将分别从网络结构、数据增强、损失函数三大部分进行详细的介绍。
网络结构
正如我们上面提到过的,DINO 是采用自蒸馏(self-distillation)的方法学习的,其整体框架包含两个相同的架构,分别为教师网络和学生网络,具体的架构可以是 ViT 等 vision transformer 或者诸如 ResNet 等 CNNs 特征提取器,非常灵活方便。当然,通过下述消融实验也知道还是 ViT 的潜力更大。
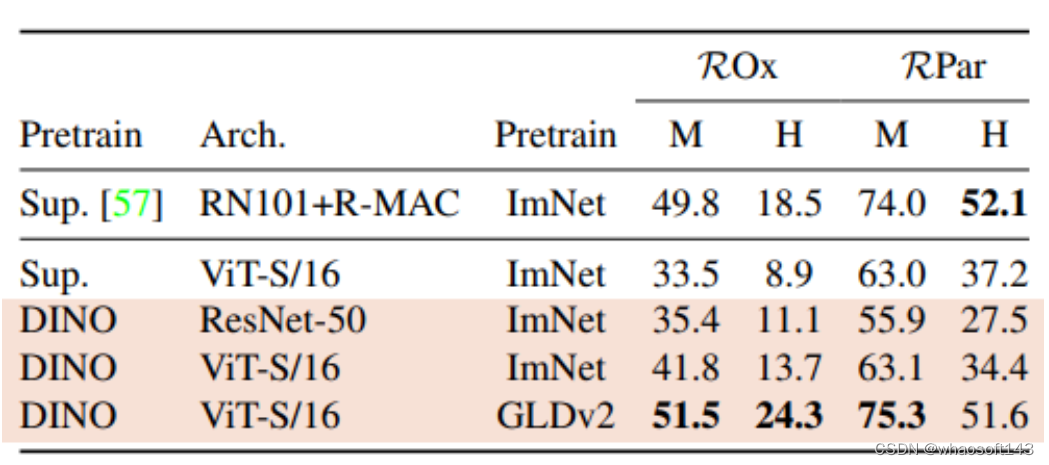
然而,这种学生和教师网络均输出相同 embeddings 的情况容易出现模式崩塌(mode collapse)的现象。在《Momentum Contrast for Unsupervised Visual Representation Learning》一文中提出了一种解决方案,即应用“动量教师”(momentum tearcher)模型,可以简单地理解为就是教师的模型不是基于反向传播更新的,而是再对学生模型进行梯度回传后,在通过指数移动平均(Exponentially Weighted Average, EWA),直接将学生网络学习到的模型参数更新给教师网络,换句话就是教师网络的权重更新自学生网络。
DINO 中便是沿用这种方式。具体地,我们可以简单看下教师权重的更新公式:

数据增强
DINO 中最核心的数据采样策略便是图像裁剪,这也是自监督学习领域应用非常广泛的主策略之一。一般来说,我们可以将裁剪后的图像分为两种:
-
Local views: 即局部视角,也称为 small crops,指的是抠图面积小于原始图像的 50%; -
Global views: 即全局视角,也称为 large crops,指的是抠图面积大于原始图像的 50%;
在 DINO 中,学生模型接收所有预处理过的 crops 图,而教师模型仅接收来自 global views 的裁剪图。据作者称,这是为了鼓励从局部到全局的响应,从而训练学生模型从一个小的裁剪画面中推断出更广泛的上下文信息。
简单来说,就是把局部特征和全局特征分别交给不同的模型来学习,以便在处理整个图像时,能够更好地对局部细节和上下文进行综合判断。
此外,为了使网络更加鲁邦,DINO 中也采用一些其它的随机增强,包括:
-
颜色扰动(
color jittering) -
高斯模糊(
Gaussian blur) -
曝光增强(
solarization)
损失函数
在 DINO 中,教师和学生网络分别预测一个一维的嵌入。为了训练学生模型,我们需要选取一个损失函数,不断地让学生的输出向教师的输出靠近。softmax 结合交叉熵损失函数是一种常用的做法,来让学生模型的输出与教师模型的输出匹配。具体地,通过 softmax 函数把教师和学生的嵌入向量尺度压缩到 0 到 1 之间,并计算两个向量的交叉熵损失。这样,在训练过程中,学生模型可以通过模仿教师模型的输出来学习更好的特征表示,从而提高模型的性能和泛化能力。
当然,这也可以看作是一个分类问题,以便网络可以从局部视图中学习更有意义的全局表示。
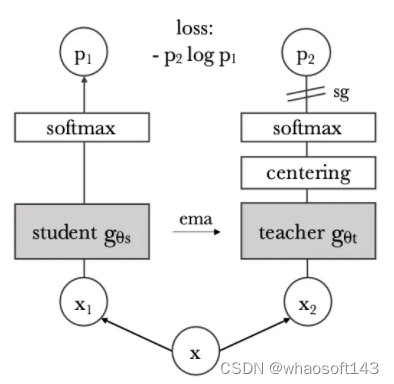
DINO Flow
Centering and Sharpening
在 DINO 论文中,还有两个不得不提的点便是 Centering 和 Sharpening,这是用于防止模式崩塌的两种有效方式。
在自监督学习中,mode collapse 是指网络的学习过程中出现了多样性减少的现象。具体来说,当网络学习到一组特征表示时,往往会出现多个输入数据映射到相同的特征表示的情况,这就是所谓的模式崩塌。这种现象通常是由于网络在优化过程中陷入了局部最优解,只能考虑到一部分数据的特征表示,而忽略了其它数据样本的模式和特征,从而导致了多样性缺失的现象,因此会对模型的鲁棒性产生很大的负面影响。
先来看下 Centering。首先,教师模型的输出经过一个 EMA 的操作,从原始激活值中减去得到一个新的结果。简单来说,可以表述为下列公式:
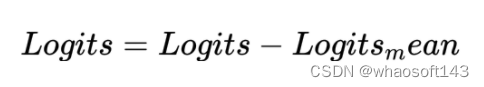
这个操作的目的是使得激活值有时候是正的(当它们高于平均值时),有时候是负的(当它们低于平均值时)。由于 softmax 函数在处理负数时会给出较小的概率值,而在处理正数时会给出较大的概率值,因此这种操作能够防止任何一个特征占据统治地位,因为平均值会在值的范围中间。
最后,再看看 Sharpening。这种技巧通过在 softmax 函数中加入一个 temperature 参数,来强制让模型将概率分布更加尖锐化。由于小差异会被夸大,这会防止所有激活值都是相同的,因为小的差异也会被放大。这个技巧和中心化操作搭配使用,可以使得激活值不断变化,从而引导学生模型更好地了解哪些特征应该变得更加强大。
实验
首先,看下这张效果图:

可以看出,DINO 是能够自动学习特定于类别(class-specific)的特征,从而实现准确的无监督对象分割。 whaosoft aiot http://143ai.com
其次,我们将此模型应用于未受过训练的场景,例如用于识别重复图像:
 可以看出,DINO 的表现也优于现有的最先进模型,尽管它起初并不是为这一目的设计的!
可以看出,DINO 的表现也优于现有的最先进模型,尽管它起初并不是为这一目的设计的!
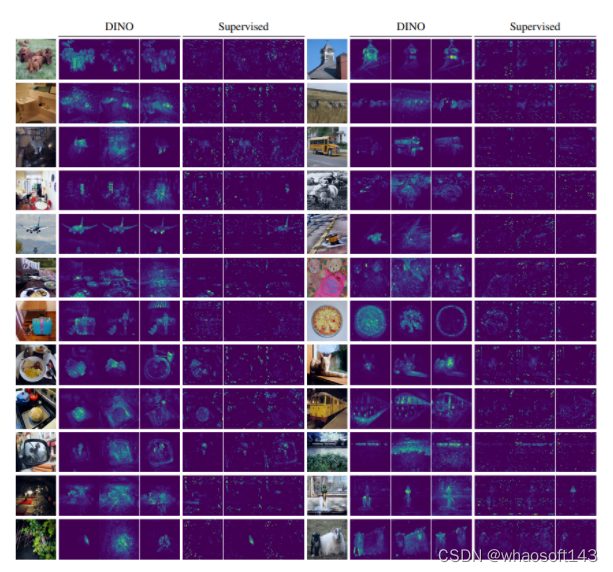
通过以上可视化结果不难看出,相比于监督学习,DINO 的潜在空间也具有很好的分离类别,这意味着它的特征足够丰富,可以分离物体中的微小差异,这使得它非常适合下游任务和迁移学习。
最后,我们通过 t-SNE 可视化一起看看 DINO 的整个学习表征过程:
 Amazing!
Amazing!
DINO 训练策略
DINO 中的 ViT 架构使用 DeiT 的实现,Patch Size 使用8或者16。DINO 也像 ViT 那样给模型加了一个 [CLS] token,即使它没有附加到任何标签或监督信息。Self-attention 机制更新这个 token。
在评估时,除了 linear evaluation 和 finetuning evaluation 之外,作者还额外尝试了 k-NN evaluation。作者冻结了预训练模型,然后存储下游任务训练数据的特征。
DINO 网络架构
消融实验结果
不同组件的作用
Patch Size 的作用
教师模型训练策略的作用
避免坍塌
总结
DINO,这是第一篇探索 ViT 模型在自监督学习领域的经典代表作。DINO 整体架构基于自蒸馏的范式进行构建,包含一个教师网络和学生网络。其中,学生网络学习从局部补丁预测图像中的全局特征,该补丁受动量教师网络嵌入的交叉熵损失的监督,同时进行居中和锐化以防止模式崩溃。
在 DINO 诞生的时期,视觉 Transformer 与 ConvNet 相比才刚刚具备竞争力,但是那是还没有明显的优势。而且,当时视觉 Transformer 对于计算量要求更高,需要更多的训练数据,且特征没有表现出独特的属性。
因此,本文想要探索一下 Transformer 成功的关键是不是来自 Self-supervised Learning。其主要的动机是 Transformer 在 NLP 中成功的主要原因就是 Self-supervised Learning,比如 BERT 的 Masked Language Modeling 或者 GPT 的 Language Modeling。自监督训练会根据上下文创建一个任务,这些任务相比于有监督训练的预测标签来讲,可以提供更加丰富的学习信号。同样的道理,图像的有监督训练是把图像中包含的丰富的视觉信息压缩到只有类别的标签信息。
因此,本文研究自监督预训练对 ViT 特征的影响。本文给出了几个有趣的观察,这些观察在以往的有监督训练以及卷积网络里面都没有:
-
自监督训练 ViT 得到的特征显式地包含场景布局,尤其是对象的边界。这个信息一般在自监督训练的视觉 Transformer 的最后一个 Block 得到,如图1所示。这个发现作者认为几乎是所有的自监督学习方法的共同特性。
-
自监督训练的视觉 Transformer 的特征可以在不经过任何微调,线性分类器,以及数据增强的前提下,仅仅使用最简单的 k-NN 分类器,就能实现 78.3% 的 top-1 ImageNet 精度。这个发现作者认为并不是所有自监督方法的共性,而是仅仅当包含一些特殊的组件比如 momentum encoder,或者使用了特殊的数据增强比如 multi-crop augmentation 的时候才会出现。
DINO 算法伪代码如下。
# gs, gt: student and teacher networks
# C: center (K)
# tps, tpt: student and teacher temperatures
# l, m: network and center momentum rates
gt.params = gs.params
for x in loader: # load a minibatch x with n samples
x1, x2 = augment(x), augment(x) # random views
s1, s2 = gs(x1), gs(x2) # student output n-by-K
t1, t2 = gt(x1), gt(x2) # teacher output n-by-K
loss = H(t1, s2)/2 + H(t2, s1)/2
loss.backward() # back-propagate
# student, teacher and center updates
update(gs) # SGD
gt.params = l*gt.params + (1-l)*gs.params
C = m*C + (1-m)*cat([t1, t2]).mean(dim=0)
def H(t, s):
t = t.detach() # stop gradient
s = softmax(s / tps, dim=1)
t = softmax((t - C) / tpt, dim=1) # center + sharpen
return - (t * log(s)).sum(dim=1).mean()

















 6241
6241

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









