







 本文介绍了轨迹池化-深度卷积描述符(TDD)技术,它结合手工制作和深度学习特征,自动学习高区分度的视频表示。TDD方法考虑了时间维度,采用轨迹受限的采样和池化策略,增强了深度学习特征。通过改进的轨迹和双向ConvNets,TDD构建了一个有效的动作识别框架。
本文介绍了轨迹池化-深度卷积描述符(TDD)技术,它结合手工制作和深度学习特征,自动学习高区分度的视频表示。TDD方法考虑了时间维度,采用轨迹受限的采样和池化策略,增强了深度学习特征。通过改进的轨迹和双向ConvNets,TDD构建了一个有效的动作识别框架。
1、摘要:
本论文提出一种新的视频表示方法,称作轨迹池化-深度卷积描述符(TDD),共享手工制作的特征和深度学习特征。优点是:(1) TDDs是自动学习,并且与这些手工制作的特征相比具有高区分度的性能;(2) TDDs考虑时间维度的本质特征,介绍轨迹受限的采样和池化的策略加强深度学习特征。
2、介绍:
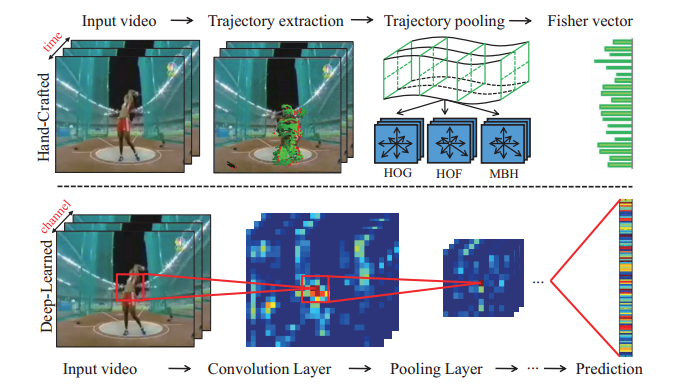
Figure 1主要有两种类型的特征:手工制作的特征和深度学习特征。对于手工制作的特征,提高的轨迹[31]结合费舍尔向量是最成功的做法。对于深度学习特征,ConNets [18]是很受欢迎的深度架构,它包含一系列的卷积和池化层。他们旨在自动学习有区别度的特征进行神经网络的训练。
2.1 视频表示的主要影响因素:背景杂斑、视角变化、各种各样的运动速度和风格、高维度和低分辨率;
2.3 两种特征的特点:
(1)手工制作的特征:
1. 手工制作的特征的处理主要包括两个阶段:
1)detector:找到突出和信息丰富的区域;
2) descriptor:利用HOG,HOF,MBH等特征提高轨迹;
2. 优点:轨迹受限的采样策略的考虑了人类动作时间上的连续性,这对于处理动作的改变问题非常有效;
3. 缺点:手工制作的描述符缺乏动作的区分性;
(2)深度特征:
TwoStream ConvNets [24] 是目前最优秀的架构,尤其在加强轨迹上。它由两个神经网络组成,分别是空间网络和时间网络ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3615
3615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









